


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (5): 1554-1562.DOI: 10.11772/j.issn.1001-9081.2021050867
收稿日期:2021-05-25
修回日期:2022-01-24
接受日期:2022-02-18
发布日期:2022-03-08
出版日期:2022-05-10
通讯作者:
李莉
作者简介:李莉(1977—),女,河南孟州人,副教授,博士,CCF会员,主要研究方向:先进软件工程、区块链、群智能优化、大型分布式计算 lli@nefu.edu.cn
Li LI( ), Kexin SHI, Zhenkang REN
), Kexin SHI, Zhenkang REN
Received:2021-05-25
Revised:2022-01-24
Accepted:2022-02-18
Online:2022-03-08
Published:2022-05-10
Contact:
Li LI
About author:LI Li, born in 1977, Ph. D., associate professor. Her research interests include advanced software engineering, blockchain, swarm intelligence optimization, large-scale distributed computing.摘要:
跨项目软件缺陷预测可以解决预测项目中训练数据较少的问题,然而源项目和目标项目通常会有较大的数据分布差异,这降低了预测性能。针对该问题,提出了一种基于特征选择和TrAdaBoost的跨项目缺陷预测方法(CPDP-FSTr)。首先,在特征选择阶段,采用核主成分分析法(KPCA)删除源项目中的冗余数据;然后,根据源项目和目标项目的属性特征分布,按距离选出与目标项目分布最接近的候选源项目数据;最后,在实例迁移阶段,通过采用评估因子改进的TrAdaBoost方法,在源项目中找出与目标项目中少量有标签实例分布相近的实例,并建立缺陷预测模型。以F1作为评价指标,与基于特征聚类和TrAdaBoost的跨项目软件缺陷预测(FeCTrA)方法以及基于多核集成学习的跨项目软件缺陷预测(CMKEL)方法相比,CPDP-FSTr的预测性能在AEEEM数据集上分别提高了5.84%、105.42%,在NASA数据集上分别提高了5.25%、85.97%,且其两过程特征选择优于单一特征选择过程。实验结果表明,当源项目特征选择比例和目标项目有类标实例比例分别为60%、20%时,所提CPDP-FSTr能取得较好的预测性能。
中图分类号:
李莉, 石可欣, 任振康. 基于特征选择和TrAdaBoost的跨项目缺陷预测方法[J]. 计算机应用, 2022, 42(5): 1554-1562.
Li LI, Kexin SHI, Zhenkang REN. Cross-project defect prediction method based on feature selection and TrAdaBoost[J]. Journal of Computer Applications, 2022, 42(5): 1554-1562.
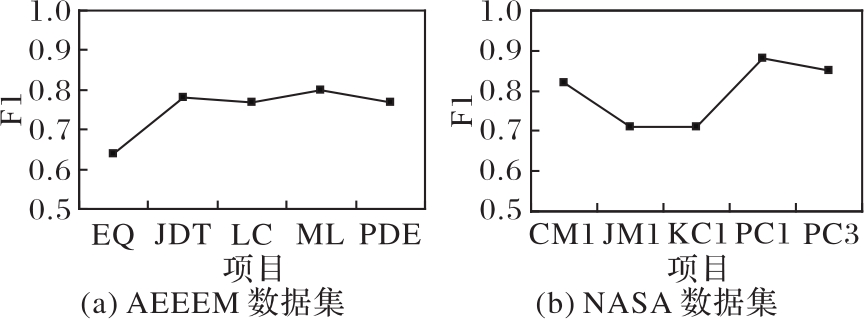
图1 特征选择过程的实验结果(KPCA)
Fig. 1 Experimental results of feature selection process (KPCA)

图2 特征选择过程的实验结果(DAFD)
Fig. 2 Experimental results of feature selection process (DAFD)

图3 特征选择过程的实验结果(两过程)
Fig. 3 Experimental results of feature selection process (two-process)

图4 CPDP-FSTr流程
Fig. 4 Flow chart of CPDP-FSTr
| 项目 | 特征数 | 样本数 | 缺陷样本数 | 缺陷样本比例/% |
|---|---|---|---|---|
| EQ | 61 | 324 | 129 | 39.81 |
| JDT | 61 | 997 | 206 | 20.66 |
| LC | 61 | 691 | 64 | 9.26 |
| ML | 61 | 1 842 | 245 | 13.16 |
| PDE | 61 | 1 497 | 209 | 13.96 |
表1 AEEEM数据集的统计信息
Tab. 1 Statistical information of AEEEM dataset
| 项目 | 特征数 | 样本数 | 缺陷样本数 | 缺陷样本比例/% |
