


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (5): 1349-1354.DOI: 10.11772/j.issn.1001-9081.2022030424
• China Conference on Data Mining 2022 (CCDM 2022) • Previous Articles
Yu TAN1, Xiaoqin WANG1, Rushi LAN1( ), Zhenbing LIU1, Xiaonan LUO2
), Zhenbing LIU1, Xiaonan LUO2
Received:2022-04-01
Revised:2022-07-19
Accepted:2022-08-03
Online:2023-05-08
Published:2023-05-10
Contact:
Rushi LAN
About author:TAN Yu, born in 1997, M. S. candidate. Her research interests include cross-modal retrieval, machine learning.Supported by:通讯作者:
蓝如师
作者简介:谭钰(1997—),女,广西南宁人,硕士研究生,主要研究方向:跨模态检索、机器学习基金资助:CLC Number:
Yu TAN, Xiaoqin WANG, Rushi LAN, Zhenbing LIU, Xiaonan LUO. Multi-label cross-modal hashing retrieval based on discriminative matrix factorization[J]. Journal of Computer Applications, 2023, 43(5): 1349-1354.
谭钰, 王小琴, 蓝如师, 刘振丙, 罗笑南. 基于判别性矩阵分解的多标签跨模态哈希检索[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1349-1354.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022030424
| 方法 | I2T任务 | T2I任务 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MIRFlickr | NUS-WIDE | MIRFlickr | NUS-WIDE | |||||||||
| 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | |
| CMFH | 55.84 | 56.30 | 56.06 | 50.79 | 48.97 | 50.93 | 55.33 | 55.70 | 55.65 | 52.02 | 50.18 | 53.67 |
| SCM | 63.45 | 63.85 | 64.90 | 54.22 | 54.88 | 54.83 | 62.34 | 62.85 | 63.69 | 50.67 | 51.41 | 51.61 |
| SMFH | 59.97 | 59.56 | 59.86 | 36.13 | 36.28 | 36.35 | 59.09 | 59.15 | 59.54 | 35.24 | 35.29 | 35.39 |
| DCH | 57.29 | 57.39 | 58.68 | 74.60 | 75.93 | 78.43 | 68.70 | 69.13 | 70.73 | |||
| GSePH | 66.17 | 66.94 | 67.34 | 71.13 | 72.47 | 73.10 | 65.46 | 67.42 | 70.03 | |||
| JIMFH | 65.47 | 66.07 | 66.94 | 57.59 | 58.29 | 58.40 | ||||||
| SRLCH | 63.10 | 66.55 | 66.56 | 42.00 | 44.40 | 43.75 | 60.83 | 62.81 | 63.46 | 51.34 | 51.16 | 52.97 |
| DMFH | 72.38 | 73.16 | 72.79 | 63.50 | 64.22 | 64.36 | 80.00 | 80.18 | 79.17 | 75.82 | 75.15 | 75.43 |
Tab. 1 mAP results comparison for I2T and T2I tasks on experimental datasets MIRFlickr and NUS-WIDE
| 方法 | I2T任务 | T2I任务 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MIRFlickr | NUS-WIDE | MIRFlickr | NUS-WIDE | |||||||||
| 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | |
| CMFH | 55.84 | 56.30 | 56.06 | 50.79 | 48.97 | 50.93 | 55.33 | 55.70 | 55.65 | 52.02 | 50.18 | 53.67 |
| SCM | 63.45 | 63.85 | 64.90 | 54.22 | 54.88 | 54.83 | 62.34 | 62.85 | 63.69 | 50.67 | 51.41 | 51.61 |
| SMFH | 59.97 | 59.56 | 59.86 | 36.13 | 36.28 | 36.35 | 59.09 | 59.15 | 59.54 | 35.24 | 35.29 | 35.39 |
| DCH | 57.29 | 57.39 | 58.68 | 74.60 | 75.93 | 78.43 | 68.70 | 69.13 | 70.73 | |||
| GSePH | 66.17 | 66.94 | 67.34 | 71.13 | 72.47 | 73.10 | 65.46 | 67.42 | 70.03 | |||
| JIMFH | 65.47 | 66.07 | 66.94 | 57.59 | 58.29 | 58.40 | ||||||
| SRLCH | 63.10 | 66.55 | 66.56 | 42.00 | 44.40 | 43.75 | 60.83 | 62.81 | 63.46 | 51.34 | 51.16 | 52.97 |
| DMFH | 72.38 | 73.16 | 72.79 | 63.50 | 64.22 | 64.36 | 80.00 | 80.18 | 79.17 | 75.82 | 75.15 | 75.43 |

