


《计算机应用》唯一官方网站 ›› 2021, Vol. 41 ›› Issue (12): 3637-3644.DOI: 10.11772/j.issn.1001-9081.2021010090
• 人工智能 • 上一篇
收稿日期:2021-01-18
修回日期:2021-04-27
接受日期:2021-04-29
发布日期:2021-12-28
出版日期:2021-12-10
通讯作者:
曾碧卿
作者简介:姚博文(1997—),男,江西赣州人,硕士研究生,CCF会员,主要研究方向:自然语言处理、关系抽取基金资助:
Bowen YAO, Biqing ZENG( ), Jian CAI, Meirong DING
), Jian CAI, Meirong DING
Received:2021-01-18
Revised:2021-04-27
Accepted:2021-04-29
Online:2021-12-28
Published:2021-12-10
Contact:
Biqing ZENG
About author:YAO Bowen, born in 1997, M. S. candidate. His research interests include natural language processing, relation extraction.Supported by:摘要:
关系抽取任务旨在从文本中抽取实体对之间的关系,是当前自然语言处理(NLP)领域的热门方向之一。针对中文人物关系抽取语料中语法结构复杂,无法有效学习文本语义特征的问题,提出一个基于预训练和多层次信息的中文人物关系抽取模型(CCREPMI)。该模型首先利用预训练模型较强的语义表征能力生成词向量,并将原始句子分成句子层次、实体层次和实体邻近层次分别进行特征提取,最终融合句子结构特征、实体含义以及实体与邻近词的依赖关系等信息进行关系分类预测。在中文人物关系数据集上的实验结果表明,该模型的精度达到81.5%,召回率达到82.3%,F1值达到81.9%,相比BERT和BERT-LSTM等基线模型有所提升。此外,该模型在SemEval2010-task8英文数据集上的F1值也达到了81.2%,表明它对英文语料具有一定的泛化能力。
中图分类号:
姚博文, 曾碧卿, 蔡剑, 丁美荣. 基于预训练和多层次信息的中文人物关系抽取模型[J]. 计算机应用, 2021, 41(12): 3637-3644.
Bowen YAO, Biqing ZENG, Jian CAI, Meirong DING. Chinese character relation extraction model based on pre-training and multi-level information[J]. Journal of Computer Applications, 2021, 41(12): 3637-3644.

图1 数据预处理流程
Fig. 1 Process of data pre-processing

图2 句子截取方式示例
Fig. 2 Example of sentence segmentation

图3 BERT模型
Fig. 3 BERT model
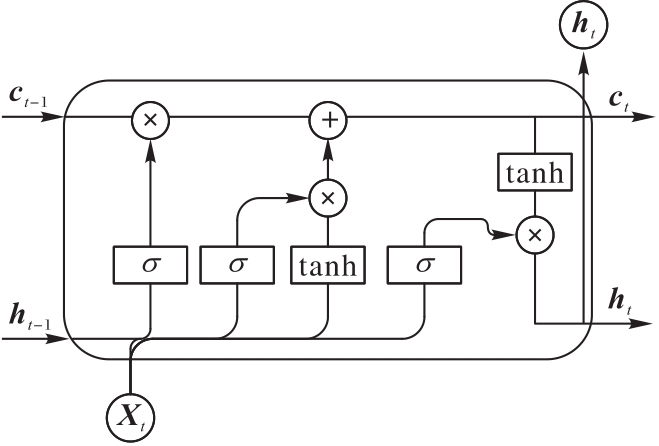
图4 LSTM结构
Fig. 4 LSTM structure
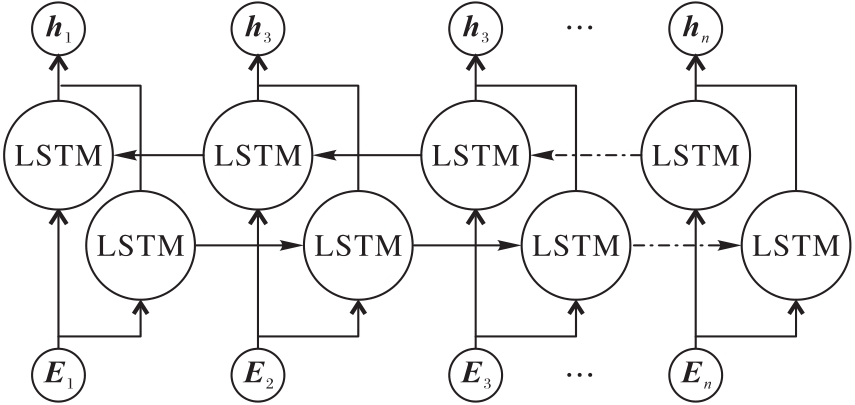
图5 双向LSTM层
Fig. 5 Bidirectional LSTM layer
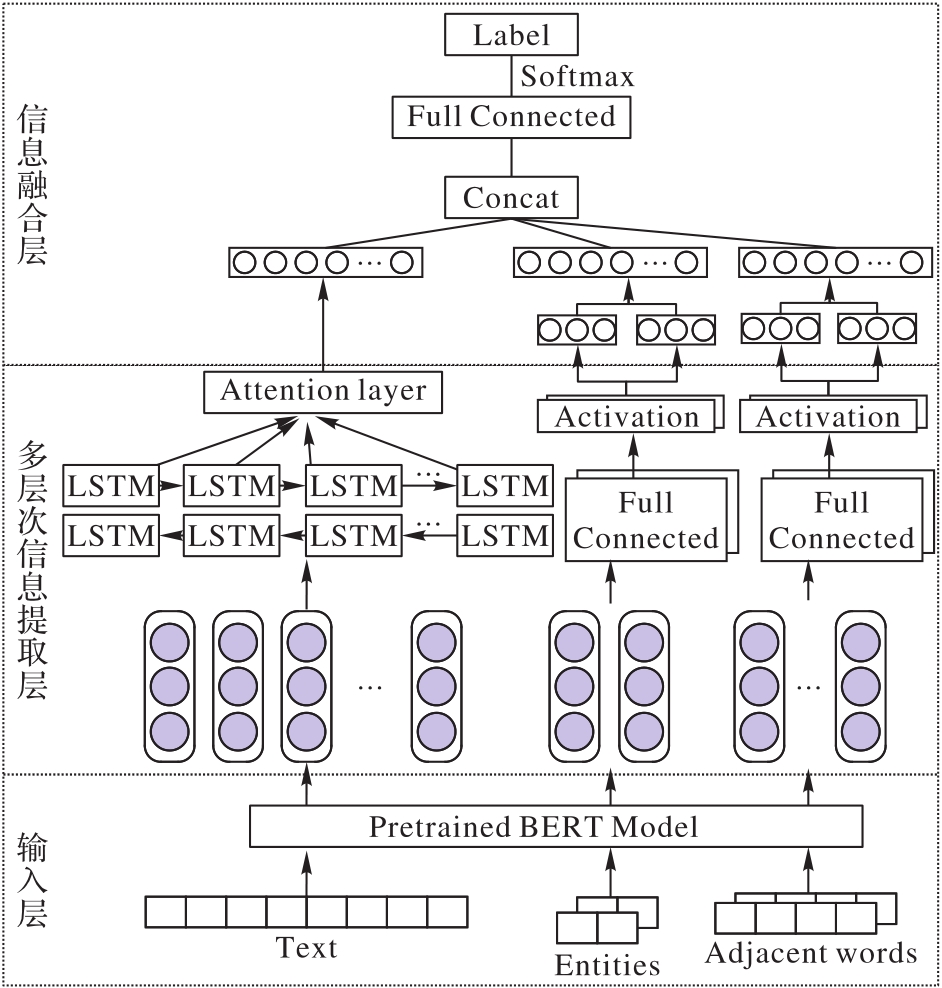
图6 CCREPMI模型结构
Fig. 6 CCREPMI model structure

图7 多层次信息提取层
Fig. 7 Multi-level information extraction layer
| 参数描述 | 值 |
|---|---|
| 批次大小 | 32 |
| 文本最大长度 | 85 |
| 学习率 | 5E-5 |
| 训练轮数 | 10 |
| 丢弃率 | 0.3 |
| BiLSTM隐藏维度 | 768 |
| BiLSTM层数 | 2 |
| 邻近词窗口长度 | 1 |
表1 超参数设置
Tab. 1 Hyperparameter setting
| 参数描述 | 值 |
|---|---|
| 批次大小 | 32 |
| 文本最大长度 | 85 |
| 学习率 | 5E-5 |
| 训练轮数 | 10 |
| 丢弃率 | 0.3 |
| BiLSTM隐藏维度 | 768 |
| BiLSTM层数 | 2 |
| 邻近词窗口长度 | 1 |
| 实验环境 | 配置 |
|---|---|
| GPU | Tesla T4 |
| 操作系统 | Windows 10 |
| 开发语言 | Python3.6 |
| 深度学习框架 | Pytorch1.7 |
表2 实验环境
Tab. 2 Experiment environment
| 实验环境 | 配置 |
|---|---|
| GPU | Tesla T4 |
| 操作系统 | Windows 10 |
| 开发语言 | Python3.6 |
| 深度学习框架 | Pytorch1.7 |
| 模型 | 嵌入维度 | 精度/% | 召回率/% | F1值% |
|---|---|---|---|---|
| CCREPMI-BERT | 768 | 81.5 | 82.3 | 81.9 |
| CCREPMI-BERT-wwm | 768 | 79.0 | 79.7 | 79.3 |
| CCREPMI-ERNIE | 768 | 79.3 | 80.0 | 79.6 |
表3 不同预训练模型的结果对比
Tab. 3 Result comparison of different pre-trained models
| 模型 | 嵌入维度 | 精度/% | 召回率/% | F1值% |
|---|---|---|---|---|
| CCREPMI-BERT | 768 | 81.5 | 82.3 | 81.9 |
| CCREPMI-BERT-wwm | 768 | 79.0 | 79.7 | 79.3 |
| CCREPMI-ERNIE | 768 | 79.3 | 80.0 | 79.6 |
| 模型类别 | 模型 | 精度 | 召回率 | F1值 |
|---|---|---|---|---|
| 基准模型 | CNN | 45.3 | 44.9 | 45.1 |
| CRCNN | 52.1 | 46.1 | 48.9 | |
| BiLSTM-Att | 58.3 | 57.6 | 57.9 | |
| BERT-based | BERT | 72.5 | 73.7 | 73.0 |
| BERT-LSTM | 73.3 | 74.3 | 73.7 | |
| RBERT | 81.0 | 81.5 | 81.2 | |
| 本文模型 | CCREPMI-S | 80.6 | 81.2 | 80.6 |
| CCREPMI-G | 81.1 | 81.9 | 81.5 | |
| CCREPMI | 81.5 | 82.3 | 81.9 |
表4 不同模型的性能对比 ( %)
Tab. 4 Performance comparison of different models
| 模型类别 | 模型 | 精度 | 召回率 | F1值 |
