


《计算机应用》唯一官方网站 ›› 2021, Vol. 41 ›› Issue (12): 3614-3619.DOI: 10.11772/j.issn.1001-9081.2021061082
• 第十八届中国机器学习会议(CCML 2021) • 上一篇
收稿日期:2021-05-12
修回日期:2021-06-24
接受日期:2021-07-21
发布日期:2021-12-28
出版日期:2021-12-10
通讯作者:
孟军
作者简介:纪腾其(1996—),男,山东烟台人,硕士研究生,主要研究方向:生物信息学、机器学习基金资助:
Tengqi JI, Jun MENG( ), Siyuan ZHAO, Hehuan HU
), Siyuan ZHAO, Hehuan HU
Received:2021-05-12
Revised:2021-06-24
Accepted:2021-07-21
Online:2021-12-28
Published:2021-12-10
Contact:
Jun MENG
About author:JI Tengqi, born in 1996, M. S. candidate. His research interests include bioinformatics, machine learning.Supported by:摘要:
长链非编码RNA(lncRNA)中的小开放阅读框(sORFs)能够编码长度不超过100个氨基酸的短肽。针对短肽预测研究中lncRNA中的sORFs特征不鲜明且高可信度数据尚不充分的问题,提出一种基于表示学习的深度森林(DF)模型。首先,使用常规lncRNA特征提取方法对sORFs进行编码;其次,通过自编码器(AE)进行表示学习来获得输入数据的高效表示;最后,训练DF模型实现对lncRNA编码短肽的预测。实验结果表明,该模型在拟南芥数据集上能够达到92.08%的准确率,高于传统机器学习模型、深度学习模型以及组合模型,且具有较好的稳定性;此外,在大豆与玉米数据集上进行的模型测试中,该模型的准确率分别能达到78.16%和74.92%,验证了所提模型良好的泛化能力。
中图分类号:
纪腾其, 孟军, 赵思远, 胡鹤还. 基于表示学习和深度森林的长链非编码RNA编码短肽预测模型[J]. 计算机应用, 2021, 41(12): 3614-3619.
Tengqi JI, Jun MENG, Siyuan ZHAO, Hehuan HU. Prediction model of lncRNA-encoded short peptides based on representation learning and deep forest[J]. Journal of Computer Applications, 2021, 41(12): 3614-3619.
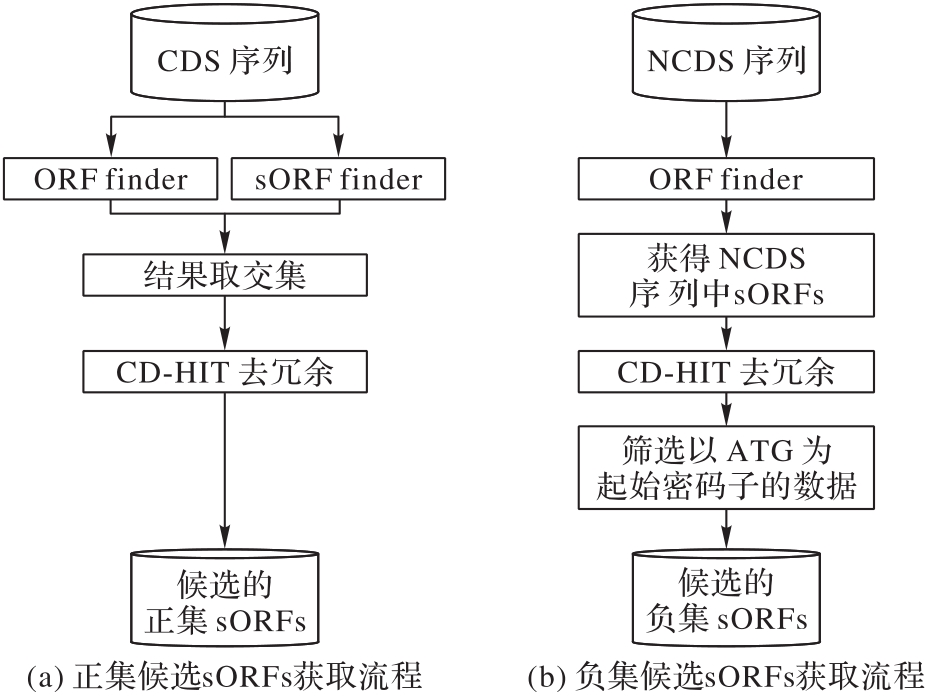
图1 候选sORFs的获取流程
Fig. 1 Process of obtaining candidate sORFs

图2 不同特征编码方式的特征可视化结果
Fig. 2 Feature visualization results for different feature encoding methods

图3 AE流程
Fig. 3 Flowchart of AutoEncoder
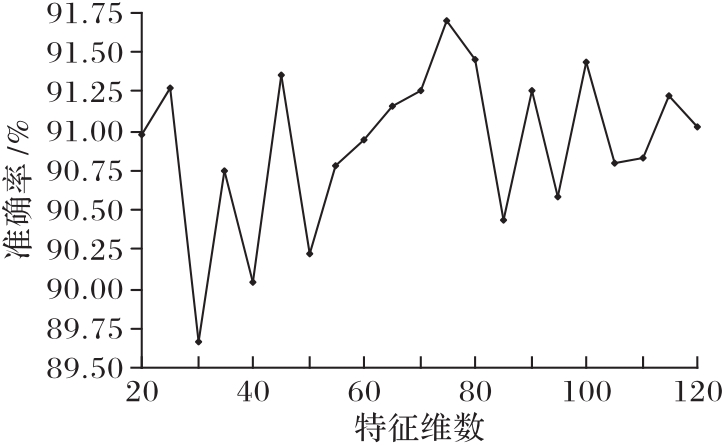
图4 不同维数特征的分类准确率
Fig. 4 Classification accuracy of features with different dimension

图5 模型整体结构
Fig. 5 Overall structure of model
| 真实结果 | 预测结果 | |
|---|---|---|
| Positive Class | Negative Class | |
| Positive Class | TP | FN |
| Negative Class | FP | TN |
表1 分类结果含义
Tab. 1 Meaning of classification results
| 真实结果 | 预测结果 | |
|---|---|---|
| Positive Class | Negative Class | |
| Positive Class | TP | FN |
| Negative Class | FP | TN |
| 模型 | ACC±SD②/% | P±SD/% | R±SD/% | F1±SD/% |
|---|---|---|---|---|
| NB | 76.36±2.8 | 75.91±3.7 | 77.01±4.0 | 76.35±2.8 |
| AE+NB | 76.77±2.6 | 74.00±4.9 | 78.79±5.0 | 76.80±2.6 |
| DT | 83.02±1.9 | 84.80±3.4 | 80.31±2.8 | 83.00±1.9 |
| AE+DT | 86.36±1.3 | 84.70±3.4 | 86.75±1.8 | 86.37±1.3 |
| RF | 86.46±1.3 | 83.45±4.2 | 82.84±2.8 | 86.46±1.3 |
| AE+RF | 87.50±1.6 | 85.46±2.9 | 88.17±2.4 | 87.50±1.6 |
| DF | 87.92±1.6 | 85.77±3.5 | 89.17±3.0 | 87.93±1.6 |
| 本文模型 | 92.08±1.2 | 91.23±1.1 | 92.40±2.6 | 92.08±1.2 |
表2 本文模型与传统机器学习模型及其组合模型以及DF在拟南芥数据集上的结果比较
Tab. 2 Result comparison of the proposed model with traditional machine learning models, their combined models and DF on Arabidopsis thaliana dataset
| 模型 | ACC±SD②/% | P±SD/% | R±SD/% | F1±SD/% |
|---|---|---|---|---|
| NB | 76.36±2.8 | 75.91±3.7 | 77.01±4.0 | 76.35±2.8 |
| AE+NB | 76.77±2.6 | 74.00±4.9 | 78.79±5.0 | 76.80±2.6 |
| DT | 83.02±1.9 | 84.80±3.4 | 80.31±2.8 | 83.00±1.9 |
| AE+DT | 86.36±1.3 | 84.70±3.4 | 86.75±1.8 | 86.37±1.3 |
| RF | 86.46±1.3 | 83.45±4.2 | 82.84±2.8 | 86.46±1.3 |
| AE+RF | 87.50±1.6 | 85.46±2.9 | 88.17±2.4 | 87.50±1.6 |
| DF | 87.92±1.6 | 85.77±3.5 | 89.17±3.0 | 87.93±1.6 |
| 本文模型 | 92.08±1.2 | 91.23±1.1 | 92.40±2.6 | 92.08±1.2 |
| 模型 | ACC±SD/% | P±SD/% | R±SD/% | F1±SD/% |
|---|---|---|---|---|
| CNN | 90.42±2.2 | 91.62±3.3 | 88.64±2.6 | 90.42±2.2 |
| AE+CNN | 91.04±1.9 | 88.75±3.3 | 92.95±2.1 | 91.05±1.9 |
| RNN | 89.48±1.5 | 89.15±2.5 | 89.58±2.6 | 89.49±1.4 |
| AE+RNN | 90.00±1.7 | 89.24±1.5 | 90.65±1.0 | 89.99±1.7 |
| 本文模型 | 92.08±1.2 | 91.23±1.1 | 92.40±2.6 | 92.08±1.2 |
表3 本文模型与深度学习模型及其组合模型在拟南芥数据集上的结果比较
Tab. 3 Result comparison of the proposed model with deep learning models and their combined models on Arabidopsis thaliana dataset
| 模型 | ACC±SD/% | P±SD/% | R±SD/% | F1±SD/% |
|---|---|---|---|---|
| CNN | 90.42±2.2 | 91.62±3.3 | 88.64±2.6 | 90.42±2.2 |
| AE+CNN | 91.04±1.9 | 88.75±3.3 | 92.95±2.1 | 91.05±1.9 |
| RNN | 89.48±1.5 | 89.15±2.5 | 89.58±2.6 | 89.49±1.4 |
| AE+RNN | 90.00±1.7 | 89.24±1.5 | 90.65±1.0 | 89.99±1.7 |
| 本文模型 | 92.08±1.2 | 91.23±1.1 | 92.40±2.6 | 92.08±1.2 |
| 数据集 | ACC/% | P/% | R/% | F1/% |
|---|---|---|---|---|
| Glycine max | 78.16 | 79.65 | 75.63 | 78.14 |
| Zea mays | 74.92 | 72.12 | 81.23 | 74.82 |
表4 本文模型在大豆和玉米数据集上的分类结果
Tab. 4 Classification results of the proposed model on Glycine max and Zea mays datasets
| 数据集 | ACC/% | P/% | R/% | F1/% |
|---|---|---|---|---|
| Glycine max | 78.16 | 79.65 | 75.63 | 78.14 |
| Zea mays | 74.92 | 72.12 | 81.23 | 74.82 |
| 1 | KLEAVELAND B, SHI C Y, STEFANO J, et al. A network of noncoding regulatory RNAs acts in the mammalian brain[J]. Cell, 2018, 174(2): 350-362.e17. 10.1016/j.cell.2018.05.022 |
| 2 | CUI J, JIANG N, MENG J, et al. LncRNA33732‐respiratory burst oxidase module associated with WRKY1 in tomato‐ Phytophthora infestans interactions[J]. The Plant Journal, 2019, 97(5): 933-946. 10.1111/tpj.14173 |
| 3 | RÖHRIG H, SCHMIDT J, MIKLASHEVICHS E, et al. Soybean ENOD40 encodes two peptides that bind to sucrose synthase[J]. Proceedings of the National Academy of Sciences of the United States of America, 2002, 99(4): 1915-1920. 10.1073/pnas.022664799 |
| 4 | LEVINE M T, JONES C D, KERN A D, et al. Novel genes derived from noncoding DNA in Drosophila melanogaster are frequently X-linked and exhibit testis-biased expression[J]. Proceedings of the National Academy of Sciences of the United States of America, 2006, 103(26): 9935-9939. 10.1073/pnas.0509809103 |
| 5 | FESENKO I, KIROV I, KNIAZEV A, et al. Distinct types of short open reading frames are translated in plant cells[J]. Genome Research, 2019, 29(9): 1464-1477. 10.1101/gr.253302.119 |
| 6 | NELSON B R, MAKAREWICH C A, ANDERSON D M, et al. A peptide encoded by a transcript annotated as long noncoding RNA enhances SERCA activity in muscle[J]. Science, 2016, 351(6270): 271-275. 10.1126/science.aad4076 |
| 7 | LIU H Z, ZHOU X, YUAN M Q, et al. ncEP: a manually curated database for experimentally validated ncRNA-encoded proteins or peptides[J]. Journal of Molecular Biology, 2020, 432(11): 3364-3368. 10.1016/j.jmb.2020.02.022 |
| 8 | 常征,孟军,施云生,等. 多特征融合的lncRNA识别与其功能预测[J]. 智能系统学报, 2018, 13(6):68-74. 10.11992/tis.201806008 |
| CHANG Z, MENG J, SHI Y S, et al. LncRNA recognition by fusing multiple features and its function prediction[J]. CAAI Transactions on Intelligent Systems, 2018, 13(6): 68-74. 10.11992/tis.201806008 | |
| 9 | WEKESA J S, MENG J, LUAN Y S. Multi-feature fusion for deep learning to predict plant lncRNA-protein interaction[J]. Genomics, 2020, 112(5): 2928-2936. 10.1016/j.ygeno.2020.05.005 |
| 10 | KANG Q, MENG J, SHI W H, et al. Ensemble deep learning based on multi-level information enhancement and greedy fuzzy decision for plant miRNA-lncRNA interaction prediction[J]. Interdisciplinary Sciences: Computational Life Sciences, 2021, 13(4): 603-614. 10.1007/s12539-021-00434-7 |
| 11 | KARIM S. Exploring plant tolerance to biotic and abiotic stresses[D]. Uppsala: Swedish University of Agricultural Sciences, 2007: 18-23. |
| 12 | ROMBEL I T, SYKES K F, RAYNER S, et al. ORF-FINDER: a vector for high-throughput gene identification[J]. Gene, 2002, 282(1/2): 33-41. 10.1016/s0378-1119(01)00819-8 |
