《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (5): 1317-1323.DOI: 10.11772/j.issn.1001-9081.2021030489
• 人工智能 • 下一篇
Xianfeng YANG1( ), Jiahe ZHAO1, Ziqiang LI2
), Jiahe ZHAO1, Ziqiang LI2
摘要:
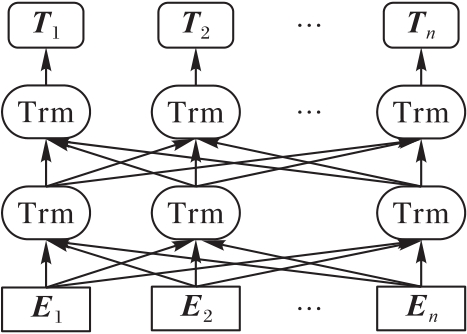
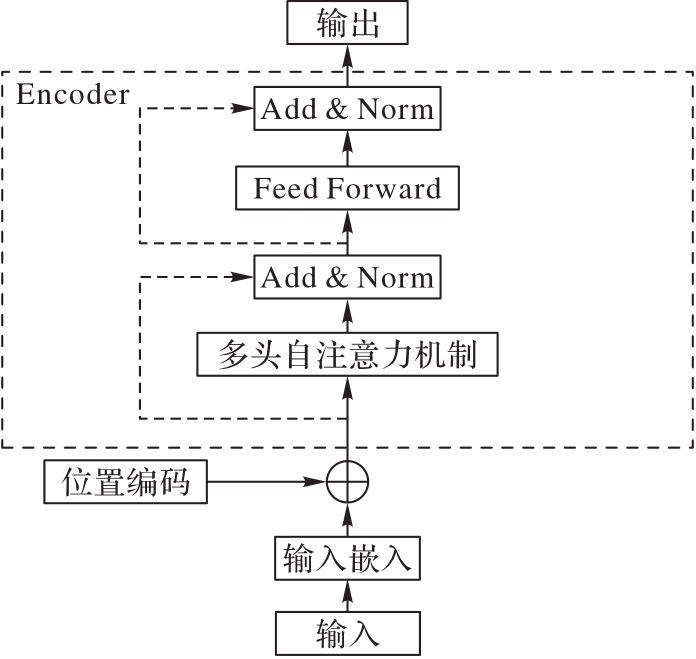
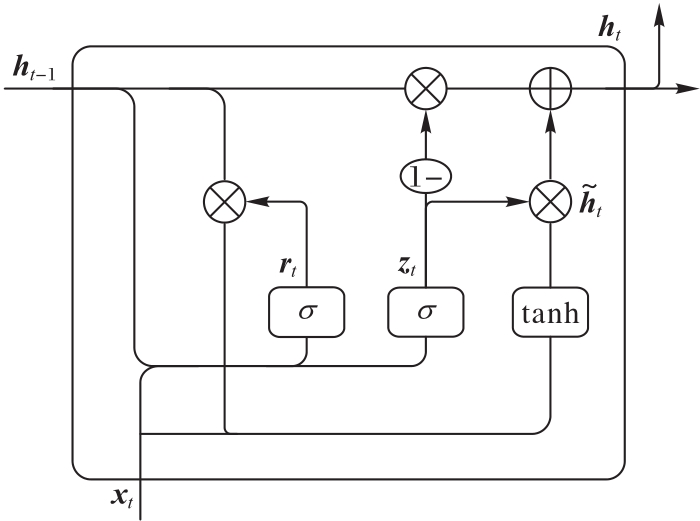
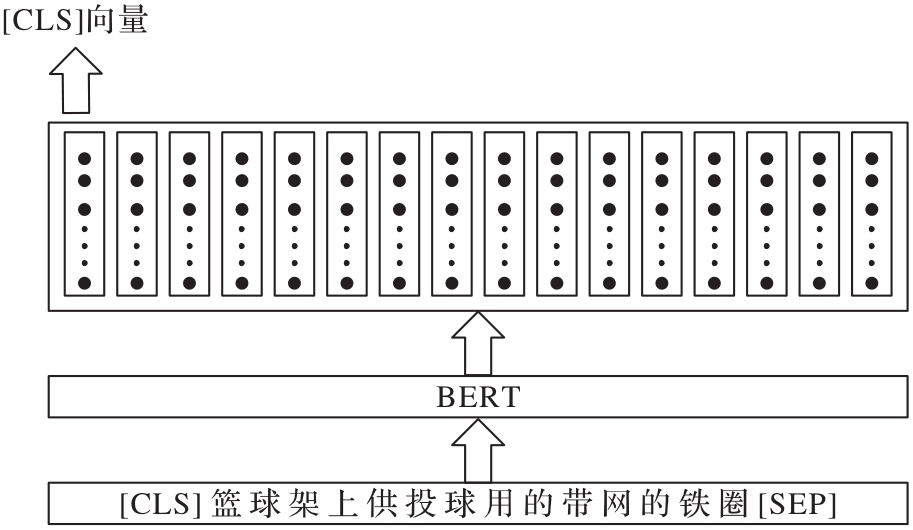
针对传统文本特征表示方法无法充分解决一词多义的问题,构建了一种融合字注释的文本分类模型。首先,借助现有中文字典,获取文本由字上下文选取的字典注释,并对其进行Transformer的双向编码器(BERT)编码来生成注释句向量;然后,将注释句向量与字嵌入向量融合作为输入层,并用来丰富输入文本的特征信息;最后,通过双向门控循环单元(BiGRU)学习文本的特征信息,并引入注意力机制突出关键特征向量。在公开数据集THUCNews和新浪微博情感分类数据集上进行的文本分类的实验结果表明,融合BERT字注释的文本分类模型相较未引入字注释的文本分类模型在性能上有显著提高,且在所有文本分类的实验模型中,所提出的BERT字注释_BiGRU_Attention模型有最高的精确率和召回率,能反映整体性能的F1-Score则分别高达98.16%和96.52%。
中图分类号: