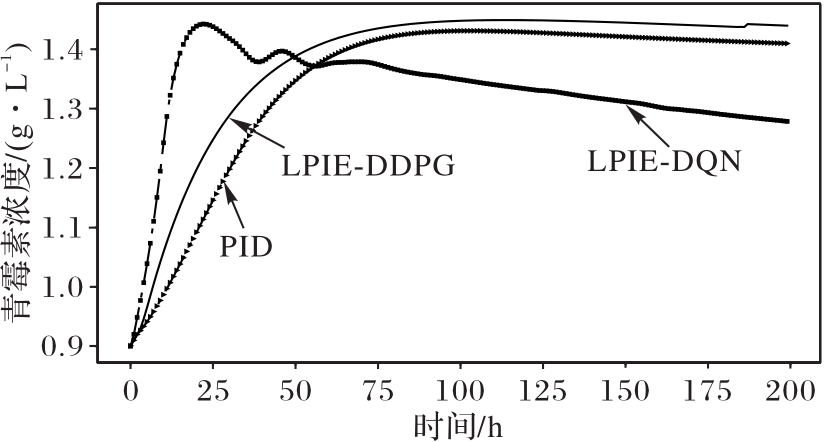
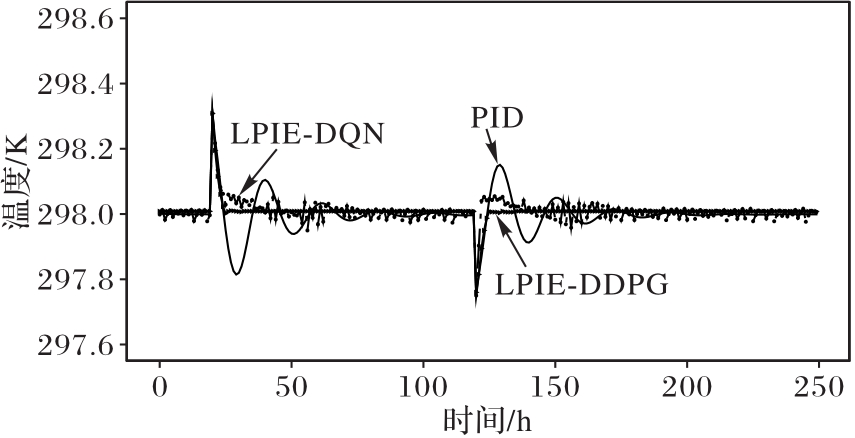
| 1 |
BANSAL V, PERKINS J D, PISTIKOPOULOS E N. A case study in simultaneous design and control using rigorous, mixed-integer dynamic optimization models [J]. Industrial and Engineering Chemistry Research, 2002, 41(4): 760-778. 10.1021/ie010156n
|
| 2 |
ASTEASUAIN M, BANDONI A, SARMORIA C, et al. Simultaneous process and control system design for grade transition in styrene polymerization [J]. Chemical Engineering Science, 2006, 61(10): 3362-3378. 10.1016/j.ces.2005.12.012
|
| 3 |
赵海丞,邹应全,刘睿佳,等.温控系统中变调节周期PID算法[J].计算机应用,2016,36(S2):116-119.
|
|
ZHAO H C, ZOU Y Q, LIU R J, et al. PID algorithm of variable adjustment period based on temperature control system [J]. Journal of Computer Applications, 2016, 36(S2): 116-119.
|
| 4 |
包元兴,丁炯,杨遂军,等.强耦合双通道热分析炉温度跟随控制策略研究[J].测控技术,2016,35(5):70-74. 10.3969/j.issn.1000-8829.2016.05.018
|
|
BAO Y X, DING J, YANG S J, et al. Study on temperature following control strategy for strong-coupled dual-channel thermal analysis furnace [J]. Measurement and Control Technology, 2016, 35(5): 70-74. 10.3969/j.issn.1000-8829.2016.05.018
|
| 5 |
吴鹏松,吴朝野,周东华.大纯滞后信号解耦内模控制系统研究[J].化工自动化及仪表,2012,39(9):1115-1117,1176. 10.3969/j.issn.1000-3932.2012.09.002
|
|
WU P S, WU C Y, ZHOU D H. Research on signal-decoupling internal mode control system with big time lag [J]. Control and Instruments in Chemical Industry, 2012, 39(9): 1115-1117, 1176. 10.3969/j.issn.1000-3932.2012.09.002
|
| 6 |
张惠琳,李醒飞,杨少波,等.深海自持式智能浮标双闭环模糊PID定深控制[J].信息与控制,2019,48(2):202-208,216.
|
|
ZHANG H L, LI X F, YANG S B, et al. Dual closed-loop fuzzy PID depth control for deep-sea self-holding intelligent buoy [J]. Information and Control, 2019, 48(2): 202-208, 216.
|
| 7 |
庄绪君,李宏光.基于遗传算法与迭代动态规划混合策略的青霉素发酵过程优化控制[J].计算机与应用化学,2013,30(9):1051-1054. 10.3969/j.issn.1001-4160.2013.09.021
|
|
ZHUANG X J, LI H G. Optimization control strategies combined genetic algorithms and iterative dynamic programming for penicillin fermentation processes [J]. Computers and Applied Chemistry, 2013, 30(9): 1051-1054. 10.3969/j.issn.1001-4160.2013.09.021
|
| 8 |
郝鹃,余建军,周文慧.基于平均强化学习的订单生产方式企业订单接受策略[J].计算机应用,2013,33(4):976-979. 10.3724/sp.j.1087.2013.00976
|
|
HAO J, YU J J, ZHOU W H. Order acceptance policy in make-to-order manufacturing based on average-reward reinforcement learning [J]. Journal of Computer Applications, 2013, 33(4): 976-979. 10.3724/sp.j.1087.2013.00976
|
| 9 |
王建平,王刚,毛晓彬,等.基于深度强化学习的二连杆机械臂运动控制方法[J].计算机应用,2021,41(6):1799-1804.
|
|
WANG J P, WANG G, MAO X B, et al. Motion control method of two-link manipulator based on deep reinforcement learning [J]. Journal of Computer Applications, 2021, 41(6): 1799-1804.
|
| 10 |
多南讯,吕强,林辉灿,等.迈进高维连续空间:深度强化学习在机器人领域中的应用[J].机器人,2019,41(2):276-288.
|
|
DUO N X, LYU Q, LIN H C, et al. Step into high-dimensional and continuous action space: a survey on applications of deep reinforcement learning to robotics [J]. Robot, 2019, 41(2): 276-288.
|
| 11 |
刘洋,李建军.深度确定性策略梯度算法优化[J].辽宁工程技术大学学报(自然科学版),2020,39(6):545-549. 10.1016/j.cie.2021.107621
|
|
LIU Y, LI J J. Optimization of deep deterministic policy gradient algorithm [J]. Journal of Liaoning Technical University (Natural Science), 2020, 39(6):545-549. 10.1016/j.cie.2021.107621
|
| 12 |
HOU Y N, LIU L F, WEI Q, et al. A novel DDPG method with prioritized experience replay [C]// Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics. Piscataway: IEEE, 2017: 316-321. 10.1109/smc.2017.8122622
|
| 13 |
NIAN R, LIU J F, HUANG B. A review on reinforcement learning: Introduction and applications in industrial process control [J]. Computers and Chemical Engineering, 2020, 139: Article No.106886. 10.1016/j.compchemeng.2020.106886
|
| 14 |
李云龙,唐文俊,白成海,等.青霉素生产工艺优化及代谢分析提高产量[J].中国抗生素杂志,2019,44(6):679-686. 10.3969/j.issn.1001-8689.2019.06.006
|
|
LI Y L, TANG W J, BAI C H, et al. Optimization of the feeding process and metabolism analysis to improve the yield of penicillin [J]. Chinese Journal of Antibiotics, 2019, 44(6): 679-686. 10.3969/j.issn.1001-8689.2019.06.006
|
| 15 |
王蕾,陈进东,潘丰.引力搜索算法在青霉素发酵模型参数估计中的应用[J].计算机应用,2013,33(11):3296-3299,3304. 10.3724/sp.j.1087.2013.03296
|
|
WANG L, CHEN J D, PAN F. Applications of gravitational search algorithm in parameters estimation of penicillin fermentation process model [J]. Journal of Computer Applications, 2013, 33(11): 3296-3299, 3304. 10.3724/sp.j.1087.2013.03296
|
| 16 |
叶凌箭,程江华.基于Matlab/Simulink的青霉素发酵过程仿真平台[J].系统仿真学报,2015,27(3):515-520.
|
|
YE L J, CHENG J H. Simulation platform of penicillin fermentation process based on Matlab/Simulink [J]. Journal of System Simulation, 2015, 27(3): 515-520.
|


 ), 李帅1,2,3,4, 刘舒锐1,2,3
), 李帅1,2,3,4, 刘舒锐1,2,3