| 13 | HANADA K, AKIYAMA K, SAKURAI T, et al. sORF finder: a program package to identify small open reading frames with high coding potential[J]. Bioinformatics, 2010, 26(3): 399-400. 10.1093/bioinformatics/btp688 |
| 14 | ZHU M M, GRIBSKOV M. MiPepid: MicroPeptide identification tool using machine learning[J]. BMC Bioinformatics, 2019, 20: No.559. 10.1186/s12859-019-3033-9 |
| 15 | DENG J, ZHANG Z X, EYBEN F, et al. Autoencoder-based unsupervised domain adaptation for speech emotion recognition[J]. IEEE Signal Processing Letters, 2014, 21(9): 1068-1072. 10.1109/lsp.2014.2324759 |
| 16 | 樊玮,王慧敏,邢艳. 基于自编码器的多视图属性网络表示学习模型[J]. 计算机应用, 2021, 41(4):1064-1070. |
| FAN W, WANG H M, XING Y. Auto-encoder based multi-view attributed network representation learning model[J]. Journal of Computer Applications, 2021, 41(4):1064-1070. | |
| 17 | YANG J C, MA S P, JIANG X P. Predicting LncRNA-disease association by autoencoder and rotation forest[C]// Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine. Piscataway: IEEE, 2019: 159-164. 10.1109/bibm47256.2019.8983261 |
| 18 | BAEK J, LEE B, KWON S, et al. lncRNAnet: long non-coding RNA identification using deep learning[J]. Bioinformatics, 2018, 34(22): 3889-3897. 10.1093/bioinformatics/bty418 |
| 19 | ZHOU Z H, FENG J. Deep forest[J]. National Science Review, 2019, 6(1): 74-86. 10.1093/nsr/nwy108 |
| 20 | LI Y, ZHANG Q, LIU Z Q, et al. Deep forest ensemble learning for classification of alignments of non-coding RNA sequences based on multi-view structure representations[J]. Briefings in Bioinformatics, 2021, 22(4):. 10.1093/bib/bbaa354 |
| No.bbaa35. 10.1093/bib/bbaa354 | |
| 21 | GOODSTEIN D M, SHU S Q, HOWSON R, et al. Phytozome: a comparative platform for green plant genomics[J]. Nucleic Acids Research, 2012, 40(D1): D1178-D1186. 10.1093/nar/gkr944 |
| 22 | FU L M, NIU B F, ZHU Z W, et al. CD-HIT: accelerated for clustering the next generation sequencing data[J]. Bioinformatics, 2012, 28(23): 3150-3152. 10.1093/bioinformatics/bts565 |
| 23 | NEGRI T D C, ALVES W A L, BUGATTI P H, et al. Pattern recognition analysis on long noncoding RNAs: a tool for prediction in plants[J]. Briefings in Bioinformatics, 2019, 20(2): 682-689. 10.1093/bib/bby034 |
| 24 | YIN C C, YAU S S T. Prediction of protein coding regions by the 3-base periodicity analysis of a DNA sequence[J]. Journal of Theoretical Biology, 2007, 247(4): 687-694. 10.1016/j.jtbi.2007.03.038 |
