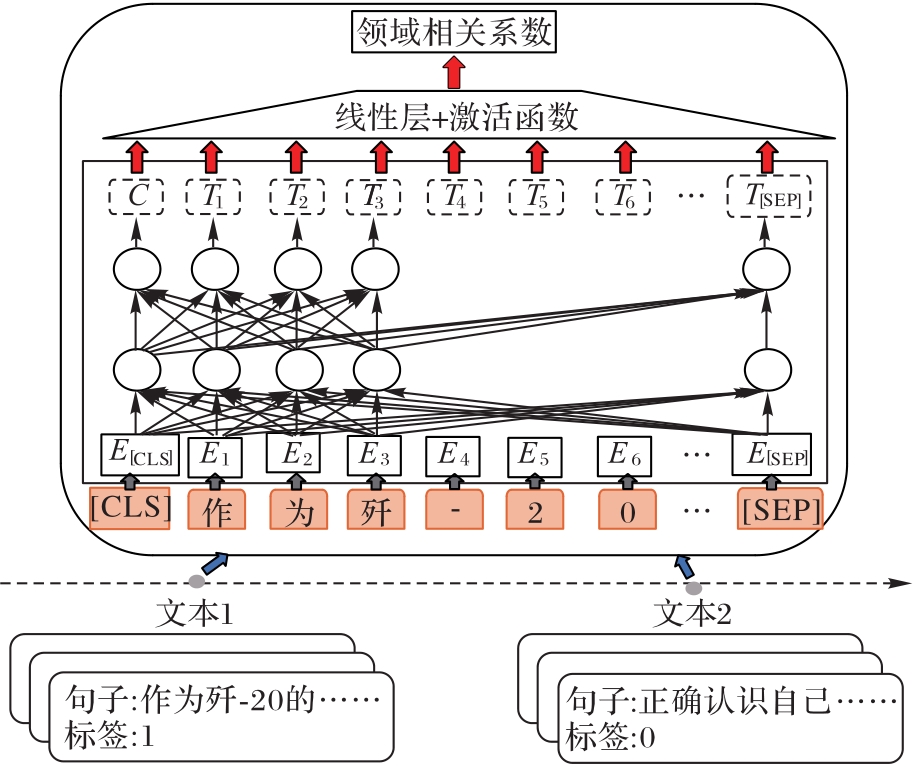
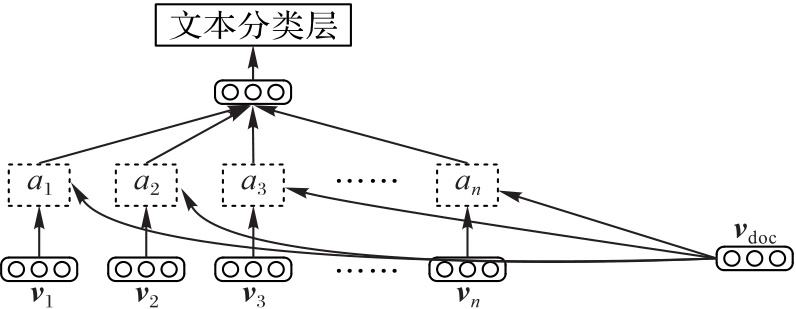
| 1 |
庞观松,蒋盛益. 文本自动分类技术研究综述[J]. 情报理论与实践, 2012, 35(2):123-128.
|
|
PANG G S, JIANG S Y. A summary of research on automatic text classification technologies[J]. Information Studies: Theory and Application, 2012, 35(2): 123-128.
|
| 2 |
LEWIS D D. Naive (Bayes) at forty: the independence assumption in information retrieval[C]// Proceeding of the 1998 European Conference on Machine Learning, LNCS 1398. Berlin: Springer, 1998: 4-15.
|
| 3 |
CORTES C, VAPNIK V. Support-vector networks[J]. Machine Learning, 1995, 20(3): 273-297. 10.1007/bf00994018
|
| 4 |
COVER T M, HART P E. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory, 1967, 13(1): 21-27. 10.1109/tit.1967.1053964
|
| 5 |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186. 10.18653/v1/n19-1423
|
| 6 |
KIM Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1746-1751. 10.3115/v1/d14-1181
|
| 7 |
杨玉基,许斌,胡家威,等. 一种准确而高效的领域知识图谱构建方法[J]. 软件学报, 2018, 29(10):2931-2947. 10.13328/j.cnki.jos.005552
|
|
YANG Y J, XU B, HU J W, et al. Accurate and efficient method for constructing domain knowledge graph[J]. Journal of Software, 2018, 29(10):2931-2947. 10.13328/j.cnki.jos.005552
|
| 8 |
JOHNSON R, ZHANG T. Deep pyramid convolutional neural networks for text categorization[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 562-570. 10.18653/v1/p17-1052
|
| 9 |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735
|
| 10 |
LAI S W, XU L H, LIU K, et al. Recurrent convolutional neural networks for text classification[C]// Proceeding of the 29th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2015: 2267-2273. 10.1609/aaai.v33i01.33017370
|
| 11 |
YANG Z C, YANG D Y, DYER C, et al. Hierarchical attention networks for document classification[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1480-1489. 10.18653/v1/n16-1174
|
| 12 |
CHO K, van MERRIËNBOER B, GU̇LÇEHRE Ç, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1724-1734. 10.3115/v1/d14-1179
|
| 13 |
卢玲,杨武,王远伦,等. 结合注意力机制的长文本分类方法[J]. 计算机应用, 2018, 38(5):1272-1277. 10.11772/j.issn.1001-9081.2017112652
|
|
LU L, YANG W, WANG Y L, et al. Long text classification combined with attention mechanism[J]. Journal of Computer Applications, 2018, 38(5):1272-1277. 10.11772/j.issn.1001-9081.2017112652
|
| 14 |
LE Q, MIKOLOV T. Distributed representations of sentences and documents[C]// Proceedings of the 31st International Conference on International Conference on Machine Learning. New York: JMLR.org, 2014: 1188-1196.
|
| 15 |
CHOI G, OH S, KIM H. Improving document-level sentiment classification using importance of sentences[J]. Entropy, 2020, 22(12): No.1336. 10.3390/e22121336
|
| 16 |
LAN Z Z, CHEN M D, GOODMAN S, et al. ALBERT: a lite BERT for self-supervised learning of language representations[EB/OL]. (2020-02-09) [2021-05-28].. 10.48550/arXiv.1909.11942
|
| 17 |
SALTON G, YU C T. On the construction of effective vocabularies for information retrieval[J]. ACM SIGPLAN Notices, 1975, 10(1):48-60. 10.1145/951787.951766
|
| 18 |
MIHALCEA R, TARAU P. TextRank: bringing order into text[C]// Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2004: 404-411. 10.3115/1220355.1220517
|
| 19 |
MACQUEEN J. Some methods for classification and analysis of multivariate observations[C]// Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley and Los Angeles, CA: University of California Press, 1967: 281-297.
|
| 20 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceeding of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. 10.1016/s0262-4079(17)32358-8
|
| 21 |
JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification[C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. Stroudsburg, PA: Association for Computational Linguistics, 2017: 427-431. 10.18653/v1/e17-2068
|
| 22 |
LIU P F, QIU X P, HUANG X J. Recurrent neural network for text classification with multi-task learning[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. California: IJCAI Organization, 2016: 2873-2879. 10.18653/v1/d16-1012
|


 ), 仝美涵1, 韩美奂1,3, 王黎明4, 钟琦4
), 仝美涵1, 韩美奂1,3, 王黎明4, 钟琦4