《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (9): 2713-2721.DOI: 10.11772/j.issn.1001-9081.2021071311
• 数据科学与技术 • 上一篇
Jun WU( ), Aijia OUYANG, Lin ZHANG
), Aijia OUYANG, Lin ZHANG
摘要:
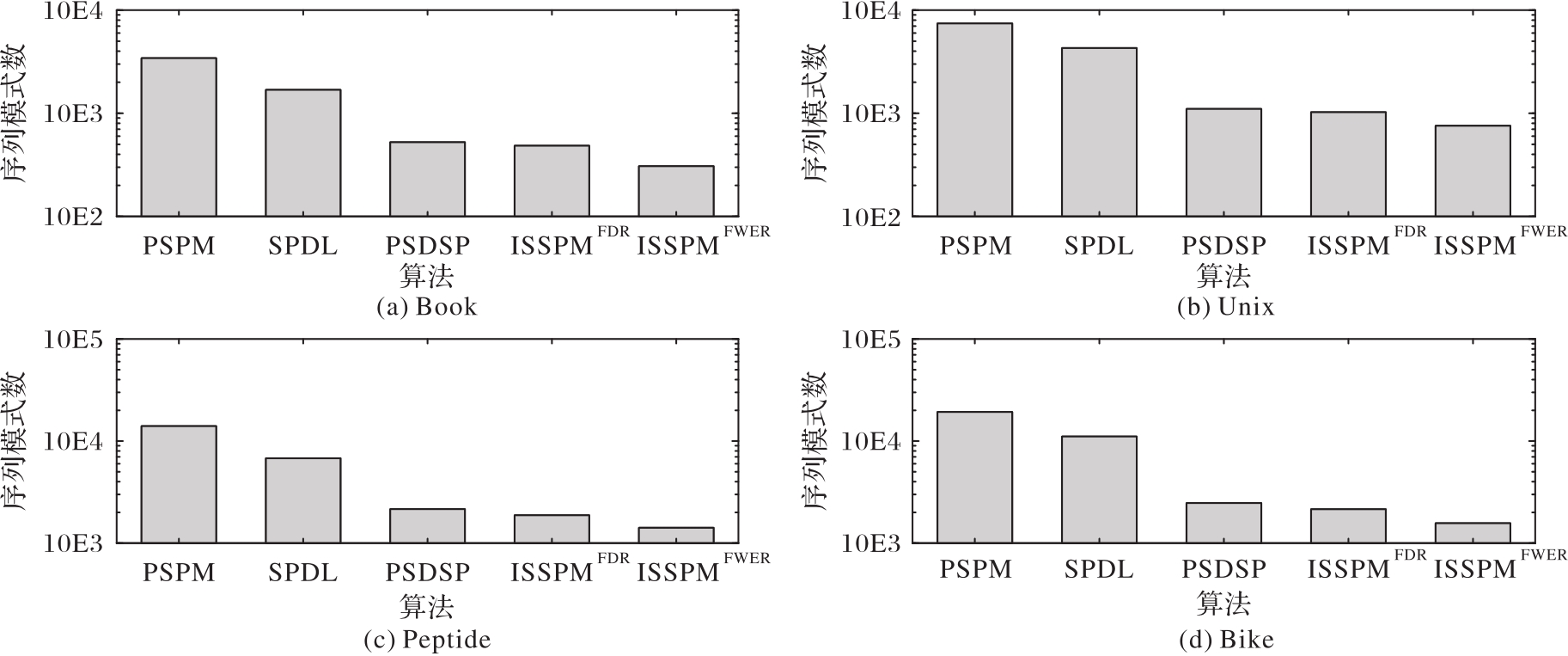
针对传统序列模式挖掘算法中支持度不能如实体现序列模式兴趣度以及未对报告的序列模式进行质量评估的问题,提出一个基于影响度的统计显著序列模式挖掘算法ISSPM。首先,递归地挖掘出所有满足兴趣度约束的序列模式;然后,使用项集置换方法构建这些序列模式的置换检验零分布;最后,通过该零分布计算出被评估的序列模式的统计度量值,并从上述序列模式中找到所有统计显著序列模式。真实序列记录集合上的实验结果表明,ISSPM算法相较于PSPM、SPDL和PSDSP算法挖掘到的序列模式数量更少但兴趣度更强;仿真序列记录集合上的实验结果表明,ISSPM算法报告的结果中假阳性序列模式数量平均占比为3.39%,且该算法的嵌入模式的发现率均不低于66.7%,明显优于上述3个对比算法。可见,ISSPM算法报告的统计显著序列模式能够体现序列记录集合中更有价值的信息,同时根据这些信息做出的进一步分析和决策也更加可靠。
中图分类号: