《计算机应用》唯一官方网站 ›› 2021, Vol. 41 ›› Issue (12): 3426-3431.DOI: 10.11772/j.issn.1001-9081.2021060923
• 第十八届中国机器学习会议(CCML 2021) • 上一篇
戴朝霞1, 曹堉栋2, 朱光明2,3, 沈沛意2,3, 徐旭2,4, 梅林2,4, 张亮2,3( )
)
Zhaoxia DAI1, Yudong CAO2, Guangming ZHU2,3, Peiyi SHEN2,3, Xu XU2,4, Lin MEI2,4, Liang ZHANG2,3()
摘要:
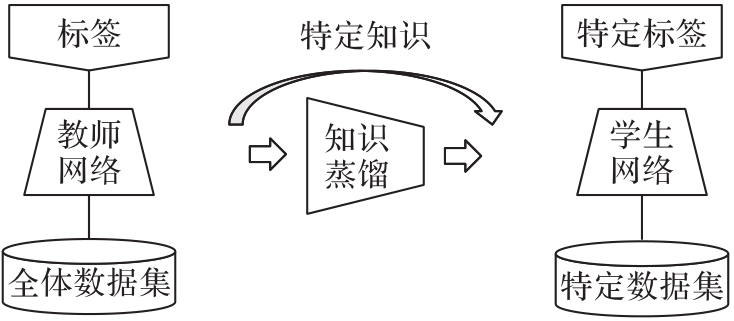
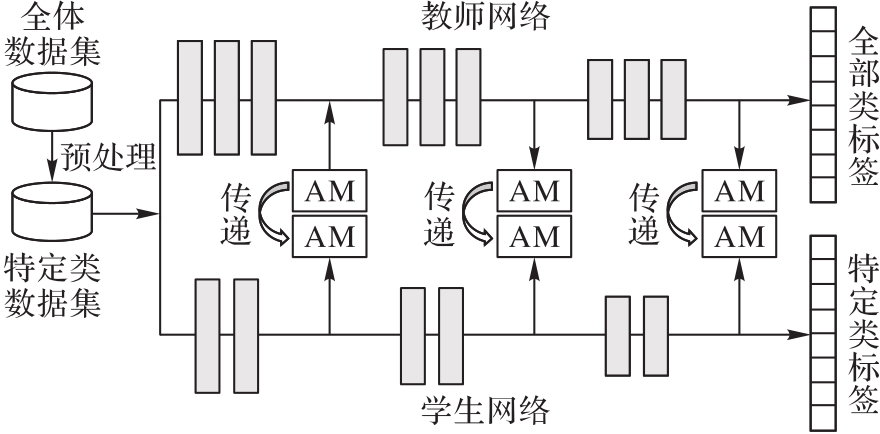
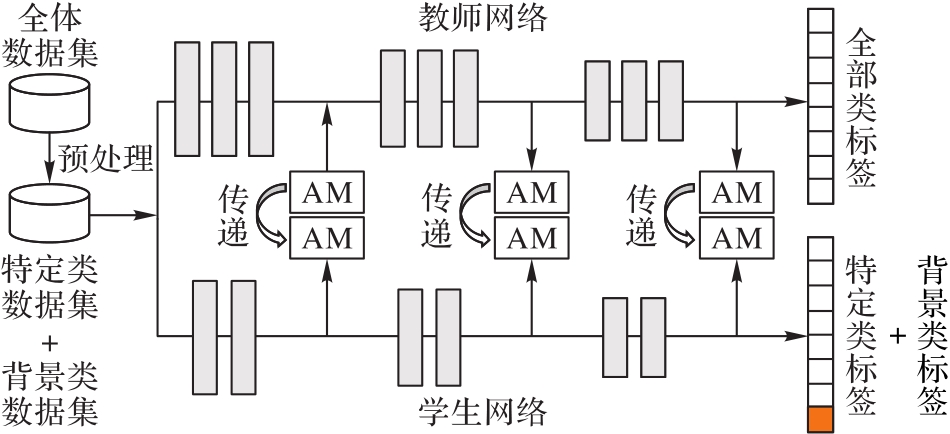
在传统知识蒸馏框架中,教师网络将自身的知识全盘传递给学生网络,而传递部分知识或者特定知识的研究几乎没有。考虑到工业现场具有场景单一、分类数目少的特点,需要重点评估神经网络模型在特定类别领域的识别性能。基于注意力特征迁移蒸馏算法,提出了三种特定知识学习算法来提升学生网络在特定类别分类中的分类性能。首先,对训练数据集作特定类筛选以排除其他非特定类别的训练数据;在此基础上,将其他非特定类别视为背景并在蒸馏过程中抑制背景知识,从而进一步减少其他无关类知识对特定类知识的影响;最后,更改网络结构,即仅在网络高层抑制背景类知识,而保留网络底层基础图形特征的学习。实验结果表明,通过特定知识学习算法训练的学生网络在特定类别分类中能够媲美甚至超越参数规模六倍于它的教师网络的分类性能。
中图分类号: