


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (5): 1455-1463.DOI: 10.11772/j.issn.1001-9081.2021050736
刘学文1, 王继奎1( ), 杨正国1, 李强1,2, 易纪海1, 李冰1, 聂飞平3
), 杨正国1, 李强1,2, 易纪海1, 李冰1, 聂飞平3
收稿日期:2021-05-10
修回日期:2021-09-19
接受日期:2021-10-14
发布日期:2022-03-08
出版日期:2022-05-10
通讯作者:
王继奎
作者简介:刘学文(1996—),男,江西赣州人,硕士研究生,主要研究方向:机器学习、人工智能基金资助:
Xuewen LIU1, Jikui WANG1(), Zhengguo YANG1, Qiang LI1,2, Jihai YI1, Bing LI1, Feiping NIE3
Received:2021-05-10
Revised:2021-09-19
Accepted:2021-10-14
Online:2022-03-08
Published:2022-05-10
Contact:
Jikui WANG
About author:LIU Xuewen, born in 1996, M. S. candidate. His researchinterests include machine learning,artificial intelligence.Supported by:摘要:
在集成算法中嵌入代价敏感和重采样方法是一种有效的不平衡数据分类混合策略。针对现有混合方法中误分代价计算和欠采样过程较少考虑样本的类内与类间分布的问题,提出了一种密度峰值优化的球簇划分欠采样不平衡数据分类算法DPBCPUSBoost。首先,利用密度峰值信息定义多数类样本的抽样权重,将存在“近邻簇”的多数类球簇划分为“易误分区域”和“难误分区域”,并提高“易误分区域”内样本的抽样权重;其次,在初次迭代过程中按照抽样权重对多数类样本进行欠采样,之后每轮迭代中按样本分布权重对多数类样本进行欠采样,并把欠采样后的多数类样本与少数类样本组成临时训练集并训练弱分类器;最后,结合样本的密度峰值信息与类别分布为所有样本定义不同的误分代价,并通过代价调整函数增加高误分代价样本的权重。在10个KEEL数据集上的实验结果表明,与现有自适应增强(AdaBoost)、代价敏感自适应增强(AdaCost)、随机欠采样增强(RUSBoost)和代价敏感欠采样自适应增强(USCBoost)等不平衡数据分类算法相比,DPBCPUSBoost在准确率(Accuracy)、F1分数(F1-Score)、几何均值(G-mean)和受试者工作特征(ROC)曲线下的面积(AUC)指标上获得最高性能的数据集数量均多于对比算法。实验结果验证了DPBCPUSBoost中样本误分代价和抽样权重定义的有效性。
中图分类号:
刘学文, 王继奎, 杨正国, 李强, 易纪海, 李冰, 聂飞平. 密度峰值优化的球簇划分欠采样不平衡数据分类算法[J]. 计算机应用, 2022, 42(5): 1455-1463.
Xuewen LIU, Jikui WANG, Zhengguo YANG, Qiang LI, Jihai YI, Bing LI, Feiping NIE. Imbalanced data classification algorithm based on ball cluster partitioning and undersampling with density peak optimization[J]. Journal of Computer Applications, 2022, 42(5): 1455-1463.
