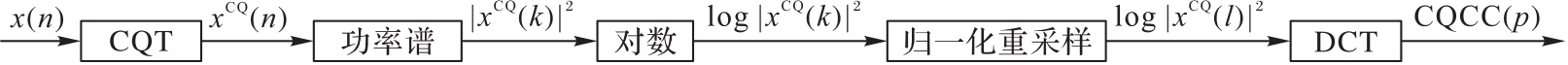| [1] |
张杨, 郝江波. 基于注意力机制和残差网络的恶意代码检测方法[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1708-1715. |
| [2] |
王汇丰, 徐岩, 魏一铭, 王会真. 基于并联卷积与残差网络的图像超分辨率重建[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1570-1576. |
| [3] |
包银鑫, 曹阳, 施佺. 基于改进时空残差卷积神经网络的城市路网短时交通流预测[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 258-264. |
| [4] |
王贺兵, 张春梅. 基于非对称卷积-压缩激发-次代残差网络的人脸关键点检测[J]. 计算机应用, 2021, 41(9): 2741-2747. |
| [5] |
刘世泽, 朱奕达, 陈润泽, 罗海勇, 赵方, 孙艺, 王宝会. 基于残差时域注意力神经网络的交通模式识别算法[J]. 计算机应用, 2021, 41(6): 1557-1565. |
| [6] |
刘世泽, 秦艳君, 王晨星, 高存远, 罗海勇, 赵方, 王宝会. 基于多尺度特征提取的交通模式识别算法[J]. 计算机应用, 2021, 41(6): 1573-1580. |
| [7] |
任奕茗, 王让定, 严迪群, 林昱臻. 基于深度残差网络的语音隐写分析方法[J]. 计算机应用, 2021, 41(3): 774-779. |
| [8] |
王永金, 左羽, 吴恋, 崔忠伟, 赵晨洁. 基于注意力机制的图像超分辨率重建[J]. 计算机应用, 2021, 41(3): 845-850. |
| [9] |
钟莎, 黄玉清. 基于孪生区域候选网络的无人机指定目标跟踪[J]. 计算机应用, 2021, 41(2): 523-529. |
| [10] |
佘玉龙, 张晓龙, 程若勤, 邓春华. 基于边缘关注模型的语义分割方法[J]. 计算机应用, 2021, 41(2): 343-349. |
| [11] |
陈朗, 王让定, 严迪群, 林昱臻. 融合残差网络和极限梯度提升的音频隐写检测模型[J]. 计算机应用, 2021, 41(2): 449-455. |
| [12] |
王海勇, 张开心, 管维正. 基于密集Inception的单图像超分辨率重建方法[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3666-3671. |
| [13] |
戴朝霞, 曹堉栋, 朱光明, 沈沛意, 徐旭, 梅林, 张亮. 基于知识蒸馏的特定知识学习[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3426-3431. |
| [14] |
闵鑫, 王海鹏, 牟长宁. 基于多头注意力机制和残差神经网络的肽谱匹配打分算法[J]. 计算机应用, 2020, 40(6): 1830-1836. |
| [15] |
代强, 程曦, 王永梅, 牛子未, 刘飞. 基于轻量自动残差缩放网络的图像超分辨率重建[J]. 计算机应用, 2020, 40(5): 1446-1452. |


 )
)