


Journal of Computer Applications ›› 2020, Vol. 40 ›› Issue (2): 571-577.DOI: 10.11772/j.issn.1001-9081.2019081462
• Data science and technology • Previous Articles Next Articles
Received:2019-08-22
Revised:2019-11-04
Accepted:2019-11-18
Online:2019-12-04
Published:2020-02-10
Contact:
Yulong TAN
About author:XU Jiangfeng,born in 1965,Ph. D., professor. His research interests include data encryption, network security.
Supported by:
徐江峰, 谭玉龙( )
)
通讯作者:
谭玉龙
作者简介:徐江峰(1965—),男,河南禹州人,教授,博士,CCF会员,主要研究方向:数据加密、网络安全;
基金资助:CLC Number:
Jiangfeng XU, Yulong TAN. Optimization of multidimensional index query mechanism based on HBase[J]. Journal of Computer Applications, 2020, 40(2): 571-577.
徐江峰, 谭玉龙. 基于HBase的多维索引查询机制的优化[J]. 《计算机应用》唯一官方网站, 2020, 40(2): 571-577.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2019081462

Fig. 1 Two-dimensional space and its equivalent first order Hilbert curve

Fig. 2 Two-dimensional second-order Hilbert curve

Fig. 3 Tree representation of two-dimensional second order Hilbert curve

Fig. 4 Example of P-Grid trie

Fig. 5 New-grid system architecture

Fig. 6 Example of a range query on points mapped to two-dimensional second order Hilbert curve

Fig. 7 Effect of varying the number of workload generators
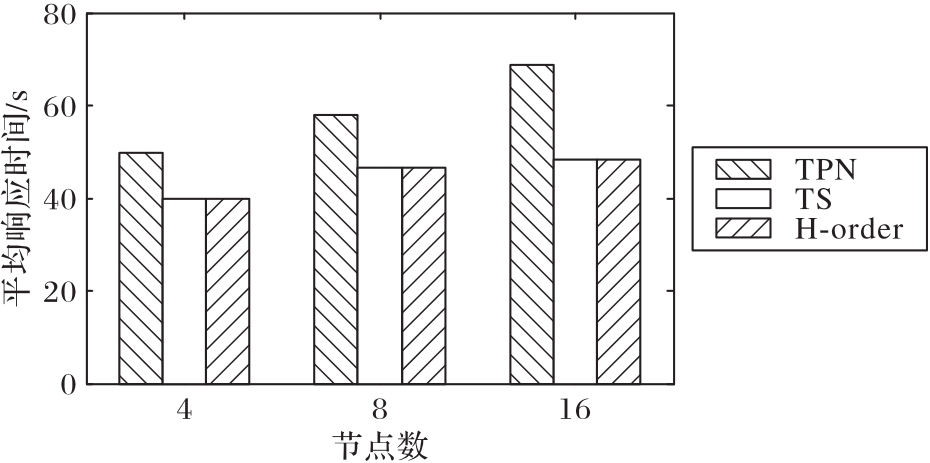
Fig. 8 Performance of point query (D=3)

Fig. 9 Performance of range query (number of nodes is 4, D=2)

Fig. 10 Performance of range query (selectivity =10%,?D=2)

Fig. 11 Performance of range query (number of nodes is 4, D=3)

Fig. 12 Performance of range query (selectivity=10%, D=3)

Fig. 13 Performance of KNN query (number of nodes is 4, D=2)

Fig. 14 Performance of KNN query (k=10?000,?D=2)

Fig. 15 Performance of KNN query (number of nodes is 4, D=3)