Fig. 1 Comprehensive analysis curves of experiments
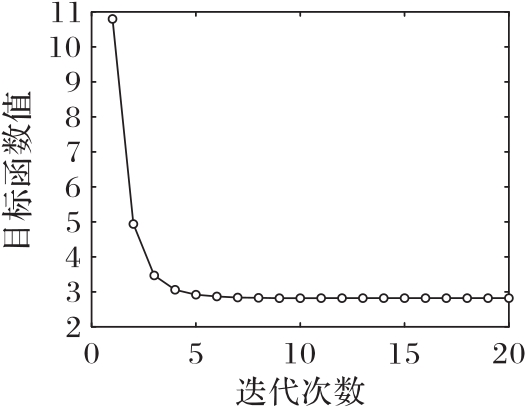
Fig. 2 Convergence curve of DMFH on dataset NUS-WIDE
| 任务 | C | MIRFlickr | NUS-WIDE | ||||
|---|---|---|---|---|---|---|---|
| 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | ||
| I2T | √ | 72.38 | 73.16 | 72.79 | 63.50 | 64.22 | 64.36 |
| × | 63.68 | 62.97 | 62.91 | 51.50 | 52.30 | 52.63 | |
| T2I | √ | 80.00 | 80.18 | 79.17 | 75.82 | 75.15 | 75.43 |
| × | 64.92 | 64.59 | 64.54 | 53.50 | 54.39 | 55.00 | |
Tab. 2 Influence of balanced matrix term C on mAP
| 任务 | C | MIRFlickr | NUS-WIDE | ||||
|---|---|---|---|---|---|---|---|
| 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | ||
| I2T | √ | 72.38 | 73.16 | 72.79 | 63.50 | 64.22 | 64.36 |
| × | 63.68 | 62.97 | 62.91 | 51.50 | 52.30 | 52.63 | |
| T2I | √ | 80.00 | 80.18 | 79.17 | 75.82 | 75.15 | 75.43 |
| × | 64.92 | 64.59 | 64.54 | 53.50 | 54.39 | 55.00 | |
| 任务 | 矩阵 | MIRFlickr | NUS-WIDE | ||||
|---|---|---|---|---|---|---|---|
| 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | ||
| I2T | S | 72.38 | 73.16 | 72.79 | 63.50 | 64.22 | 64.36 |
| 71.56 | 71.71 | 72.27 | 62.10 | 63.18 | 63.17 | ||
| T2I | S | 80.00 | 80.18 | 79.17 | 75.82 | 75.15 | 75.43 |
| 78.56 | 78.37 | 78.84 | 73.34 | 74.30 | 74.17 | ||
Tab. 3 Comparison of mAP between traditional similarity matrix S' andproposed similarity matrix S
| 任务 | 矩阵 | MIRFlickr | NUS-WIDE | ||||
|---|---|---|---|---|---|---|---|
| 32 b | 64 b | 128 b | 32 b | 64 b | 128 b | ||
| I2T | S | 72.38 | 73.16 | 72.79 | 63.50 | 64.22 | 64.36 |
| 71.56 | 71.71 | 72.27 | 62.10 | 63.18 | 63.17 | ||
| T2I | S | 80.00 | 80.18 | 79.17 | 75.82 | 75.15 | 75.43 |
| 78.56 | 78.37 | 78.84 | 73.34 | 74.30 | 74.17 | ||
| 1 | GONG Y C, LAZEBNIK S, GORDO A, et al. Iterative quantization: a procrustean approach to learning binary codes for large-scale image retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2916-2929. 10.1109/tpami.2012.193 |
| 2 | RASIWASIA N, COSTA PEREIRA J, COVIELLO E, et al. A new approach to cross-modal multimedia retrieval[C]// Proceedings of the 18th ACM International Conference on Multimedia. New York: ACM, 2010: 251-260. 10.1145/1873951.1873987 |
| 3 | 冯霞,胡志毅,刘才华. 跨模态检索研究进展综述[J]. 计算机科学, 2021, 48(8): 13-23. 10.11896/jsjkx.200800165 |
| FENG X, HU Z Y, LIU C H. Survey of research progress on cross-modal retrieval[J]. Computer Science, 2021, 48(8): 13-23. 10.11896/jsjkx.200800165 | |
| 4 | WANG Y X, CHEN Z D, LUO X, et al. Fast cross-modal hashing with global and local similarity embedding[J]. IEEE Transactions on Cybernetics, 2022, 52(10):10064-10077. 10.1109/tcyb.2021.3059886 |
| 5 | 梁美玉,王笑笑,杜军平. 基于多模态图和对抗哈希注意力网络的跨媒体细粒度表示学习[J]. 模式识别与人工智能, 2022, 35(3):195-206. 10.16451/j.cnki.issn1003-6059.202203001 |
| LIANG M Y, WANG X X, DU J P. Cross-media fine-grained representation learning based on multi-modal graph and adversarial hash attention network[J]. Pattern Recognition and Artificial Intelligence, 2022, 35(3):195-206. 10.16451/j.cnki.issn1003-6059.202203001 | |
