


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (3): 770-777.DOI: 10.11772/j.issn.1001-9081.2021040791
• 2021年中国计算机学会人工智能会议(CCFAI 2021) • 上一篇
收稿日期:2021-05-17
修回日期:2021-06-04
接受日期:2021-06-09
发布日期:2021-11-09
出版日期:2022-03-10
通讯作者:
严珂
作者简介:张建(1997—),男,江西高安人,硕士研究生,主要研究方向:文本分类、多任务学习情感识别基金资助:
Jian ZHANG, Ke YAN( ), Xiang MA
), Xiang MA
Received:2021-05-17
Revised:2021-06-04
Accepted:2021-06-09
Online:2021-11-09
Published:2022-03-10
Contact:
Ke YAN
About author:ZHANG Jian, born in 1997, M. S. candidate. His research interests include text classification, recognition of multi-task learning.Supported by:摘要:
垃圾信息的识别是自然语言处理方面主要的任务之一。传统方法是基于文本特征或词频的方法,其识别准确率主要依赖于特定关键词的出现与否,存在对关键词识别错误或对未出现关键词的垃圾信息文本识别能力较差的问题,提出基于神经网络的方法。首先,利用传统方法针对这一类垃圾信息文本进行识别训练和测试;然后,利用从垃圾短信、广告和垃圾邮件数据集中挑选出传统方法识别困难的垃圾信息,再从原数据集中随机挑选出同样数量的正常信息,将其组成三个无重复数据的新数据集;最后,以卷积神经网络和循环神经网络为基础,建立了三个模型,并在新数据集上进行识别训练。实验结果表明,基于神经网络的方法可以从文本中学习到更好的语义特征,在三个数据集上均能达到98%以上的准确率,高于朴素贝叶斯(NB)、随机森林(RF)、支持向量机(SVM)等传统方法。实验结果还显示,不同的神经网络适用于不同长度的文本分类,由循环神经网络组成的模型擅长识别句子长度的文本,由卷积神经网络组成的模型擅长识别段落长度的文本,由两者共同组成的模型擅长识别篇章长度的文本。
中图分类号:
张建, 严珂, 马祥. 基于神经网络的复杂垃圾信息过滤算法分析[J]. 计算机应用, 2022, 42(3): 770-777.
Jian ZHANG, Ke YAN, Xiang MA. Analysis of complex spam filtering algorithm based on neural network[J]. Journal of Computer Applications, 2022, 42(3): 770-777.
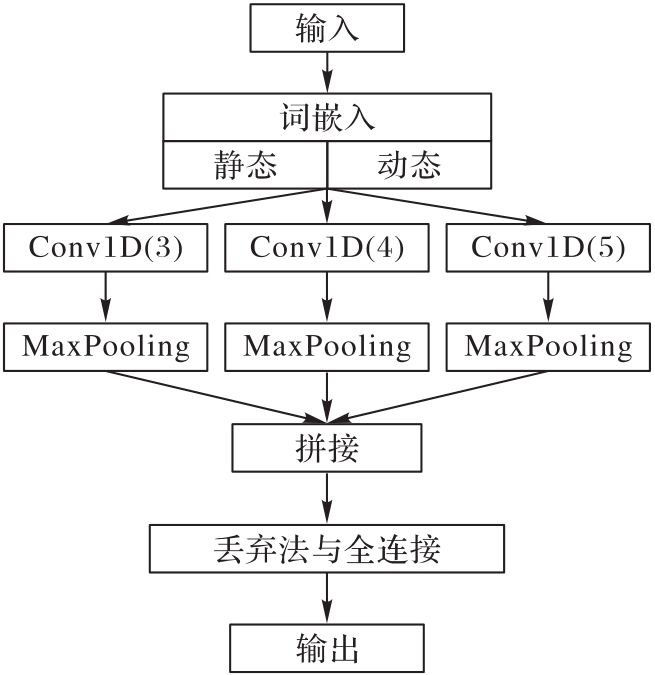
图1 TextCNN模型结构
Fig. 1 Structure of TextCNN model
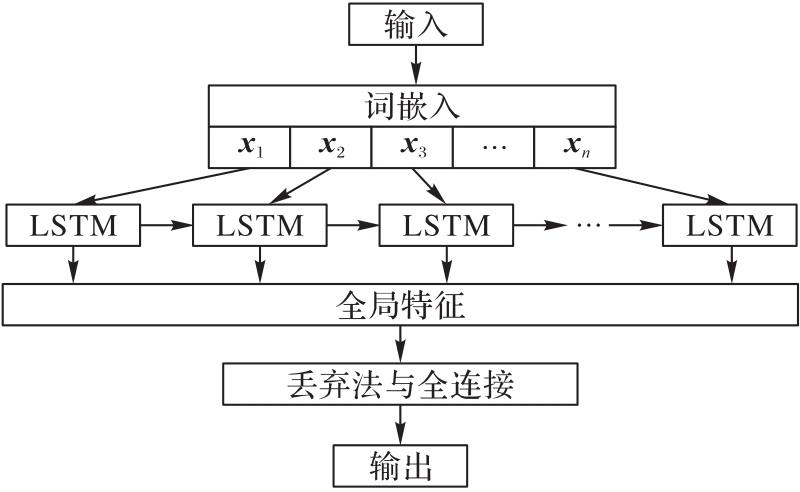
图2 TextRNN模型结构
Fig. 2 Structure of TextRNN model
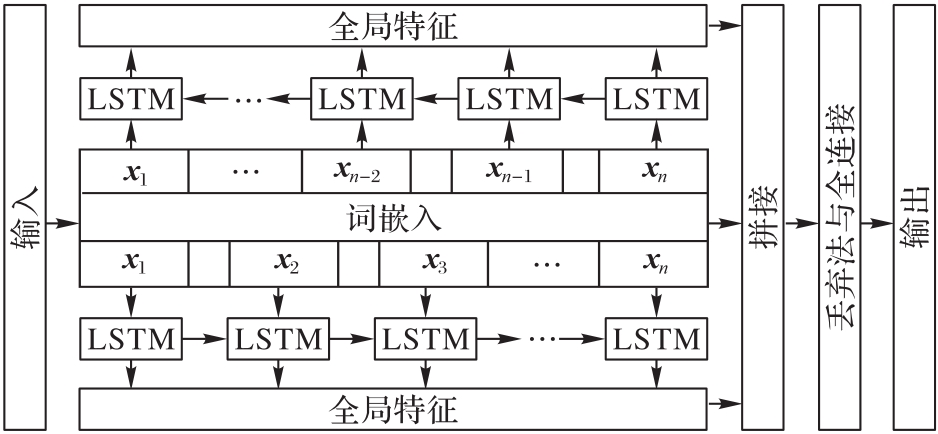
图3 TextRCNN模型结构
Fig. 3 Structure of TextRCNN model
| 数据集 | 文本 |
|---|---|
| 垃圾短信(SMS Spam) | CALL 09090900040 & LISTEN TO EXTREME DIRTY LIVE CHAT GOING ON IN THE OFFICE RIGHT NOW TOTAL PRIVACY NO ONE KNOWS YOUR [sic] LISTENING 60P MIN |
| Hungry gay guys feeling hungry and up 4 it, now. Call 08718730555 just 10p/min. To stop texts call 08712460324 (10p/min) | |
| (Bank of Granite issues Strong-Buy) EXPLOSIVE PICK FOR OUR MEMBERS *****UP OVER 300% *********** Nasdaq Symbol CDGT That is a $5.00 per.. | |
| 垃圾广告(Ads Spam) | facial lines along with loose skin color could be enhanced by a single skin care product. Elliskin The idea is included with Supplements C as well as some various other needed nutritional requirements along with healthy antioxidants distinguished for cor |
| Albuminoidal is what ultimately conceals the age spots and collectively the discoloration of your skin. It additionally aids in adjustment the skin so on deflate wrinkles. On exploitation of times many of its users have according that they give the impre | |
| 垃圾邮件(Email Spam) | Norton AD ATTENTION: This is a MUST for ALL Computer Users!!! *NEW - Special Package Deal!* …… |
表2 部分较难识别的垃圾信息
Tab. 2 Some spam difficult to identify
| 数据集 | 文本 |
|---|---|
| 垃圾短信(SMS Spam) | CALL 09090900040 & LISTEN TO EXTREME DIRTY LIVE CHAT GOING ON IN THE OFFICE RIGHT NOW TOTAL PRIVACY NO ONE KNOWS YOUR [sic] LISTENING 60P MIN |
| Hungry gay guys feeling hungry and up 4 it, now. Call 08718730555 just 10p/min. To stop texts call 08712460324 (10p/min) | |
| (Bank of Granite issues Strong-Buy) EXPLOSIVE PICK FOR OUR MEMBERS *****UP OVER 300% *********** Nasdaq Symbol CDGT That is a $5.00 per.. | |
| 垃圾广告(Ads Spam) | facial lines along with loose skin color could be enhanced by a single skin care product. Elliskin The idea is included with Supplements C as well as some various other needed nutritional requirements along with healthy antioxidants distinguished for cor |
| Albuminoidal is what ultimately conceals the age spots and collectively the discoloration of your skin. It additionally aids in adjustment the skin so on deflate wrinkles. On exploitation of times many of its users have according that they give the impre | |
| 垃圾邮件(Email Spam) | Norton AD ATTENTION: This is a MUST for ALL Computer Users!!! *NEW - Special Package Deal!* …… |
| 方法 | 分类器 | 类别 | SMS数据集 | Ads数据集 | Email数据集 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |||
传统 方法 | NB | Spam | 0.825 | 0.867 | 0.846 | 0.964 | 0.900 | 0.931 | 0.851 | 0.950 | 0.898 |
| Ham | 0.860 | 0.817 | 0.838 | 0.906 | 0.967 | 0.935 | 0.943 | 0.833 | 0.885 | ||
| RF | Spam | 0.918 | 0.750 | 0.826 | 0.938 | 1.000 | 0.968 | 0.866 | 0.967 | 0.913 | |
| Ham | 0.789 | 0.933 | 0.855 | 1.000 | 0.933 | 0.966 | 0.962 | 0.850 | 0.903 | ||
| SVM | Spam | 0.942 | 0.817 | 0.875 | 0.935 | 0.967 | 0.951 | 0.965 | 0.917 | 0.940 | |
| Ham | 0.838 | 0.950 | 0.891 | 0.966 | 0.933 | 0.949 | 0.921 | 0.967 | 0.943 | ||
| LR | Spam | 0.940 | 0.783 | 0.855 | 0.951 | 0.967 | 0.959 | 0.921 | 0.967 | 0.943 | |
| Ham | 0.814 | 0.950 | 0.877 | 0.966 | 0.950 | 0.958 | 0.965 | 0.917 | 0.940 | ||
| DT | Spam | 0.843 | 0.717 | 0.775 | 0.966 | 0.933 | 0.949 | 0.786 | 0.917 | 0.846 | |
| Ham | 0.754 | 0.867 | 0.806 | 0.935 | 0.967 | 0.951 | 0.900 | 0.750 | 0.818 | ||
当前 主流 方法 | DPCNN | Spam | 0.965 | 0.917 | 0.940 | 0.952 | 1.000 | 0.976 | 0.930 | 0.993 | 0.906 |
| Ham | 0.921 | 0.967 | 0.943 | 1.000 | 0.950 | 0.974 | 0.889 | 0.933 | 0.911 | ||
| BERT | Spam | 0.931 | 0.900 | 0.915 | 0.967 | 0.983 | 0.975 | 0.944 | 0.850 | 0.895 | |
| Ham | 0.903 | 0.933 | 0.918 | 0.983 | 0.967 | 0.975 | 0.864 | 0.950 | 0.905 | ||
| TinyBERT | Spam | 0.903 | 0.933 | 0.918 | 0.967 | 0.967 | 0.967 | 0.906 | 0.800 | 0.850 | |
| Ham | 0.931 | 0.900 | 0.915 | 0.967 | 0.967 | 0.967 | 0.821 | 0.917 | 0.866 | ||
神经 网络 方法 | TextCNN | Spam | 0.967 | 0.967 | 0.967 | 0.984 | 1.000 | 0.992 | 0.967 | 0.983 | 0.975 |
| Ham | 0.967 | 0.967 | 0.967 | 1.000 | 0.983 | 0.992 | 0.983 | 0.967 | 0.975 | ||
| TextRNN | Spam | 0.983 | 0.983 | 0.983 | 0.967 | 0.983 | 0.975 | — | — | — | |
