


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (10): 2990-2995.DOI: 10.11772/j.issn.1001-9081.2021081521
收稿日期:2021-08-26
修回日期:2021-12-03
接受日期:2021-12-06
发布日期:2022-01-07
出版日期:2022-10-10
通讯作者:
向阳
作者简介:第一联系人:罗萍(1997—),女,安徽黄山人,硕士研究生,主要研究方向:自然语言处理、信息抽取、事件抽取基金资助:Ping LUO1, Ling DING1, Xue YANG2, Yang XIANG1
Received:2021-08-26
Revised:2021-12-03
Accepted:2021-12-06
Online:2022-01-07
Published:2022-10-10
Contact:
Yang XIANG
About author:LUO Ping, born in 1997, M. S. candidate. Her research interests include natural language processing, information extraction, event extraction.Supported by:摘要:
当前的事件检测模型严重依赖于人工标注的数据,在标注数据规模有限的情况下,事件检测任务中基于完全监督方法的深度学习模型经常会出现过拟合的问题,而基于弱监督学习的使用自动标注数据代替耗时的人工标注数据的方法又常常依赖于复杂的预定义规则。为了解决上述问题,就中文事件检测任务提出了一种基于BERT的混合文本对抗训练(BMAD)方法。所提方法基于数据增强和对抗学习设定了弱监督学习场景,并采用跨度抽取模型来完成事件检测任务。首先,为改善数据不足的问题,采用回译、Mix-Text等数据增强方法来增强数据并为事件检测任务创建弱监督学习场景;然后,使用一种对抗训练机制进行噪声学习,力求最大限度地生成近似真实样本的生成样本,并最终提高整个模型的鲁棒性。在广泛使用的真实数据集自动文档抽取(ACE)2005上进行实验,结果表明相较于NPN、TLNN、HCBNN等算法,所提方法在F1分数上获取了至少0.84个百分点的提升。
中图分类号:
罗萍, 丁玲, 杨雪, 向阳. 基于数据增强和弱监督对抗训练的中文事件检测[J]. 计算机应用, 2022, 42(10): 2990-2995.
Ping LUO, Ling DING, Xue YANG, Yang XIANG. Chinese event detection based on data augmentation and weakly supervised adversarial training[J]. Journal of Computer Applications, 2022, 42(10): 2990-2995.
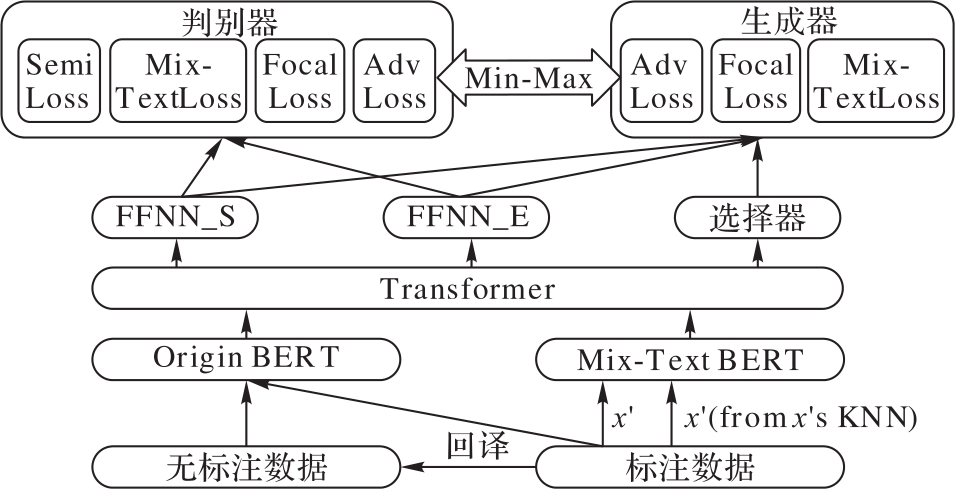
图1 BMAD模型整体结构
Fig. 1 Overall structure of BMAD model
| 模型 | P | R | F1 |
|---|---|---|---|
| HNN[ | 77.10 | 53.10 | 63.00 |
| NPN[ | 60.90 | 69.30 | 64.80 |
| TLNN[ | 64.45 | 71.47 | 67.78 |
| HCBNN[ | 66.40 | 76.00 | 70.90 |
| BMAD | 73.94 | 69.67 | 71.74 |
表1 ACE2005上触发词分类任务上的实验结果 (%)
Tab. 1 Experimental results on trigger classification task on ACE2005
| 模型 | P | R | F1 |
|---|---|---|---|
| HNN[ | 77.10 | 53.10 | 63.00 |
| NPN[ | 60.90 | 69.30 | 64.80 |
| TLNN[ | 64.45 | 71.47 | 67.78 |
| HCBNN[ | 66.40 | 76.00 | 70.90 |
| BMAD | 73.94 | 69.67 | 71.74 |
| 模型 | P | R | F1 |
|---|---|---|---|
| Baseline | 71.78 | 65.66 | 68.59 |
| Baseline + Semi | 72.80 | 66.42 | 69.46 |
| Baseline + Mix | 75.49 | 67.17 | 71.09 |
| Baseline + Semi + Mix | 72.97 | 69.67 | 71.28 |
| BMAD (Baseline + Semi + Mix + Adv) | 73.94 | 69.67 | 71.74 |
表2 消融实验结果 ( %)
Tab. 2 Ablation experimental results
| 模型 | P | R | F1 |
|---|---|---|---|
| Baseline | 71.78 | 65.66 | 68.59 |
| Baseline + Semi | 72.80 | 66.42 | 69.46 |
| Baseline + Mix | 75.49 | 67.17 | 71.09 |
| Baseline + Semi + Mix | 72.97 | 69.67 | 71.28 |
| BMAD (Baseline + Semi + Mix + Adv) | 73.94 | 69.67 | 71.74 |
| 1 | 贺瑞芳, 段绍杨. 基于多任务学习的中文事件抽取联合模型[J]. 软件学报, 2019, 30(4):1015-1030. |
| HE R F, DUAN S Y. Joint Chinese event extraction based multi-task learning[J]. Journal of Software, 2019, 30(4): 1015-1030. | |
| 2 | YANG H, CHUA T S, WANG S G, et al. Structured use of external knowledge for event-based open domain question answering[C]// Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2003:33-40. 10.1145/860435.860444 |
| 3 | BASILE P, CAPUTO A, SEMERARO G, et al. Time event extraction to boost an information retrieval system[M]// LAI C, GIULIANI A, SEMERARO G. Information Filtering and Retrieval, SCI 668. Cham: Springer International Publishing, 2017 :1-12. |