Fig. 16 Performance of KNN query (k=10 000, D=3)
| 1 | McMAHON M, STEKETEE C. Investigation of proposed applications for LBS enabled mobile handsets [C]// Proceedings of the 2006 International Conference on Mobile Business. Washington, DC: IEEE Computer Society, 2006: 26. 10.1109/icmb.2006.27 |
| 2 | GUTTMAN A. R-trees:a dynamic index structure for spatial searching[C]// Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data. New York: ACM, 1984: 47-57. 10.1145/602259.602266 |
| 3 | FINKEL R A, BENTLEY J L. Quad trees a data structure for retrieval on composite keys [J]. Acta Informatica,1974, 4(1): 1-9. 10.1007/bf00288933 |
| 4 | CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable: a distributed storage system for structured data[J]. ACM Transactions on Computer Systems, 2008, 26(2): 1-1-26. 10.1145/1365815.1365816 |
| 5 | HBase [2019-05-12]. . 10.1007/978-1-4842-2424-3_2 |
| 6 | Apache. Apache Cassandra[2019-04-19]. . 10.1007/978-1-4842-3126-5_1 |
| 7 | 夏露.基于MapReduce的PageRank计算系统的设计与实现[D].沈阳:东北大学,2011:22-24. |
| XIA L. Design and implementation of a PageRank computing system based on MapReduce[D]. Shenyang: Northeast University, 2011: 22-24. | |
| 8 | HILLERT D.Ueber die stetige Abbildung einer Line auf ein Flächenstück[J]. Mathematische Annalen, 1891, 38: 459-460. 10.1007/bf01199431 |
| 9 | ABERER K, CUDRÉ-MAUROUX P, DATTA A, et al. P-Grid: a self-organizing structured P2P system[J]. ACM SIGMOD Record, 2003, 32(3): 29-33. 10.1145/945721.945729 |
| 10 | LI F, CHEN R, ZHOU C, et al. A novel geo-spatial image storage method based on Hilbert space filling curves[C]// Proceedings of the 2010 18th International Conference on Geoinformatics. Piscataway: IEEE, 2010: 1-4. 10.1109/geoinformatics.2010.5567999 |
| 11 | PAVANAKUMAR M, KAUSHIK K N. Revisiting the space-filling curves for storage, reordering and partitioning mesh based data in scientific computing [C]// Proceedings of the 2013 20th International Conference on High Performance Computing (HiPC). Washington, DC: IEEE Computer Society, 2013, 1: 362-367. 10.1109/hipc.2013.6799097 |
| 12 | HU C, ZHAO Y, WEI X, et al. ACTGIS: a Web-based collaborative tiled geospatial image map system[C]// Proceedings of the 2010 IEEE Symposium on Computers and Communications. Piscataway: IEEE, 2010: 521-528. 10.1109/iscc.2010.5546717 |
| 13 | BUTZ A R. Alternative algorithm for Hilbert’s space-filling curve [J]. IEEE Transactions on Computers, 1971, C-20(4): 424-426. 10.1109/t-c.1971.223258 |
| 14 | BIALLY T. Space-filling curves: their generation and their application to bandwidth reduction[J]. IEEE Transactions on Information Theory, 1969, 15(6): 658-664. 10.1109/tit.1969.1054385 |
| 15 | HAMILTON C H, RAU-CHAPLIN A. Compact Hilbert indices for multi-dimensional data[C]// Proceedings of the First International Conference on Complex, Intelligent and Software Intensive Systems. Washington, DC: IEEE Computer Society, 2007: 139-146. 10.1109/cisis.2007.16 |
| 16 | 田敬,代亚非.P2P持久存储研究[J].软件学报,2007,18(6):1379-1399. 10.1360/jos181379 |
| TIAN J, DAI Y F. Study on durable Peer-to-Peer storage techniques[J]. Journal of Software, 2007, 18(6): 1379-1399. 10.1360/jos181379 | |
| 17 | ABERER K, DATTA A, HAUSWIRTH M: Indexing data-oriented overlay networks [C]// Proceedings of the 31st International Conference on Very Large Data Bases. New York: ACM, 2005: 685-696. |
| 18 | TAO Y, ZHANG J, PAPADIAS D, et al. An efficient cost model for optimization of nearest neighbor search in low and medium dimensional space [J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(10): 1169-1184. 10.1109/tkde.2004.48 |
| 19 | NISHIMURA S, DA S, AGRAWAL D, et al. MD-HBase: design and implementation of elastic infrastructure for cloud-scale location services[J]. Distributed and Parallel Databases, 2013, 31: 289-319. 10.1007/s10619-012-7109-z |
| 20 | COOPER B F, SILBERSTEIN A, TAM E, et al. Benchmarking cloud serving systems with YCSB[C]// Proceedings of the 1st ACM Symposium on Cloud Computing. New York: ACM, 2010: 143-154. 10.1145/1807128.1807152 |
| 21 | CRAINICEANU A, LINGA P, MACHANAVAJJHALA A, et al. P-ring: an efficient and robust P2P range index structure[C]// Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2007: 223-234. 10.1145/1247480.1247507 |
| [1] | Li YANG, Jianting CHEN, Yang XIANG. Performance optimization strategy of distributed storage for industrial time series big data based on HBase [J]. Journal of Computer Applications, 2023, 43(3): 759-766. |
| [2] | CUI Shuangshuang, WANG Hongzhi. Implementation method of lightweight distributed index based on log structured merge-tree [J]. Journal of Computer Applications, 2021, 41(3): 630-635. |
| [3] | FU Yu, WANG Hong. Virtual trajectory filling algorithm for location privacy protection [J]. Journal of Computer Applications, 2019, 39(8): 2318-2325. |
| [4] | FENG Jun, LI Dingsheng, LU Jiamin, ZHANG Lixia. Spatio-temporal index method for moving objects in road network based on HBase [J]. Journal of Computer Applications, 2018, 38(6): 1575-1583. |
| [5] | CUI Chen, ZHENG Linjiang, HAN Fengping, HE Mujun. Design of secondary indexes in HBase based on memory [J]. Journal of Computer Applications, 2018, 38(6): 1584-1590. |
| [6] | WU Renbiao, LIU Chao, QU Jingyi. Storage method for flight delay platform based on HBase and Hive [J]. Journal of Computer Applications, 2018, 38(5): 1339-1345. |
| [7] | CUI Weirong, DU Chenglie. Fast proximity testing method with privacy preserving in mobile social network [J]. Journal of Computer Applications, 2017, 37(6): 1657-1662. |
| [8] | FANG Jun, LI Dong, GUO Huiyun, WANG Jiayi. Spatio-temporal index for massive traffic data based on HBase [J]. Journal of Computer Applications, 2017, 37(2): 311-315. |
| [9] | ZHAO Dapeng, SONG Guangxuan, JIN Yuanyuan, WANG Xiaoling. Query probability-based location privacy protection approach [J]. Journal of Computer Applications, 2017, 37(2): 347-351. |
| [10] | LIU Qing, FU Yinjin, NI Guiqiang, MEI Jianmin. Distributed deduplication storage system based on Hadoop platform [J]. Journal of Computer Applications, 2016, 36(2): 330-335. |
| [11] | PI Wenjun, GONG Xiujun. Data driven parallel incremental support vector machine learning algorithm based on Hadoop framework [J]. Journal of Computer Applications, 2016, 36(11): 3044-3049. |
| [12] | LI Zhenju, LI Xuejun, XIE Jianwei, LI Yannan. Massive terrain data storage based on HBase [J]. Journal of Computer Applications, 2015, 35(7): 1849-1853. |
| [13] | LU Ting, FANG Jun, QIAO Yanke. HBase-based real-time storage system for traffic stream data [J]. Journal of Computer Applications, 2015, 35(1): 103-107. |
| [14] | LIU Zhaobin LIU Wenzhi FANG Ligang TANG Yazhe. Channel allocation model and credibility evaluation for LBS indoor nodes [J]. Journal of Computer Applications, 2013, 33(03): 603-606. |
| [15] | CHEN Qing-kui ZHOU Li-zhen. HBase-based storage system for large-scale data in wireless sensor network [J]. Journal of Computer Applications, 2012, 32(07): 1920-1923. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||