| Ham | 0.983 | 0.983 | 0.983 | 0.983 | 0.967 | 0.975 | — | — | — | ||
| TextRCNN | Spam | 0.952 | 0.983 | 0.967 | 0.968 | 1.000 | 0.984 | 0.968 | 1.000 | 0.984 | |
| Ham | 0.983 | 0.950 | 0.966 | 1.000 | 0.967 | 0.983 | 1.000 | 0.967 | 0.983 | ||
表3 传统方法、当前主流方法和神经网络方法在三种数据集上的分类结果
Tab. 3 Classification results of traditional methods, current methods, and neural network methods on three datasets
| 方法 | 分类器 | 类别 | SMS数据集 | Ads数据集 | Email数据集 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |||
传统 方法 | NB | Spam | 0.825 | 0.867 | 0.846 | 0.964 | 0.900 | 0.931 | 0.851 | 0.950 | 0.898 |
| Ham | 0.860 | 0.817 | 0.838 | 0.906 | 0.967 | 0.935 | 0.943 | 0.833 | 0.885 | ||
| RF | Spam | 0.918 | 0.750 | 0.826 | 0.938 | 1.000 | 0.968 | 0.866 | 0.967 | 0.913 | |
| Ham | 0.789 | 0.933 | 0.855 | 1.000 | 0.933 | 0.966 | 0.962 | 0.850 | 0.903 | ||
| SVM | Spam | 0.942 | 0.817 | 0.875 | 0.935 | 0.967 | 0.951 | 0.965 | 0.917 | 0.940 | |
| Ham | 0.838 | 0.950 | 0.891 | 0.966 | 0.933 | 0.949 | 0.921 | 0.967 | 0.943 | ||
| LR | Spam | 0.940 | 0.783 | 0.855 | 0.951 | 0.967 | 0.959 | 0.921 | 0.967 | 0.943 | |
| Ham | 0.814 | 0.950 | 0.877 | 0.966 | 0.950 | 0.958 | 0.965 | 0.917 | 0.940 | ||
| DT | Spam | 0.843 | 0.717 | 0.775 | 0.966 | 0.933 | 0.949 | 0.786 | 0.917 | 0.846 | |
| Ham | 0.754 | 0.867 | 0.806 | 0.935 | 0.967 | 0.951 | 0.900 | 0.750 | 0.818 | ||
当前 主流 方法 | DPCNN | Spam | 0.965 | 0.917 | 0.940 | 0.952 | 1.000 | 0.976 | 0.930 | 0.993 | 0.906 |
| Ham | 0.921 | 0.967 | 0.943 | 1.000 | 0.950 | 0.974 | 0.889 | 0.933 | 0.911 | ||
| BERT | Spam | 0.931 | 0.900 | 0.915 | 0.967 | 0.983 | 0.975 | 0.944 | 0.850 | 0.895 | |
| Ham | 0.903 | 0.933 | 0.918 | 0.983 | 0.967 | 0.975 | 0.864 | 0.950 | 0.905 | ||
| TinyBERT | Spam | 0.903 | 0.933 | 0.918 | 0.967 | 0.967 | 0.967 | 0.906 | 0.800 | 0.850 | |
| Ham | 0.931 | 0.900 | 0.915 | 0.967 | 0.967 | 0.967 | 0.821 | 0.917 | 0.866 | ||
神经 网络 方法 | TextCNN | Spam | 0.967 | 0.967 | 0.967 | 0.984 | 1.000 | 0.992 | 0.967 | 0.983 | 0.975 |
| Ham | 0.967 | 0.967 | 0.967 | 1.000 | 0.983 | 0.992 | 0.983 | 0.967 | 0.975 | ||
| TextRNN | Spam | 0.983 | 0.983 | 0.983 | 0.967 | 0.983 | 0.975 | — | — | — | |
| Ham | 0.983 | 0.983 | 0.983 | 0.983 | 0.967 | 0.975 | — | — | — | ||
| TextRCNN | Spam | 0.952 | 0.983 | 0.967 | 0.968 | 1.000 | 0.984 | 0.968 | 1.000 | 0.984 | |
| Ham | 0.983 | 0.950 | 0.966 | 1.000 | 0.967 | 0.983 | 1.000 | 0.967 | 0.983 | ||
| 方法 | 分类器 | 类别 | SMS数据集 | Ads数据集 | Email数据集 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Spam | Ham | AUC | Spam | Ham | AUC | Spam | Ham | AUC | |||
传统 方法 | NB | Spam | 0.867 | 0.133 | 0.842 | 0.900 | 0.100 | 0.933 | 0.950 | 0.050 | 0.892 |
| Ham | 0.183 | 0.817 | 0.033 | 0.967 | 0.167 | 0.833 | |||||
| RF | Spam | 0.750 | 0.250 | 0.842 | 1.000 | 0.000 | 0.967 | 0.967 | 0.033 | 0.908 | |
| Ham | 0.067 | 0.933 | 0.067 | 0.933 | 0.150 | 0.850 | |||||
| SVM | Spam | 0.817 | 0.183 | 0.883 | 0.967 | 0.033 | 0.950 | 0.917 | 0.083 | 0.942 | |
| Ham | 0.050 | 0.950 | 0.067 | 0.933 | 0.033 | 0.967 | |||||
| LR | Spam | 0.783 | 0.217 | 0.867 | 0.967 | 0.033 | 0.958 | 0.967 | 0.033 | 0.942 | |
| Ham | 0.050 | 0.950 | 0.050 | 0.950 | 0.083 | 0.917 | |||||
| DT | Spam | 0.717 | 0.283 | 0.792 | 0.933 | 0.067 | 0.950 | 0.917 | 0.083 | 0.833 | |
| Ham | 0.133 | 0.867 | 0.033 | 0.967 | 0.250 | 0.750 | |||||
当前 主流 方法 | DPCNN | Spam | 0.917 | 0.033 | 0.942 | 1.000 | 0.050 | 0.975 | 0.883 | 0.067 | 0.908 |
| Ham | 0.083 | 0.967 | 0.000 | 0.950 | 0.117 | 0.933 | |||||
| BERT | Spam | 0.900 | 0.067 | 0.917 | 0.983 | 0.033 | 0.975 | 0.850 | 0.050 | 0.900 | |
| Ham | 0.100 | 0.933 | 0.017 | 0.967 | 0.150 | 0.950 | |||||
| TinyBERT | Spam | 0.933 | 0.100 | 0.917 | 0.967 | 0.033 | 0.967 | 0.800 | 0.083 | 0.858 | |
| Ham | 0.067 | 0.900 | 0.033 | 0.967 | 0.200 | 0.917 | |||||
神经 网络 方法 | TextCNN | Spam | 0.967 | 0.033 | 0.967 | 1.000 | 0.000 | 0.992 | 0.983 | 0.017 | 0.975 |
| Ham | 0.033 | 0.967 | 0.017 | 0.983 | 0.033 | 0.967 | |||||
| TextRNN | Spam | 0.983 | 0.017 | 0.983 | 0.983 | 0.017 | 0.975 | — | — | — | |
| Ham | 0.017 | 0.983 | 0.033 | 0.967 | — | — | |||||
| TextRCNN | Spam | 0.983 | 0.017 | 0.967 | 1.000 | 0.000 | 0.983 | 1.000 | 0.000 | 0.983 | |
| Ham | 0.050 | 0.950 | 0.033 | 0.967 | 0.033 | 0.967 | |||||
表4 传统方法、当前主流方法和神经网络方法在三种数据集上的混淆矩阵和AUC值
Tab. 4 Confusion matrixes and AUC values of traditional methods, current methods, and neural network methods on three datasets
| 方法 | 分类器 | 类别 | SMS数据集 | Ads数据集 | Email数据集 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Spam | Ham | AUC | Spam | Ham | AUC | Spam | Ham | AUC | |||
传统 方法 | NB | Spam | 0.867 | 0.133 | 0.842 | 0.900 | 0.100 | 0.933 | 0.950 | 0.050 | 0.892 |
| Ham | 0.183 | 0.817 | 0.033 | 0.967 | 0.167 | 0.833 | |||||
| RF | Spam | 0.750 | 0.250 | 0.842 | 1.000 | 0.000 | 0.967 | 0.967 | 0.033 | 0.908 | |
| Ham | 0.067 | 0.933 | 0.067 | 0.933 | 0.150 | 0.850 | |||||
| SVM | Spam | 0.817 | 0.183 | 0.883 | 0.967 | 0.033 | 0.950 | 0.917 | 0.083 | 0.942 | |
| Ham | 0.050 | 0.950 | 0.067 | 0.933 | 0.033 | 0.967 | |||||
| LR | Spam | 0.783 | 0.217 | 0.867 | 0.967 | 0.033 | 0.958 | 0.967 | 0.033 | 0.942 | |
| Ham | 0.050 | 0.950 | 0.050 | 0.950 | 0.083 | 0.917 | |||||
| DT | Spam | 0.717 | 0.283 | 0.792 | 0.933 | 0.067 | 0.950 | 0.917 | 0.083 | 0.833 | |
| Ham | 0.133 | 0.867 | 0.033 | 0.967 | 0.250 | 0.750 | |||||
当前 主流 方法 | DPCNN | Spam | 0.917 | 0.033 | 0.942 | 1.000 | 0.050 | 0.975 | 0.883 | 0.067 | 0.908 |
| Ham | 0.083 | 0.967 | 0.000 | 0.950 | 0.117 | 0.933 | |||||
| BERT | Spam | 0.900 | 0.067 | 0.917 | 0.983 | 0.033 | 0.975 | 0.850 | 0.050 | 0.900 | |