|---|---|---|---|---|
| EQ | 61 | 324 | 129 | 39.81 |
| JDT | 61 | 997 | 206 | 20.66 |
| LC | 61 | 691 | 64 | 9.26 |
| ML | 61 | 1 842 | 245 | 13.16 |
| PDE | 61 | 1 497 | 209 | 13.96 |
| 项目 | 特征数 | 样本数 | 缺陷样本数 | 缺陷样本比例/% |
|---|---|---|---|---|
| CM1 | 37 | 327 | 42 | 12.84 |
| JM1 | 37 | 7 720 | 1 612 | 20.88 |
| KC1 | 37 | 1 163 | 294 | 25.28 |
| PC1 | 37 | 705 | 61 | 8.65 |
| PC3 | 37 | 1 077 | 134 | 12.44 |
表2 NASA数据集的统计信息
Tab. 2 Statistical information of NASA dataset
| 项目 | 特征数 | 样本数 | 缺陷样本数 | 缺陷样本比例/% |
|---|---|---|---|---|
| CM1 | 37 | 327 | 42 | 12.84 |
| JM1 | 37 | 7 720 | 1 612 | 20.88 |
| KC1 | 37 | 1 163 | 294 | 25.28 |
| PC1 | 37 | 705 | 61 | 8.65 |
| PC3 | 37 | 1 077 | 134 | 12.44 |
| 源项目→目标项目 | CPDP-FSTr | CPDP-FSNTr | FeCTrA | CMKEL |
|---|---|---|---|---|
| AVG | 0.834 | 0.807 | 0.788 | 0.406 |
| PDE→EQ | 0.749 | 0.689 | 0.682 | 0.382 |
| LC→EQ | 0.742 | 0.697 | 0.793 | 0.393 |
| ML→EQ | 0.757 | 0.709 | 0.698 | 0.402 |
| JDT→EQ | 0.736 | 0.683 | 0.696 | 0.354 |
| PDE→JDT | 0.809 | 0.783 | 0.805 | 0.496 |
| LC→JDT | 0.800 | 0.789 | 0.789 | 0.472 |
| ML→JDT | 0.819 | 0.782 | 0.781 | 0.493 |
| EQ→JDT | 0.802 | 0.795 | 0.807 | 0.461 |
| PDE→LC | 0.886 | 0.880 | 0.826 | 0.365 |
| ML→LC | 0.885 | 0.885 | 0.789 | 0.364 |
| EQ→LC | 0.888 | 0.888 | 0.794 | 0.371 |
| JDT→LC | 0.886 | 0.882 | 0.823 | 0.377 |
| PDE→ML | 0.868 | 0.835 | 0.803 | 0.472 |
| LC→ML | 0.871 | 0.842 | 0.801 | 0.463 |
| EQ→ML | 0.878 | 0.814 | 0.812 | 0.468 |
| JDT→ML | 0.867 | 0.838 | 0.837 | 0.465 |
| LC→PDE | 0.866 | 0.820 | 0.809 | 0.344 |
| ML→PDE | 0.862 | 0.851 | 0.813 | 0.338 |
| EQ→PDE | 0.852 | 0.835 | 0.766 | 0.319 |
| JDT→PDE | 0.859 | 0.835 | 0.841 | 0.330 |
表3 不同算法预测性能的结果对比(AEEEM数据集)
Tab. 3 Result comparison of prediction performance of different algorithms (AEEEM dataset)
| 源项目→目标项目 | CPDP-FSTr | CPDP-FSNTr | FeCTrA | CMKEL |
|---|---|---|---|---|
| AVG | 0.834 | 0.807 | 0.788 | 0.406 |
| PDE→EQ | 0.749 | 0.689 | 0.682 | 0.382 |
| LC→EQ | 0.742 | 0.697 | 0.793 | 0.393 |
| ML→EQ | 0.757 | 0.709 | 0.698 | 0.402 |
| JDT→EQ | 0.736 | 0.683 | 0.696 | 0.354 |
| PDE→JDT | 0.809 | 0.783 | 0.805 | 0.496 |
| LC→JDT | 0.800 | 0.789 | 0.789 | 0.472 |
| ML→JDT | 0.819 | 0.782 | 0.781 | 0.493 |
| EQ→JDT | 0.802 | 0.795 | 0.807 | 0.461 |
| PDE→LC | 0.886 | 0.880 | 0.826 | 0.365 |
| ML→LC | 0.885 | 0.885 | 0.789 | 0.364 |
| EQ→LC | 0.888 | 0.888 | 0.794 | 0.371 |
| JDT→LC | 0.886 | 0.882 | 0.823 | 0.377 |
| PDE→ML | 0.868 | 0.835 | 0.803 | 0.472 |
| LC→ML | 0.871 | 0.842 | 0.801 | 0.463 |
| EQ→ML | 0.878 | 0.814 | 0.812 | 0.468 |
| JDT→ML | 0.867 | 0.838 | 0.837 | 0.465 |
| LC→PDE | 0.866 | 0.820 | 0.809 | 0.344 |
| ML→PDE | 0.862 | 0.851 | 0.813 | 0.338 |
| EQ→PDE | 0.852 | 0.835 | 0.766 | 0.319 |
| JDT→PDE | 0.859 | 0.835 | 0.841 | 0.330 |
| 源项目→目标项目 | CPDP-FSTr | CPDP-FSNTr | FeCTrA | CMKEL |
|---|---|---|---|---|
| AVG | 0.822 | 0.811 | 0.781 | 0.442 |
| JM1→CM1 | 0.820 | 0.822 | 0.821 | 0.352 |
| KC1→CM1 | 0.815 | 0.805 | 0.807 | 0.405 |
| PC1→CM1 | 0.825 | 0.820 | 0.818 | 0.468 |
| PC3→CM1 | 0.828 | 0.818 | 0.815 | 0.507 |
| CM1→JM1 | 0.788 | 0.759 | 0.721 | 0.463 |
| KC1→JM1 | 0.778 | 0.753 | 0.698 | 0.457 |
| PC1→JM1 | 0.786 | 0.767 | 0.737 | 0.473 |
| PC3→JM1 | 0.787 | 0.770 | 0.280 | 0.466 |
| CM1→KC1 | 0.731 | 0.741 | 0.693 | 0.457 |
| JM1→KC1 | 0.741 | 0.740 | 0.731 | 0.363 |
| PC1→KC1 | 0.786 | 0.769 | 0.768 | 0.463 |
| PC3→KC1 | 0.782 | 0.733 | 0.776 | 0.481 |
| CM1→PC1 | 0.906 | 0.886 | 0.887 | 0.472 |
| JM1→PC1 | 0.906 | 0.884 | 0.884 | 0.477 |
| KC1→PC1 | 0.906 | 0.906 | 0.892 | 0.465 |
| PC3→PC1 | 0.898 | 0.883 | 0.886 | 0.443 |
| CM1→PC3 | 0.869 | 0.852 | 0.855 | 0.378 |
| JM1→PC3 | 0.851 | 0.849 | 0.851 | 0.403 |
| KC1→PC3 | 0.866 | 0.847 | 0.848 | 0.421 |
| PC1→PC3 | 0.850 | 0.848 | 0.847 | 0.417 |
表4 不同算法的预测性能结果对比(NASA数据集)
Tab. 4 Result comparison of prediction performance of different algorithms (NASA dataset)
| 源项目→目标项目 | CPDP-FSTr | CPDP-FSNTr | FeCTrA | CMKEL |
|---|---|---|---|---|
| AVG | 0.822 | 0.811 | 0.781 | 0.442 |
| JM1→CM1 | 0.820 | 0.822 | 0.821 | 0.352 |
| KC1→CM1 | 0.815 | 0.805 | 0.807 | 0.405 |
| PC1→CM1 | 0.825 | 0.820 | 0.818 | 0.468 |
| PC3→CM1 | 0.828 | 0.818 | 0.815 | 0.507 |
| CM1→JM1 | 0.788 | 0.759 | 0.721 | 0.463 |
| KC1→JM1 | 0.778 | 0.753 | 0.698 | 0.457 |
| PC1→JM1 | 0.786 | 0.767 | 0.737 | 0.473 |
| PC3→JM1 | 0.787 | 0.770 | 0.280 | 0.466 |
| CM1→KC1 | 0.731 | 0.741 | 0.693 | 0.457 |
| JM1→KC1 | 0.741 | 0.740 | 0.731 | 0.363 |
| PC1→KC1 | 0.786 | 0.769 | 0.768 | 0.463 |
| PC3→KC1 | 0.782 | 0.733 | 0.776 | 0.481 |
| CM1→PC1 | 0.906 | 0.886 | 0.887 | 0.472 |
| JM1→PC1 | 0.906 | 0.884 | 0.884 | 0.477 |
| KC1→PC1 | 0.906 | 0.906 | 0.892 | 0.465 |
| PC3→PC1 | 0.898 | 0.883 | 0.886 | 0.443 |
| CM1→PC3 | 0.869 | 0.852 | 0.855 | 0.378 |
| JM1→PC3 | 0.851 | 0.849 | 0.851 | 0.403 |
| KC1→PC3 | 0.866 | 0.847 | 0.848 | 0.421 |
| PC1→PC3 | 0.850 | 0.848 | 0.847 | 0.417 |
| 项目 | CPDP-FSTr | FSTr-KP | FSTr-D |
|---|---|---|---|
| AVG | 0.84 | 0.75 | 0.81 |
| EQ | 0.75 | 0.64 | 0.73 |
| JDT | 0.81 | 0.78 | 0.79 |
| LC | 0.89 | 0.77 | 0.88 |
| ML | 0.87 | 0.80 | 0.82 |
| PDE | 0.86 | 0.77 | 0.83 |
表5 特征选择过程的实验结果(AEEEM数据集)
Tab. 5 Experimental results of feature selection process (AEEEM dataset)
| 项目 | CPDP-FSTr | FSTr-KP | FSTr-D |
|---|---|---|---|
| AVG | 0.84 | 0.75 | 0.81 |
| EQ | 0.75 | 0.64 | 0.73 |
| JDT | 0.81 | 0.78 | 0.79 |
| LC | 0.89 | 0.77 | 0.88 |
| ML | 0.87 | 0.80 | 0.82 |
| PDE | 0.86 | 0.77 | 0.83 |
| 项目 | CPDP-FSTr | FSTr-KP | FSTr-D |
|---|---|---|---|
| AVG | 0.82 | 0.79 | 0.80 |
| CM1 | 0.82 | 0.82 | 0.81 |
| JM1 | 0.78 | 0.71 | 0.71 |
| KC1 | 0.76 | 0.71 | 0.74 |
| PC1 | 0.90 | 0.88 | 0.89 |
| PC3 | 0.86 | 0.85 | 0.85 |
表6 特征选择过程的实验结果(NASA数据集)
Tab. 6 Experimental results of feature selection process (NASA dataset)
| 项目 | CPDP-FSTr | FSTr-KP | FSTr-D |
|---|---|---|---|
| AVG | 0.82 | 0.79 | 0.80 |
| CM1 | 0.82 | 0.82 | 0.81 |
| JM1 | 0.78 | 0.71 | 0.71 |
| KC1 | 0.76 | 0.71 | 0.74 |
| PC1 | 0.90 | 0.88 | 0.89 |
| PC3 | 0.86 | 0.85 | 0.85 |
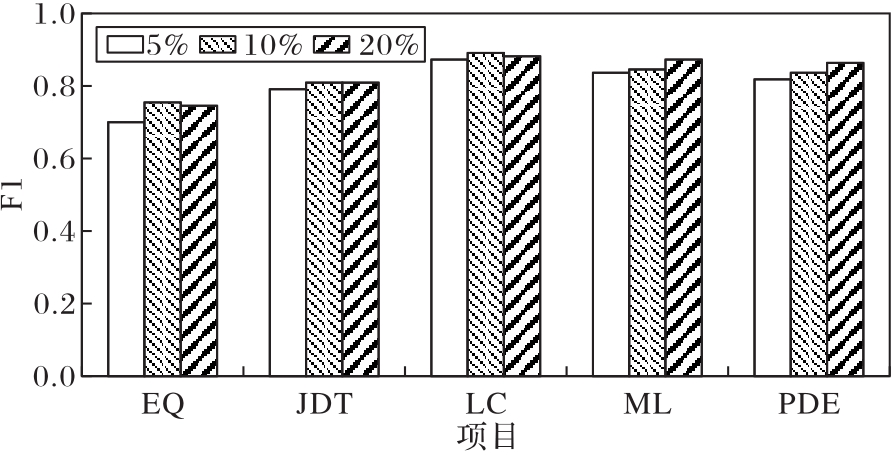
图5 目标项目有类标实例比例对性能的影响(AEEEM数据集)
Fig. 5 Influence of target project labeled instance proportion on performance (AEEEM dataset)

图6 目标项目有类标实例比例对性能的影响(NASA数据集)
Fig. 6 Influence of target project labeled instance proportion on performance (NASA dataset)
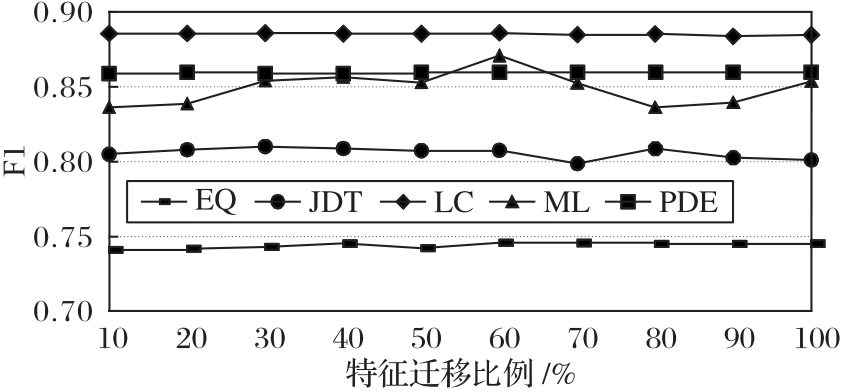
图7 特征选择比例对性能的影响(AEEEM数据集)
Fig. 7 Influence of feature selection proportion on performance (AEEEM dataset)
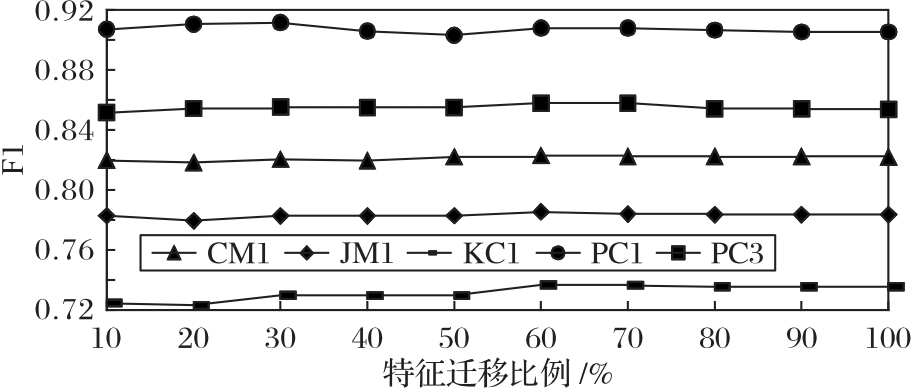
图8 特征选择比例对性能的影响(NASA数据集)
Fig. 8 Influence of feature selection proportion on performance (NASA dataset)
| 1 | 宫丽娜,姜淑娟,姜丽.软件缺陷预测技术研究进展[J].软件学报,2019,30(10):3090-3114. 10.13328/j.cnki.jos.005790 |
| GONG L N, JIANG S J, JIANG L. Research progress of software defect prediction [J]. Journal of Software, 2019, 30(10): 3090-3114. 10.13328/j.cnki.jos.005790 | |
| 2 | HALL T, BEECHAM S, BOWES D, et al. A systematic literature review on fault prediction performance in software engineering [J]. IEEE Transactions on Software Engineering, 2012, 38(6): 1276-1304. 10.1109/tse.2011.103 |
| 3 | GONG L N, JIANG S J, BO L L, et al. A novel class-imbalance learning approach for both within-project and cross-project defect prediction [J]. IEEE Transactions on Reliability, 2020, 69(1): 40-54. 10.1109/tr.2019.2895462 |
| 4 | 陈翔,王莉萍,顾庆,等.跨项目软件缺陷预测方法研究综述[J].计算机学报,2018,41(1):254-274. 10.11897/SP.J.1016.2018.00254 |
| CHEN X, WANG L P, GU Q, et al. A survey on cross-project software defect prediction methods [J]. Chinese Journal of Computers, 2018, 41(1): 254-274. 10.11897/SP.J.1016.2018.00254 | |
| 5 | YUAN Z D, CHEN X, CUI Z Q, et al. ALTRA: cross-project software defect prediction via active learning and TrAdaBoost [J]. IEEE Access, 2020, 8: 30037-30049. 10.1109/access.2020.2972644 |
| 6 | PRABHA C L, SHIVAKUMAR N. Software defect prediction using machine learning techniques [C]// Proceedings of the 2020 4th International Conference on Trends in Electronics and Informatics. Piscataway: IEEE, 2020: 728-733. 10.1109/icoei48184.2020.9142909 |
| 7 | SAIFUDIN A, TRISETYARSO A, SUPARTA W, et al. Feature selection in cross-project software defect prediction [J]. Journal of Physics: Conference Series, 2019, 1569(2): Article No.022001. 10.1088/1742-6596/1569/2/022001 |
| 8 | 吴琦.基于迁移学习的跨项目软件缺陷预测[D].长春:吉林大学,2018:12-13. |
| WU Q. Cross-project defect prediction based on transfer learning [D]. Changchun: Jilin University, 2018: 12-13. | |
| 9 | ZIMMERMANN R, NAGAPPAN N, GALL H, et al. Cross-project defect prediction: a large scale experiment on data vs. domain vs. process [C]// Proceeding of the 2009 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering. New York: ACM, 2009: 91-100. 10.1145/1595696.1595713 |
| 10 | HE Z M, SHU F D, YANG Y, et al. An investigation on the feasibility of cross-project defect prediction [J]. Automated Software Engineering, 2012, 19(2): 167-199. 10.1007/s10515-011-0090-3 |
| 11 | TURHAN B. On the dataset shift problem in software engineering prediction models [J]. Empirical Software Engineering, 2012, 17(1/2): 62-74. 10.1007/s10664-011-9182-8 |
| 12 | PETERS F, MENZIES T, MARCUS A. Better cross company defect prediction [C]// Proceedings of the 2013 10th Working Conference on Mining Software Repositories. Piscataway: IEEE, 2013: 409-418. 10.1109/msr.2013.6624057 |
| 13 | NAM J, PAM S J, KIM S. Transfer defect learning [C]// Proceedings of the 2013 35th International Conference on Software Engineering, Piscataway: IEEE, 2013: 382-391. 10.1109/icse.2013.6606584 |
| 14 | PANICHELLA A, OLIVETO R, DE LUCIA A. Cross-project defect prediction models: L’Union fait la force [C]// Proceedings of the 2014 Software Evolution Week — IEEE Conference on Software Maintenance, Reengineering, and Reverse Engineering. Piscataway: IEEE, 2014: 164-173. 10.1109/csmr-wcre.2014.6747166 |
| 15 | 黄琳,荆晓远,董西伟.基于多核集成学习的跨项目软件缺陷预测[J].计算机技术与发展,2019,29(6):27-31. 10.3969/j.issn.1673-629X.2019.06.006 |
| HUANG L, JING X Y, DONG X W, Cross-project software defect prediction based on multiple kernel ensemble learning [J]. Computer Technology and Development, 2019, 29(6): 27-31. 10.3969/j.issn.1673-629X.2019.06.006 | |
| 16 | 刘芳,高兴,周冰,等.基于PCA-ISVM的软件缺陷预测模型[J].计算机仿真,2014,31(3):397-401. 10.3969/j.issn.1006-9348.2014.03.090 |
| LIU F, GAO X, ZHOU B, et al. Software defect prediction model based on PCA-ISVM [J]. Computer Simulation, 2014, 31(3): 397-401. 10.3969/j.issn.1006-9348.2014.03.090 | |
| 17 | 邱少健.基于迁移学习的跨项目软件缺陷预测关键技术研究[D].广州:华南理工大学,2019:40-60. |
