


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (3): 909-915.DOI: 10.11772/j.issn.1001-9081.2022010047
• 多媒体计算与计算机仿真 • 上一篇
收稿日期:2022-01-17
修回日期:2022-06-08
接受日期:2022-06-10
发布日期:2022-07-11
出版日期:2023-03-10
通讯作者:
王煜坤
作者简介:张秋余(1966—),男,河北辛集人,研究员,主要研究方向:网络与信息安全、智能信息处理、模式识别基金资助:Received:2022-01-17
Revised:2022-06-08
Accepted:2022-06-10
Online:2022-07-11
Published:2023-03-10
Contact:
Yukun WANG
About author:ZHANG Qiuyu, born in 1966, research fellow. His research interests include network and information security, intelligent information processing, pattern recognition.
Supported by:摘要:
针对传统音频分类模型提取音频特征的过程繁琐,以及现有神经网络模型存在过拟合、分类精度不高、梯度消失等问题,提出一种基于改进Inception网络的语音分类模型。首先,在模型中加入ResNet中的残差跳连思想以改进传统的InceptionV2模型,使网络模型在加深的同时避免梯度消失;其次,优化Inception模块中的卷积核大小,并利用不同尺寸卷积对原始语音的Log-Mel谱图进行深度特征提取,使模型通过自主学习的方式选择合适的卷积处理数据;同时,在深度与宽度两个维度改进模型以提高分类精度;最后,利用训练好的网络模型对语音数据进行分类预测,并通过Softmax函数得到分类结果。在清华大学汉语语音数据集THCHS-30与环境声音数据集UrbanSound8K数据集上的实验结果表明,改进的Inception网络模型在上述两个数据集上分类准确率分别为92.76%与93.34%。相较于VGG16、InceptionV2、GoogLeNet等模型,所提模型的分类准确率取得了最优,最多提高了27.30个百分点。所提模型具有更强的特征融合能力和更准确的分类结果,能够解决过拟合、梯度消失等问题。
中图分类号:
张秋余, 王煜坤. 基于改进Inception网络的语音分类模型[J]. 计算机应用, 2023, 43(3): 909-915.
Qiuyu ZHANG, Yukun WANG. Speech classification model based on improved Inception network[J]. Journal of Computer Applications, 2023, 43(3): 909-915.

图1 Log-Mel谱图特征提取流程
Fig. 1 Extraction flow of Log-Mel spectrogram features
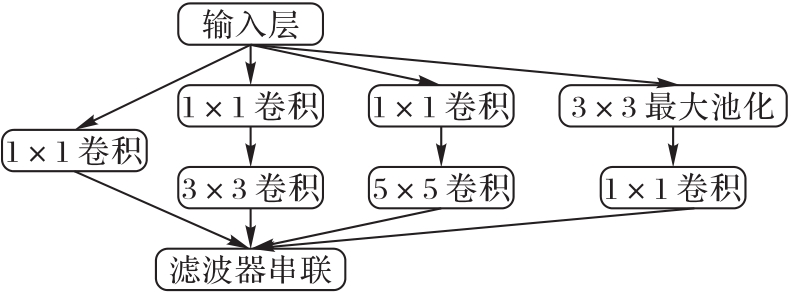
图2 Inception网络模型结构
Fig. 2 Structure of Inception network model
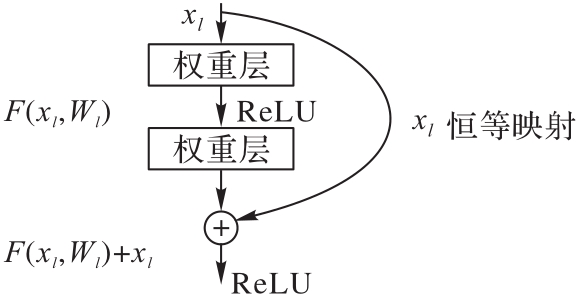
图3 ResNet的残差跳连
Fig. 3 Residual skip connection for ResNet

图4 改进的Inception模块结构
Fig. 4 Structure of improved Inception module
| 网络层 | 类别 | 卷积尺寸 | 步长 | 深度 | 激活函数 |
|---|---|---|---|---|---|
| 输入 | 输入层 | — | — | 3 | ReLU |
| 卷积1 | 卷积层 | 3×3 | 1 | 16 | ReLU |
| 改进Inception | 卷积+池化 | 1×1,1×3,3×3 | 2 | 16 | ReLU |
| 改进Inception | 卷积+池化 | 1×1,1×3,3×3 | 1 | 64 | ReLU |
| 改进Inception | 卷积+池化 | 1×1,1×3,3×3 | 2 | 32 | ReLU |
| 改进Inception | 卷积+池化 | 1×1,1×3,3×3 | 1 | 128 | ReLU |
| 全局池化 | 池化 | 3×3 | 1 | — | — |
| 输出 | 输出 | — | — | — | Softmax |
表1 改进的网络模型各层参数
Tab. 1 Parameters of each layer of improved network model
| 网络层 | 类别 | 卷积尺寸 | 步长 | 深度 | 激活函数 |
|---|---|---|---|---|---|
| 输入 | 输入层 | — | — | 3 | ReLU |
| 卷积1 | 卷积层 | 3×3 | 1 | 16 | ReLU |
| 改进Inception | 卷积+池化 | 1×1,1×3,3×3 | 2 | 16 | ReLU |
| 改进Inception | 卷积+池化 | 1×1,1×3,3×3 | 1 | 64 | ReLU |
| 改进Inception | 卷积+池化 | 1×1,1×3,3×3 | 2 | 32 | ReLU |
| 改进Inception | 卷积+池化 | 1×1,1×3,3×3 | 1 | 128 | ReLU |
| 全局池化 | 池化 | 3×3 | 1 | — | — |
| 输出 | 输出 | — | — | — | Softmax |
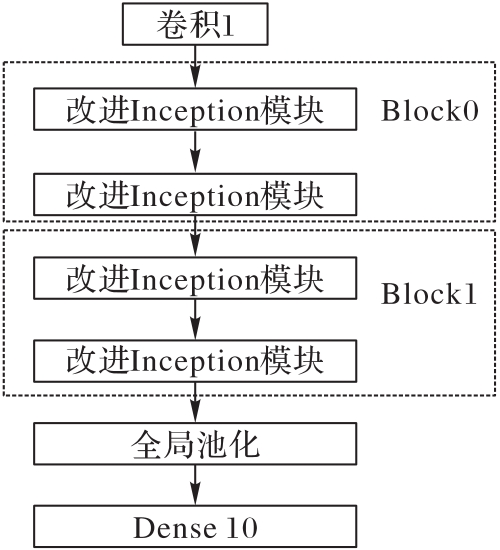
图5 改进的Inception模块
Fig. 5 Improved Inception module
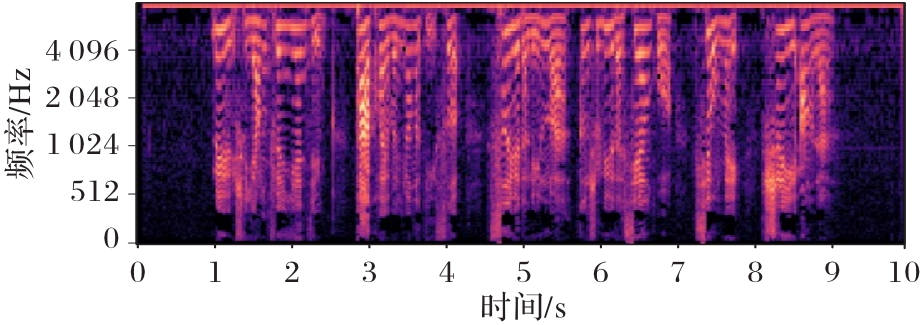
图6 Log-Mel谱图
Fig. 6 Log-Mel spectrogram
| 参数名 | 参数值 | 效果 |
|---|---|---|
| rotation_range | 40 | 指定数值,将数据在0至此 数值内随机角度旋转 |
| width_shift_range | 0.2 | 水平方向随机平移,平移 最大距离为参数值乘图像宽度 |
| height_shift_range | 0.2 | 垂直方向随机平移,平移 最大距离为参数值乘图像高 |
| shear_range | 0.2 | 错切交错,让所有点的x(或y)轴 不变,y(或x)轴按参数值比例平移 |
| zoom_range | 0.2 | 在长宽两个方向分别进行按 参数值进行缩放操作 |
| horizontal_flip | True | 随机对图片执行水平翻转操作 |
| fill_mode | nearest | 采用默认方式对平移、缩放、 错切操作之后的数据进行填充 |
表2 数据增强具体方法
Tab. 2 Specific methods of data enhancement
| 参数名 | 参数值 | 效果 |
|---|---|---|
| rotation_range | 40 | 指定数值,将数据在0至此 数值内随机角度旋转 |
| width_shift_range | 0.2 | 水平方向随机平移,平移 最大距离为参数值乘图像宽度 |
| height_shift_range | 0.2 | 垂直方向随机平移,平移 最大距离为参数值乘图像高 |
| shear_range | 0.2 | 错切交错,让所有点的x(或y)轴 不变,y(或x)轴按参数值比例平移 |
| zoom_range | 0.2 | 在长宽两个方向分别进行按 参数值进行缩放操作 |
| horizontal_flip | True | 随机对图片执行水平翻转操作 |
| fill_mode | nearest | 采用默认方式对平移、缩放、 错切操作之后的数据进行填充 |
| 迭代次数 | 准确率/% | 迭代次数 | 准确率/% |
|---|---|---|---|
| 15 | 83.24 | 35 | 89.92 |
| 20 | 85.00 | 40 | 92.55 |
| 25 | 88.30 | 45 | 93.03 |
| 30 | 87.20 | 50 | 93.48 |
表3 不同迭代次数的分类准确率
Tab. 3 Classification accuracy of different iteration times
| 迭代次数 | 准确率/% | 迭代次数 | 准确率/% |
|---|---|---|---|
| 15 | 83.24 | 35 | 89.92 |
| 20 | 85.00 | 40 | 92.55 |
| 25 | 88.30 | 45 | 93.03 |
| 30 | 87.20 | 50 | 93.48 |
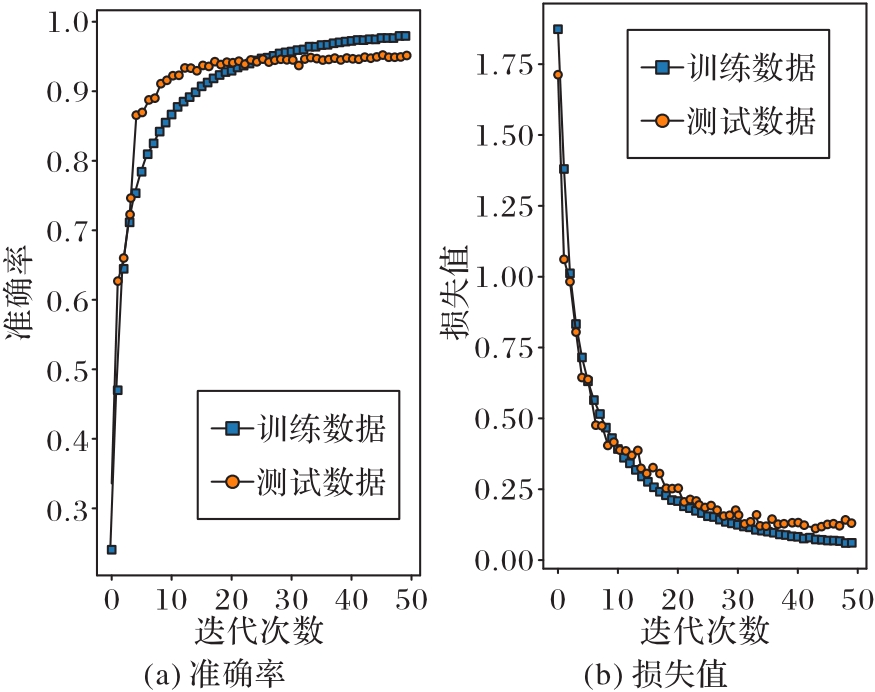
图7 分类准确率与损失值收敛结果
Fig. 7 Convergence results of classification accuracy and loss value
| 噪声强度/dB | 分类准确率/% |
|---|---|
| 0 | 93.34 |
| 20 | 92.83 |
| 15 | 89.97 |
表4 不同噪声强度下的分类准确率
Tab. 4 Classification accuracy of different noise intensity
| 噪声强度/dB | 分类准确率/% |
|---|---|
| 0 | 93.34 |
| 20 | 92.83 |
| 15 | 89.97 |
| 模型 | 损失值 | 准确率% | 时间/s |
|---|---|---|---|
| AlexNet | 1.143 | 65.46 | 5 895.7 |
| VGG16 | 0.532 | 86.32 | 186 251.3 |
| InceptionV2 | 0.524 | 89.47 | 167 654.8 |
| 本文模型 | 0.465 | 92.76 | 154 176.4 |
表5 不同模型分类性能对比
Tab. 5 Comparison of classification performance of different models
| 模型 | 损失值 | 准确率% | 时间/s |
|---|---|---|---|
| AlexNet | 1.143 | 65.46 | 5 895.7 |
| VGG16 | 0.532 | 86.32 | 186 251.3 |
| InceptionV2 | 0.524 | 89.47 | 167 654.8 |
| 本文模型 | 0.465 | 92.76 | 154 176.4 |
| 模型 | 特征 | 网络模型构造 | 准确率/% |
|---|---|---|---|
| EnvNet | Log-Mel谱图 | 2Conv+3Pooling+2FC | 71.00 |
| Dilated CNN | Log-Mel谱图 | 2Conv+2Pooling+2FC | 78.00 |
| 1D CNN | 音频 | 4Conv+2Pooling+3FC | 89.00 |
| DS-CNN | 音频+Log-Mel | 5Conv+FC+7Conv+1Pooling+FC | 92.20 |
| GoogLeNet | 语谱图+MFCC | 9Inception+3Softmax | 93.00 |
| 本文模型 | Log-Mel谱图 | 1Conv+4改进Inception+1FC | 93.34 |
表6 不同网络模型准确率对比
Tab. 6 Comparison of accuracy results of different network models
| 模型 | 特征 | 网络模型构造 | 准确率/% |
|---|---|---|---|
| EnvNet | Log-Mel谱图 | 2Conv+3Pooling+2FC | 71.00 |
| Dilated CNN | Log-Mel谱图 | 2Conv+2Pooling+2FC | 78.00 |
| 1D CNN | 音频 | 4Conv+2Pooling+3FC | 89.00 |
| DS-CNN | 音频+Log-Mel | 5Conv+FC+7Conv+1Pooling+FC | 92.20 |
| GoogLeNet | 语谱图+MFCC | 9Inception+3Softmax | 93.00 |
| 本文模型 | Log-Mel谱图 | 1Conv+4改进Inception+1FC | 93.34 |
| 1 | MUSHTAQ Z, SU S F, TRAN Q V. Spectral images based environmental sound classification using CNN with meaningful data augmentation[J]. Applied Acoustics, 2021, 172: No.107581. 10.1016/j.apacoust.2020.107581 |
| 2 | TLEMSANI R, NEGGAZ N. A hybrid evolutionary neural networks training applied to phonetic classification[J]. Algerian Journal of Research and Technology, 2021, 5(1): 1-10. |
| 3 | 付炜,杨洋. 基于卷积神经网络和随机森林的音频分类方法[J]. 计算机应用, 2018, 38(S2): 58-62. |