| 变量 | 说明 |
|---|---|
1个样本, | |
| 样本 | |
| 样本 | |
| 多数类球簇的易误分区域 | |
| 多数类样本 |
表1 变量及说明
Tab. 1 Variables and descriptions
| 变量 | 说明 |
|---|---|
1个样本, | |
| 样本 | |
| 样本 | |
| 多数类球簇的易误分区域 | |
| 多数类样本 |
| 序号 | 序号 | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 2.985 | 1.462 | 4.364 | 13 | 0.935 | 0.138 | 0.129 |
| 2 | 1.918 | 0.801 | 1.536 | 14 | 1.031 | 0.120 | 0.124 |
| 3 | 2.532 | 0.098 | 0.249 | 15 | 1.699 | 0.072 | 0.122 |
| 4 | 2.128 | 0.113 | 0.240 | 16 | 0.867 | 0.136 | 0.118 |
| 5 | 2.219 | 0.097 | 0.215 | 17 | 0.789 | 0.144 | 0.114 |
| 6 | 1.749 | 0.120 | 0.210 | 18 | 0.817 | 0.135 | 0.110 |
| 7 | 1.720 | 0.107 | 0.184 | 19 | 0.673 | 0.156 | 0.105 |
| 8 | 1.497 | 0.116 | 0.174 | 20 | 0.809 | 0.128 | 0.104 |
| 9 | 1.220 | 0.141 | 0.172 | 21 | 0.449 | 0.147 | 0.066 |
| 10 | 1.716 | 0.081 | 0.139 | 22 | 0.156 | 0.196 | 0.031 |
| 11 | 1.057 | 0.129 | 0.136 | 23 | 0.001 | 0.447 | 0.000 |
| 12 | 1.026 | 0.131 | 0.134 | 24 | 0.000 | 0.601 | 0.000 |
表2 样本信息
Tab. 2 Sample information
| 序号 | 序号 | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 2.985 | 1.462 | 4.364 | 13 | 0.935 | 0.138 | 0.129 |
| 2 | 1.918 | 0.801 | 1.536 | 14 | 1.031 | 0.120 | 0.124 |
| 3 | 2.532 | 0.098 | 0.249 | 15 | 1.699 | 0.072 | 0.122 |
| 4 | 2.128 | 0.113 | 0.240 | 16 | 0.867 | 0.136 | 0.118 |
| 5 | 2.219 | 0.097 | 0.215 | 17 | 0.789 | 0.144 | 0.114 |
| 6 | 1.749 | 0.120 | 0.210 | 18 | 0.817 | 0.135 | 0.110 |
| 7 | 1.720 | 0.107 | 0.184 | 19 | 0.673 | 0.156 | 0.105 |
| 8 | 1.497 | 0.116 | 0.174 | 20 | 0.809 | 0.128 | 0.104 |
| 9 | 1.220 | 0.141 | 0.172 | 21 | 0.449 | 0.147 | 0.066 |
| 10 | 1.716 | 0.081 | 0.139 | 22 | 0.156 | 0.196 | 0.031 |
| 11 | 1.057 | 0.129 | 0.136 | 23 | 0.001 | 0.447 | 0.000 |
| 12 | 1.026 | 0.131 | 0.134 | 24 | 0.000 | 0.601 | 0.000 |
图1 样本分布
Fig. 1 Sample distribution

图2 决策图
Fig. 2 Decision diagram

图3 划分球簇
Fig. 3 Dividing ball clusters
| 数据集(标记) | 样本数 | 属性数 | 不平衡比例 |
|---|---|---|---|
| vehicle3(D1) | 846 | 18 | 2.52 |
| ecoli2(D2) | 336 | 7 | 5.46 |
| yeast_0_5_6_7_9_vs_4(D3) | 528 | 8 | 9.35 |
| ecoli-0-6-7_vs_5(D4) | 220 | 6 | 10.00 |
| yeast_1_vs_7(D5) | 459 | 7 | 13.87 |
| yeast_1_4_5_8_vs_7(D6) | 693 | 8 | 22.10 |
| yeast_2_vs_8(D7) | 482 | 8 | 23.10 |
| yeast6(D8) | 1 484 | 8 | 39.15 |
| poker-8-9_vs_6-5-5tst(D9) | 1 485 | 10 | 58.40 |
| abalone19(D10) | 4 714 | 8 | 128.87 |
表3 实验数据集
Tab. 3 Experimental datasets
| 数据集(标记) | 样本数 | 属性数 | 不平衡比例 |
|---|---|---|---|
| vehicle3(D1) | 846 | 18 | 2.52 |
| ecoli2(D2) | 336 | 7 | 5.46 |
| yeast_0_5_6_7_9_vs_4(D3) | 528 | 8 | 9.35 |
| ecoli-0-6-7_vs_5(D4) | 220 | 6 | 10.00 |
| yeast_1_vs_7(D5) | 459 | 7 | 13.87 |
| yeast_1_4_5_8_vs_7(D6) | 693 | 8 | 22.10 |
| yeast_2_vs_8(D7) | 482 | 8 | 23.10 |
| yeast6(D8) | 1 484 | 8 | 39.15 |
| poker-8-9_vs_6-5-5tst(D9) | 1 485 | 10 | 58.40 |
| abalone19(D10) | 4 714 | 8 | 128.87 |
| 数据集 | AdaBoost | |||
|---|---|---|---|---|
| Accuracy | F1-Score | G-mean | AUC | |
| D1 | 50.71 | 50.83 | 50.94 | 61.96 |
| D2 | 70.34 | 74.49 | 79.15 | 93.51 |
| D3 | 66.84 | 70.09 | 73.66 | 72.53 |
| D4 | 67.44 | 70.99 | 74.95 | 95.00 |
| D5 | 60.60 | 65.60 | 71.50 | 81.76 |
| D6 | 47.81 | 32.35 | 24.44 | 66.92 |
| D7 | 53.26 | 57.70 | 62.94 | 61.68 |
| D8 | 61.63 | 67.71 | 75.11 | 86.55 |
| D9 | 49.08 | 32.92 | 24.77 | 42.12 |
| D10 | 49.64 | 33.17 | 24.91 | 51.59 |
| 数据集 | AdaCost | |||
| Accuracy | F1-Score | G-mean | AUC | |
| D1 | 37.50 | 27.27 | 21.43 | 69.78 |
| D2 | 83.69 | 85.20 | 86.76 | 92.63 |
| D3 | 69.10 | 72.03 | 75.23 | 73.16 |
| D4 | 65.38 | 71.77 | 79.55 | 96.25 |
| D5 | 55.80 | 60.04 | 64.98 | 77.06 |
| D6 | 65.65 | 55.04 | 60.92 | 68.83 |
| D7 | 65.05 | 69.76 | 75.19 | 52.45 |
| D8 | 56.95 | 64.94 | 75.53 | 92.34 |
| D9 | 49.08 | 32.92 | 24.77 | 28.01 |
| D10 | 50.31 | 54.41 | 59.25 | 60.17 |
表4 AdaBoost和AdaCost的分类性能测试结果 (%)
Tab. 4 Classification performance test results ofAdaBoost and AdaCost
| 数据集 | AdaBoost | |||
|---|---|---|---|---|
| Accuracy | F1-Score | G-mean | AUC | |
| D1 | 50.71 | 50.83 | 50.94 | 61.96 |
| D2 | 70.34 | 74.49 | 79.15 | 93.51 |
| D3 | 66.84 | 70.09 | 73.66 | 72.53 |
| D4 | 67.44 | 70.99 | 74.95 | 95.00 |
| D5 | 60.60 | 65.60 | 71.50 | 81.76 |
| D6 | 47.81 | 32.35 | 24.44 | 66.92 |
| D7 | 53.26 | 57.70 | 62.94 | 61.68 |
| D8 | 61.63 | 67.71 | 75.11 | 86.55 |
| D9 | 49.08 | 32.92 | 24.77 | 42.12 |
| D10 | 49.64 | 33.17 | 24.91 | 51.59 |
| 数据集 | AdaCost | |||
| Accuracy | F1-Score | G-mean | AUC | |
| D1 | 37.50 | 27.27 | 21.43 | 69.78 |
| D2 | 83.69 | 85.20 | 86.76 | 92.63 |
| D3 | 69.10 | 72.03 | 75.23 | 73.16 |
| D4 | 65.38 | 71.77 | 79.55 | 96.25 |
| D5 | 55.80 | 60.04 | 64.98 | 77.06 |
| D6 | 65.65 | 55.04 | 60.92 | 68.83 |
| D7 | 65.05 | 69.76 | 75.19 | 52.45 |
| D8 | 56.95 | 64.94 | 75.53 | 92.34 |
| D9 | 49.08 | 32.92 | 24.77 | 28.01 |
| D10 | 50.31 | 54.41 | 59.25 | 60.17 |
| 数据集 | RUSBoost | |||||||
|---|---|---|---|---|---|---|---|---|
| 初次迭代性能 | 10次迭代性能 | |||||||
| Accuracy | F1-Score | G-mean | AUC | Accuracy | F1-Score | G-mean | AUC | |
| D1 | 57.73 | 58.70 | 59.72 | 59.89 | 55.17 | 55.86 | 56.59 | 58.86 |
| D2 | 66.03 | 70.46 | 75.55 | 96.22 | 85.82 | 87.18 | 88.62 | 96.84 |