| QIU S J. Research on cross-project software defect prediction by transfer learning [D]. Guangzhou: South China University of Technology, 2019: 40-60. | |
| 18 | 倪超,陈翔,刘望舒,等.基于特征迁移和实例迁移的跨项目缺陷预测方法[J].软件学报,2019,30(5):1308-1329. |
| NI C, CHEN X, LIU W S, et al. Cross-project defect prediction method based on feature transfer and instance transfer [J]. Journal of Software, 2019, 30(5): 1308-1329. | |
| 19 | SCHÖLKOPF B, SMOLA A, MÜLLER K R. Kernel principal component analysis [C]// Proceedings of the 1997 International Conference on Artificial Neural Networks, LNCS 1327. Berlin: Springer, 1997: 583-588. |
| [1] | 孙林, 赵婧, 徐久成, 王欣雅. 基于邻域粗糙集和帝王蝶优化的特征选择算法[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1355-1366. |
| [2] | 李晓寒, 贾华丁, 程雪, 李太勇. 基于改进遗传算法和图神经网络的股市波动预测方法[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1624-1633. |
| [3] | 张小清, 王晨曦, 吕彦, 林耀进. 基于ReliefF的层次分类在线流特征选择算法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 688-694. |
| [4] | 轩书婷, 刘惊雷. 基于离散哈希的聚类[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 713-723. |
| [5] | 李懿恒, 杜晨曦, 杨燕燕, 李翔宇. 基于伪标签一致度的不平衡数据特征选择算法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 475-484. |
| [6] | 陈永波, 李巧勤, 刘勇国. 基于动态相关性的特征选择算法[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 109-114. |
| [7] | 湛航, 何朗, 黄樟灿, 李华峰, 张蔷, 谈庆. 改进的基于层次距离的基因表达式编程特征选择分类算法[J]. 计算机应用, 2021, 41(9): 2658-2667. |
| [8] | 祝承, 赵晓琦, 赵丽萍, 焦玉宏, 朱亚飞, 陈建英, 周伟, 谭颖. 基于谱聚类半监督特征选择的功能磁共振成像数据分类[J]. 计算机应用, 2021, 41(8): 2288-2293. |
| [9] | 李蒙蒙, 秦伟, 刘艺, 刁兴春. 结合头脑风暴优化的混合蚁群优化算法[J]. 计算机应用, 2021, 41(8): 2412-2417. |
| [10] | 林筠超, 万源. 基于图结构优化的自适应多度量非监督特征选择方法[J]. 计算机应用, 2021, 41(5): 1282-1289. |
| [11] | 贾鹤鸣, 姜子超, 李瑶, 孙康健. 基于改进斑点鬣狗优化算法的同步优化特征选择[J]. 计算机应用, 2021, 41(5): 1290-1298. |
| [12] | 杨柳, 李云. 混合式的K-匿名特征选择算法[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3521-3526. |
| [13] | 张志浩, 林耀进, 卢舜, 郭晨, 王晨曦. 缺失标记下基于类属属性的多标记特征选择[J]. 计算机应用, 2021, 41(10): 2849-2857. |
| [14] | 黄学雨, 徐浩特, 陶剑文. 具有特征选择的多源自适应分类框架[J]. 计算机应用, 2020, 40(9): 2499-2506. |
| [15] | 顾桐, 许国良, 李万林, 李家浩, 王志愿, 雒江涛. 基于集成LightGBM和贝叶斯优化策略的房价智能评估模型[J]. 计算机应用, 2020, 40(9): 2762-2767. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||