


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (5): 1407-1416.DOI: 10.11772/j.issn.1001-9081.2021030533
收稿日期:2021-04-08
修回日期:2021-06-17
接受日期:2021-06-17
发布日期:2022-06-11
出版日期:2022-05-10
通讯作者:
赵海涛
作者简介:庄屹(1996—),男,上海人,硕士研究生,主要研究方向:目标检测、目标跟踪Received:2021-04-08
Revised:2021-06-17
Accepted:2021-06-17
Online:2022-06-11
Published:2022-05-10
Contact:
Haitao ZHAO
About author:ZHUANG Yi, born in 1996, M. S. candidate. His research interests include object detection, object tracking.摘要:
与二维可见光图像相比,三维点云在空间中保留了物体真实丰富的几何信息,能够应对单目标跟踪问题中存在尺度变换的视觉挑战。针对三维目标跟踪精度受到点云数据稀疏性导致的信息缺失影响,以及物体位置变化带来的形变影响这两个问题,在端到端的学习模式下提出了由三个模块构成的提案聚合网络,通过在最佳提案内定位物体的中心来确定三维边界框从而实现三维点云中的单目标跟踪。首先,将模板和搜索区域的点云数据转换为鸟瞰伪图,模块一通过空间和跨通道注意力机制丰富特征信息;然后,模块二用基于锚框的深度互相关孪生区域提案子网给出最佳提案;最后,模块三先利用最佳提案对搜索区域的感兴趣区域池化操作来提取目标特征,随后聚合了目标与模板特征,利用稀疏调制可变形卷积层来解决点云稀疏以及形变的问题并确定了最终三维边界框。在KITTI跟踪数据集上把所提方法与最新的三维点云单目标跟踪方法进行比较的实验结果表明:在汽车类综合性实验中,真实场景中所提方法在成功率上提高了1.7个百分点,精确率上提高了0.2个百分点;在多类别扩展性实验上,即在汽车、货车、骑车人以及行人这4类上所提方法的平均成功率提高了0.8个百分点,平均精确率提高了2.8个百分点。可见,所提方法能够解决三维点云中的单目标跟踪问题,使得三维目标跟踪结果更加精确。
中图分类号:
庄屹, 赵海涛. 面向三维点云单目标跟踪的提案聚合网络[J]. 计算机应用, 2022, 42(5): 1407-1416.
Yi ZHUANG, Haitao ZHAO. Proposal-based aggregation network for single object tracking in 3D point cloud[J]. Journal of Computer Applications, 2022, 42(5): 1407-1416.
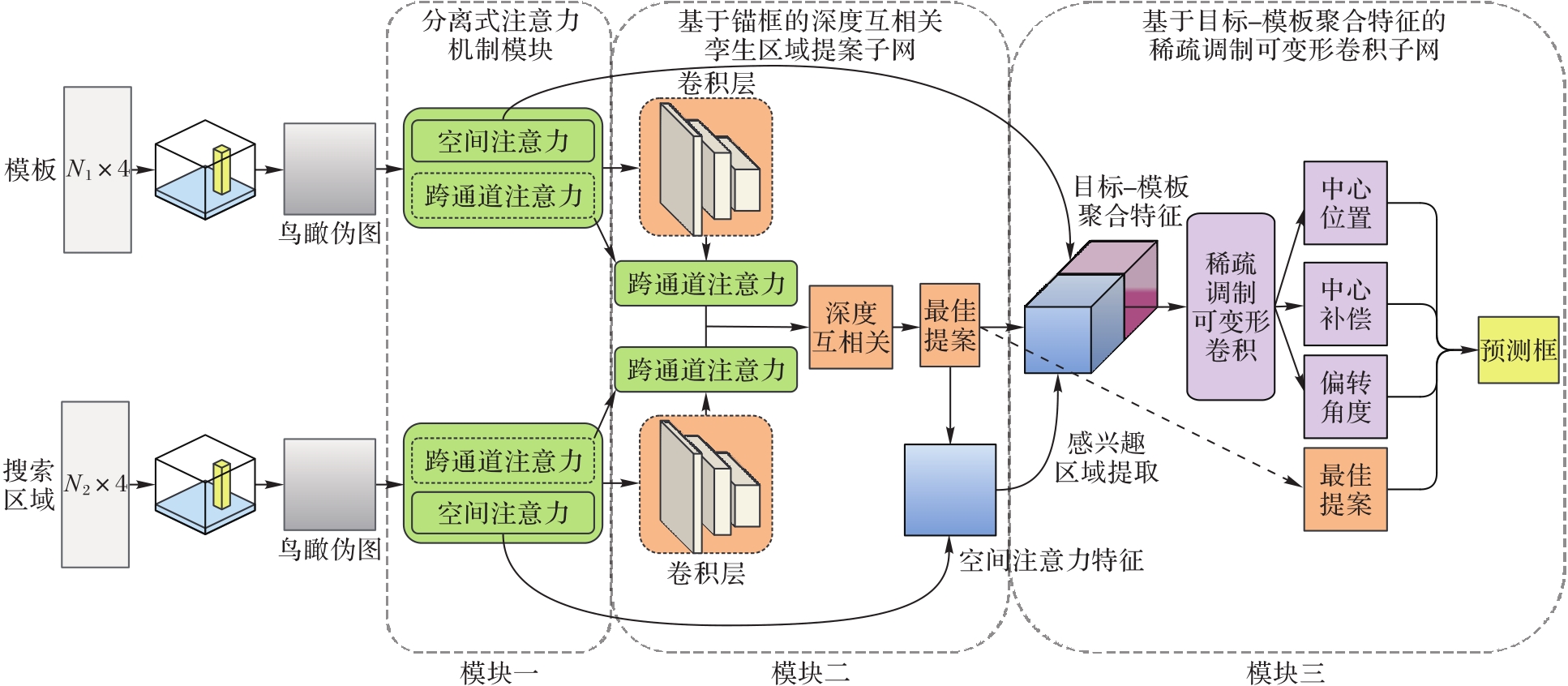
图1 提案聚合网络(PA-Net)的整体结构
Fig. 1 Overall structure of Proposal-based Aggregation Network (PA-Net)

图2 点云栅格化特征提取
Fig. 2 Rasterized feature extraction for point cloud
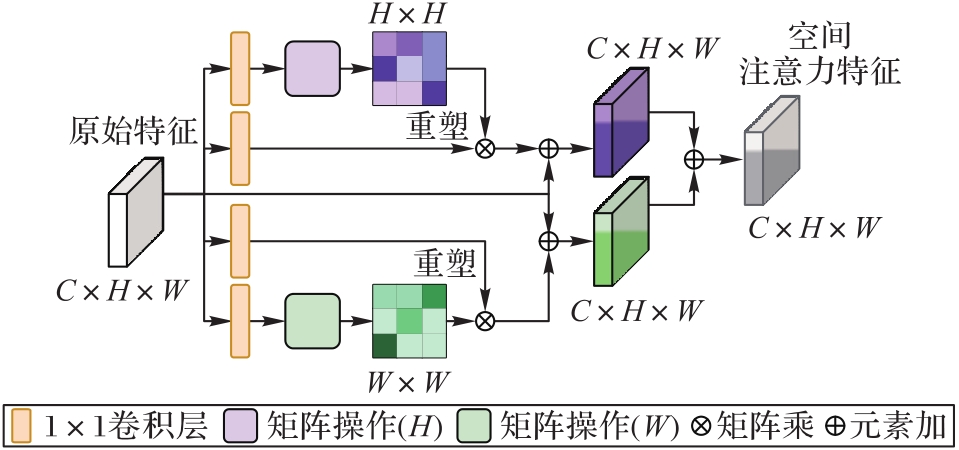
图3 空间注意力机制模块结构
Fig. 3 Structure of spatial attention mechanism module
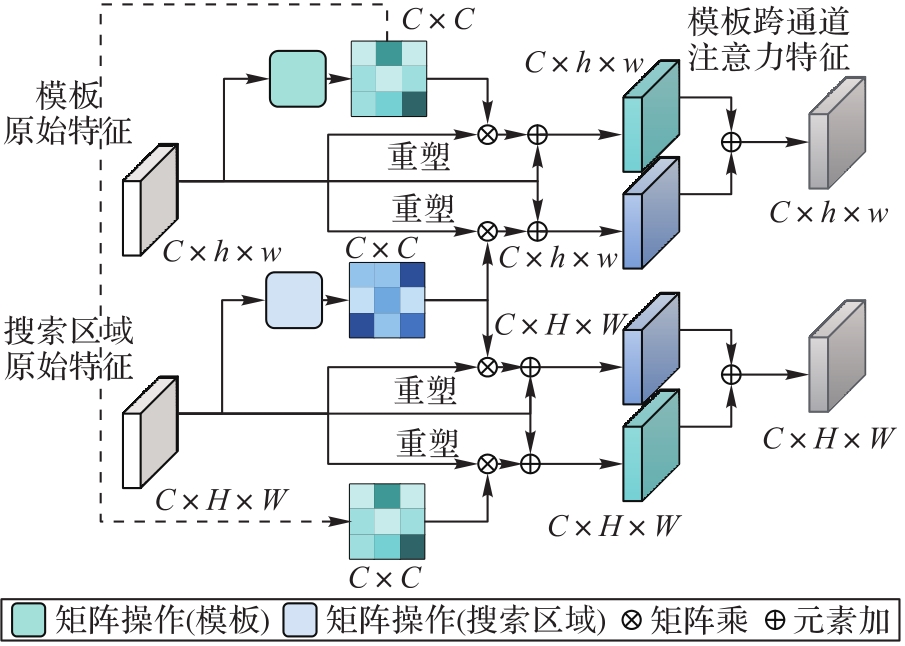
图4 跨通道注意力机制模块结构
Fig. 4 Structure of cross-channel attention mechanism module

图5 卷积与深度互相关示意图
Fig. 5 Schematic diagram of convolution and deep cross-correlation
| 模块 | 参数 |
|---|---|
| 卷积块1 | Conv2D(64,128,3,2,1) |
| Conv2D(128,128,3,1,1)*3 | |
| BatchNorm2D(128,128) | |
| ReLU | |
| 卷积块2 | Conv2D(128,128,3,2,1) |
| Conv2D(128,128,3,1,1)*5 | |
| BatchNorm2D(128,128) | |
| ReLU | |
| 卷积块3 | Conv2D(128,256,3,2,1) |
| Conv2D(256,256,3,1,1)*5 | |
| BatchNorm2D(256,256) | |
| ReLU | |
| 上采样块1 | Deconv2D(128,256,1,1,0) |
| 上采样块2 | Deconv2D(128,256,2,2,0) |
| 上采样块3 | Deconv2D(256,256,4,4,0) |
| 分类融合卷积块 | Conv2D(256,2,1,1,0)(用于3个分辨率) |
| Concatenate(拼接3个分辨率结果) | |
| Conv2D(6,2,1,1,0) | |
| Sigmoid | |
| 锚框偏移融合卷积块 | Conv2D(256,4,1,1,0)(用于3个分辨率) |
| Concatenate(拼接3个分辨率结果) | |
| Conv2D(12,4,1,1,0) |
表1 卷积模块参数设置
Tab. 1 Parameter setting of convolution modules
| 模块 | 参数 |
|---|---|
| 卷积块1 | Conv2D(64,128,3,2,1) |
| Conv2D(128,128,3,1,1)*3 | |
| BatchNorm2D(128,128) | |
| ReLU | |
| 卷积块2 | Conv2D(128,128,3,2,1) |
| Conv2D(128,128,3,1,1)*5 | |
| BatchNorm2D(128,128) | |
| ReLU | |
| 卷积块3 | Conv2D(128,256,3,2,1) |
| Conv2D(256,256,3,1,1)*5 | |
| BatchNorm2D(256,256) | |
| ReLU | |
| 上采样块1 | Deconv2D(128,256,1,1,0) |
| 上采样块2 | Deconv2D(128,256,2,2,0) |
| 上采样块3 | Deconv2D(256,256,4,4,0) |
| 分类融合卷积块 | Conv2D(256,2,1,1,0)(用于3个分辨率) |
| Concatenate(拼接3个分辨率结果) | |
| Conv2D(6,2,1,1,0) | |
| Sigmoid | |
| 锚框偏移融合卷积块 | Conv2D(256,4,1,1,0)(用于3个分辨率) |
| Concatenate(拼接3个分辨率结果) | |
| Conv2D(12,4,1,1,0) |
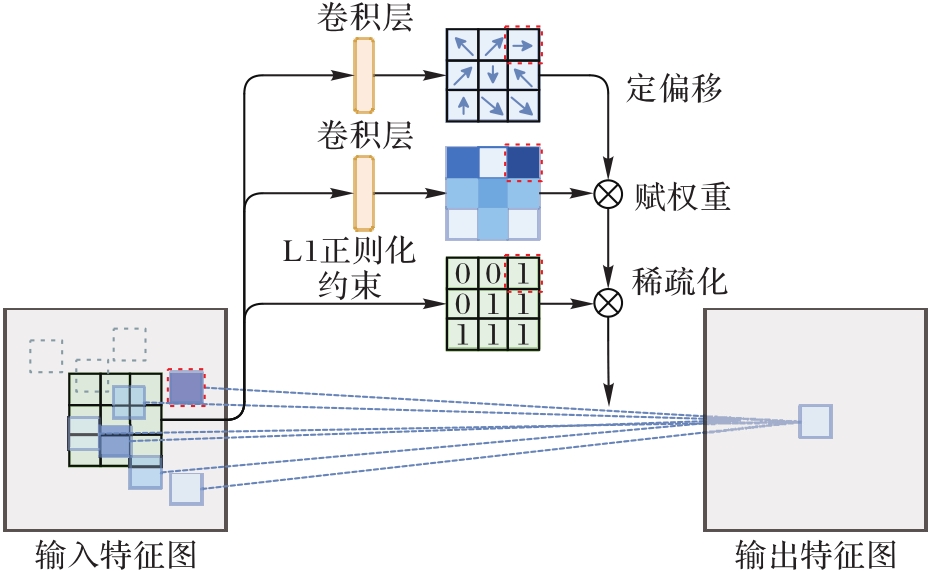
图6 稀疏调制可变形卷积结构
Fig. 6 Structure of sparse modulated deformable convolution

图7 模板点云合并采样的融合结果(汽车)
Fig. 7 Fusion result of merged sampling oftemplate point cloud(Car)
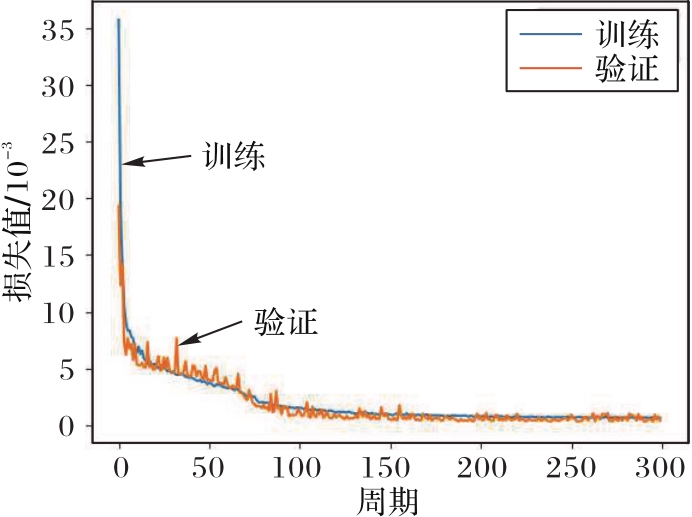
图8 训练与验证中的损失函数曲线
Fig. 8 Curves of loss in training and validation
| 方法 | 成功率/% | 精确率/% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| SC3D | 2D-SC3D | P2B | 3D-SiamRPN | PA-Net | SC3D | 2D-SC3D | P2B | 3D-SiamRPN | PA-Net | |
| 前一帧预测 | 41.3 | 36.2 | 56.2 | 57.3 | 59.0 | 57.9 | 51.0 | 72.8 | 75.0 | 75.2 |
| 前一帧GT | 64.6 | — | 82.4 | — | 85.5 | 74.5 | — | 90.1 | — | 91.8 |
