


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (5): 1625-1635.DOI: 10.11772/j.issn.1001-9081.2022040541
• Frontier and comprehensive applications • Previous Articles Next Articles
Xianlan WANG1, Jinkun ZHOU1, Nan MU2, Chen WANG3( )
)
Received:2022-04-18
Revised:2022-07-04
Accepted:2022-07-05
Online:2022-08-12
Published:2023-05-10
Contact:
Chen WANG
About author:WANG Xianlan, born in 1969, senior engineer. Her research interests include artificial intelligence, data communication.Supported by:通讯作者:
王晨
作者简介:王先兰(1969—),女,湖北荆州人,高级工程师,主要研究方向:人工智能、数据通信基金资助:CLC Number:
Xianlan WANG, Jinkun ZHOU, Nan MU, Chen WANG. Cross-view geo-localization method based on multi-task joint learning[J]. Journal of Computer Applications, 2023, 43(5): 1625-1635.
王先兰, 周金坤, 穆楠, 王晨. 基于多任务联合学习的跨视角地理定位方法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1625-1635.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022040541
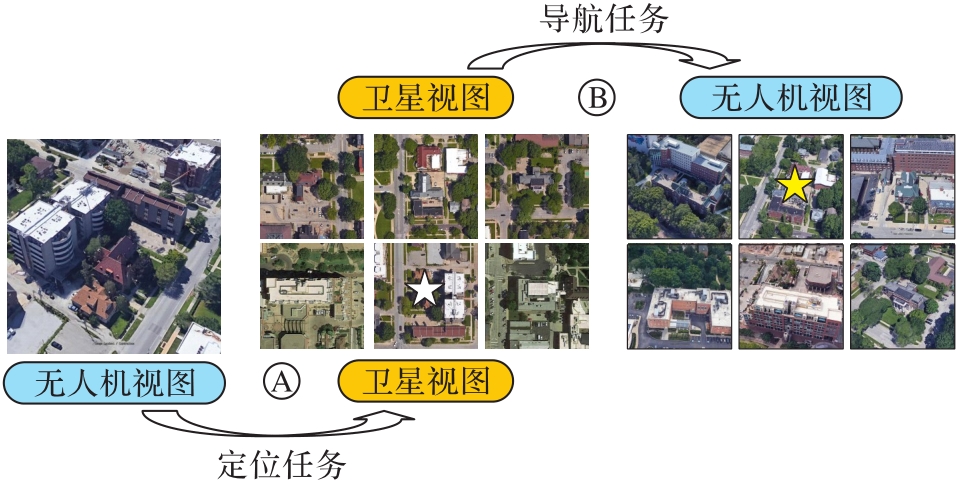
Fig. 1 Schematic diagram of UAV image localization and navigation tasks
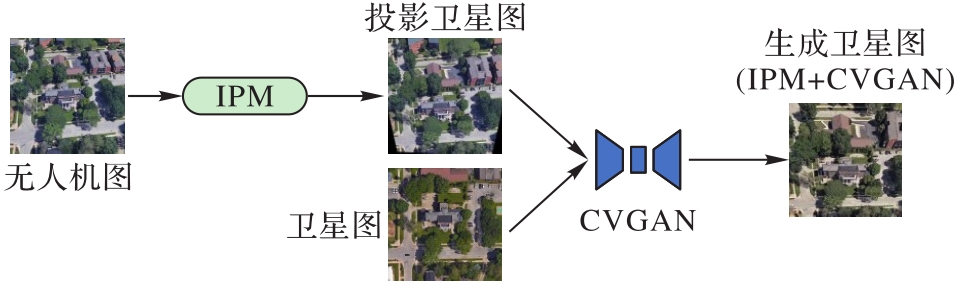
Fig. 2 Proactive image generation model based on view transformation
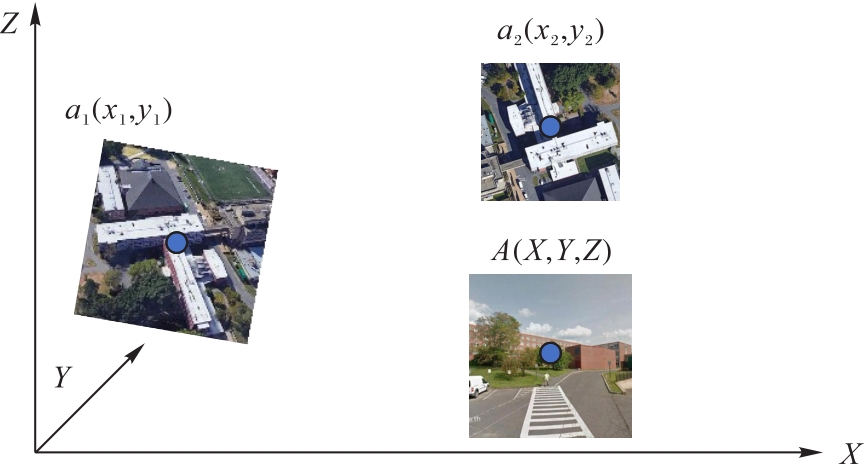
Fig. 3 Schematic diagram of IPM of UAV localization scene

Fig. 4 Effect diagram of coordinate transformation based on IPM

Fig. 5 Schematic diagram of generator architecture
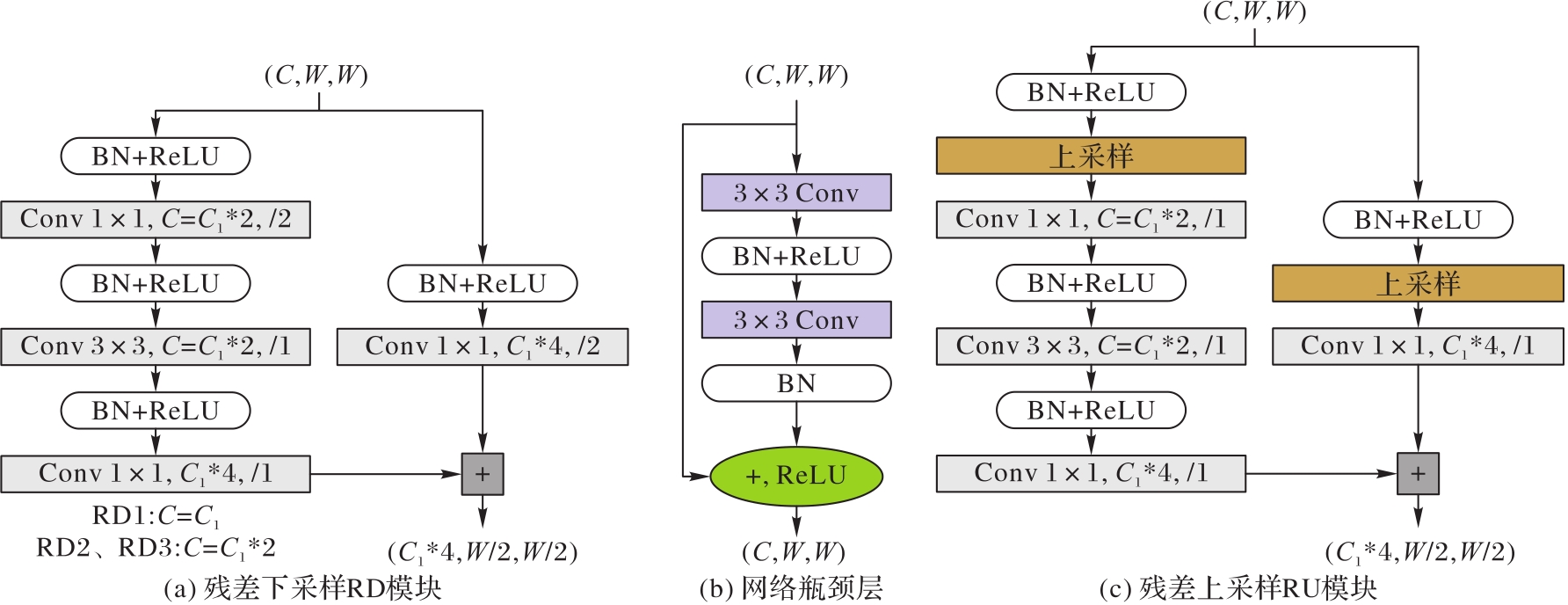
Fig.6 Schematic diagram of generator details
| 参数名称 | 输出特征尺寸 |
|---|---|
| 3, 256, 256 | |
| 1×1 Conv | 32, 256, 256 |
| (enc1) 残差下采样模块RD1 | 128, 128, 128 |
| (enc2) 残差下采样模块RD2 | 256, 64, 64 |
| (enc3) 残差下采样模块RD3 | 512, 32, 32 |
| 网络瓶颈层×6 | 512, 32, 32 |
| +嵌合 (enc3)残差上采样模块RU1 | 256, 64, 64 |
| +嵌合 (enc2)自注意力模块 | 512, 64, 64 |
| 残差上采样模块RU2 | 128 128, 128 |
| +嵌合 (enc1)残差上采样模块RU3 | 32, 256, 256 |
| 3×3 Conv + Tanh | 3, 256, 256 |
Tab. 1 Network structure parameters of generator
| 参数名称 | 输出特征尺寸 |
|---|---|
| 3, 256, 256 | |
| 1×1 Conv | 32, 256, 256 |
| (enc1) 残差下采样模块RD1 | 128, 128, 128 |
| (enc2) 残差下采样模块RD2 | 256, 64, 64 |
| (enc3) 残差下采样模块RD3 | 512, 32, 32 |
| 网络瓶颈层×6 | 512, 32, 32 |
| +嵌合 (enc3)残差上采样模块RU1 | 256, 64, 64 |
| +嵌合 (enc2)自注意力模块 | 512, 64, 64 |
| 残差上采样模块RU2 | 128 128, 128 |
| +嵌合 (enc1)残差上采样模块RU3 | 32, 256, 256 |
| 3×3 Conv + Tanh | 3, 256, 256 |
| 参数名称 | 输出特征尺寸 |
|---|---|
| 3, 256, 256 | |
| 4×4 Conv + LeakyReLU(0.2) | 64, 128, 128 |
| 4×4 Conv + LeakyReLU(0.2) | 128, 64, 64 |
| 非局部自注意力模块 | 128, 64, 64 |
| 4×4 Conv + LeakyReLU(0.2) | 256, 32, 32 |
| 4×4 Conv + LeakyReLU(0.2) | 512, 32, 32 |
| 4×4 Conv | 1, 32, 32 |
Tab. 2 Network structure parameters of discriminator
| 参数名称 | 输出特征尺寸 |
|---|---|
| 3, 256, 256 | |
| 4×4 Conv + LeakyReLU(0.2) | 64, 128, 128 |
| 4×4 Conv + LeakyReLU(0.2) | 128, 64, 64 |
| 非局部自注意力模块 | 128, 64, 64 |
| 4×4 Conv + LeakyReLU(0.2) | 256, 32, 32 |
| 4×4 Conv + LeakyReLU(0.2) | 512, 32, 32 |
| 4×4 Conv | 1, 32, 32 |

Fig. 7 Schematic diagram of MJLM architecture

Fig. 8 Samples of images from University-1652 dataset
| 方法 | 骨干网络 | 无人机→卫星 | 卫星→无人机 | ||
|---|---|---|---|---|---|
| R@1 | AP | R@1 | AP | ||
| ORB[ | — | 11.31 | 19.36 | 28.46 | 30.12 |
| SIFT[ | — | 21.47 | 29.47 | 41.57 | 35.43 |
| SURF[ | — | 19.69 | 36.29 | 45.26 | 34.13 |
| 加权软边界三元组损失[ | VGG16 | 53.21 | 58.03 | 65.62 | 54.47 |
| 实例损失[ | ResNet-50 | 58.23 | 62.91 | 74.47 | 59.45 |
| LCM[ | ResNet-50 | 66.65 | 70.82 | 79.89 | 65.38 |
| SFPN[ | ResNet-50 | 70.83 | 77.36 | 80.26 | 71.58 |
| LPN[ | ResNet-50 | 75.93 | 79.14 | 86.45 | 74.79 |
| PCL[ | ResNet-50 | 83.27 | 87.32 | 91.78 | 82.18 |
| MMNet[ | ResNet-50 | 83.97 | 86.96 | 90.15 | 84.69 |
| FSRA[ | Vit-S | 85.50 | 87.53 | 89.73 | 84.94 |
| MSBA[ | ResNet-50 | 86.61 | 88.55 | 92.15 | 84.45 |
| IPM+CVGAN+LPN | ResNet-50 | 81.58 | 85.45 | — | — |
| MJLM | ResNet-50 | 87.54 | 89.22 | — | — |
Tab. 3 Performance comparison between MJLM and state-of-the-art methods on University-1652 dataset
| 方法 | 骨干网络 | 无人机→卫星 | 卫星→无人机 | ||
|---|---|---|---|---|---|
| R@1 | AP | R@1 | AP | ||
| ORB[ | — | 11.31 | 19.36 | 28.46 | 30.12 |
| SIFT[ | — | 21.47 | 29.47 | 41.57 | 35.43 |
| SURF[ | — | 19.69 | 36.29 | 45.26 | 34.13 |
| 加权软边界三元组损失[ | VGG16 | 53.21 | 58.03 | 65.62 | 54.47 |
| 实例损失[ | ResNet-50 | 58.23 | 62.91 | 74.47 | 59.45 |
| LCM[ | ResNet-50 | 66.65 | 70.82 | 79.89 | 65.38 |
| SFPN[ | ResNet-50 | 70.83 | 77.36 | 80.26 | 71.58 |
| LPN[ | ResNet-50 | 75.93 | 79.14 | 86.45 | 74.79 |
| PCL[ | ResNet-50 | 83.27 | 87.32 | 91.78 | 82.18 |
| MMNet[ | ResNet-50 | 83.97 | 86.96 | 90.15 | 84.69 |
| FSRA[ | Vit-S | 85.50 | 87.53 | 89.73 | 84.94 |
| MSBA[ | ResNet-50 | 86.61 | 88.55 | 92.15 | 84.45 |
| IPM+CVGAN+LPN | ResNet-50 | 81.58 | 85.45 | — | — |
| MJLM | ResNet-50 | 87.54 | 89.22 | — | — |

Fig. 9 Result graphs of UAV localization tasks
| 模型 | RMSE(↓) | SSIM(↑) | PSNR(↑) | SD(↑) |
|---|---|---|---|---|
| Ips vs Is (i.) | 49.154 | 0.459 | 19.546 | 16.421 |
| w/o R (ii.) | 39.638 | 0.799 | 30.232 | 31.678 |
| w / LPN (iii.) | 39.304 | 0.816 | 30.644 | 31.824 |
| w / MMNet (iv.) | 39.289 | 0.821 | 30.651 | 31.815 |
Tab. 4 Ablation study results of proactive image generation model on University-1652 dataset
| 模型 | RMSE(↓) | SSIM(↑) | PSNR(↑) | SD(↑) |
|---|---|---|---|---|
| Ips vs Is (i.) | 49.154 | 0.459 | 19.546 | 16.421 |
| w/o R (ii.) | 39.638 | 0.799 | 30.232 | 31.678 |
| w / LPN (iii.) | 39.304 | 0.816 | 30.644 | 31.824 |
| w / MMNet (iv.) | 39.289 | 0.821 | 30.651 | 31.815 |
| 模型 | 无人机→卫星 | |||
|---|---|---|---|---|
| R@1 | R@5 | R@10 | AP | |
| MMNet | 83.97 | 88.84 | 93.29 | 86.96 |
| w/o IPM(i.) | 85.73. | 90.63 | 95.10 | 87.85 |
| w/o G&D(ii.) | 85.42 | 90.85 | 95.77 | 87.33 |
| w/o | 86.95 | 91.71 | 96.46 | 88.81 |
| w/ | 86.53 | 91.18 | 96.01 | 88.74 |
| MJLM | 87.54 | 92.33 | 96.95 | 89.22 |
Tab. 5 Ablation study results of posterior image retrieval model on University-1652 dataset
| 模型 | 无人机→卫星 | |||
|---|---|---|---|---|
| R@1 | R@5 | R@10 | AP | |
| MMNet | 83.97 | 88.84 | 93.29 | 86.96 |
| w/o IPM(i.) | 85.73. | 90.63 | 95.10 | 87.85 |
| w/o G&D(ii.) | 85.42 | 90.85 | 95.77 | 87.33 |
| w/o | 86.95 | 91.71 | 96.46 | 88.81 |
| w/ | 86.53 | 91.18 | 96.01 | 88.74 |
| MJLM | 87.54 | 92.33 | 96.95 | 89.22 |
| 距离 | 无人机→卫星 | |
|---|---|---|
| R@1 | AP | |
| 全部 | 87.54 | 89.22 |
| 短 | 87.75 | 89.59 |
| 中 | 88.99 | 91.84 |
| 长 | 85.97 | 87.87 |
Tab. 6 Influence of shooting distance on localization performance on University-1652 dataset
| 距离 | 无人机→卫星 | |
|---|---|---|
| R@1 | AP | |
| 全部 | 87.54 | 89.22 |
| 短 | 87.75 | 89.59 |
| 中 | 88.99 | 91.84 |
| 长 | 85.97 | 87.87 |
| 偏移像素 | 无人机→卫星 | |
|---|---|---|
| R@1 | AP | |
| 0 | 87.54 | 89.22 |
| 10 | 87.19 | 88.93 |
| 20 | 85.70 | 86.75 |
| 30 | 84.57 | 85.11 |
| 40 | 81.21 | 81.00 |
| 50 | 76.92 | 77.44 |
Tab. 7 Verification results of offset-invariance on University-1652 dataset
| 偏移像素 | 无人机→卫星 | |
|---|---|---|
| R@1 | AP | |
| 0 | 87.54 | 89.22 |
| 10 | 87.19 | 88.93 |
| 20 | 85.70 | 86.75 |
| 30 | 84.57 | 85.11 |
| 40 | 81.21 | 81.00 |
| 50 | 76.92 | 77.44 |
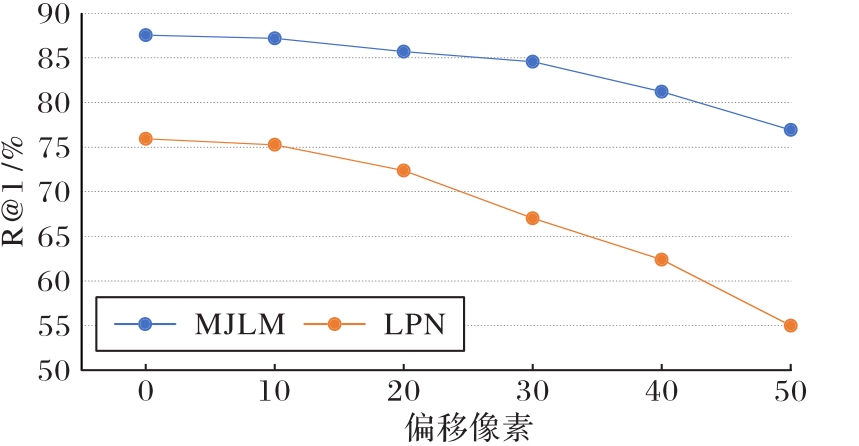
Fig. 10 Comparison map of offset-invariance ablation experiment
| 旋转角度/(°) | 无人机→卫星 | ||
|---|---|---|---|
| Query集 | Gallery集 | R@1/% | AP/% |
| 0 | 0 | 87.54 | 89.22 |
| 45 | 0 | 85.97 | 85.13 |
| 90 | 0 | 81.38 | 82.94 |
| 135 | 0 | 84.19 | 84.61 |
| 180 | 0 | 86.15 | 88.49 |
| 32 | 75 | 85.81 | 86.26 |
| 216 | 87 | 83.44 | 83.17 |
Tab. 8 Verification results of rotation-invariance on University-1652 dataset
| 旋转角度/(°) | 无人机→卫星 | ||
|---|---|---|---|
| Query集 | Gallery集 | R@1/% | AP/% |
| 0 | 0 | 87.54 | 89.22 |
| 45 | 0 | 85.97 | 85.13 |
| 90 | 0 | 81.38 | 82.94 |
| 135 | 0 | 84.19 | 84.61 |
| 180 | 0 | 86.15 | 88.49 |
| 32 | 75 | 85.81 | 86.26 |
| 216 | 87 | 83.44 | 83.17 |
| 1 | SHI Y J, YU X, CAMPBELL D, et al. Where am I looking at? Joint location and orientation estimation by cross-view matching[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4063-4071. 10.1109/cvpr42600.2020.00412 |
| 2 | SHI Y J, LIU L, YU X, et al. Spatial-aware feature aggregation for image based cross-view geo-localization[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems [2022-03-12].. 10.1609/aaai.v34i07.6875 |
| 3 | RODRIGUES R, TANI M. Are these from the same place? Seeing the unseen in cross-view image geo-localization[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 3752-3760. 10.1109/wacv48630.2021.00380 |
| 4 | ZHU S J, YANG T J N, CHEN C. Revisiting street-to-aerial view image geo-localization and orientation estimation[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 756-765. 10.1109/wacv48630.2021.00080 |
| 5 | YU Q, WANG C F, CETINER B, et al. Building information modeling and classification by visual learning at a city scale[EB/OL]. (2020-07-21) [2022-02-01].. |
| 6 | LONG Y, GONG Y P, XIAO Z F, et al. Accurate object localization in remote sensing images based on convolutional neural networks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(5): 2486-2498. 10.1109/tgrs.2016.2645610 |
| 7 | ZHAI M H, BESSINGER Z, WORKMAN S, et al. Predicting ground-level scene layout from aerial imagery[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4132-4140. 10.1109/cvpr.2017.440 |
| 8 | TIAN Y C, CHEN C, SHAH M. Cross-view image matching for geo-localization in urban environments[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1998-2006. 10.1109/cvpr.2017.216 |
| 9 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10) [2022-01-21].. |
| 10 | HU S X, FENG M D, NGUYEN R M H, et al. CVM-Net: cross-view matching network for image-based ground-to-aerial geo-localization[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7258-7267. 10.1109/cvpr.2018.00758 |
| 11 | REGMI K, SHAH M. Bridging the domain gap for ground-to-aerial image matching[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision . Piscataway: IEEE, 2019: 470-479. 10.1109/iccv.2019.00056 |
| 12 | ZHU S J, YANG T J N, CHEN C. VIGOR: cross-view image geo-localization beyond one-to-one retrieval[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5316-5325. 10.1109/cvpr46437.2021.00364 |
| 13 | TOKER A, ZHOU Q J, MAXIMOV M, et al. Coming down to earth: satellite-to-street view synthesis for geo-localization[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 6484-6493. 10.1109/cvpr46437.2021.00642 |
| 14 | YAN Y N, DENG L, LIU X L, et al. Application of UAV-based multi-angle hyperspectral remote sensing in fine vegetation classification[J]. Remote Sensing, 2019, 11(23): No.2753. 10.3390/rs11232753 |
| 15 | 赵爽,黄怀玉,胡一鸣,等. 基于深度学习的无人机航拍车辆检测[J].计算机应用, 2019, 39(S2):91-96. |
| ZHAO S, HUANG H Y, HU Y M, et al. Vehicle detection in satellite imagery based on deep learning[J]. Journal of Computer Applications, 2019, 39(S2): 91-96. | |
| 16 | LIU W, YANG M Y, XIE M, et al. Accurate building extraction from fused DSM and UAV images using a chain fully convolutional neural network[J]. Remote Sensing, 2019, 11(24): No.2912. 10.3390/rs11242912 |
| 17 | ZHENG Z D, WEI Y C, YANG Y. University-1652: a multi-view multi-source benchmark for drone-based geo-localization[C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 1395-1403. 10.1145/3394171.3413896 |
| 18 | WANG T Y, ZHENG Z D, YAN C G, et al. Each part matters: local patterns facilitate cross-view geo-localization[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(2): 867-879. 10.1109/tcsvt.2021.3061265 |