|---|---|---|---|---|
| 基准模型 | CNN | 45.3 | 44.9 | 45.1 |
| CRCNN | 52.1 | 46.1 | 48.9 | |
| BiLSTM-Att | 58.3 | 57.6 | 57.9 | |
| BERT-based | BERT | 72.5 | 73.7 | 73.0 |
| BERT-LSTM | 73.3 | 74.3 | 73.7 | |
| RBERT | 81.0 | 81.5 | 81.2 | |
| 本文模型 | CCREPMI-S | 80.6 | 81.2 | 80.6 |
| CCREPMI-G | 81.1 | 81.9 | 81.5 | |
| CCREPMI | 81.5 | 82.3 | 81.9 |
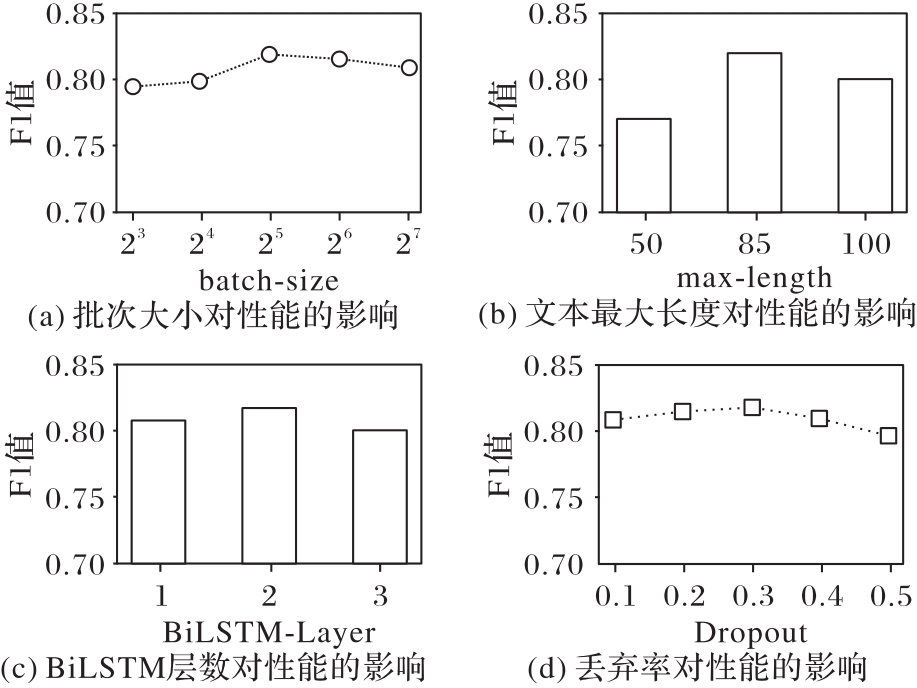
图8 超参数对模型性能的影响
Fig. 8 Influence of hyperparameters on model performance
| 模型 | F1值 |
|---|---|
| CNN | 78.9 |
| MVRNN | 79.1 |
| FCM | 80.6 |
| CCREPMI | 81.2 |
表5 不同模型在英文数据集SemEval2010-task8上的实验结果对比 ( %)
Tab. 5 Results comparison of different models on English dataset SemEval2010-task8
| 模型 | F1值 |
|---|---|
| CNN | 78.9 |
| MVRNN | 79.1 |
| FCM | 80.6 |
| CCREPMI | 81.2 |
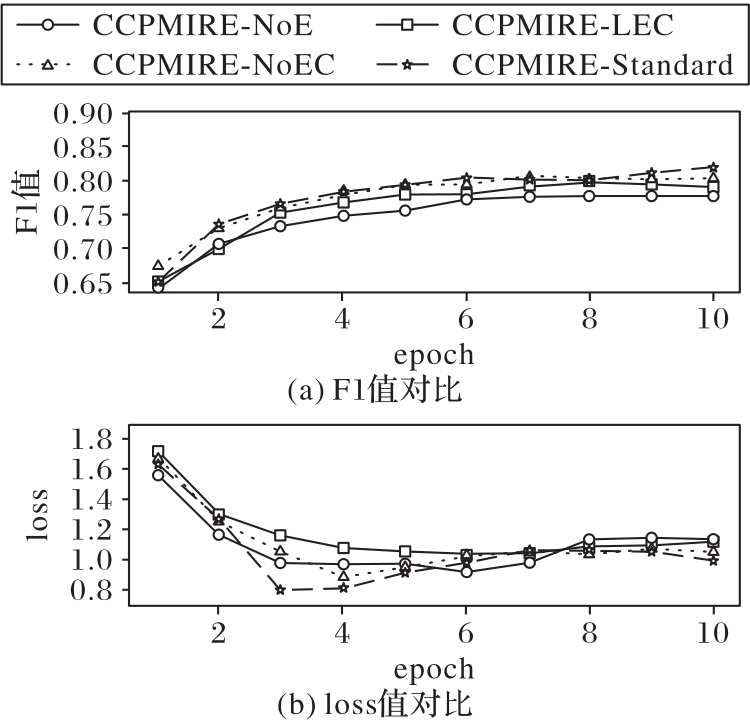
图9 变体模型对比结果
Fig.9 Comparison results of variant models
| 1 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186. 10.18653/v1/n19-1423 |
| 2 | RADFORD A, NARASIMHAN K, SALIMANS T.et al. Improving language understanding by generative pre-training[EB/OL]. [2020-09-07].. |
| 3 | SOCHER R, HUVAL B, MANNING C D, et al. Semantic compositionality through recursive matrix-vector spaces[C]// Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg, PA: Association for Computational Linguistics, 2012: 1201-1211. |
| 4 | ZENG D J, LIU K, LAI S W, et al. Relation classification via convolutional deep neural network[C]// Proceedings of the 25th International Conference on Computational Linguistics: Technical Papers. Stroudsburg, PA: Association for Computational Linguistics, 2014: 2335-2344. |