| 6 | IRIE G, ARAI H, TANIGUCHI Y. Alternating co-quantization for cross-modal hashing[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1886-1894. 10.1109/iccv.2015.219 |
| 7 | ZHANG D Q, LI W J. Large-scale supervised multimodal hashing with semantic correlation maximization[C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2014: 2177-2183. 10.1609/aaai.v28i1.8995 |
| 8 | 刘芳名,张鸿. 基于多级语义的判别式跨模态哈希检索算法[J]. 计算机应用, 2021, 41(8): 2187-2192. 10.11772/j.issn.1001-9081.2020101607 |
| LIU F M, ZHANG H. Cross-modal retrieval algorithm based on multi-level semantic discriminative guided hashing[J]. Journal of Computer Applications, 2021, 41(8): 2187-2192. 10.11772/j.issn.1001-9081.2020101607 | |
| 9 | YU J, WU X J, KITTLER J. Discriminative supervised hashing for cross-modal similarity search[J]. Image and Vision Computing, 2019, 89: 50-56. 10.1016/j.imavis.2019.06.004 |
| 10 | LIU X, HU Z K, LING H B, et al. MTFH: a matrix tri-factorization hashing framework for efficient cross-modal retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(3): 964-981. 10.1109/TPAMI.2019.2940446 |
| 11 | 张成,万源,强浩鹏. 基于知识蒸馏的深度无监督离散跨模态哈希[J]. 计算机应用, 2021, 41(9): 2523-2531. 10.11772/j.issn.1001-9081.2020111785 |
| ZHANG C, WAN Y, QIANG H P. Deep unsupervised discrete cross-modal hashing based on knowledge distillation[J]. Journal of Computer Applications, 2021, 41(9): 2523-2531. 10.11772/j.issn.1001-9081.2020111785 | |
| 12 | LIU H, JI R R, WU Y J, et al. Cross-modality binary code learning via fusion similarity hashing[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6345-6353. 10.1109/cvpr.2017.672 |
| 13 | ZHOU J L, DING G G, GUO Y C. Latent semantic sparse hashing for cross-modal similarity search[C]// Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2014: 415-424. 10.1145/2600428.2609610 |
| 14 | HU H T, XIE L X, HONG R C, et al. Creating something from nothing: unsupervised knowledge distillation for cross-modal hashing[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3120-3129. 10.1109/cvpr42600.2020.00319 |
| 15 | GUO J, ZHU W W. Collective affinity learning for partial cross-modal hashing[J]. IEEE Transactions on Image Processing, 2020, 29: 1344-1355. 10.1109/tip.2019.2941858 |
| 16 | MANDAL D, CHAUDHURY K N, BISWAS S. Generalized semantic preserving hashing for cross-modal retrieval[J]. IEEE Transactions on Image Processing, 2019, 28(1): 102-112. 10.1109/tip.2018.2863040 |
| 17 | LIN Z J, DING G G, HU M Q, et al. Semantics-preserving hashing for cross-view retrieval[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3864-3872. 10.1109/cvpr.2015.7299011 |
| 18 | TANG J, WANG K, SHAO L. Supervised matrix factorization hashing for cross-modal retrieval[J]. IEEE Transactions on Image Processing, 2016, 25(7): 3157-3166. 10.1109/tip.2016.2564638 |
| 19 | LIU X, CHEUNG Y M, HU Z K, et al. Adversarial tri-fusion hashing network for imbalanced cross-modal retrieval[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2021, 5(4): 607-619. 10.1109/tetci.2020.3007143 |
| 20 | XU X, SHEN F M, YANG Y, et al. Learning discriminative binary codes for large-scale cross-modal retrieval[J]. IEEE Transactions on Image Processing, 2017, 26(5): 2494-2507. 10.1109/tip.2017.2676345 |
| 21 | DING G G, GUO Y C, ZHOU J L. Collective matrix factorization hashing for multimodal data[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 2083-2090. 10.1109/cvpr.2014.267 |
| 22 | LIU X B, NIE X S, ZHOU Q, et al. Model optimization boosting framework for linear model hash learning[J]. IEEE Transactions on Image Processing, 2020, 29: 4254-4268. 10.1109/tip.2020.2970577 |
| 23 | CAO Y, QI H, ZHOU W R, et al. Binary hashing for approximate nearest neighbor search on big data: a survey[J]. IEEE Access, 2018, 6: 2039-2054. 10.1109/access.2017.2781360 |
| 24 | LIN M B, JI R R, LIU H, et al. Supervised online hashing via Hadamard codebook learning[C]// Proceedings of the 26th ACM International Conference on Multimedia. New York: ACM, 2018: 1635-1643. 10.1145/3240508.3240519 |
| 25 | YUAN L, WANG T, ZHANG X P, et al. Central similarity quantization for efficient image and video retrieval[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3080-3089. 10.1109/cvpr42600.2020.00315 |
| 26 | BIAN X M, LAN R S, WANG X Q, et al. Discriminative codebook hashing for supervised video retrieval[J]. Computational Intelligence and Neuroscience, 2021, 2021: No.5845094. 10.1155/2021/5845094 |
| 27 | CHEN C, WANG X Q, CHEN X, et al. Discriminative similarity-balanced online hashing for supervised image retrieval[J]. Scientific Programming, 2022, 2022: No.2809222. 10.1155/2022/2809222 |
| 28 | LI C X, CHEN Z D, ZHANG P F, et al. SCRATCH: a scalable discrete matrix factorization hashing for cross-modal retrieval[C]// Proceedings of the 26th ACM International Conference on Multimedia. New York: ACM, 2018: 1-9. 10.1145/3240508.3240547 |
| 29 | WANG D, WANG Q, HE L H, et al. Joint and individual matrix factorization hashing for large-scale cross-modal retrieval[J]. Pattern Recognition, 2020, 107: No.107479. 10.1016/j.patcog.2020.107479 |
| 30 | DATAR M, IMMORLICA N, INDYK P, et al. Locality-sensitive hashing scheme based on p-stable distributions[C]// Proceedings of the 12th Annual Symposium on Computational Geometry. New York: ACM, 2004: 253-262. 10.1145/997817.997857 |
| 31 | ZHANG D Q, LI W J. Large-scale supervised multimodal hashing with semantic correlation maximization[C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2014: 2177-2183. 10.1609/aaai.v28i1.8995 |
| 32 | SHEN H T, LIU L C, YANG Y, et al. Exploiting subspace relation in semantic labels for cross-modal hashing[J]. IEEE Transactions on Knowledge and Data Engineering, 2021, 33(10): 3351-3365. 10.1109/tkde.2020.2970050 |