| 4 | CHENG P X, ERK K. Implicit argument prediction with event knowledge[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 831-840. 10.18653/v1/n18-1076 |
| 5 | AHN D. The stages of event extraction[C]// Proceedings of the 2006 Workshop on Annotating and Reasoning about Time and Events. Stroudsburg, PA: Association for Computational Linguistics, 2006: 1-8. 10.3115/1629235.1629236 |
| 6 | JI H, GRISHMAN R. Refining event extraction through cross-document inference[C]// Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2008: 254-262. 10.3115/1564169 |
| 7 | LI Q, JI H, HUANG L. Joint event extraction via structured prediction with global features[C]// Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2013: 73-82. |
| 8 | ARAKI J, MITAMURA T. Joint event trigger identification and event coreference resolution with structured perceptron[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 2074-2080. 10.18653/v1/d15-1247 |
| 9 | NGUYEN T H, GRISHMAN R. Event detection and domain adaptation with convolutional neural networks[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2015: 365-371. 10.3115/v1/p15-2060 |
| 10 | GHAEINI R, FERN X, HUANG L, et al. Event nugget detection with forward-backward recurrent neural networks[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 369-373. 10.18653/v1/p16-2060 |
| 11 | WADDEN D, WENNBERG U, LUAN Y, et al. Entity, relation, and event extraction with contextualized span representations[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 5784-5789. 10.18653/v1/d19-1585 |
| 12 | CAO P F, CHEN Y B, ZHAO J, et al. Incremental event detection via knowledge consolidation networks[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2020: 707-717. 10.18653/v1/2020.emnlp-main.52 |
| 13 | WANG Z Q, WANG X Z, HAN X, et al. CLEVE: contrastive pre-training for event extraction[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2021: 6283-6297. 10.18653/v1/2021.acl-long.491 |
| 14 | XIE Q Z, DAI Z H, HOVY E, et al. Unsupervised data augmentation for consistency training[C/OL]// Proceedings of the 34th Conference on Neural Information Processing Systems. [2021-04-29].. |
| 15 | ABDULMUMIN I, GALADANCI B S, ISA A. Iterative batch back-translation for neural machine translation: a conceptual model[EB/OL]. (2019-11-26) [2021-10-10].. 10.1007/s10590-021-09284-y |
| 16 | PATWARDHAN S, RILOFF E. A unified model of phrasal and sentential evidence for information extraction[C]// Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2009: 151-160. 10.3115/1699510.1699530 |
| 17 | LIAO S S, GRISHMAN R. Using document level cross-event inference to improve event extraction[C]// Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2010: 789-797. |
| 18 | McCLOSKY D, SURDEANU M, MANNING C D. Event extraction as dependency parsing[C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 1626-1635. |
| 19 | HONG Y, ZHANG J F, MA B, et al. Using cross-entity inference to improve event extraction[C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 1127-1136. |
| 20 | HUANG R H, RILOFF E. Modeling textual cohesion for event extraction[C]// Proceedings of the 26th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2012: 1664-1670. |
| 21 | LI Q, JI H, HONG Y, et al. Constructing information networks using one single model[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1846-1851. 10.3115/v1/d14-1198 |
| 22 | CHEN Y B, XU L H, LIU K, et al. Event extraction via dynamic multi-pooling convolutional neural networks[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2015: 167-176. 10.3115/v1/p15-1017 |
| 23 | NGUYEN T H, GRISHMAN R. Modeling skip-grams for event detection with convolutional neural networks[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2016: 886-891. 10.18653/v1/d16-1085 |
| 24 | LIU S L, CHEN Y B, LIU K, et al. Exploiting argument information to improve event detection via supervised attention mechanisms[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 1789-1798. 10.18653/v1/p17-1164 |
| 25 | LIU S B, CHENG R, YU X M, et al. Exploiting contextual information via dynamic memory network for event detection[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 1030-1035. 10.18653/v1/d18-1127 |
| 26 | YAN H R, JIN X L, MENG X B, et al. Event detection with multi-order graph convolution and aggregated attention[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 5766-5770. 10.18653/v1/d19-1582 |
| 27 | WANG Z H, GUO Y, WANG J H. Empower Chinese event detection with improved atrous convolution neural networks[J]. Neural Computing and Applications, 2021, 33(11): 5805-5820. 10.1007/s00521-020-05360-1 |
| 28 | CHEN Y B, LIU S L, ZHANG X, et al. Automatically labeled data generation for large scale event extraction[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 409-419. 10.18653/v1/p17-1038 |
| 29 | ARAKI J, MITAMURA T. Open-domain event detection using distant supervision[C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 878-891. |
| 30 | ZENG Y, FENG Y S, MA R, et al. Scale up event extraction learning via automatic training data generation[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 6045-6052. 10.1609/aaai.v32i1.12030 |
| 31 | HUANG L F, JI H. Semi-supervised new event type induction and event detection[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2020: 718-724. 10.18653/v1/2020.emnlp-main.53 |
| 32 | SHAO Z H, SHANG L F, LIU Q, et al. A mutual information maximization approach for the spurious solution problem in weakly supervised question answering[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2021: 4111-4124. 10.18653/v1/2021.acl-long.318 |
| 33 | GOOGFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014:2672-2680. |
| 34 | HONG Y, ZHOU W X, ZHANG J L, et al. Self-regulation: employing a generative adversarial network to improve event detection[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 515-526. 10.18653/v1/p18-1048 |
| 35 | WANG X Z, HAN X, LIU Z Y, et al. Adversarial training for weakly supervised event detection[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 998-1008. 10.18653/v1/n18-2 |
| 36 | MA X Y, SHEN Y L, FANG G F, et al. Adversarial self-supervised data-free distillation for text classification[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2020: 6182-6192. 10.18653/v1/2020.emnlp-main.499 |