| 5 | SANTOS C N DOS, XIANG B, ZHOU B W. Classifying relations by ranking with convolutional neural networks[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics/ the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2015: 626-634. 10.3115/v1/p15-1061 |
| 6 | XU Y, MOU L L, LI G, et al. Classifying relations via long short term memory networks along shortest dependency paths[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 1785-1794. 10.18653/v1/d15-1206 |
| 7 | LEE J, SEO S, CHOI Y S. Semantic relation classification via bidirectional LSTM networks with entity-aware attention using latent entity typing[J]. Symmetry, 2019, 11(6): No.785. 10.3390/sym11060785 |
| 8 | MINTZ M, BILLS S, SNOW R, et al. Distant supervision for relation extraction without labeled data[C]// Proceedings of the Joint Conference of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2009: 1003-1011. 10.3115/1690219.1690287 |
| 9 | LIN Y K, SHEN S Q, LIU Z Y, et al. Neural relation extraction with selective attention over instances[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 2124-2133. 10.18653/v1/p16-1200 |
| 10 | PENG N Y, POON H, QUIRK C, et al. Cross-sentence n-ary relation extraction with graph LSTMs[J]. Transactions of the Association for Computational Linguistics, 2017, 5: 101-115. 10.1162/tacl_a_00049 |
| 11 | JI G L, LIU K, HE S Z, et al. Distant supervision for relation extraction with sentence-level attention and entity descriptions[C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017: 3060-3066. |