| [1] | Xiaoyu WANG, Zhanqing WANG, Wei XIONG. Deep asymmetric discrete cross-modal hashing method [J]. Journal of Computer Applications, 2022, 42(8): 2461-2470. |
| [2] | Yongchun BAO, Jianchen ZHANG, Shouxin DU, Junjun ZHANG. Multi-label classification algorithm based on non-negative matrix factorization and sparse representation [J]. Journal of Computer Applications, 2022, 42(5): 1375-1382. |
| [3] | Yinying ZHOU, Mengyi ZHANG, Dunhui YU, Ming ZHU. Social recommendation combining trust implicit similarity and score similarity [J]. Journal of Computer Applications, 2022, 42(12): 3671-3678. |
| [4] | Xinghua LIU, Guitao CAO, Qiubin LIN, Wenming CAO. Adaptive hybrid attention hashing for deep cross-modal retrieval [J]. Journal of Computer Applications, 2022, 42(12): 3663-3670. |
| [5] | Changhong LIU, Sheng ZENG, Bin ZHANG, Yong CHEN. Cross-modal tensor fusion network based on semantic relation graph for image-text retrieval [J]. Journal of Computer Applications, 2022, 42(10): 3018-3024. |
| [6] | LIU Fangming, ZHANG Hong. Cross-modal retrieval algorithm based on multi-level semantic discriminative guided hashing [J]. Journal of Computer Applications, 2021, 41(8): 2187-2192. |
| [7] | WANG Jinkai, JIA Xu. Vein recognition algorithm based on Siamese nonnegative matrix factorization with transferability [J]. Journal of Computer Applications, 2021, 41(3): 898-903. |
| [8] | Xian CHEN, Liying HU, Xiaowei LIN, Lifei CHEN. Directed graph clustering algorithm based on kernel nonnegative matrix factorization [J]. Journal of Computer Applications, 2021, 41(12): 3447-3454. |
| [9] | Han DU, Xianzhong LONG, Yun LI. Graph learning regularized discriminative non-negative matrix factorization based face recognition [J]. Journal of Computer Applications, 2021, 41(12): 3455-3461. |
| [10] | Hua LI, Guifu LU, Qinru YU. Manifold regularized nonnegative matrix factorization based on clean data [J]. Journal of Computer Applications, 2021, 41(12): 3492-3498. |
| [11] | Jinwei LUO, Dugang LIU, Weike PAN, Zhong MING. Unbiased recommendation model based on improved propensity score estimation [J]. Journal of Computer Applications, 2021, 41(12): 3508-3514. |
| [12] | WEN Wen, LIU Fang, CAI Ruichu, HAO Zhifeng. Dynamic recommendation algorithm for group-users' temporal behaviors [J]. Journal of Computer Applications, 2021, 41(1): 60-66. |
| [13] | LI Mingwei, JIANG Qingyuan, XIE Yinpeng, HE Jindong, WU Dan. Hash learning based malicious SQL detection [J]. Journal of Computer Applications, 2021, 41(1): 121-126. |
| [14] | TIAN Baojun, LIU Shuang, FANG Jiandong. Hybrid recommendation algorithm by fusion of topic information and convolution neural network [J]. Journal of Computer Applications, 2020, 40(7): 1901-1907. |
| [15] | WANG Jinkai, JIA Xu. Vehicle face recognition algorithm based on NMF with weighted and orthogonal constraints [J]. Journal of Computer Applications, 2020, 40(4): 1050-1055. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||