| D3 | 65.86 | 70.36 | 75.55 | 95.90 | 63.88 | 67.20 | 70.90 | 81.45 |
| D4 | 57.74 | 61.36 | 67.39 | 97.50 | 73.31 | 72.30 | 72.80 | 93.75 |
| D5 | 56.85 | 60.31 | 64.29 | 91.37 | 59.69 | 64.53 | 70.23 | 69.25 |
| D6 | 53.17 | 56.80 | 61.39 | 86.95 | 51.83 | 55.73 | 60.80 | 76.19 |
| D7 | 54.40 | 44.00 | 45.83 | 46.31 | 53.32 | 57.48 | 63.24 | 56.20 |
| D8 | 57.75 | 65.52 | 75.72 | 85.08 | 59.88 | 66.67 | 75.25 | 84.66 |
| D9 | 65.47 | 33.80 | 49.77 | 60.81 | 50.54 | 54.27 | 60.29 | 50.75 |
| D10 | 51.38 | 56.08 | 66.61 | 53.38 | 50.22 | 54.48 | 60.50 | 38.97 |
| 数据集 | USCBoost | |||||||
| 初次迭代性能 | 10次迭代性能 | |||||||
| Accuracy | F1-Score | G-mean | AUC | Accuracy | F1-Score | G-mean | AUC | |
| D1 | 57.41 | 58.39 | 59.40 | 59.55 | 51.21 | 51.02 | 50.86 | 55.26 |
| D2 | 65.97 | 70.42 | 75.51 | 96.45 | 87.96 | 88.80 | 89.65 | 98.21 |
| D3 | 65.96 | 70.44 | 75.59 | 95.85 | 60.98 | 64.72 | 68.94 | 73.89 |
| D4 | 58.74 | 63.85 | 70.91 | 97.03 | 69.21 | 74.30 | 80.22 | 93.88 |
| D5 | 58.43 | 62.02 | 66.17 | 91.37 | 61.48 | 65.94 | 71.10 | 81.92 |
| D6 | 52.54 | 55.47 | 59.41 | 87.35 | 47.58 | 32.24 | 24.38 | 62.20 |
| D7 | 56.31 | 44.75 | 48.19 | 48.78 | 56.16 | 52.93 | 53.24 | 62.55 |
| D8 | 57.77 | 65.57 | 75.82 | 84.90 | 63.95 | 70.45 | 78.44 | 94.86 |
| D9 | 68.33 | 30.40 | 49.19 | 61.53 | 58.96 | 32.94 | 29.82 | 40.81 |
| D10 | 51.32 | 54.77 | 64.05 | 50.93 | 50.64 | 56.87 | 64.84 | 58.74 |
| 数据集 | DPBCPUSBoost | |||||||
| 初次迭代性能 | 10次迭代性能 | |||||||
| Accuracy | F1-Score | G-mean | AUC | Accuracy | F1-Score | G-mean | AUC | |
| D1 | 57.24 | 58.24 | 59.27 | 59.34 | 63.30 | 63.99 | 64.70 | 63.78 |
| D2 | 65.46 | 70.24 | 75.78 | 96.99 | 90.38 | 91.17 | 91.96 | 99.23 |
| D3 | 65.36 | 69.99 | 75.34 | 95.75 | 75.73 | 77.77 | 79.94 | 75.68 |
| D4 | 60.14 | 66.54 | 74.60 | 97.55 | 73.68 | 76.96 | 80.54 | 93.75 |
| D5 | 56.84 | 60.63 | 65.12 | 90.57 | 52.51 | 55.10 | 57.97 | 84.31 |
| D6 | 53.39 | 57.22 | 61.99 | 88.81 | 65.15 | 69.93 | 75.46 | 83.71 |
| D7 | 57.89 | 39.86 | 45.60 | 47.25 | 47.89 | 32.38 | 24.46 | 82.07 |
| D8 | 57.44 | 65.63 | 75.68 | 84.76 | 64.85 | 70.99 | 78.45 | 93.72 |
| D9 | 67.40 | 31.82 | 49.81 | 61.61 | 49.03 | 32.90 | 24.76 | 54.26 |
| D10 | 50.43 | 57.75 | 68.23 | 53.60 | 50.37 | 60.30 | 75.09 | 32.61 |
表5 RUSBoost、USCBoost和DPBCPUSBoost的分类性能测试结果 (%)
Tab. 5 Classification performance test results of RUSBoost, USCBoost and DPBCPUSBoost
| 数据集 | RUSBoost | |||||||
|---|---|---|---|---|---|---|---|---|
| 初次迭代性能 | 10次迭代性能 | |||||||
| Accuracy | F1-Score | G-mean | AUC | Accuracy | F1-Score | G-mean | AUC | |
| D1 | 57.73 | 58.70 | 59.72 | 59.89 | 55.17 | 55.86 | 56.59 | 58.86 |
| D2 | 66.03 | 70.46 | 75.55 | 96.22 | 85.82 | 87.18 | 88.62 | 96.84 |
| D3 | 65.86 | 70.36 | 75.55 | 95.90 | 63.88 | 67.20 | 70.90 | 81.45 |
| D4 | 57.74 | 61.36 | 67.39 | 97.50 | 73.31 | 72.30 | 72.80 | 93.75 |
| D5 | 56.85 | 60.31 | 64.29 | 91.37 | 59.69 | 64.53 | 70.23 | 69.25 |
| D6 | 53.17 | 56.80 | 61.39 | 86.95 | 51.83 | 55.73 | 60.80 | 76.19 |
| D7 | 54.40 | 44.00 | 45.83 | 46.31 | 53.32 | 57.48 | 63.24 | 56.20 |
| D8 | 57.75 | 65.52 | 75.72 | 85.08 | 59.88 | 66.67 | 75.25 | 84.66 |
| D9 | 65.47 | 33.80 | 49.77 | 60.81 | 50.54 | 54.27 | 60.29 | 50.75 |
| D10 | 51.38 | 56.08 | 66.61 | 53.38 | 50.22 | 54.48 | 60.50 | 38.97 |
| 数据集 | USCBoost | |||||||
| 初次迭代性能 | 10次迭代性能 | |||||||
| Accuracy | F1-Score | G-mean | AUC | Accuracy | F1-Score | G-mean | AUC | |
| D1 | 57.41 | 58.39 | 59.40 | 59.55 | 51.21 | 51.02 | 50.86 | 55.26 |
| D2 | 65.97 | 70.42 | 75.51 | 96.45 | 87.96 | 88.80 | 89.65 | 98.21 |
| D3 | 65.96 | 70.44 | 75.59 | 95.85 | 60.98 | 64.72 | 68.94 | 73.89 |
| D4 | 58.74 | 63.85 | 70.91 | 97.03 | 69.21 | 74.30 | 80.22 | 93.88 |
| D5 | 58.43 | 62.02 | 66.17 | 91.37 | 61.48 | 65.94 | 71.10 | 81.92 |
| D6 | 52.54 | 55.47 | 59.41 | 87.35 | 47.58 | 32.24 | 24.38 | 62.20 |
| D7 | 56.31 | 44.75 | 48.19 | 48.78 | 56.16 | 52.93 | 53.24 | 62.55 |
| D8 | 57.77 | 65.57 | 75.82 | 84.90 | 63.95 | 70.45 | 78.44 | 94.86 |
| D9 | 68.33 | 30.40 | 49.19 | 61.53 | 58.96 | 32.94 | 29.82 | 40.81 |
| D10 | 51.32 | 54.77 | 64.05 | 50.93 | 50.64 | 56.87 | 64.84 | 58.74 |
| 数据集 | DPBCPUSBoost | |||||||
| 初次迭代性能 | 10次迭代性能 | |||||||
| Accuracy | F1-Score | G-mean | AUC | Accuracy | F1-Score | G-mean | AUC | |
| D1 | 57.24 | 58.24 | 59.27 | 59.34 | 63.30 | 63.99 | 64.70 | 63.78 |
| D2 | 65.46 | 70.24 | 75.78 | 96.99 | 90.38 | 91.17 | 91.96 | 99.23 |
| D3 | 65.36 | 69.99 | 75.34 | 95.75 | 75.73 | 77.77 | 79.94 | 75.68 |
| D4 | 60.14 | 66.54 | 74.60 | 97.55 | 73.68 | 76.96 | 80.54 | 93.75 |
| D5 | 56.84 | 60.63 | 65.12 | 90.57 | 52.51 | 55.10 | 57.97 | 84.31 |
| D6 | 53.39 | 57.22 | 61.99 | 88.81 | 65.15 | 69.93 | 75.46 | 83.71 |
| D7 | 57.89 | 39.86 | 45.60 | 47.25 | 47.89 | 32.38 | 24.46 | 82.07 |
| D8 | 57.44 | 65.63 | 75.68 | 84.76 | 64.85 | 70.99 | 78.45 | 93.72 |
| D9 | 67.40 | 31.82 | 49.81 | 61.61 | 49.03 | 32.90 | 24.76 | 54.26 |
| D10 | 50.43 | 57.75 | 68.23 | 53.60 | 50.37 | 60.30 | 75.09 | 32.61 |

图4 不同算法取得最高性能的数据集数量
Fig. 4 Number of datasets of different algorithms with highest performance
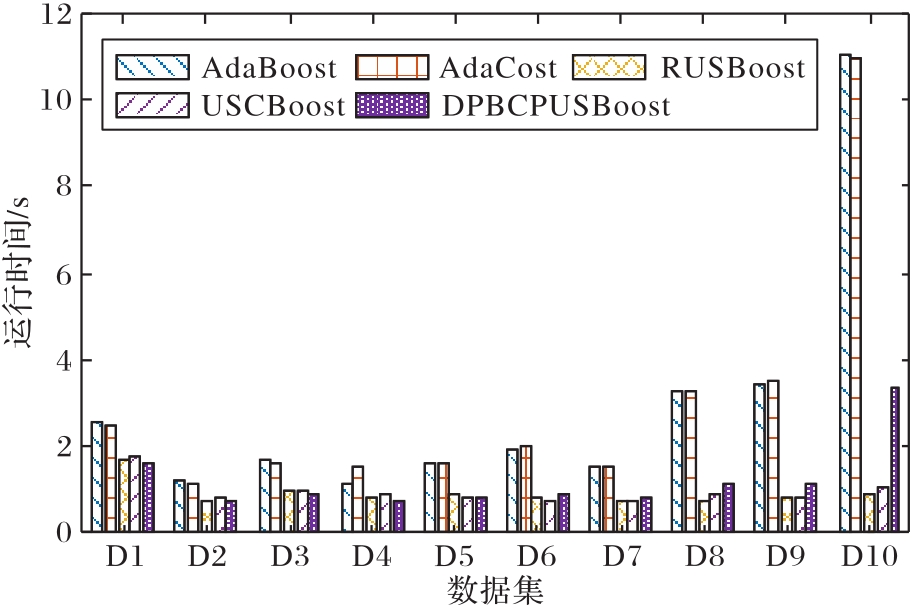
图5 不同算法在不同数据集上的运行时间
Fig. 5 Running time for different algorithms on different datasets
| 1 | ZHOU X K, HU Y Y, LIANG W, et al. Variational LSTM enhanced anomaly detection for industrial big data [J]. IEEE Transactions on Industrial Informatics, 2021, 17(5): 3469-3477. 10.1109/tii.2020.3022432 |
| 2 | 胡姣姣,王晓峰,张萌,等.基于深度学习的时间序列数据异常检测方法[J].信息与控制,2019,48(1):1-8. |
| HU J J, WANG X F, ZHANG M, et al. Time-series data anomaly detection method based on deep learning [J]. Information and Control, 2019, 48(1): 1-8. | |
| 3 | 张跃飞,王敬飞,陈斌,等.基于改进的Mask R-CNN的公路裂缝检测算法[J].计算机应用,2020,40(S2):162-165. |
| ZHANG Y F, WANG J F, CHEN B, et al. Pavement crack detection algorithm based on improved Mask R-CNN [J]. Journal of Computer Applications, 2020, 40(S2): 162-165. | |
| 4 | LIN P, YE K J, XU C Z. Dynamic network anomaly detection system by using deep learning techniques [C]// Proceedings of the 2019 International Conference on Cloud Computing, LNCS 11513. Cham: Springer, 2019: 161-176. |
| 5 | 刘颖,杨轲.基于深度集成学习的类极度不均衡数据信用欺诈检测算法[J].计算机研究与发展,2021,58(3):539-547. 10.7544/issn1000-1239.2021.20200324 |
| LIU Y, YANG K. Credit fraud detection for extremely imbalanced data based on ensembled deep learning [J]. Journal of Computer Research and Development, 2021, 58(3): 539-547. 10.7544/issn1000-1239.2021.20200324 | |
| 6 | ZHU H H, LIU G J, ZHOU M C, et al. Optimizing weighted extreme learning machines for imbalanced classification and application to credit card fraud detection [J]. Neurocomputing, 2020, 407: 50-62. 10.1016/j.neucom.2020.04.078 |
| 7 | LI Z C, HUANG M, LIU G J, et al. A hybrid method with dynamic weighted entropy for handling the problem of class imbalance with overlap in credit card fraud detection [J]. Expert Systems with Applications, 2021, 175: Article No.114750. 10.1016/j.eswa.2021.114750 |
| 8 | 易东义,邓根强,董超雄,等.基于图卷积神经网络的医保欺诈检测算法[J].计算机应用,2020,40(5):1272-1277. |
| YI D Y, DENG G Q, DONG C X, et al. Medical insurance fraud detection algorithm based on graph convolutional neural network [J]. Journal of Computer Applications, 2020, 40(5): 1272-1277. | |
| 9 | 刘枭,王晓国.基于密集子图的银行电信诈骗检测方法[J].计算机应用,2019,39(4):1214-1219. 10.11772/j.issn.1001-9081.2018091861 |
| LIU X, WANG X G. Dense subgraph based telecommunication fraud detection approach in bank [J]. Journal of Computer Applications, 2019, 39(4): 1214-1219. 10.11772/j.issn.1001-9081.2018091861 | |
| 10 | LU C, LIN S F, LIU X L, et al. Telecom fraud identification based on ADASYN and random forest [C]// Proceedings of the 2020 5th International Conference on Computer and Communication Systems. Piscataway: IEEE, 2020: 447-452. 10.1109/icccs49078.2020.9118521 |
