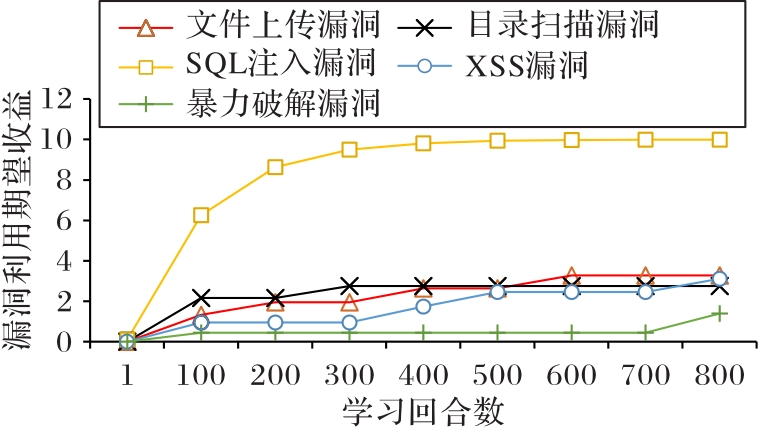
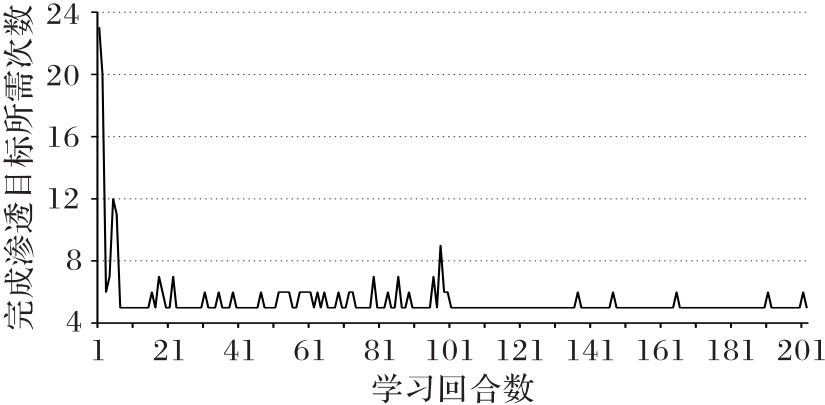
| [1] |
邓世权, 叶绪国. 基于深度Q网络的多目标任务卸载算法[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1668-1674. |
| [2] |
邓绍斌, 朱军, 周晓锋, 李帅, 刘舒锐. 基于局部策略交互探索的深度确定性策略梯度的工业过程控制方法[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1642-1648. |
| [3] |
陈浩杰, 范江亭, 刘勇. 深度强化学习解决动态旅行商问题[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1194-1200. |
| [4] |
李学明, 吴国豪, 周尚波, 林晓然, 谢洪斌. 基于分数阶网络和强化学习的图像实例分割模型[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 574-583. |
| [5] |
曾柏森, 钟勇, 牛宪华. 基于因子分解机用于安全探索的Q表初始化方法[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 209-214. |
| [6] |
王宇, 刘燕丽, 陈劭武. 基于顶点冲突学习的最大公共子图算法[J]. 计算机应用, 2021, 41(6): 1756-1760. |
| [7] |
王建平, 王刚, 毛晓彬, 马恩琪. 基于深度强化学习的二连杆机械臂运动控制方法[J]. 计算机应用, 2021, 41(6): 1799-1804. |
| [8] |
杜嘻嘻, 程华, 房一泉. 基于优势演员-评论家算法的强化自动摘要模型[J]. 计算机应用, 2021, 41(3): 699-705. |
| [9] |
刘思嘉, 童向荣. 基于强化学习的城市交通路径规划[J]. 计算机应用, 2021, 41(1): 185-190. |
| [10] |
姚兴虎, 谭晓阳. 基于奖励高速路网络的多智能体强化学习中的全局信用分配算法[J]. 计算机应用, 2021, 41(1): 1-7. |
| [11] |
傅魁, 梁少晴, 李冰. 基于改进的深度Q网络结构的商品推荐模型[J]. 计算机应用, 2020, 40(9): 2613-2621. |
| [12] |
胡学敏, 成煜, 陈国文, 张若晗, 童秀迟. 基于深度时空Q网络的定向导航自动驾驶运动规划[J]. 计算机应用, 2020, 40(7): 1919-1925. |
| [13] |
郑延斌, 樊文鑫, 韩梦云, 陶雪丽. 基于博弈论及Q学习的多Agent协作追捕算法[J]. 计算机应用, 2020, 40(6): 1613-1620. |
| [14] |
任娜, 张楠, 崔妍, 张融雪, 庞新富. 面向无人机电力巡检的语义实体构建及航迹控制方法[J]. 计算机应用, 2020, 40(10): 3095-3100. |
| [15] |
陈佳沣, 滕冲. 基于强化学习的实体关系联合抽取模型[J]. 计算机应用, 2019, 39(7): 1918-1924. |


 )
)