| Ham | 0.100 | 0.933 | 0.017 | 0.967 | 0.150 | 0.950 | |||||
| TinyBERT | Spam | 0.933 | 0.100 | 0.917 | 0.967 | 0.033 | 0.967 | 0.800 | 0.083 | 0.858 | |
| Ham | 0.067 | 0.900 | 0.033 | 0.967 | 0.200 | 0.917 | |||||
神经 网络 方法 | TextCNN | Spam | 0.967 | 0.033 | 0.967 | 1.000 | 0.000 | 0.992 | 0.983 | 0.017 | 0.975 |
| Ham | 0.033 | 0.967 | 0.017 | 0.983 | 0.033 | 0.967 | |||||
| TextRNN | Spam | 0.983 | 0.017 | 0.983 | 0.983 | 0.017 | 0.975 | — | — | — | |
| Ham | 0.017 | 0.983 | 0.033 | 0.967 | — | — | |||||
| TextRCNN | Spam | 0.983 | 0.017 | 0.967 | 1.000 | 0.000 | 0.983 | 1.000 | 0.000 | 0.983 | |
| Ham | 0.050 | 0.950 | 0.033 | 0.967 | 0.033 | 0.967 | |||||
| 方法 | 分类器 | 运行时间 | ||
|---|---|---|---|---|
| SMS数据集 | Ads数据集 | Email数据集 | ||
当前 主流 方法 | DPCNN | 3.4 | 37.1 | 1 098.1 |
| BERT | 61.6 | 358.1 | 320.0 | |
| Tiny-BERT | 17.8 | 77.7 | 78.1 | |
神经 网络 方法 | TextCNN | 2.2 | 6.0 | 138.4 |
| TextRNN | 1.9 | 11.3 | — | |
| TextRCNN | 1.9 | 12.7 | 869.0 | |
表5 传统方法、当前主流方法和神经网络方法在三种数据集上的运行时间 (s)
Tab. 5 Running times of traditional methods, current methods and neural network methods on three datasets
| 方法 | 分类器 | 运行时间 | ||
|---|---|---|---|---|
| SMS数据集 | Ads数据集 | Email数据集 | ||
当前 主流 方法 | DPCNN | 3.4 | 37.1 | 1 098.1 |
| BERT | 61.6 | 358.1 | 320.0 | |
| Tiny-BERT | 17.8 | 77.7 | 78.1 | |
神经 网络 方法 | TextCNN | 2.2 | 6.0 | 138.4 |
| TextRNN | 1.9 | 11.3 | — | |
| TextRCNN | 1.9 | 12.7 | 869.0 | |
| 1 | EL-ALFY E-S M, ALHASAN A A. Spam filtering framework for multimodal mobile communication based on dendritic cell algorithm [J]. Future Generation Computer Systems, 2016, 64: 98-107. 10.1016/j.future.2016.02.018 |
| 2 | FERNANDES D, COSTA K A P D, ALMEIDA T A, et al. SMS spam filtering through optimum-path forest-based classifiers[C]// Proceedings of the 2015 International Conference on Machine Learning and Applications. Piscataway: IEEE, 2015: 133-137. 10.1109/icmla.2015.71 |
| 3 | RAZAK M F AB, ANUAR N B, SALLEH R, et al. The rise of “malware”: Bibliometric analysis of malware study[J]. Journal of Network and Computer Applications, 2016, 75: 58-76. 10.1016/j.jnca.2016.08.022 |
| 4 | ALMEIDA T, HIDALGO J M G, SILVA T P. Towards SMS spam filtering: results under a new dataset[J]. International Journal of Information Security Science, 2013, 2(1): 1-18. |
| 5 | JUNAID M B, FAROOQ M. Using evolutionary learning classifiers to do MobileSpam (SMS) filtering [C]// Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation. New York: ACM, 2011: 1795-1802. 10.1145/2001576.2001817 |
| 6 | SILVA R M, ALMEIDA T A, YAMAKAMI A. MDLText: an efficient and lightweight text classifier [J]. Knowledge-Based Systems, 2017, 118: 152-164. 10.1016/j.knosys.2016.11.018 |
| 7 | ADEWOLE K S, ANUAR N B, KAMSIN A, et al. SMSAD: a framework for spam message and spam account detection [J]. Kluwer Academic Publishers, 2019, 78(4): 3925-3960. 10.1007/s11042-017-5018-x |
| 8 | BOUJNOUNI M E. SMS spam filtering using N-gram method, information gain metric and an improved version of SVDD classifier [J]. Journal of Engineering Science and Technology Review, 2017, 10(1): 131-137. 10.25103/jestr.101.18 |
| 9 | RUANO-ORDÁS D, FDEZ-GLEZ J, FDEZ-RIVEROLA F, et al. RuleSIM: a toolkit for simulating the operation and improving throughput of rule-based spam filters [J]. Software Practice & Experience, 2016,46(8): 1091-1108. 10.1002/spe.2342 |
| 10 | 郝苗苗, 徐秀娟, 于红, 等. 基于中文微博的情绪分类与预测算法 [J]. 计算机应用, 2018, 38(S2): 89-96. |
| HAO M M, XU X J, YU H, et al. Emotion classification and prediction algorithm based on Chinese microblog [J]. Journal of Computer Applications, 2018, 38(S2): 89-96. | |
| 11 | 焦庆争, 蔚承建. 分布权值调节概率标准差的文本分类方法[J]. 计算机应用, 2009, 29(12): 3303-3306. 10.3724/sp.j.1087.2009.03303 |
| JIAO Q Z, WEI C J. Text categorization approach based on probability standard deviation with evaluation of distribution information [J]. Journal of Computer Applications, 2009, 29(12): 3303-3306. 10.3724/sp.j.1087.2009.03303 | |
| 12 | RUANO-ORDAS D, FDEZ-GLEZ J, FDEZ-RIVEROLA F, et al. Effective scheduling strategies for boosting performance on rule-based spam filtering frameworks [J]. Journal of Systems & Software, 2013, 86(12): 3151-3161. 10.1016/j.jss.2013.07.036 |
| 13 | RUANO-ORDÁS D, FDEZ-GLEZ J, FDEZ-RIVEROLA F, et al. Using new scheduling heuristics based on resource consumption information for increasing throughput on rule-based spam filtering systems [J]. Software Practice & Experience, 2016, 46(8): 1035-1051. 10.1002/spe.2343 |
| 14 | WU C-H. Behavior-based spam detection using a hybrid method of rule-based techniques and neural networks [J]. Expert Systems with Applications, 2009, 36(3): 4321-4330. 10.1016/j.eswa.2008.03.002 |
| 15 | LUO Q, LIU B, YAN J, et al. Design and implement a rule-based spam filtering system using neural network [C]// Proceedings of the 2011 International Conference on Computational and Information Sciences. Piscataway: IEEE, 2011: 398-401. 10.1109/iccis.2011.125 |
| 16 | CUTLER A, CUTLER D R, STEVENS J R. Random forests [J]. Machine Learning, 2011, 45: 157-176. 10.1007/978-1-4419-9326-7_5 |
| 17 | CORTES C, VAPNIK V. Support-vector networks [J]. Machine Learning, 1995, 20(3): 273-297. 10.1007/bf00994018 |
| 18 | 高秀梅, 陈芳, 宋枫溪, 等. 特征权对贝叶斯分类器文本分类性能的影响[J]. 计算机应用, 2008, 28(12): 3080-3083. 10.3724/sp.j.1087.2008.03080 |
| GAO X M, CHEN F, SONG F X, et al. Influence of feature weight on text categorization performance of Bayesian classifier [J]. Journal of Computer Applications,2008,28(12):3080-3083. 10.3724/sp.j.1087.2008.03080 | |
| 19 | 董才正, 刘柏嵩. 面向问答社区的中文问题分类[J]. 计算机应用, 2016, 36(4): 1060-1065. 10.11772/j.issn.1001-9081.2016.04.1060 |
| DONG C Z, LIU B S. Community question answering-oriented Chinese question classification [J]. Journal of Computer Applications, 2016, 36(4): 1060-1065. 10.11772/j.issn.1001-9081.2016.04.1060 | |
| 20 | MARTINEAU J, FININ T. Delta TFIDF: an improved feature space for sentiment analysis [C]// Proceedings of the 2009 International Conference on Weblogs and Social Media. Palo Alto, CA: AAAI, 2009:258-261. 10.1109/cse.2009.584 |
| 21 | KIM Y. Convolutional neural networks for sentence classification [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1746-1751. 10.3115/v1/d14-1181 |
| 22 | LIU P, QIU X, HUANG X. Recurrent neural network for text classification with multi-task learning [C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI, 2016: 2873-2879. |
| 23 | LAI S, XU L, LIU K, et al. Recurrent convolutional neural networks for text classification [C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI, 2015: 2267-2273. 10.1609/aaai.v33i01.33017370 |
| 24 | LUONG T, PHAM H, MANNING C D. Effective approaches to attention-based neural machine translation [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 1412-1421. 10.18653/v1/d15-1166 |
| 25 | YANG Z, YANG D, DYER C, et al. Hierarchical attention networks for document classification [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1480-1489. 10.18653/v1/n16-1174 |
| 26 | JOHNSON R, ZHANG T. Deep pyramid convolutional neural networks for text categorization [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2017: 562-570. 10.18653/v1/p17-1052 |
| 27 | MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [EB/OL].[2020-06-22] . 10.3126/jiee.v3i1.34327 |
| 28 | PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1532-1543. 10.3115/v1/d14-1162 |
| 29 | PETERS M, NEUMANN M, IYYER M, et al. Deep contextualized word representations [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2018: 2227-2237. 10.18653/v1/n18-1202 |
| 30 | DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186. 10.18653/v1/n19-1423 |
| 31 | JIAO X, YIN Y, SHANG L, et al. TinyBERT: Distilling BERT for natural language understanding[C]// Proceedings of the 2020 Findings of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 4163-4174. 10.18653/v1/2020.findings-emnlp.372 |
| 32 | DUA D, GRAFF C. UCI machine learning repository [D]. Irvine, California: University of California, 2017. |
| 33 | PISHARADY P K, VADAKKEPAT P, POH L A. Hand posture and face recognition using fuzzy-rough approach[C]// Computational Intelligence in Multi-Feature Visual Pattern Recognition. Singapore: Springer, 2014: 63-80. 10.1007/978-981-287-056-8_5 |
| 34 | BOUJON C. Playing with text classified ads [EB/OL]. [2020-07-24]. . |
| 35 | KROONBERG M VAN DEN, VEST B.Index of /old/publiccorpus [EB/OL]. [2020-07-21]. . |
| 36 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735 |
| 37 | TAGG C. A corpus linguistics study of SMS text messaging [D]. Birmingham: University of Birmingham, 2009. |
| 38 | 杨国峰, 杨勇. 基于BERT的常见作物病害问答系统问句分类[J]. 计算机应用, 2020, 40(6): 1580-1586. 10.1109/wacv45572.2020.9093596 |
| YANG G F, YANG Y. Question classification of common crop disease question answering system based on BERT [J]. Journal of Computer Applications, 2020, 40(6): 1580-1586. 10.1109/wacv45572.2020.9093596 | |
| 39 | YANG Z, DAI Z, YANG Y, et al. XLNet: generalized autoregressive pretraining for language understanding [C]// Proceedings of the 2019 Advances in Neural Information Processing Systems. New York: Curran Associates, 2019, 32: 5754-5764. 10.1016/j.ymssp.2019.106289 |
| 40 | NURUZZAMAN M T, LEE C, CHOI D. Independent and personal SMS spam filtering [C]// Proceedings of the 2011 International Conference on Computer and Information Technology. Piscataway: IEEE, 2011: 429-435. 10.1109/cit.2011.23 |
| [1] | 黄勇康, 梁美玉, 王笑笑, 陈徵, 曹晓雯. 基于深度时空残差卷积神经网络的课堂教学视频中多人课堂行为识别[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 736-742. |
| [2] | 陈亭秀, 尹建芹. 基于关键帧筛选网络的视听联合动作识别[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 731-735. |
| [3] | 张璐, 方春, 祝铭. 基于Res2Net-YOLACT和融合特征的室内跌倒检测算法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 757-763. |
| [4] | 潘仁志, 钱付兰, 赵姝, 张燕平. 基于卷积神经网络交互的用户属性偏好建模的推荐模型[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 404-411. |
| [5] | 陈薪羽, 刘明哲, 任俊, 汤影. 基于多列卷积神经网络的参数异步更新算法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 395-403. |
| [6] | 富坤, 高金辉, 赵晓梦, 李佳宁. 融合全局结构信息的拓扑优化图卷积网络[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 357-364. |
| [7] | 刘羽茜, 刘玉奇, 张宗霖, 卫志华, 苗冉. 注入注意力机制的深度特征融合新闻推荐模型[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 426-432. |
| [8] | 李薇, 樊瑶驰, 江巧永, 王磊, 徐庆征. 基于教与学优化的可变卷积自编码器的医学图像分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 592-598. |
| [9] | 陈权, 李莉, 陈永乐, 段跃兴. 面向深度学习可解释性的对抗攻击算法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 510-518. |
| [10] | 许慧青, 陈斌, 王敬飞, 陈志毅, 覃健. 基于卷积神经网络的细长路面病害检测方法[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 265-272. |
| [11] | 李建明, 陈斌, 江志伟, 覃健. 优化搜索空间下带约束的可微分神经网络架构搜索[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 44-49. |
| [12] | 吕学强, 彭郴, 张乐, 董志安, 游新冬. 融合BERT与标签语义注意力的文本多标签分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 57-63. |
| [13] | 包银鑫, 曹阳, 施佺. 基于改进时空残差卷积神经网络的城市路网短时交通流预测[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 258-264. |
| [14] | 段佳良, 蔡国明, 徐开勇. 基于多BP神经网络的内存组合特征分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 178-182. |
| [15] | 李恒鑫, 常侃, 谭宇飞, 凌铭阳, 覃团发. 应用通道间相关性及增强信息蒸馏的彩色图像去马赛克网络[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 245-251. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||