| 11 | 王伟,谢耀滨,尹青.针对不平衡数据的决策树改进方法[J].计算机应用,2019,39(3):623-628. 10.11772/j.issn.1001-9081.2018071513 |
| WANG W, XIE Y B, YIN Q. Decision tree improvement method for imbalanced data [J]. Journal of Computer Applications, 2019, 39(3): 623-628. 10.11772/j.issn.1001-9081.2018071513 | |
| 12 | 徐玲玲,迟冬祥.面向不平衡数据集的机器学习分类策略[J].计算机工程与应用,2020,56(24):12-27. |
| XU L L, CHI D X. Machine learning classification strategy for imbalanced data sets [J]. Computer Engineering and Applications, 2020, 56(24): 12-27. | |
| 13 | 陈木生,卢晓勇.三种用于垃圾网页检测的随机欠采样集成分类器[J].计算机应用,2017,37(2):535-539,558. 10.11772/j.issn.1001-9081.2017.02.0535 |
| CHEN M S, LU X Y. Three random under-sampling based ensemble classifiers for Web spam detection [J]. Journal of Computer Applications, 2017, 37(2): 535-539, 558. 10.11772/j.issn.1001-9081.2017.02.0535 | |
| 14 | 王俊红,闫家荣.基于欠采样和代价敏感的不平衡数据分类算法[J].计算机应用,2021,41(1):48-52. 10.11772/j.issn.1001-9081.2020060878 |
| WANG J H, YAN J R. Classification algorithm based on undersampling and cost-sensitiveness for unbalanced data [J]. Journal of Computer Applications, 2021, 41(1): 48-52. 10.11772/j.issn.1001-9081.2020060878 | |
| 15 | KAYA E, KORKMAZ S, ŞAHMAN M A, et al. DEBOHID: a differential evolution based oversampling approach for highly imbalanced datasets [J]. Expert Systems with Applications, 2021, 169: Article No.114482. 10.1016/j.eswa.2020.114482 |
| 16 | ENGELMANN J, LESSMANN S. Conditional Wasserstein GAN-based oversampling of tabular data for imbalanced learning [J]. Expert Systems with Applications, 2021, 174: Article No.114582. 10.1016/j.eswa.2021.114582 |
| 17 | WANG X Y, XU J, ZENG T Y, et al. Local distribution-based adaptive minority oversampling for imbalanced data classification [J]. Neurocomputing, 2021, 422: 200-213. 10.1016/j.neucom.2020.05.030 |
| 18 | GAO X, REN B, ZHANG H, et al. An ensemble imbalanced classification method based on model dynamic selection driven by data partition hybrid sampling [J]. Expert Systems with Applications, 2020, 160: Article No.113660. 10.1016/j.eswa.2020.113660 |
| 19 | ZHU Y W, YAN Y T, ZHANG Y W, et al. EHSO: evolutionary hybrid sampling in overlapping scenarios for imbalanced learning [J]. Neurocomputing, 2020, 417: 333-346. 10.1016/j.neucom.2020.08.060 |
| 20 | FREUND Y, SCHAPIRE R E. Experiments with a new boosting algorithm [C]// Proceedings of the 13th International Conference on International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 1996: 148-156. 10.1145/238061.238163 |