| 37 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional trans-formers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 38 | YU J T, BOHNET B, POESIO M. Named entity recognition as dependency parsing[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 6470-6476. 10.18653/v1/2020.acl-main.577 |
| 39 | CHEN J A, YANG Z C, YANG D Y. MixText: linguistically-informed interpolation of hidden space for semi-supervised text classification[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 2147-2157. 10.18653/v1/2020.acl-main.194 |
| 40 | CHEN J A, WANG Z H, TIAN R, et al. Local additivity based data augmentation for semi-supervised NER[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2020: 1241-1251. 10.18653/v1/2020.emnlp-main.95 |
| 41 | FENG X C, QIN B, LIU T. A language-independent neural network for event detection[J]. Science China (Information Sciences), 2018, 61(9): No.92106. 10.1007/s11432-017-9359-x |
| 42 | LIN H Y, LU Y J, HAN X P, et al. Nugget proposal networks for Chinese event detection[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 1565-1574. 10.18653/v1/p18-1145 |
| 43 | DING N, LI Z R, LIU Z Y, et al. Event detection with trigger-aware lattice neural network[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. PA: Association for Computational Linguistics, 2019: 347-356. 10.18653/v1/d19-1033 |
| 44 | XI X Y, ZHANG T, YE W, et al. A hybrid character representation for Chinese event detection[C]// Proceedings of the 2019 International Joint Conference on Neural Networks. Piscataway: IEEE, 2019: 1-8. 10.1109/ijcnn.2019.8851786 |
| [1] | 孙邱杰, 梁景贵, 李思. 基于BART噪声器的中文语法纠错模型[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 860-866. |
| [2] | 曹一珉, 蔡磊, 高敬阳. 基于生成对抗网络的基因数据生成方法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 783-790. |
| [3] | 彭禹, 宋耀莲, 杨俊. 基于数据增强的运动想象脑电分类[J]. 《计算机应用》唯一官方网站, 2022, 42(11): 3625-3632. |
| [4] | 邓爽, 何小海, 卿粼波, 陈洪刚, 滕奇志. 基于改进VGG网络的弱监督细粒度阿尔兹海默症分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 302-309. |
| [5] | 贾承勋, 赖华, 余正涛, 文永华, 于志强. 融合单语语言模型的汉越伪平行语料生成[J]. 计算机应用, 2021, 41(6): 1652-1658. |
| [6] | 甘岚, 沈鸿飞, 王瑶, 张跃进. 基于改进DCGAN的数据增强方法[J]. 计算机应用, 2021, 41(5): 1305-1313. |
| [7] | 陆鑫伟, 余鹏飞, 李海燕, 李红松, 丁文谦. 基于注意力自身线性融合的弱监督细粒度图像分类算法[J]. 计算机应用, 2021, 41(5): 1319-1325. |
| [8] | 霍首君, 郝琰, 石慧宇, 董艳清, 曹锐. 基于深度卷积网络的运动想象脑电信号模式识别[J]. 计算机应用, 2021, 41(4): 1042-1048. |
| [9] | 崔博文, 金涛, 王建民. 自由文本电子病历信息抽取综述[J]. 计算机应用, 2021, 41(4): 1055-1063. |
| [10] | 蒋宁, 方景龙, 杨庆. 基于单点多盒检测器的全局-局部层级的域适应目标检测[J]. 计算机应用, 2021, 41(2): 517-522. |
| [11] | 龚云鹏, 曾智勇, 叶锋. 基于灰度域特征增强的行人重识别方法[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3590-3595. |
| [12] | 陈莉, 王洪元, 张云鹏, 曹亮, 殷雨昌. 联合均等采样随机擦除和全局时间特征池化的视频行人重识别方法[J]. 计算机应用, 2021, 41(1): 164-169. |
| [13] | 陈佛计, 朱枫, 吴清潇, 郝颖明, 王恩德. 基于生成对抗网络的红外图像数据增强[J]. 计算机应用, 2020, 40(7): 2084-2088. |
| [14] | 程广涛, 巩家昌, 李建. 基于稠密卷积神经网络的烟雾识别方法[J]. 计算机应用, 2020, 40(5): 1465-1469. |
| [15] | 谌贵辉, 易欣, 李忠兵, 钱济人, 陈伍. 基于改进YOLOv2和迁移学习的管道巡检航拍图像第三方施工目标检测[J]. 计算机应用, 2020, 40(4): 1062-1068. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||