| 19 | HE S J, WANG Y H. Cross-view geo-localization via salient feature partition network[J]. Journal of Physics: Conference Series, 2021, 1914: No.012009. 10.1088/1742-6596/1914/1/012009 |
| 20 | DING L R, ZHOU J, MENG L X, et al. A practical cross-view image matching method between UAV and satellite for UAV-based geo-localization[J]. Remote Sensing, 2020, 13(1): No.47. 10.3390/rs13010047 |
| 21 | ZHUANG J D, DAI M, CHEN X R Y, et al. A faster and more effective cross-view matching method of UAV and satellite images for UAV geolocalization[J]. Remote Sensing, 2021, 13(19): No.3979. 10.3390/rs13193979 |
| 22 | DAI M, HU J H, ZHUANG J D, et al. A Transformer-based feature segmentation and region alignment method for UAV-view geo-localization[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(7): 4376-4389. 10.1109/tcsvt.2021.3135013 |
| 23 | HU S Y, CHANG X J. Multi-view drone-based geo-localization via style and spatial alignment[EB/OL]. (2020-07-09) [2022-03-15]. . |
| 24 | HUI T, CHEN X Q, ZHU R G, et al. Cross-view matching neural network for remote sensing images[C]// Proceedings of the IEEE 6th International Conference on Smart Cloud. Piscataway: IEEE, 2021: 138-143. 10.1109/smartcloud52277.2021.00031 |
| 25 | 周金坤,王先兰,穆楠,等. 基于多视角多监督网络的无人机图像定位方法[J]. 计算机应用, 2022, 42(10):3191-3199. 10.11772/j.issn.1001-9081.2021081518 |
| ZHOU J K, WANG X L, MU N, et al. Unmanned aerial vehicle image localization based on multi-view and multi-supervision network[J]. Journal of Computer Applications, 2022, 42(10):3191-3199. 10.11772/j.issn.1001-9081.2021081518 | |
| 26 | 四川省人工智能研究院(宜宾). 一种基于无人机-卫星的跨视角地理定位方法: 202110916258 .6[P]. 2021-09-07. |
| Sichuan Institute of Artificial Intelligence (Yibin). A cross-view geo-localization method between UAV and satellite: 202110916258 .6[P]. 2021-09-07. | |
| 27 | SHI Y J, YU X, LIU L, et al. Optimal feature transport for cross-view image geo-localization[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 11990-11997. 10.1609/aaai.v34i07.6875 |
| 28 | REGMI K, BORJI A. Cross-view image synthesis using conditional GANs[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3501-3510. 10.1109/cvpr.2018.00369 |
| 29 | LU X H, LI Z Y, CUI Z P, et al. Geometry-aware satellite-to-ground image synthesis for urban areas[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 856-864. 10.1109/cvpr42600.2020.00094 |