| 12 | LI Y, LONG G D, SHEN T, et al. Self-attention enhanced selective gate with entity-aware embedding for distantly supervised relation extraction[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 8269-8276. 10.1609/aaai.v34i05.6342 |
| 13 | BANKO M, CAFARELLA M J, SODERLAND S, et al. Open information extraction from the Web[C]// Proceedings of the 20th International Joint Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2007: 2670-2676. 10.3115/1614164.1614177 |
| 14 | AKBIK A, LÖSER A. KrakeN: N-ary facts in open information extraction[C]// Proceedings of the 2012 Joint Workshop on Automatic Knowledge Base Construction and Web-scale Knowledge Extraction. Stroudsburg, PA: Association for Computational Linguistics, 2012: 52-56. |
| 15 | 王明波,王峥,邱秀连. 基于双向GRU和PCNN的人物关系抽取[J]. 电子设计工程, 2020, 28(10):160-165. 10.1109/access.2021.3078114 |
| WANG M B, WANG Z, QIU X L. Character relationship extraction based on bidirectional GRU and PCNN[J]. Electronic Design Engineering, 2020, 28(10): 160-165. 10.1109/access.2021.3078114 | |
| 16 | 刘鉴,张怡,张勇. 基于双向LSTM和自注意力机制的中文关系抽取研究[J]. 山西大学学报(自然科学版), 2020, 43(1):8-13. |
| LIU J, ZHANG Y, ZHANG Y. Chinese relationship extraction based on bidirectional LSTM and self-attention mechanism[J]. Journal of Shanxi University (Natural Science Edition), 2020, 43(1): 8-13 | |
| 17 | CUI Y M, CHE W X, LIU T, et al. Pre-training with whole word masking for Chinese BERT[EB/OL]. (2019-10-29) [2020-10-09]. . 10.1109/taslp.2021.3124365 |
| 18 | SUN Y, WANG S H, LI Y K, et al. ERNIE: enhanced representation through knowledge integration[EB/OL]. (2019-04-19) [2020-09-11].. |
| 19 | ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 207-212. 10.18653/v1/p16-2034 |
