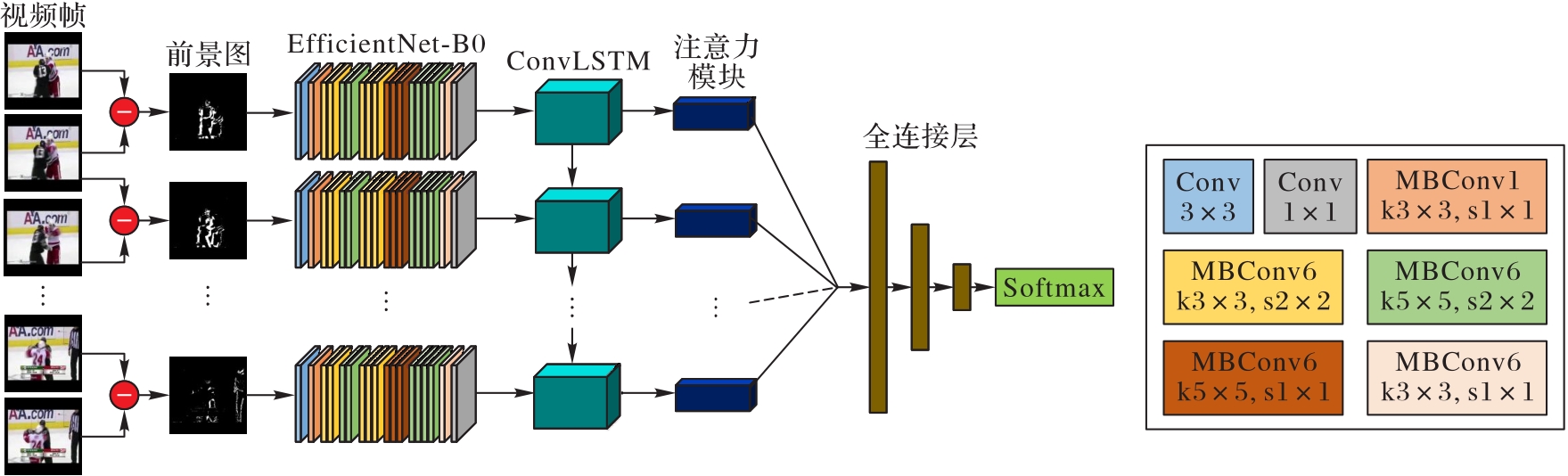
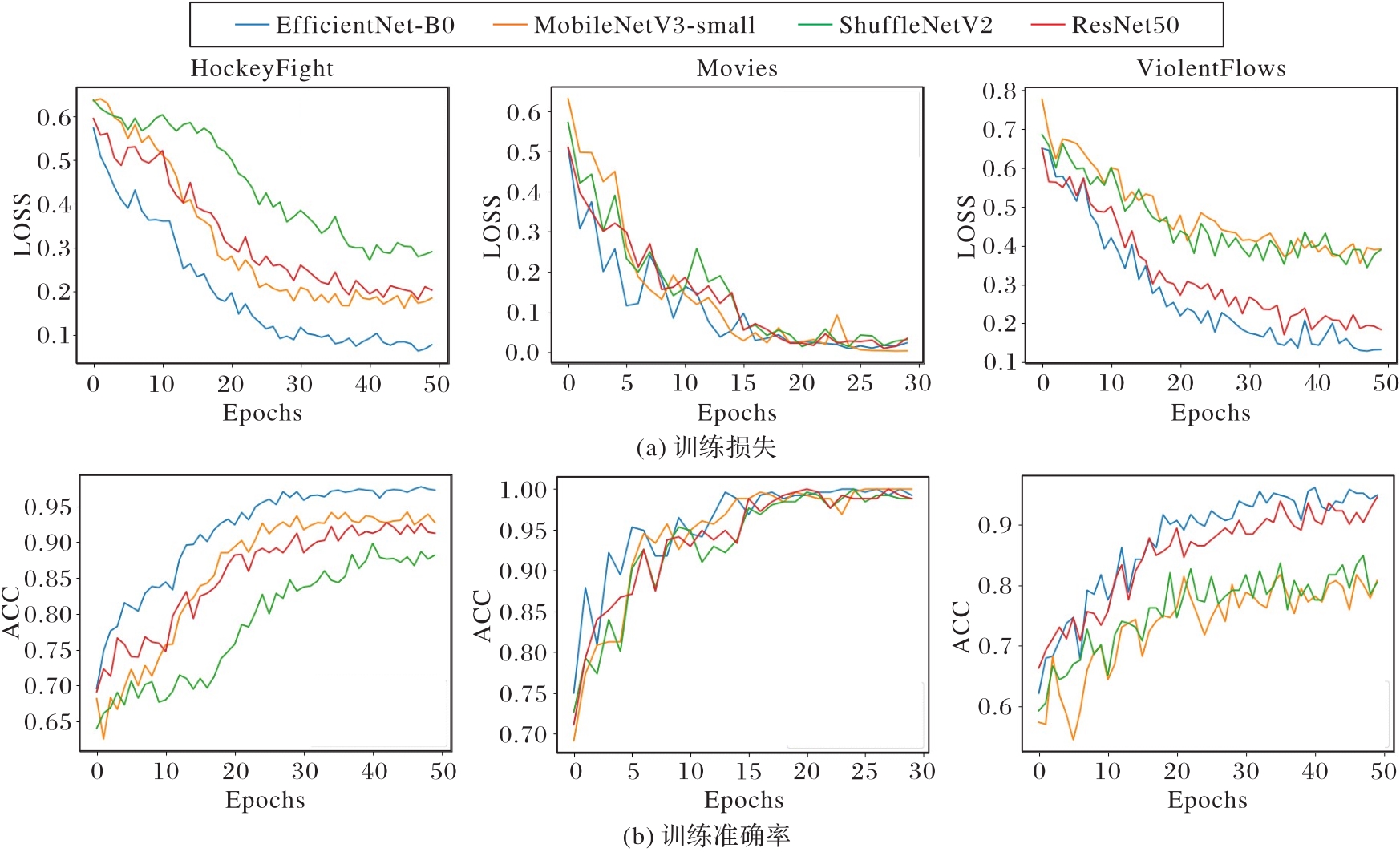
| 1 |
SUDHAKARAN S, LANZ O. Learning to detect violent videos using convolutional long short-term memory[C]// Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway: IEEE, 2017: 1-6. 10.1109/avss.2017.8078468
|
| 2 |
杨亚虎,王瑜,陈天华. 基于深度学习的远程视频监控异常图像检测[J]. 电讯技术, 2021, 61(2): 203-210. 10.3969/j.issn.1001-893x.2021.02.012
|
|
YANG Y H, WANG Y, CHEN T H. Detection of abnormal remote video surveillance image based on deep learning[J]. Telecommunication Engineering, 2021, 61(2): 203-210. 10.3969/j.issn.1001-893x.2021.02.012
|
| 3 |
卢修生,姚鸿勋. 视频中动作识别任务综述[J]. 智能计算机与应用, 2020, 10(3): 406-411. 10.3969/j.issn.2095-2163.2020.03.089
|
|
LU X S, YAO H X. A survey of action recognition in videos[J]. Intelligent Computer and Applications, 2020, 10(3): 406-411. 10.3969/j.issn.2095-2163.2020.03.089
|
| 4 |
谭等泰,王炜,王轶群. 治安监控视频中暴力行为的识别与检测[J]. 中国人民公安大学学报(自然科学版), 2021, 27(2): 94-100. 10.3969/j.issn.1007-1784.2021.02.014
|
|
TAN D T, WANG W, WANG Y Q. Recognition and detection of violence in public security surveillance video[J]. Journal of People’s Public Security University of China (Science and Technology), 2021, 27(2): 94-100. 10.3969/j.issn.1007-1784.2021.02.014
|
| 5 |