| 当前帧GT | 76.9 | — | 84.0 | — | 89.4 | 81.3 | — | 90.3 | — | 93.2 |
表2 汽车类上不同方法的综合性实验结果
Tab. 2 Comprehensive experimental results of different methods on Car
| 方法 | 成功率/% | 精确率/% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| SC3D | 2D-SC3D | P2B | 3D-SiamRPN | PA-Net | SC3D | 2D-SC3D | P2B | 3D-SiamRPN | PA-Net | |
| 前一帧预测 | 41.3 | 36.2 | 56.2 | 57.3 | 59.0 | 57.9 | 51.0 | 72.8 | 75.0 | 75.2 |
| 前一帧GT | 64.6 | — | 82.4 | — | 85.5 | 74.5 | — | 90.1 | — | 91.8 |
| 当前帧GT | 76.9 | — | 84.0 | — | 89.4 | 81.3 | — | 90.3 | — | 93.2 |
| 类别 | 帧数 | 成功率/% | 精确率/% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SC3D | 2D-SC3D | P2B | 3D-SiamRPN | PA-Net | SC3D | 2D-SC3D | P2B | 3D-SiamRPN | PA-Net | ||
| 均值 | 30.0 | 26.6 | 42.4 | 46.7 | 47.5 | 46.7 | 43.6 | 60.0 | 64.9 | 67.7 | |
| 汽车 | 6 424 | 41.3 | 36.2 | 56.2 | 57.3 | 59.0 | 57.9 | 51.0 | 72.8 | 75.0 | 75.2 |
| 货车 | 1 248 | 40.4 | — | 40.8 | 45.7 | 51.2 | 47.0 | — | 48.4 | 52.8 | 62.8 |
| 骑车人 | 308 | 41.5 | 43.2 | 32.1 | 36.1 | 55.8 | 70.4 | 81.2 | 44.7 | 49.0 | 78.4 |
| 行人 | 6 088 | 18.2 | 17.9 | 28.7 | 35.2 | 38.4 | 37.8 | 47.8 | 49.6 | 56.2 | 66.2 |
表3 不同方法的多类别扩展性实验结果
Tab. 3 Extensive experimental results on different categories of different methods
| 类别 | 帧数 | 成功率/% | 精确率/% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SC3D | 2D-SC3D | P2B | 3D-SiamRPN | PA-Net | SC3D | 2D-SC3D | P2B | 3D-SiamRPN | PA-Net | ||
| 均值 | 30.0 | 26.6 | 42.4 | 46.7 | 47.5 | 46.7 | 43.6 | 60.0 | 64.9 | 67.7 | |
| 汽车 | 6 424 | 41.3 | 36.2 | 56.2 | 57.3 | 59.0 | 57.9 | 51.0 | 72.8 | 75.0 | 75.2 |
| 货车 | 1 248 | 40.4 | — | 40.8 | 45.7 | 51.2 | 47.0 | — | 48.4 | 52.8 | 62.8 |
| 骑车人 | 308 | 41.5 | 43.2 | 32.1 | 36.1 | 55.8 | 70.4 | 81.2 | 44.7 | 49.0 | 78.4 |
| 行人 | 6 088 | 18.2 | 17.9 | 28.7 | 35.2 | 38.4 | 37.8 | 47.8 | 49.6 | 56.2 | 66.2 |
| 特征丰富层 | 聚合回归层 | 成功率 | 精确率 |
