


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (3): 860-866.DOI: 10.11772/j.issn.1001-9081.2021030441
• 人工智能 • 上一篇
收稿日期:2021-03-23
修回日期:2021-07-20
接受日期:2021-07-21
发布日期:2022-04-09
出版日期:2022-03-10
通讯作者:
孙邱杰
作者简介:梁景贵(1996—),男,广西玉林人,硕士研究生,主要研究方向:自然语言理解、语法纠错基金资助:
Qiujie SUN( ), Jinggui LIANG, Si LI
), Jinggui LIANG, Si LI
Received:2021-03-23
Revised:2021-07-20
Accepted:2021-07-21
Online:2022-04-09
Published:2022-03-10
Contact:
Qiujie SUN
About author:LIANG Jinggui, born in 1996, M. S. candidate. His research interests include natural language understanding, grammatical error correction.Supported by:摘要:
在中文语法纠错中,基于神经机器翻译的方法被广泛应用,该方法在训练过程中需要大量的标注数据才能保障性能,但中文语法纠错的标注数据较难获取。针对标注数据有限导致中文语法纠错系统性能不佳问题,提出一种基于BART噪声器的中文语法纠错模型——BN-CGECM。首先,为了加快模型的收敛,使用基于BERT的中文预训练语言模型对BN-CGECM的编码器参数进行初始化;其次,在训练过程中,通过BART噪声器对输入样本引入文本噪声,自动生成更多样的含噪文本用于模型训练,从而缓解标注数据有限的问题。在NLPCC 2018数据集上的实验结果表明,所提模型的F0.5值比有道开发的中文语法纠错系统(YouDao)提高7.14个百分点,比北京语言大学开发的集成中文语法纠错系统(BLCU_ensemble)提高6.48个百分点;同时,所提模型不增加额外的训练数据量,增强了原始数据的多样性,且具有更快的收敛速度。
中图分类号:
孙邱杰, 梁景贵, 李思. 基于BART噪声器的中文语法纠错模型[J]. 计算机应用, 2022, 42(3): 860-866.
Qiujie SUN, Jinggui LIANG, Si LI. Chinese grammatical error correction model based on bidirectional and auto-regressive transformers noiser[J]. Journal of Computer Applications, 2022, 42(3): 860-866.
错误 类型 | 错误句子(输入序列) | 正确句子(输出序列) |
|---|---|---|
| M | 中国是世界拥有最多“烟民”的国家。 | 中国是世界上拥有最多“烟民”的国家。 |
| R | 孩子的教育不能只靠一个学校老师。 | 孩子的教育不能只靠一个老师。 |
| S | 父母对孩子的爱情是最重要的。 | 父母对孩子的关爱是最重要的。 |
| W | 生产率较低,那肯定价格要上升。 | 生产率较低,那价格肯定要上升。 |
表1 语法纠错任务示例
Tab. 1 Examples for grammatical error correction
错误 类型 | 错误句子(输入序列) | 正确句子(输出序列) |
|---|---|---|
| M | 中国是世界拥有最多“烟民”的国家。 | 中国是世界上拥有最多“烟民”的国家。 |
| R | 孩子的教育不能只靠一个学校老师。 | 孩子的教育不能只靠一个老师。 |
| S | 父母对孩子的爱情是最重要的。 | 父母对孩子的关爱是最重要的。 |
| W | 生产率较低,那肯定价格要上升。 | 生产率较低,那价格肯定要上升。 |

图1 BN-CGECM框架
Fig. 1 Architecture of BN-CGECM
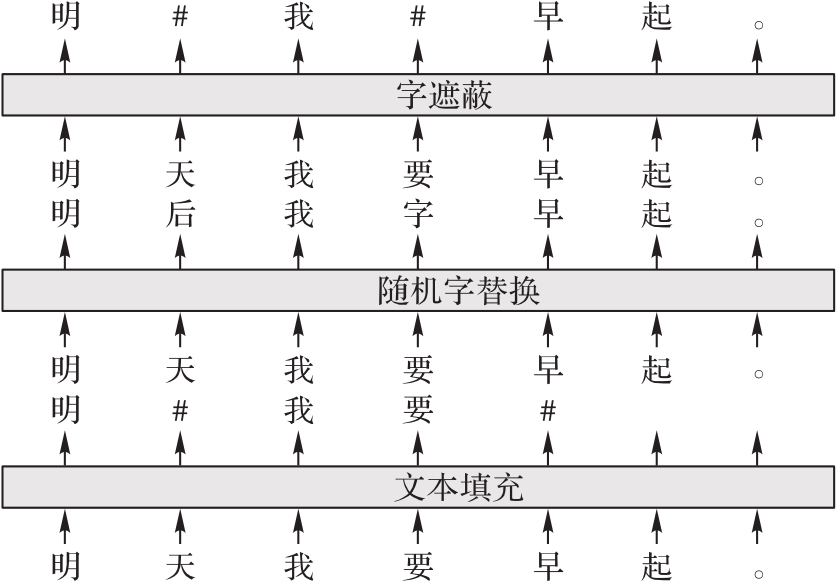
图2 不同噪声方案的噪声示例
Fig. 2 Examples of different noise schemes
| 类型 | 句子数 | Src词数 | Tgt词数 |
|---|---|---|---|
| 原始训练集 | 1 200 000 | 23700 000 | 25 000 000 |
| 伪训练集 | 1 200 000 | 23700 000 | 25 100 000 |
| 验证集 | 5 000 | 99 300 | 104 100 |
| 测试集 | 2 000 | 58 900 | — |
表2 NLPCC 2018 Task 2 数据集
Tab. 2 NLPCC 2018 Task 2 dataset
| 类型 | 句子数 | Src词数 | Tgt词数 |
|---|---|---|---|
| 原始训练集 | 1 200 000 | 23700 000 | 25 000 000 |
| 伪训练集 | 1 200 000 | 23700 000 | 25 100 000 |
| 验证集 | 5 000 | 99 300 | 104 100 |
| 测试集 | 2 000 | 58 900 | — |
| 模型 | P | R | |
|---|---|---|---|
| YouDao | 35.24 | 18.64 | 29.91 |
| BLCU | 41.73 | 13.08 | 29.02 |
| BLCU_ensemble | 47.63 | 12.56 | 30.57 |
| BERT-encoder | 32.67 | 22.19 | 29.76 |
| BERT-encoder_ensemble | 41.84 | 22.02 | 35.51 |