| 20 | SHI P, LIN J. Simple BERT models for relation extraction and semantic role labeling[EB/OL]. (2019-04-10) [2020-09-21].. |
| 21 | WU S C, HE Y F. Enriching pre-trained language model with entity information for relation classification[C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM, 2019: 2361-2364. 10.1145/3357384.3358119 |
| [1] | 谢德峰, 吉建民. 融入句法感知表示进行句法增强的语义解析[J]. 计算机应用, 2021, 41(9): 2489-2495. |
| [2] | 刘雅璇, 钟勇. 基于头实体注意力的实体关系联合抽取方法[J]. 计算机应用, 2021, 41(9): 2517-2522. |
| [3] | 王伟, 赵尔平, 崔志远, 孙浩. 基于HowNet义原和Word2vec词向量表示的多特征融合消歧方法[J]. 计算机应用, 2021, 41(8): 2193-2198. |
| [4] | 周险兵, 樊小超, 任鸽, 杨勇. 基于多层次语义特征的英文作文自动评分方法[J]. 计算机应用, 2021, 41(8): 2205-2211. |
| [5] | 吴丽丹, 薛雨阳, 童同, 杜民, 高钦泉. 基于前景语义信息的图像着色算法[J]. 计算机应用, 2021, 41(7): 2048-2053. |
| [6] | 杜炎, 吕良福, 焦一辰. 基于模糊推理的模糊原型网络[J]. 计算机应用, 2021, 41(7): 1885-1890. |
| [7] | 章荪, 尹春勇. 基于多任务学习的时序多模态情感分析模型[J]. 计算机应用, 2021, 41(6): 1631-1639. |
| [8] | 王朱君, 王石, 李雪晴, 朱俊武. 基于深度学习的事件因果关系抽取综述[J]. 《计算机应用》唯一官方网站, 2021, 41(5): 1247-1255. |
| [9] | 李雪晴, 王石, 王朱君, 朱俊武. 自然语言生成综述[J]. 《计算机应用》唯一官方网站, 2021, 41(5): 1227-1235. |
| [10] | 赖雪梅, 唐宏, 陈虹羽, 李珊珊. 基于注意力机制的特征融合-双向门控循环单元多模态情感分析[J]. 计算机应用, 2021, 41(5): 1268-1274. |
| [11] | 刘睿珩, 叶霞, 岳增营. 面向自然语言处理任务的预训练模型综述[J]. 《计算机应用》唯一官方网站, 2021, 41(5): 1236-1246. |
| [12] | 李文惠, 曾上游, 王金金. 基于改进注意力机制的图像描述生成算法[J]. 计算机应用, 2021, 41(5): 1262-1267. |
| [13] | 卞鹏程, 郑忠龙, 李明禄, 何依然, 王天翔, 张大伟, 陈丽媛. 基于注意力融合网络的视频超分辨率重建[J]. 计算机应用, 2021, 41(4): 1012-1019. |
| [14] | 崔博文, 金涛, 王建民. 自由文本电子病历信息抽取综述[J]. 计算机应用, 2021, 41(4): 1055-1063. |
| [15] | 李慧慧, 闫坤, 张李轩, 刘威, 李执. 基于MobileNetV2的圆形指针式仪表识别系统[J]. 计算机应用, 2021, 41(4): 1214-1220. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||