SARMAN S, SERT M. Audio based violent scene classification using ensemble learning[C]// Proceedings of the 6th International Symposium on Digital Forensic and Security. Piscataway: IEEE, 2018: 1-5. 10.1109/isdfs.2018.8355393
|
| 6 |
杨吕祥. 基于改进的CRNN的暴力音频事件检测方法研究[D]. 武汉:武汉理工大学, 2019.
|
|
YANG L X. Research on violent sound event detection based on improved CRNN[D]. Wuhan: Wuhan University of Technology, 2019.
|
| 7 |
ACAR E, HOPFGARTNER F, ALBAYRAK S. Violence detection in Hollywood movies by the fusion of visual and mid-level audio cues[C]// Proceedings of the 21st ACM International Conference on Multimedia. New York: ACM, 2013: 717-720. 10.1145/2502081.2502187
|
| 8 |
谷学汇. 基于信息融合算法的暴力视频内容识别[J]. 济南大学学报(自然科学版), 2019, 33(3): 224-228. 10.13349/j.cnki.jdxbn.2019.03.005
|
|
GU X H. Information composite technology in violent video content recognition[J]. Journal of University of Jinan (Science and Technology), 2019, 33(3): 224-228. 10.13349/j.cnki.jdxbn.2019.03.005
|
| 9 |
GAO Y, LIU H, SUN X H, et al. Violence detection using oriented violent flows[J]. Image and Vision Computing, 2016, 48/49: 37-41. 10.1016/j.imavis.2016.01.006
|
| 10 |
宋凯. 面向视频监控的暴力行为检测技术研究[D]. 哈尔滨:哈尔滨工程大学, 2018.
|
|
SONG K. Research on detection technology of violence in the background of monitoring[D]. Harbin: Harbin Engineering University, 2018.
|
| 11 |
MABROUK A BEN, ZAGROUBA E. Spatio-temporal feature using optical flow based distribution for violence detection[J]. Pattern Recognition Letters, 2017, 92: 62-67. 10.1016/j.patrec.2017.04.015
|
| 12 |
ZHANG T, JIA W J, YANG B Q, et al. MoWLD: a robust motion image descriptor for violence detection[J]. Multimedia Tools and Applications, 2017, 76(1): 1419-1438. 10.1007/s11042-015-3133-0
|
| 13 |
丁春辉. 基于深度学习的暴力检测及人脸识别方法研究[D]. 合肥:中国科学技术大学, 2017.
|
|
DING C H. Violence detection and face recognition based on deep learning method[D]. Hefei: University of Science and Technology of China, 2017.
|
| 14 |
DONG Z H, QIN J, WANG Y H. Multi-stream deep networks for person to person violence detection in videos[C]// Proceedings of the 2016 Chinese Conference on Pattern Recognition, CCIS 662. Singapore: Springer, 2016: 517-531.
|
| 15 |
CHATTERJEE R, HALDER R. Discrete wavelet transform for CNN-BiLSTM-based violence detection[C]// Proceedings of the 2020 International Conference on Emerging Trends and Advances in Electrical Engineering and Renewable Energy, LNEE 708. Singapore: Springer, 2021: 41-52.
|
| 16 |
SHI X J, CHEN Z R, WANG H, et al. Convolutional LSTM network: a machine learning approach for precipitation now casting[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 802-810.
|
| 17 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90
|
| 18 |
HAN K, WANG Y H, TIAN Q, et al. GhostNet: more features from cheap operations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1577-1586. 10.1109/cvpr42600.2020.00165
|
| 19 |
刘超军,段喜萍,谢宝文. 应用GhostNet卷积特征的ECO目标跟踪算法改进[J]. 激光技术, 2022, 46(2):239-247. 10.7510/jgjs.issn.1001-3806.2022.02.015
|
|
LIU C J, DUAN X P, XIE B W. Improvement of ECO target tracking algorithm based on GhostNet convolution feature[J]. Laser Technology, 2022, 46(2):239-247. 10.7510/jgjs.issn.1001-3806.2022.02.015
|
| 20 |
WEI B Y, SHEN X L, YUAN Y L. Remote sensing scene classification based on improved GhostNet[J]. Journal of Physics: Conference Series, 2020, 1621: No.012091. 10.1088/1742-6596/1621/1/012091
|
| 21 |
TAN M X, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 6105-6114.
|
| 22 |
尹梓睿,张索非,张磊,等. 适于行人重识别的二分支EfficientNet网络设计[J]. 信号处理, 2020, 36(9): 1481-1488.
|
|
YIN Z R, ZHANG S F, ZHANG L, et al. Design of a two-branch EfficientNet for person re-identification[J]. Journal of Signal Processing, 2020, 36(9): 1481-1488.
|
| 23 |
曹毅,刘晨,盛永健,等. 基于三维图卷积与注意力增强的行为识别模型[J]. 电子与信息学报, 2021, 43(7): 2071-2078. 10.11999/JEIT200448
|
|
CAO Y, LIU C, SHENG Y J, et al. Action recognition model based on 3D graph convolution and attention enhanced[J]. Journal of Electronics and Information Technology, 2021, 43(7): 2071-2078. 10.11999/JEIT200448
|
| 24 |
梁智杰. 聋哑人手语识别关键技术研究[D]. 武汉:华中师范大学, 2019.
|
|
LIANG Z J. Research on key technologies of sign language recognition for deaf-mutes[D]. Wuhan: Central China Normal University, 2019.
|
| 25 |
HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1314-1324. 10.1109/iccv.2019.00140
|
| 26 |
MA N N, ZHANG X Y, ZHENG H T, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 122-138.
|
| 27 |
MOHAMMADI S, PERINA A, KIANI H, et al. Angry crowds: detecting violent events in videos[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9911. Cham: Springer, 2016: 3-18.
|
| 28 |
SENST T, EISELEIN V, KUHN A, et al. Crowd violence detection using global motion-compensated Lagrangian features and scale sensitive video-level representation[J]. IEEE Transactions on Information Forensics and Security, 2017, 12(12): 2945-2956. 10.1109/tifs.2017.2725820
|
| 29 |
MAHMOODI J, SALAJEGHE A. A classification method based on optical flow for violence detection[J]. Expert Systems with Applications, 2019, 127: 121-127. 10.1016/j.eswa.2019.02.032
|
| 30 |
于京. 特殊视频内容分析算法研究[D]. 北京:北京交通大学, 2020.
|
|
YU J. Study on content analysis algorithms in special video[D]. Beijing: Beijing Jiaotong University, 2020.
|


 )
)