| BN-CGECM | 44.27 | 18.36 | 34.53 |
| BN-CGECM_ensemble | 51.57 | 17.43 | 37.05 |
表3 几种模型在NLPCC 2018数据集的实验结果 (%)
Tab. 3 Experimental results of several models on NLPCC 2018 dataset
| 模型 | P | R | |
|---|---|---|---|
| YouDao | 35.24 | 18.64 | 29.91 |
| BLCU | 41.73 | 13.08 | 29.02 |
| BLCU_ensemble | 47.63 | 12.56 | 30.57 |
| BERT-encoder | 32.67 | 22.19 | 29.76 |
| BERT-encoder_ensemble | 41.84 | 22.02 | 35.51 |
| BN-CGECM | 44.27 | 18.36 | 34.53 |
| BN-CGECM_ensemble | 51.57 | 17.43 | 37.05 |
| 方法 | P | R | |
|---|---|---|---|
| Char-Transformer | 39.95 | 12.71 | 27.96 |
| Char-Transformer+字屏蔽 | 45.25 | 17.40 | 34.28 |
| Char-Transformer+随机字替换 | 21.38 | 24.15 | 21.88 |
| Char-Transformer+文本填充 | 46.16 | 16.25 | 33.74 |
| Char-Transformer+混合方法 | 44.27 | 18.36 | 34.53 |
表4 不同噪声方法的实验结果 (%)
Tab. 4 Experimental results of different noise methods
| 方法 | P | R | |
|---|---|---|---|
| Char-Transformer | 39.95 | 12.71 | 27.96 |
| Char-Transformer+字屏蔽 | 45.25 | 17.40 | 34.28 |
| Char-Transformer+随机字替换 | 21.38 | 24.15 | 21.88 |
| Char-Transformer+文本填充 | 46.16 | 16.25 | 33.74 |
| Char-Transformer+混合方法 | 44.27 | 18.36 | 34.53 |

图3 模型收敛速度比较
Fig. 3 Comparison on convergence speed of models
| 预训练模型 | P | R | |
|---|---|---|---|
| — | 44.27 | 18.36 | 34.53 |
| Chinese-BERT-wwm | 44.46 | 18.38 | 34.63 |
| Chinese-BERT-wwm-ext | 44.38 | 18.37 | 34.59 |
| Chinese-RoBERTa-wwm-ext | 45.55 | 18.50 | 35.24 |
表5 不同预训练模型的实验结果 (%)
Tab. 5 Experimental results of different pre-trained models
| 预训练模型 | P | R | |
|---|---|---|---|
| — | 44.27 | 18.36 | 34.53 |
| Chinese-BERT-wwm | 44.46 | 18.38 | 34.63 |
| Chinese-BERT-wwm-ext | 44.38 | 18.37 | 34.59 |
| Chinese-RoBERTa-wwm-ext | 45.55 | 18.50 | 35.24 |
| 1 | MARTINS B, SILVA M J. Spelling correction for search engine queries [C]// Proceedings of the 2004 International Conference on Natural Language Processing. Cham: Springer, 2004: 372-383. 10.1007/978-3-540-30228-5_33 |
| 2 | GAO J F, LI X L, MICOL D, et al. A large scale ranker-based system for search query spelling correction [C]// Proceedings of the 23rd International Conference on Computational Linguistics. New York: ACM, 2010: 358-366. |
| 3 | AFLI H, QIU Z, WAY A, et al. Using SMT for OCR error correction of historical texts [C]// Proceedings of the Tenth International Conference on Language Resources and Evaluation. Portorož: European Language Resources Association, 2016: 962-966. |
| 4 | WANG D M, SONG Y, LI J, et al. A hybrid approach to automatic corpus generation for Chinese spelling check [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: Association for Computational Linguistics, 2018: 2517-2527. 10.18653/v1/d18-1273 |
| 5 | BURSTEIN J, CHODOROW M. Automated essay scoring for nonnative English speakers[C]// Proceedings of a Symposium on Computer Mediated Language Assessment and Evaluation in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 1999: 68-75. 10.3115/1598834.1598847 |
| 6 | YUAN Z, BRISCOE T. Grammatical error correction using neural machine translation [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2016: 380-386. 10.18653/v1/n16-1042 |
| 7 | JI J S, WANG Q L, TOUTANOVA K, et al. A nested attention neural hybrid model for grammatical error correction [EB/OL]. [2020-10-10]. . 10.18653/v1/p17-1070 |
| 8 | CHOLLAMPATT S, NG H T. A multilayer convolutional encoder-decoder neural network for grammatical error correction [EB/OL]. [2020-10-10]. . 10.18653/v1/d18-1274 |
| 9 | CHENG X Y, XU W D, CHEN K L, et al. SpellGCN: incorporating phonological and visual similarities into language models for Chinese spelling check[EB/OL]. [2021-01-10]. . 10.18653/v1/2020.acl-main.81 |
| 10 | REN H K, YANG L, XUN E. A sequence to sequence learning for Chinese grammatical error correction [C]// Proceedings of the 7th CCF International Conference on Natural Language Processing and Chinese Computing. Cham: Springer, 2018: 401-410. 10.1007/978-3-319-99501-4_36 |
| 11 | ZHOU J, LI C, LIU H, et al. Chinese grammatical error correction using statistical and neural models [C]// Proceedings of the 7th CCF International Conference on Natural Language Processing and Chinese Computing. Cham: Springer, 2018: 117-128. 10.1007/978-3-319-99501-4_10 |
| 12 | 张佳宁,严冬梅,王勇. 基于word2vec的语音识别后文本纠错[J]. 计算机工程与设计, 2020,41(11):3235-3240. 10.16208/j.issn1000-7024.2020.11.038 |
| ZHANG J N, YAN D M, WANG Y. Text correction based on word2vec speech recognition full-text in Chinese [J]. Computer Engineering and Design, 2020,41(11):3235-3240. 10.16208/j.issn1000-7024.2020.11.038 | |
| 13 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186. 10.18653/v1/n19-1423 |
| 14 | CUI Y M, CHE W X, LIU T, et al. Revisiting pre-trained models for Chinese natural language processing [EB/OL].[2020-10-10]. . 10.18653/v1/2020.findings-emnlp.58 |
| 15 | ZHANG Z, HAN X, LIU Z, et al. ERNIE: enhanced language representation with informative entities [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 1441-1451. 10.18653/v1/p19-1139 |
| 16 | KIYONO S, SUZUKI J, MITA M, et al. An empirical study of incorporating pseudo data into grammatical error correction [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 1236-1242. 10.18653/v1/d19-1119 |
| 17 | LEWIS M, LIU Y, GOYAL N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 7871-7880. 10.18653/v1/2020.acl-main.703 |
| 18 | REN H, YANG L, XUN E. A sequence to sequence learning for Chinese grammatical error correction [C]// Proceedings of the 2018 CCF International Conference on Natural Language Processing and Chinese Computing. Cham: Springer, 2018: 401-410. 10.1007/978-3-319-99501-4_36 |
| 19 | BUSTAMANTE F R, LEÓN F S. GramCheck: a grammar and style checker [C]// Proceedings of the 16th Conference on Computational Linguistics. New York: ACM, 1996,1: 175-181. 10.3115/992628.992661 |
| 20 | HEIDORN G E, JENSEN K, MILLER L A, et al. The EPISTLE text-critiquing system[J]. IBM Systems Journal, 1982, 21(3): 305-326. 10.1147/sj.213.0305 |
| 21 | DE FELICE R, PULMAN S. A classifier-based approach to preposition and determiner error correction in L2 English [C]// Proceedings of the 22nd International Conference on Computational Linguistics. New York: ACM, 2008: 169-176. 10.3115/1599081.1599103 |
| 22 | ROZOVSKAYA A, ROTH D. Grammatical error correction: machine translation and classifiers [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 2205-2215. 10.18653/v1/p16-1208 |
| 23 | BROCKETT C, DOLAN W B, GAMON M. Correcting ESL errors using phrasal SMT techniques [C]// Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2006: 249-256. 10.3115/1220175.1220207 |
| 24 | JUNCZYS-DOWMUNT M, GRUNDKIEWICZ R. Phrase-based machine translation is state-of-the-art for automatic grammatical error correction [C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1546-1556. 10.18653/v1/d16-1161 |
| 25 | NG H T, WU S M, BRISCOE T, et al. The CoNLL-2014 shared task on grammatical error correction [C]// Proceedings of the 18th Conference on Computational Natural Language Learning: Shared Task. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1-14. 10.3115/v1/w14-1701 |
| 26 | XIE Z, AVATI A, ARIVAZHAGAN N, et al. Neural language correction with character-based attention [EB/OL]. [2016-05-31]. . |
| 27 | CHOLLAMPATT S, NG H T. A multilayer convolutional encoder-decoder neural network for grammatical error correction [EB/OL]. [2018-01-26]. . 10.18653/v1/d18-1274 |
| 28 | GRUNDKIEWICZ R, JUNCZYS-DOWMUNT M. Near human-level performance in grammatical error correction with hybrid machine translation[EB/OL]. [2018-04-16]. . 10.18653/v1/n18-2046 |
| 29 | WANG H, KUROSAWA M, KATSUMATA S, et al. Chinese grammatical correction using BERT-based pre-trained model [EB/OL]. [2020-11-04]. . |
| 30 | FELICE M, YUAN Z. Generating artificial errors for grammatical error correction [C]// Proceedings of the Student Research Workshop at the 14th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2014: 116-126. 10.3115/v1/e14-3013 |
| 31 | XIE Z, AVATI A, ARIVAZHAGAN N, et al. Neural language correction with character-based attention [EB/OL]. [2016-05-31]. . |
| 32 | ZHAO Y, JIANG N, SUN W, et al. Overview of the NLPCC 2018 shared task: grammatical error correction [C]// Proceedings of the 2018 CCF International Conference on Natural Language Processing and Chinese Computing. Cham: Springer, 2018: 439-445. 10.1007/978-3-319-99501-4_41 |
| 33 | FU K, HUANG J, DUAN Y. Youdao’s winning solution to the NLPCC-2018 task 2 challenge: a neural machine translation approach to Chinese grammatical error correction [C]// Proceedings of the 2018 CCF International Conference on Natural Language Processing and Chinese Computing. Cham: Springer, 2018: 341-350. 10.1007/978-3-319-99495-6_29 |
| 34 | DAHLMEIER D, NG H T. Better evaluation for grammatical error correction [C]// Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2012: 568-572. |
| [1] | 曹一珉, 蔡磊, 高敬阳. 基于生成对抗网络的基因数据生成方法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 783-790. |
| [2] | 于婉莹, 梁美玉, 王笑笑, 陈徵, 曹晓雯. 基于深度注意力网络的课堂教学视频中学生表情识别与智能教学评估[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 743-749. |
| [3] | 李讷, 徐光柱, 雷帮军, 马国亮, 石勇涛. 交通道路行驶车辆车标识别算法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 810-817. |
| [4] | 陈亭秀, 尹建芹. 基于关键帧筛选网络的视听联合动作识别[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 731-735. |
| [5] | 陈薪羽, 刘明哲, 任俊, 汤影. 基于多列卷积神经网络的参数异步更新算法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 395-403. |
| [6] | 曹建荣, 朱亚琴, 张玉婷, 吕俊杰, 杨红娟. 基于关节点特征的跌倒检测算法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 622-630. |
| [7] | 李俊伯, 秦品乐, 曾建潮, 李萌. 基于超分辨率网络的CT三维重建算法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 584-591. |
| [8] | 彭宇, 李晓瑜, 胡世杰, 刘晓磊, 钱伟中. 基于BERT的三阶段式问答模型[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 64-70. |
| [9] | 邓爽, 何小海, 卿粼波, 陈洪刚, 滕奇志. 基于改进VGG网络的弱监督细粒度阿尔兹海默症分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 302-309. |
| [10] | 马敬奇, 雷欢, 陈敏翼. 基于AlphaPose优化模型的老人跌倒行为检测算法[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 294-301. |
| [11] | 吴洁, 张师天, 谢海滨, 杨光. 基于多影像中心磁共振成像数据的半监督膝盖异常分类[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 316-324. |
| [12] | 陈成瑞, 孙宁, 何世彪, 廖勇. 面向C-V2X通信的基于深度学习的联合信道估计与均衡算法[J]. 计算机应用, 2021, 41(9): 2687-2693. |
| [13] | 郑志强, 胡鑫, 翁智, 王雨禾, 程曦. 基于改进DenseNet的牛眼图像特征提取方法[J]. 计算机应用, 2021, 41(9): 2780-2784. |
| [14] | 赵宏, 孔东一. 图像特征注意力与自适应注意力融合的图像内容中文描述[J]. 计算机应用, 2021, 41(9): 2496-2503. |
| [15] | 徐江浪, 李林燕, 万新军, 胡伏原. 结合目标检测的室内场景识别方法[J]. 计算机应用, 2021, 41(9): 2720-2725. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||