| 30 | 张建伟,雷霖. 基于透视投影的垂直视角投影算法研究[J]. 成都大学学报(自然科学版), 2017, 36(1): 47-50. 10.3969/j.issn.1004-5422.2017.01.012 |
| ZHANG J W, LEI L. Top-view projection algorithm research based on perspective projection[J]. Journal of Chengdu University (Natural Science Edition), 2017, 36(1): 47-50. 10.3969/j.issn.1004-5422.2017.01.012 | |
| 31 | ZHANG H, GOODFELLOW I, METAXAS D, et al. Self-attention generative adversarial networks[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 7354-7363. |
| 32 | HE K M, ZHANG X Y, REN S Q, et al. Identity mappings in deep residual networks[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9908. Cham: Springer, 2016: 630-645. |
| 33 | MIYATO T, KATAOKA T, KOYAMA M, et al. Spectral normalization for generative adversarial networks[EB/OL]. (2018-02-16) [2022-03-21].. 10.1007/978-3-030-63416-2_860 |
| 34 | KE Y, SUKTHANKAR R. PCA-SIFT: a more distinctive representation for local image descriptors[C]// Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2004: II-506-II-513. |
| 35 | RUBLEE E, RABAUD V, KONOLIGE K, et al. ORB: an efficient alternative to SIFT or SURF[C]// Proceedings of the 2011 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2011: 2564-2571. 10.1109/iccv.2011.6126544 |
| 36 | BAY H, TUYTELAARS T, van GOOL L. SURF: speeded up robust features[C]// Proceedings of the 2006 European Conference on Computer Vision, LNCS 3951. Berlin: Springer, 2006: 404-417. |
| [1] | Yang LIU, Zhiyang LU, Jun WANG, Jun SHI. Gibbs artifact removal algorithm for magnetic resonance imaging based on self-attention connection UNet [J]. Journal of Computer Applications, 2023, 43(5): 1606-1611. |
| [2] | Qinghai XU, Shifei DING, Tongfeng SUN, Jian ZHANG, Lili GUO. Improved capsule network based on multipath feature [J]. Journal of Computer Applications, 2023, 43(5): 1330-1335. |
| [3] | Liyao FU, Mengxiao YIN, Feng YANG. Transformer based U-shaped medical image segmentation network: a survey [J]. Journal of Computer Applications, 2023, 43(5): 1584-1595. |
| [4] | Haiyu YANG, Wenpu GUO, Kai KANG. Signal modulation recognition method based on convolutional long short-term deep neural network [J]. Journal of Computer Applications, 2023, 43(4): 1318-1322. |
| [5] | Zhoubo XU, Puqing CHEN, Huadong LIU, Xin YANG. Deep graph matching model based on self-attention network [J]. Journal of Computer Applications, 2023, 43(4): 1005-1012. |
| [6] | Mengting GE, Minghua WAN. Feature extraction model based on neighbor supervised locally invariant robust principal component analysis [J]. Journal of Computer Applications, 2023, 43(4): 1013-1020. |
| [7] | Cheng FANG, Bei LI, Ping HAN, Qiong WU. Fine-grained emotion classification of Chinese microblog based on syntactic dependency graph [J]. Journal of Computer Applications, 2023, 43(4): 1056-1061. |
| [8] | Xu ZHANG, Long SHENG, Haifang ZHANG, Feng TIAN, Wei WANG. Pre-hospital emergency text classification model based on label confusion [J]. Journal of Computer Applications, 2023, 43(4): 1050-1055. |
| [9] | Xiaoyu FAN, Suzhen LIN, Yanbo WANG, Feng LIU, Dawei LI. Reconstruction algorithm for highly undersampled magnetic resonance images based on residual graph convolutional neural network [J]. Journal of Computer Applications, 2023, 43(4): 1261-1268. |
| [10] | Rong GAO, Jiawei SHEN, Xiongkai SHAO, Xinyun WU. Instance segmentation algorithm based on Fastformer and self-supervised contrastive learning [J]. Journal of Computer Applications, 2023, 43(4): 1062-1070. |
| [11] | Guangyi DOU, Fanan WEI, Chuangyi QIU, Jianshu CHAO. Tracking appearance features based on attention self-correlation mechanism [J]. Journal of Computer Applications, 2023, 43(4): 1248-1254. |
| [12] | Jianqing GAO, Yanhui TU, Feng MA, Zhonghua FU. Progressive ratio mask-based adaptive noise estimation method [J]. Journal of Computer Applications, 2023, 43(4): 1303-1308. |
| [13] | Jiangfeng ZHANG, Tao YAN, Bin CHEN, Yuhua QIAN, Yantao SONG. Multi-depth-of-field 3D shape reconstruction with global spatio-temporal feature coupling [J]. Journal of Computer Applications, 2023, 43(3): 894-902. |
| [14] | You YANG, Ruhui ZHANG, Pengcheng XU, Kang KANG, Hao ZHAI. Improved U-Net for seal segmentation of Republican archives [J]. Journal of Computer Applications, 2023, 43(3): 943-948. |
| [15] | Xuedong HE, Shibin XUAN, Kuan WANG, Mengnan CHEN. DeepLabV3+ image segmentation algorithm fusing cumulative distribution function and channel attention mechanism [J]. Journal of Computer Applications, 2023, 43(3): 936-942. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||