|---|---|---|---|
| 无注意力机制 | 传统卷积 | 52.2 | 62.3 |
| 并行式注意力机制 | 传统卷积 | 54.3 | 64.0 |
| 分离式注意力机制 | 传统卷积 | 54.4 | 68.8 |
| 分离式注意力机制 | 调制可变性卷积 | 58.8 | 74.9 |
| 分离式注意力机制 | 稀疏调制可变性卷积 | 59.0 | 75.2 |
表4 PA-Net在汽车类上特征丰富层与聚合回归层的消融实验结果 (%)
Tab. 4 Ablation experimental results of PA-Net in feature enriching layer and aggregated regression layer on Car
| 特征丰富层 | 聚合回归层 | 成功率 | 精确率 |
|---|---|---|---|
| 无注意力机制 | 传统卷积 | 52.2 | 62.3 |
| 并行式注意力机制 | 传统卷积 | 54.3 | 64.0 |
| 分离式注意力机制 | 传统卷积 | 54.4 | 68.8 |
| 分离式注意力机制 | 调制可变性卷积 | 58.8 | 74.9 |
| 分离式注意力机制 | 稀疏调制可变性卷积 | 59.0 | 75.2 |
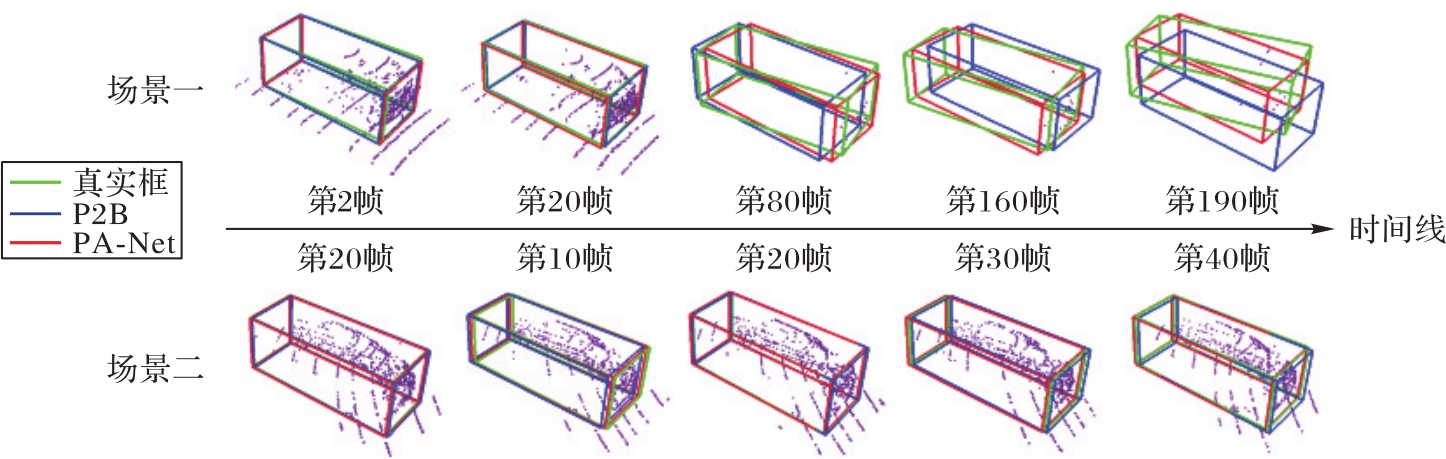
图9 汽车类上PA-Net与P2B的跟踪结果可视化对比
Fig. 9 Visual comparison of PA-Net and P2B tracking results on Car
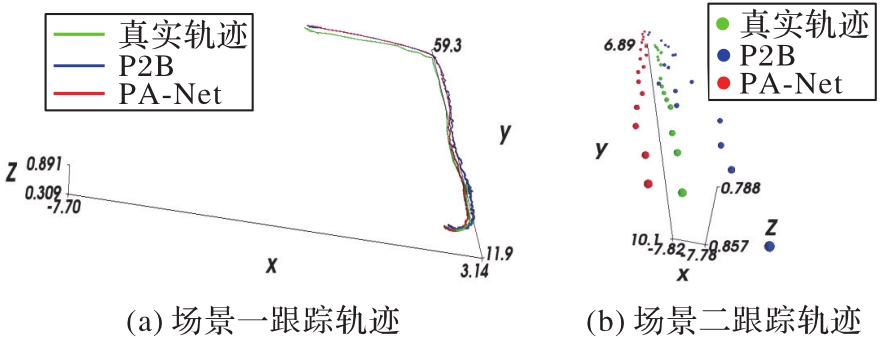
图10 汽车类上PA-Net与P2B的跟踪轨迹
Fig. 10 Tracking trajectories of PA-Net and P2B on Car

图11 不同特征丰富层作用下的分类热力图
Fig. 11 Classification heat maps with different feature enriching layers
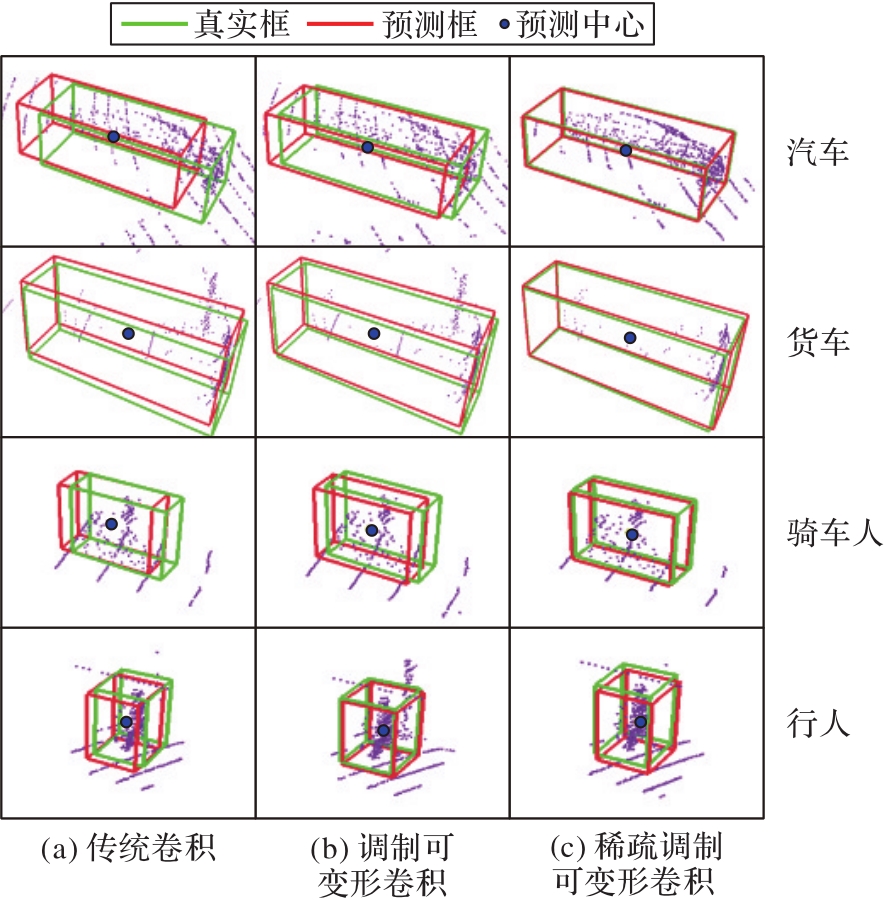
图12 不同输出层作用下的物体边界框以及中心预测
Fig. 12 Prediction of object bounding box and center with different output layers
| 回归对象 | 预测值 | |
|---|---|---|
| 中心位置 | 提案前景最优置信度 | 0.987 |
| 回归值/m | [2.500 5,11.901 0,0.752 1] | |
| 中心补偿 | 中心前景最优置信度 | 0.945 |
| 补偿值/m | [0.034 8,0.195 4,0.015 3] | |
| 预测中心/m | [2.535 3,12.096 4,0.767 4] | |
| 真实中心/m | [2.289 0,12.072 6,0.764 7] | |
| 中心偏差/m | [0.246 3,0.023 8,0.002 7] | |
| 预测偏转角度/rad | 0.048 7 | |
| 真实偏转角度/rad | 0.058 6 | |
| 角度偏差/rad | ||
表5 中心位置与偏转角度预测的结果
Tab. 5 Results of predicted center position and deflection angle
| 回归对象 | 预测值 | |
|---|---|---|
| 中心位置 | 提案前景最优置信度 | 0.987 |
| 回归值/m | [2.500 5,11.901 0,0.752 1] | |
| 中心补偿 | 中心前景最优置信度 | 0.945 |
| 补偿值/m | [0.034 8,0.195 4,0.015 3] | |
| 预测中心/m | [2.535 3,12.096 4,0.767 4] | |
| 真实中心/m | [2.289 0,12.072 6,0.764 7] | |
| 中心偏差/m | [0.246 3,0.023 8,0.002 7] | |
| 预测偏转角度/rad | 0.048 7 | |
| 真实偏转角度/rad | 0.058 6 | |
| 角度偏差/rad | ||
| 方法 | 预处理/ms | 模型推理/ms | 后处理/ms | 总时长/ms | 帧率/(frame·s-1) |
|---|---|---|---|---|---|
| P2B | 7.0 | 14.3 | 0.9 | 22.2 | 45.0 |
| 3D-SiamRPN | 0.5 | 40.7 | 7.2 | 48.0 | 20.8 |
| PA-Net | 35.0 | 5.6 | 0.3 | 40.9 | 24.4 |
表6 不同方法在汽车类上的运行速度
Tab. 6 Running speeds of different methods on Car
| 方法 | 预处理/ms | 模型推理/ms | 后处理/ms | 总时长/ms | 帧率/(frame·s-1) |
|---|---|---|---|---|---|
| P2B | 7.0 | 14.3 | 0.9 | 22.2 | 45.0 |
| 3D-SiamRPN | 0.5 | 40.7 | 7.2 | 48.0 | 20.8 |
| PA-Net | 35.0 | 5.6 | 0.3 | 40.9 | 24.4 |
| 1 | SMEULDERS A W M, CHU D M, CUCCHIARA R, et al. Visual tracking: an experimental survey [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1442-1468. 10.1109/tpami.2013.230 |
| 2 | SHAO L, SHAH P, DWARACHERLA V, et al. Motion-based object segmentation based on dense RGB-D scene flow [J]. IEEE Robotics and Automation Letters, 2018, 3(4): 3797-3804. 10.1109/lra.2018.2856525 |
| 3 | ZHOU Y, WANG T, HU R H, et al. Multiple Kernelized Correlation Filters (MKCF) for extended object tracking using X-band marine radar data [J]. IEEE Transactions on Signal Processing, 2019, 67(14): 3676-3688. 10.1109/tsp.2019.2917812 |
| 4 | LI C L, ZHU C L, HUANG Y, et al. Cross-modal ranking with soft consistency and noisy labels for robust RGB-T tracking [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11217. Cham: Springer, 2018: 831-847. |
| 5 | ZHU Y B, LI C L, TANG J, et al. Quality-aware feature aggregation network for robust RGBT tracking [J]. IEEE Transactions on Intelligent Vehicles, 2021, 6(1): 121-130. 10.1109/tiv.2020.2980735 |
| 6 | 王红艳,郑伶杰,陈献娜.简述激光雷达点云数据的处理应用[J].资源导刊,2015(S2):44-45. 10.3969/j.issn.1674-053X.2015.z2.022 |
| WANG H Y, ZHENG L J, CHEN X N. Brief introduction of the processing application of the point cloud data of lidar [J]. Resources Guide, 2015(S2): 44-45. 10.3969/j.issn.1674-053X.2015.z2.022 | |