| 21 | FAN W, STOLFO S J, ZHANG J X, et al. AdaCost: misclassification cost-sensitive boosting [C]// Proceedings of the 1999 16th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 1999: 97-105. |
| 22 | LIU X Y, WU J X, ZHOU Z H. Exploratory undersampling for class-imbalance learning [J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2009, 39(2): 539-550. 10.1109/tsmcb.2008.2007853 |
| 23 | SEIFFERT C, KHOSHGOFTAAR T M, HULSE J VAN, et al. RUSBoost: a hybrid approach to alleviating class imbalance [J]. IEEE Transactions on Systems, Man, and Cybernetics — Part A: Systems and Humans, 2010, 40(1): 185-197. 10.1109/tsmca.2009.2029559 |
| 24 | 万建武,杨明.代价敏感学习方法综述[J].软件学报,2020,31(1):113-136. |
| WAN J W, YANG M. Survey on cost-sensitive learning method [J]. Journal of Software, 2020, 31(1): 113-136. | |
| 25 | RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks [J]. Science, 2014, 344(6191): 1492-1496. 10.1126/science.1242072 |
| 26 | XIA S Y, PENG D W, MENG D Y, et al. Ball k-means: fast adaptive clustering with no bounds [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 87-99. |
| 27 | HART P. The condensed nearest neighbor rule (corresp.) [J]. IEEE Transactions on Information Theory, 1968, 14(3): 515-516. 10.1109/tit.1968.1054155 |
| [1] | 杜洁, 马燕, 黄慧. 基于局部引力和距离的聚类算法[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1472-1479. |
| [2] | 孟凡, 陈广, 王勇, 高阳, 高德群, 贾文龙. 基于多粒度时序结构表示的异常检测算法在储层含油性检测中应用[J]. 计算机应用, 2021, 41(8): 2453-2459. |
| [3] | 郭佳, 韩李涛, 孙宪龙, 周丽娟. 自动确定聚类中心的比较密度峰值聚类算法[J]. 计算机应用, 2021, 41(3): 738-744. |
| [4] | 吕佳, 鲜焱. 结合改进密度峰值聚类和共享子空间的协同训练算法[J]. 计算机应用, 2021, 41(3): 686-693. |
| [5] | 王俊红, 闫家荣. 基于欠采样和代价敏感的不平衡数据分类算法[J]. 计算机应用, 2021, 41(1): 48-52. |
| [6] | 吴斌, 卢红丽, 江惠君. 自适应密度峰值聚类算法[J]. 计算机应用, 2020, 40(6): 1654-1661. |
| [7] | 苏俊宁, 叶东毅. 基于样本密度峰值的不平衡数据欠抽样方法[J]. 计算机应用, 2020, 40(1): 83-89. |
| [8] | 王忠震, 黄勃, 方志军, 高永彬, 张娟. 改进SMOTE的不平衡数据集成分类算法[J]. 计算机应用, 2019, 39(9): 2591-2596. |
| [9] | 龚彦鹭, 吕佳. 结合主动学习和密度峰值聚类的协同训练算法[J]. 计算机应用, 2019, 39(8): 2297-2301. |
| [10] | 杨浩, 王宇, 张中原. 基于K最近邻样本平均距离的代价敏感算法的集成[J]. 计算机应用, 2019, 39(7): 1883-1887. |
| [11] | 王莉, 陈红梅, 王生武. 新的基于代价敏感集成学习的非平衡数据集分类方法NIBoost[J]. 计算机应用, 2019, 39(3): 629-633. |
| [12] | 王治和, 黄梦莹, 杜辉, 秦红武. 基于密度峰值与密度聚类的集成算法[J]. 计算机应用, 2019, 39(2): 398-402. |
| [13] | 王军, 周凯, 程勇. 混合的密度峰值聚类算法[J]. 计算机应用, 2019, 39(2): 403-408. |
| [14] | 韩忠华, 毕开元, 司雯, 吕哲. 基于谱分析的密度峰值快速聚类算法[J]. 计算机应用, 2019, 39(2): 409-413. |
| [15] | 杜航原, 裴希亚, 王文剑. 面向属性网络的重叠社区发现算法[J]. 计算机应用, 2019, 39(11): 3151-3157. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||