| FU W, YANG Y. Audio classification method based on convolutional neural network and random forest[J]. Journal of Computer Applications, 2018, 38(S2): 58-62. | |
| 4 | CHIT Y W, HLAING W E, KHAING M M. Myanmar continuous speech recognition system using convolutional neural network[J]. International Journal of Image, Graphics and Signal Processing, 2021, 13(2): 44-52. 10.5815/ijigsp.2021.02.04 |
| 5 | BALLESTEROS D M, RODRIGUEZ-ORTEGA Y, RENZA D, et al. Deep4SNet: deep learning for fake speech classification[J]. Expert Systems with Applications, 2021, 184: No.115465. 10.1016/j.eswa.2021.115465 |
| 6 | 杨立东,张壮壮. 改进卷积神经网络的音频场景分类研究[J]. 现代电子技术, 2021, 44(3): 91-94. |
| YANG L D, ZHANG Z Z. Research on acoustic scene classification based on improved convolutional neural network[J]. Modern Electronics Technique, 2021, 44(3): 91-94. | |
| 7 | TOKOZUME Y, HARADA T. Learning environmental sounds with end-to-end convolutional neural network[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2017: 2721-2725. 10.1109/icassp.2017.7952651 |
| 8 | PONS J, SERRA X. Randomly weighted CNNs for (music) audio classification[C]// Proceeding of the 2019 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2019: 336-340. 10.1109/icassp.2019.8682912 |
| 9 | JIN X, WU L, LI X D, et al. ILGNet: inception modules with connected local and global features for efficient image aesthetic quality classification using domain adaptation[J]. IET Computer Vision, 2019, 13(2): 206-212. 10.1049/iet-cvi.2018.5249 |
| 10 | MEGHANA A S, SUDHAKAR S, ARUMUGAM G, et al. Age and gender prediction using convolution, ResNet50 and inception ResNetV2[J]. International Journal of Advanced Trends in Computer Science and Engineering, 2020, 9(2): 1328-1334. 10.30534/ijatcse/2020/65922020 |
| 11 | 熊华煜,余勤,任品,等. 基于机器学习的音频分类[J]. 计算机工程与设计, 2021, 42(1): 156-160. |
| XIONG H Y, YU Q, REN P, et al. Audio classification based on machine learning[J]. Computer Engineering and Design, 2021, 42(1): 156-160. | |
| 12 | PICZAK K J. Environmental sound classification with convolutional neural networks[C]// Proceeding of the IEEE 25th International Workshop on Machine Learning for Signal Processing. Piscataway: IEEE, 2015: 1-6. 10.1109/mlsp.2015.7324337 |
| 13 | SALAMON J, BELLO J P. Deep convolutional neural networks and data augmentation for environmental sound classification[J]. IEEE Signal Processing Letters, 2017, 24(3): 279-283. 10.1109/lsp.2017.2657381 |
| 14 | LU L, YANG Y H, JING Y Z, et al. Shallow convolutional neural networks for acoustic scene classification[J]. Wuhan University Journal of Natural Sciences, 2018, 23(2):178-184. 10.1007/s11859-018-1308-z |
| 15 | PASEDDULA C, GANGASHETTY S V. Late fusion framework for Acoustic Scene Classification using LPCC, SCMC, and log-Mel band energies with Deep Neural Networks[J]. Applied Acoustics, 2021, 172: No.107568. 10.1016/j.apacoust.2020.107568 |
| 16 | SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9. 10.1109/cvpr.2015.7298594 |
| 17 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 18 | KHAN S H, HAYAT M, PORIKLI F. Regularization of deep neural networks with spectral dropout[J]. Neural Networks, 2019, 110: 82-90. 10.1016/j.neunet.2018.09.009 |
| 19 | SINGARIMBUN R N, NABABAN E B, SITOMPUL O S. Adaptive moment estimation to minimize square error in backpropagation algorithm[C]// Proceedings of the 2019 International Conference of Computer Science and Information Technology. Piscataway: IEEE, 2019: 1-7. 10.1109/icosnikom48755.2019.9111563 |
| 20 | WANG D, ZHANG X W. THCHS-30: a free Chinese speech corpus[EB/OL]. (2015-12-10) [2021-11-20].. |
| 21 | BOCK S, GOPPOLD J, WEIβ M. An improvement of the convergence proof of the ADAM-Optimizer[EB/OL]. (2018-04-27) [2021-11-20].. |
| 22 | ABDOLI S, CARDINAL P, KOERICH A L. End-to-end environmental sound classification using a 1D convolutional neural network[J]. Expert Systems with Applications, 2019, 136: 252-263. 10.1016/j.eswa.2019.06.040 |
| 23 | CHEN Y, GUO Q, LIANG X Y, et al. Environmental sound classification with dilated convolutions[J]. Applied Acoustics, 2019, 148: 123-132. 10.1016/j.apacoust.2018.12.019 |
| 24 | LI S B, YAO Y, HU J, et al. An ensemble stacked convolutional neural network model for environmental event sound recognition[J]. Applied Sciences, 2018, 8(7): No.1152. 10.3390/app8071152 |
| 25 | BODDAPATI V, PETEF A, RASMUSSON J, et al. Classifying environmental sounds using image recognition networks[J]. Procedia Computer Science, 2017, 112: 2048-2056. 10.1016/j.procs.2017.08.250 |
| [1] | 李振亮, 李波. 基于矩阵分解的卷积神经网络改进方法[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 685-691. |
| [2] | 倪苒岩, 张轶. 基于视频时空特征的行为识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 521-528. |
| [3] | 王若莹, 吕凡, 赵柳清, 胡伏原. 融合用户需求和边界约束的平面图生成算法[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 575-582. |
| [4] | 王萍, 陈楠, 鲁磊. 基于场景先验及注意力引导的跌倒检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 529-535. |
| [5] | 汪洋, 傅洪亮, 陶华伟, 杨静, 谢跃, 赵力. 基于决策边界优化域自适应的跨库语音情感识别[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 374-379. |
| [6] | 王佑芯, 陈斌. 基于深度对比网络的印刷缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 250-258. |
| [7] | 林荐壮, 杨文忠, 谭思翔, 周乐鑫, 陈丹妮. 融合滤波增强和反转注意力网络用于息肉分割[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 265-272. |
| [8] | 申志军, 穆丽娜, 高静, 史远航, 刘志强. 细粒度图像分类综述[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 51-60. |
| [9] | 刘月峰, 张小燕, 郭威, 边浩东, 何滢婕. 基于优化混合模型的航空发动机剩余寿命预测方法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2960-2968. |
| [10] | 衡红军, 徐天宝. 基于多尺度卷积和门控机制的注意力情感分析模型[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2674-2679. |
| [11] | 刘汉卿, 康晓东, 张福青, 赵秀圆, 杨靖怡, 王笑天, 李梦凡. 改进的Libra区域卷积神经网络的脑动脉狭窄影像学检测算法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2909-2916. |
| [12] | 王宇航, 周永霞, 吴良武. 基于高斯函数的池化算法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2800-2806. |
| [13] | 徐成霞, 阎庆, 李腾, 苗开超. 基于联合注意力机制的单幅图像去雨算法[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2578-2585. |
| [14] | 吕振虎, 许新征, 张芳艳. 基于挤压激励的轻量化注意力机制模块[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2353-2360. |
| [15] | 靳华中, 张修洋, 叶志伟, 张闻其, 夏小鱼. 基于近似U型网络结构的图像去噪模型[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2571-2577. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