| 7 | GIANCOLA S, ZARZAR J, GHANEM B. Leveraging shape completion for 3D Siamese tracking [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1359-1368. 10.1109/cvpr.2019.00145 |
| 8 | QI H Z, FENG C, CAO Z G, et al. P2B: point-to-box network for 3D object tracking in point clouds [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6328-6337. 10.1109/CVPR42600.2020.00636 |
| 9 | QI C H, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space [C]// Proceedings of the 2017 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 5105-5114. |
| 10 | QI C H, LITANY O, HE K M, et al. Deep Hough voting for 3D object detection in point clouds [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9276-9285. 10.1109/iccv.2019.00937 |
| 11 | FANG Z, ZHOU S F, CUI Y B, et al. 3D-SiamRPN: an end-to-end learning method for real-time 3D single object tracking using raw point cloud [J]. IEEE Sensors Journal, 2021, 21(4): 4995-5011. 10.1109/jsen.2020.3033034 |
| 12 | ZARZAR J, GIANCOLA S, GHANEM B. Efficient tracking proposals using 2D-3D Siamese networks on LIDAR [EB/OL]. [2021-02-13]. . |
| 13 | LI B, YAN J J, WU W, et al. High performance visual tracking with Siamese region proposal network [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8971-8980. 10.1109/cvpr.2018.00935 |
| 14 | LI B, WU W, WANG Q, et al. SiamRPN++: evolution of Siamese visual tracking with very deep networks [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 4277-4286. 10.1109/cvpr.2019.00441 |
| 15 | ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4490-4499. 10.1109/cvpr.2018.00472 |
| 16 | YAN Y, MAO Y X, LI B. SECOND: sparsely embedded convolutional detection [J]. Sensors, 2018, 18(10): Article No.3337. 10.3390/s18103337 |
| 17 | LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12689-12697. 10.1109/cvpr.2019.01298 |
| 18 | NAM H, HA J W, KIM J. Dual attention networks for multimodal reasoning and matching [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2156-2164. 10.1109/cvpr.2017.232 |
| 19 | FU J, LIU J, TIAN H J, et al. Dual attention network for scene segmentation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3141-3149. 10.1109/cvpr.2019.00326 |
| 20 | DAI J F, QI H Z, XIONG Y W, et al. Deformable convolutional networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 764-773. 10.1109/iccv.2017.89 |
| 21 | ZHU X Z, HU H, LIN S, et al. Deformable ConvNets v2: more deformable, better results [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 9300-9308. 10.1109/cvpr.2019.00953 |
| 22 | YU Y C, XIONG Y L, HUANG W Let al. Deformable Siamese attention networks for visual object tracking [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6727-6736. 10.1109/cvpr42600.2020.00676 |
| 23 | 尚丽,苏品刚,周燕.基于改进的快速稀疏编码的图像特征提取[J].计算机应用,2013,33(3):656-659. 10.3724/SP.J.1087.2013.00656 |
| SHANG L, SU P G, ZHOU Y. Image feature extraction based on modified fast sparse coding algorithm [J]. Journal of Computer Applications, 2013, 33(3): 656-659. 10.3724/SP.J.1087.2013.00656 | |
| 24 | LIN T Y, GOYAL P, GIRSHICK Ret al. Focal loss for dense object detection [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007. 10.1109/iccv.2017.324 |
| 25 | SHAH J, QURESHI I, DENG Y M, et al. Reconstruction of sparse signals and compressively sampled images based on smooth l1-norm approximation [J]. Journal of Signal Processing Systems, 2017, 88(3): 333-344. 10.1007/s11265-016-1168-8 |
| 26 | GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? the KITTI vision benchmark suite [C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2012: 3354-3361. 10.1109/cvpr.2012.6248074 |
| 27 | WU Y, LIM J, YANG M H. Online object tracking: a benchmark [C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2013: 2411-2418. 10.1109/cvpr.2013.312 |
| 28 | KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2021-02-03]. . |
| [1] | 杨先凤, 赵家和, 李自强. 融合字注释的文本分类模型[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1317-1323. |
| [2] | 陈代丽, 许国良. 基于注意力机制学习域内变化的跨域行人重识别方法[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1391-1397. |
| [3] | 屈震, 李堃婷, 冯志玺. 基于有效通道注意力的遥感图像场景分类[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1431-1439. |
| [4] | 张晔, 刘蓉, 刘明, 陈明. 基于多通道注意力机制的图像超分辨率重建网络[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1563-1569. |
| [5] | 胡鹤轩, 隋华超, 胡强, 张晔, 胡震云, 马能武. 基于图注意力网络与双阶注意力机制的径流预报模型[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1607-1615. |
| [6] | 任炜, 白鹤翔. 基于全局与局部标签关系的多标签图像分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1383-1390. |
| [7] | 董永峰, 孙跃华, 高立超, 韩鹏, 季海鹏. 基于改进一维卷积和双向长短期记忆神经网络的故障诊断方法[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1207-1215. |
| [8] | 蒋雯静, 熊熙, 李中志, 李斌勇. 基于无采样协作知识图网络的推荐系统[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1057-1064. |
| [9] | 张锦, 屈佩琪, 孙程, 罗蒙. 基于改进YOLOv5的安全帽佩戴检测算法[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1292-1300. |
| [10] | 胡新荣, 张君宇, 彭涛, 刘军平, 何儒汉, 何凯. 级联跨域特征融合的虚拟试衣[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1269-1274. |
| [11] | 刘志华, 陈文洁, 陈爱斌. 基于自注意力机制时频谱同源特征融合的鸟鸣声分类[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1260-1268. |
| [12] | 顾军华, 王锐, 李宁宁, 张素琪. 融合协同过滤信息的知识图注意力网络[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1087-1092. |
| [13] | 黄勇康, 梁美玉, 王笑笑, 陈徵, 曹晓雯. 基于深度时空残差卷积神经网络的课堂教学视频中多人课堂行为识别[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 736-742. |
| [14] | 罗圣钦, 陈金怡, 李洪均. 基于注意力机制的多尺度残差UNet实现乳腺癌灶分割[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 818-824. |
| [15] | 朱文球, 邹广, 曾志高. 融合层次特征和混合注意力的目标跟踪算法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 833-843. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