| 25 | RODRIGUEZ-GALIANO V F, GHIMIRE B, ROGAN J, et al. An assessment of the effectiveness of a random forest classifier for land-cover classification[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2012, 67: 93-104. 10.1016/j.isprsjprs.2011.11.002 |
| 26 | GAO C Z, CHENG Q, HE P, et al. Privacy-preserving Naive Bayes classifiers secure against the substitution-then-comparison attack[J]. Information Sciences, 2018, 444: 72-88. 10.1016/j.ins.2018.02.058 |
| 27 | SAFAVIAN S R, LANDGREBE D. A survey of decision tree classifier methodology[J]. IEEE Transactions on Systems, Man, and Cybernetics, 1991, 21(3): 660-674. 10.1109/21.97458 |
| 28 | CHENG J, WANG P S, LI G, et al. Recent advances in efficient computation of deep convolutional neural networks[J]. Frontiers of Information Technology and Electronic Engineering, 2018, 19(1): 64-77. 10.1631/fitee.1700789 |
| 29 | WILLIAMS R J, ZIPSER D. A learning algorithm for continually running fully recurrent networks[J]. Neural Computation, 1989, 1(2): 270-280. 10.1162/neco.1989.1.2.270 |
| [1] | 代雨柔, 杨庆, 张凤荔, 周帆. 基于自监督学习的社交网络用户轨迹预测模型[J]. 计算机应用, 2021, 41(9): 2545-2551. |
| [2] | 蔡彪, 李蕊岑, 吴媛媛. 相似性特征对链路预测的影响与增强[J]. 计算机应用, 2021, 41(9): 2569-2577. |
| [3] | 安鑫, 杨海娇, 李建华, 任福继. 热安全约束下异构多核系统动态映射方法[J]. 计算机应用, 2021, 41(9): 2631-2638. |
| [4] | 丁尹, 桑楠, 李晓瑜, 吴飞舟. 基于循环神经网络的电信行业容量数据预测方法[J]. 计算机应用, 2021, 41(8): 2373-2378. |
| [5] | 王梓森, 梁英, 刘政君, 谢小杰, 张伟, 史红周. 科研项目同行评议专家学术专长匹配方法[J]. 计算机应用, 2021, 41(8): 2418-2426. |
| [6] | 张元钧, 张曦煌. 基于图卷积与长短期记忆网络的动态网络表示学习模型[J]. 计算机应用, 2021, 41(7): 1857-1864. |
| [7] | 张萌, 李维华. 用户互动表示下的影响力最大化算法[J]. 计算机应用, 2021, 41(7): 1964-1969. |
| [8] | 李洋莹, 陈智军, 张子豪, 游兰. 基于改进Elman神经网络的制糖企业原糖需求预测模型[J]. 计算机应用, 2021, 41(7): 2113-2120. |
| [9] | 武维, 李泽平, 杨华蔚, 林川, 王忠德. 融合内容特征和时序信息的深度注意力视频流行度预测模型[J]. 计算机应用, 2021, 41(7): 1878-1884. |
| [10] | 张蓉, 张献国. 基于层次异构图注意力网络的虚假评论检测[J]. 计算机应用, 2021, 41(5): 1275-1281. |
| [11] | 徐国保, 陈媛晓, 王骥. 基于图卷积网络的药物靶标关联预测算法[J]. 计算机应用, 2021, 41(5): 1522-1526. |
| [12] | 倪水平, 李慧芳. 基于一维卷积神经网络与长短期记忆网络结合的电池荷电状态预测方法[J]. 计算机应用, 2021, 41(5): 1514-1521. |
| [13] | 李旭娟, 皮建勇, 黄飞翔, 贾海朋. 基于自生成深度神经网络的4D航迹预测[J]. 计算机应用, 2021, 41(5): 1492-1499. |
| [14] | 余东昌, 赵文芳, 聂凯, 张舸. 基于LightGBM算法的能见度预测模型[J]. 计算机应用, 2021, 41(4): 1035-1041. |
| [15] | 樊玮, 王慧敏, 邢艳. 基于自编码器的多视图属性网络表示学习模型[J]. 计算机应用, 2021, 41(4): 1064-1070. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||