《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (1): 209-214.DOI: 10.11772/j.issn.1001-9081.2021020239
• 先进计算 • 上一篇
Bosen ZENG1,2,3( ), Yong ZHONG1,2, Xianhua NIU4,5
), Yong ZHONG1,2, Xianhua NIU4,5
摘要:
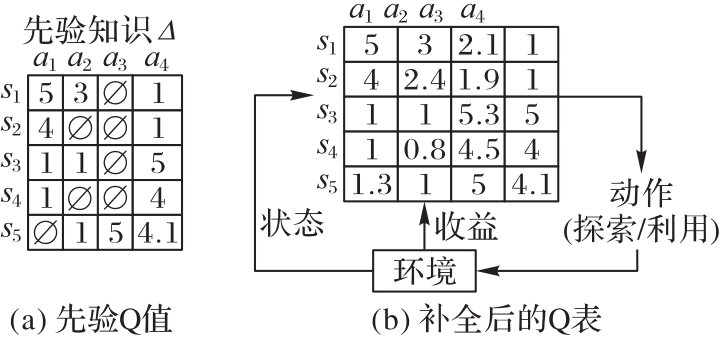
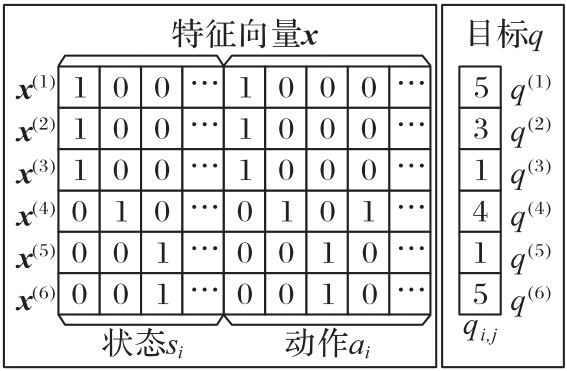
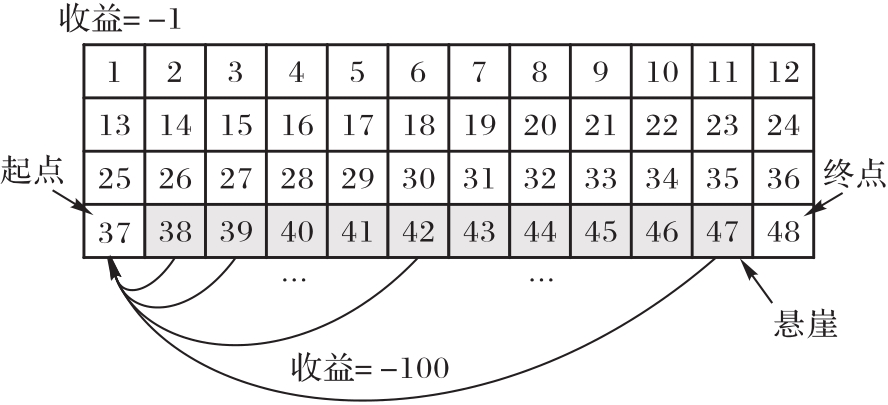
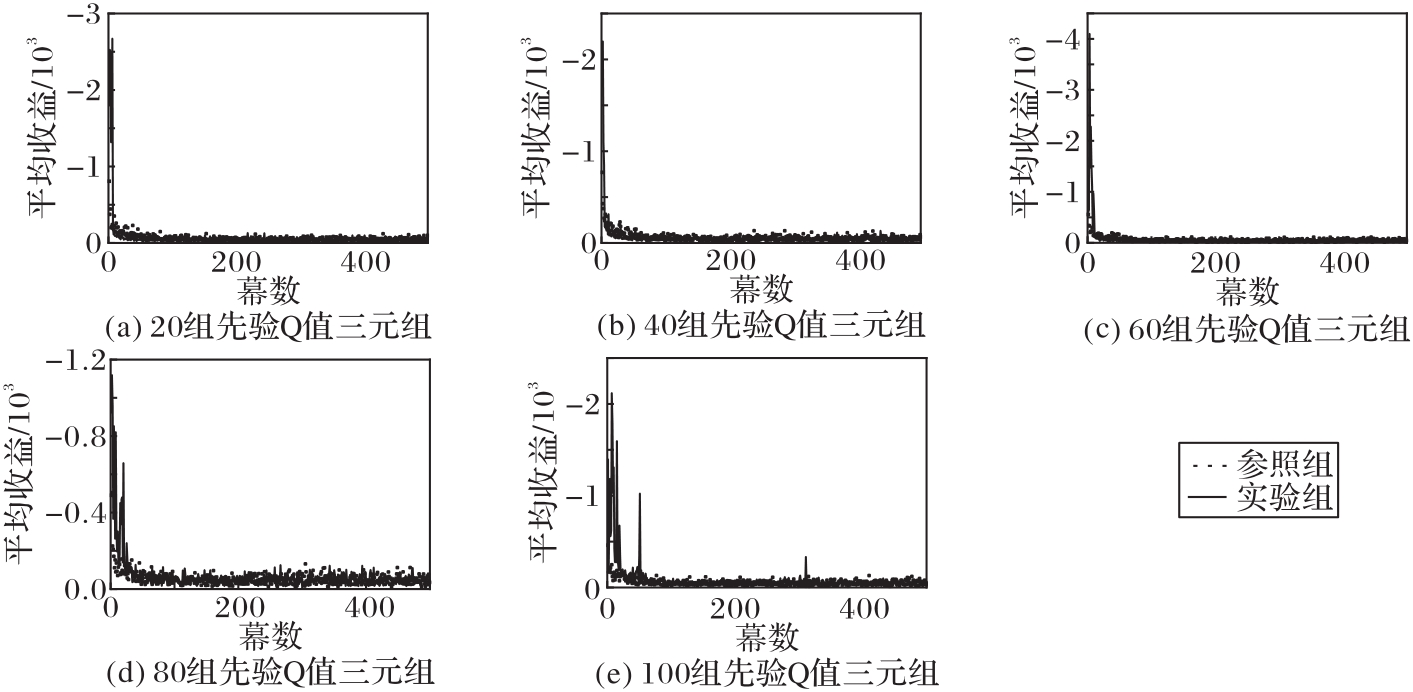
针对强化学习的大多数探索/利用策略在探索过程中忽略智能体随机选择动作带来的风险的问题,提出一种基于因子分解机(FM)用于安全探索的Q表初始化方法。首先,引入Q表中已探索的Q值作为先验知识;然后,利用FM建立先验知识中状态和行动间潜在的交互作用的模型;最后,基于该模型预测Q表中的未知Q值,从而进一步引导智能体探索。在OpenAI Gym的网格强化学习环境Cliffwalk中进行的A/B测试里,基于所提方法的Boltzmann和置信区间上界(UCB)探索/利用策略的不良探索幕数分别下降了68.12%和89.98%。实验结果表明,所提方法提高了传统策略的探索安全性,同时加快了收敛。
中图分类号: