


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (5): 1620-1624.DOI: 10.11772/j.issn.1001-9081.2022040630
• Frontier and comprehensive applications • Previous Articles
Xiaohui HUANG, Kaiming YANG( ), Jiahao LING
), Jiahao LING
Received:2022-05-06
Revised:2022-07-11
Accepted:2022-07-13
Online:2022-08-05
Published:2023-05-10
Contact:
Kaiming YANG
About author:HUANG Xiaohui, born in 1984, Ph. D., associate professor. His research interests include deep learning, intelligent transportation.Supported by:通讯作者:
杨凯铭
作者简介:黄晓辉(1984—),男,江西上高人,副教授,博士,CCF会员,主要研究方向:深度学习、智慧交通基金资助:CLC Number:
Xiaohui HUANG, Kaiming YANG, Jiahao LING. Order dispatching by multi-agent reinforcement learning based on shared attention[J]. Journal of Computer Applications, 2023, 43(5): 1620-1624.
黄晓辉, 杨凯铭, 凌嘉壕. 基于共享注意力的多智能体强化学习订单派送[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1620-1624.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022040630
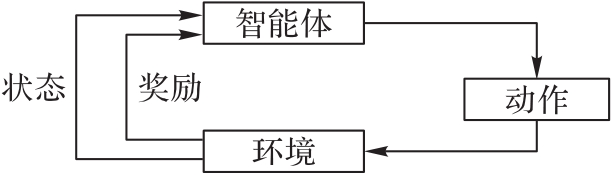
Fig. 1 Flow of deep reinforcement learning

Fig. 2 Overall framework of SARL
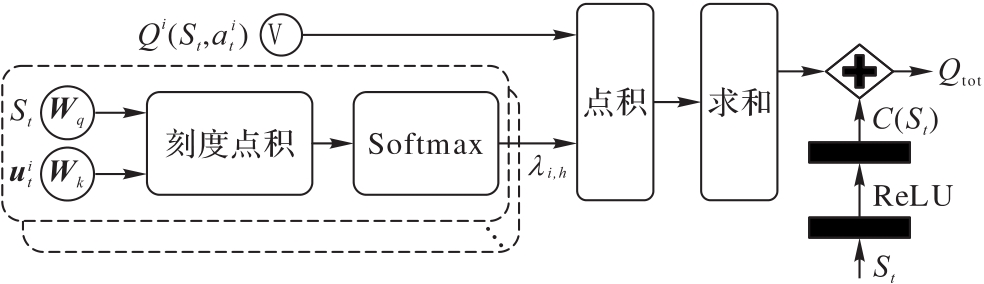
Fig.3 Shared attention module
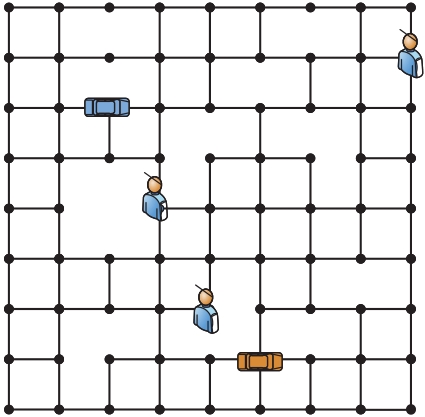
Fig. 4 Grid map
| 地图尺寸 | 车乘组合 | 时长/s | 提升率/% | ||||
|---|---|---|---|---|---|---|---|
| Random | Greedy | DQN | QMIX | SARL | |||
100×100 (训练模型) | P=7, C=2 | 3 386.25 | 3 526.96 | 3 306.88 | 2 981.38 | 7.37 | |
| P=10, C=10 | 2 210.87 | 2 208.55 | 2 102.65 | 1 912.15 | 6.34 | ||
| P=11, C=13 | 2 089.87 | 2 089.63 | 2 046.65 | 1 742.73 | 10.71 | ||
| P=9, C=4 | 2 958.86 | 3 072.81 | 2 763.20 | 2 523.49 | 7.38 | ||
| P=10, C=2 | 4 644.59 | 4 934.91 | 4 847.97 | 4 214.86 | 3.28 | ||
| P=25,C=20 | 2 962.79 | 3 173.54 | 2 853.66 | 2 109.84 | 18.03 | ||
| 10×10 | P=7, C=2 | 337.30 | 348.70 | 323.90 | 295.38 | 6.67 | |
| P=10, C=10 | 215.64 | 209.07 | 206.46 | 179.10 | 13.25 | ||
| P=11, C=13 | 208.77 | 199.75 | 197.53 | 181.11 | 8.22 | ||
| P=9, C=4 | 287.57 | 303.86 | 265.10 | 247.01 | 6.82 | ||
| P=10, C=2 | 448.38 | 474.44 | 454.27 | 392.16 | 6.16 | ||
| P=25, C=20 | 291.62 | 287.84 | 285.62 | 230.93 | 18.42 | ||
| 500×500 | P=7, C=2 | 17 092.40 | 17 251.20 | 16 473.10 | 14 916.60 | 8.34 | |
| P=10, C=10 | 10 860.21 | 10 720.60 | 10 139.36 | 10 021.45 | 0.98 | ||
| P=11, C=13 | 10 428.24 | 10 950.80 | 9 968.44 | 9 098.43 | 7.50 | ||
| P=9, C=4 | 14 715.82 | 15 582.50 | 13 571.88 | 12 182.71 | 10.08 | ||
| P=10, C=2 | 23 303.64 | 24 491.40 | 23 688.50 | 20 910.92 | 4.39 | ||
| P=25, C=20 | 14 820.33 | 16 046.20 | 14 649.64 | 11 902.55 | 6.89 | ||
Tab. 1 Experimental comparison on different size maps
| 地图尺寸 | 车乘组合 | 时长/s | 提升率/% | ||||
|---|---|---|---|---|---|---|---|
| Random | Greedy | DQN | QMIX | SARL | |||
100×100 (训练模型) | P=7, C=2 | 3 386.25 | 3 526.96 | 3 306.88 | 2 981.38 | 7.37 | |
| P=10, C=10 | 2 210.87 | 2 208.55 | 2 102.65 | 1 912.15 | 6.34 | ||
| P=11, C=13 | 2 089.87 | 2 089.63 | 2 046.65 | 1 742.73 | 10.71 | ||
| P=9, C=4 | 2 958.86 | 3 072.81 | 2 763.20 | 2 523.49 | 7.38 | ||
| P=10, C=2 | 4 644.59 | 4 934.91 | 4 847.97 | 4 214.86 | 3.28 | ||
| P=25,C=20 | 2 962.79 | 3 173.54 | 2 853.66 | 2 109.84 | 18.03 | ||
| 10×10 | P=7, C=2 | 337.30 | 348.70 | 323.90 | 295.38 | 6.67 | |
| P=10, C=10 | 215.64 | 209.07 | 206.46 | 179.10 | 13.25 | ||
| P=11, C=13 | 208.77 | 199.75 | 197.53 | 181.11 | 8.22 | ||
| P=9, C=4 | 287.57 | 303.86 | 265.10 | 247.01 | 6.82 | ||
| P=10, C=2 | 448.38 | 474.44 | 454.27 | 392.16 | 6.16 | ||
| P=25, C=20 | 291.62 | 287.84 | 285.62 | 230.93 | 18.42 | ||
| 500×500 | P=7, C=2 | 17 092.40 | 17 251.20 | 16 473.10 | 14 916.60 | 8.34 | |
| P=10, C=10 | 10 860.21 | 10 720.60 | 10 139.36 | 10 021.45 | 0.98 | ||
| P=11, C=13 | 10 428.24 | 10 950.80 | 9 968.44 | 9 098.43 | 7.50 | ||
| P=9, C=4 | 14 715.82 | 15 582.50 | 13 571.88 | 12 182.71 | 10.08 | ||
| P=10, C=2 | 23 303.64 | 24 491.40 | 23 688.50 | 20 910.92 | 4.39 | ||
| P=25, C=20 | 14 820.33 | 16 046.20 | 14 649.64 | 11 902.55 | 6.89 | ||
| 方法 | 10×10网格 (Pmax=10,Cmax=10) | 500×500网格 (Pmax =20, Cmax =20) |
|---|---|---|
| 提升率/% | 6.28 | 1.24 |
| Random | 209.03 | 13 700.14 |
| Greedy | 201.85 | 13 871.07 |
| DQN | 199.43 | 13 462.82 |
| QMIX | ||
| SARL | 183.36 | 12 653.74 |
Tab. 2 Comparison of efficiency with variable vehicle and passenger combinations
| 方法 | 10×10网格 (Pmax=10,Cmax=10) | 500×500网格 (Pmax =20, Cmax =20) |
|---|---|---|
| 提升率/% | 6.28 | 1.24 |
| Random | 209.03 | 13 700.14 |
| Greedy | 201.85 | 13 871.07 |
| DQN | 199.43 | 13 462.82 |
| QMIX | ||
| SARL | 183.36 | 12 653.74 |
| 1 | LI Z, LIANG C, HONG Y,et al. How do on-demand ridesharing services affect traffic congestion? The moderating role of urban compactness [EB/OL]. [2022-01-22]. . 10.1111/poms.13530 |
| 2 | 李建斌,杨帆,管梦城,等.共同配送模式下订单车辆匹配决策优化研究[J].管理工程学报,2021,35(6):259-266. |
| LI J B, YANG F, GUAN M C, et al. Research on optimization of order-vehicle matching decision under the joint distribution mode[J]. Journal of Industrial Engineering and Engineering Management, 2021, 35(6): 259-266. | |
| 3 | QIN Z, TANG X, JIAO Y, et al. Ride-hailing order dispatching at DiDi via reinforcement learning[J]. INFORMS Journal on Applied Analytics, 2020, 50(5): 272-286. 10.1287/inte.2020.1047 |
| 4 | GAŠPEROV B, KOSTANJČAR Z. Deep reinforcement learning for market making under a Hawkes process-based limit order book model[J]. IEEE Control Systems Letters, 2022, 6: 2485-2490. 10.1109/lcsys.2022.3166446 |
| 5 | TANG X, HUANG B, LIU T, et al. Highway decision-making and motion planning for autonomous driving via soft actor-critic[J]. IEEE Transactions on Vehicular Technology, 2022, 71(5): 4706-4717. 10.1109/tvt.2022.3151651 |
| 6 | 王建平,王刚,毛晓彬,等.基于深度强化学习的二连杆机械臂运动控制方法[J].计算机应用,2021,41(6):1799-1804. 10.11772/j.issn.1001-9081.2020091410 |
| WANG J P, WANG G, MAO X B, et al. Motion control method of two-link manipulator based on deep reinforcement learning[J]. Journal of Computer Applications, 2021, 41(6): 1799-1804. 10.11772/j.issn.1001-9081.2020091410 | |
| 7 | 陈浩杰,范江亭,刘勇.深度强化学习解决动态旅行商问题[J].计算机应用,2022,42(4):1194-1200. 10.11772/j.issn.1001-9081.2021071253 |
| CHEN H J, FAN J T, LIU Y. Solving dynamic traveling salesman problem by deep reinforcement learning[J]. Journal of Computer Applications, 2022, 42(4): 1194-1200. 10.11772/j.issn.1001-9081.2021071253 | |
| 8 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. 10.1038/nature14236 |
| 9 | RASHID T, SAMVELYAN M, DE WITT C S, et al. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 4295-4304. 10.48550/arXiv.1803.11485 |
| 10 | DE LIMA O, SHAH H, CHU T S, et al. Efficient ridesharing dispatch using multi-agent reinforcement learning[EB/OL]. [2022-03-27].. |
| 11 | PAN L, CAI Q, FANG Z, et al. A deep reinforcement learning framework for rebalancing dockless bike sharing systems[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 1393-1400. 10.1609/aaai.v33i01.33011393 |
| 12 | TANG X, QIN Z, ZHANG F, et al. A deep value-network based approach for multi-driver order dispatching[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2019: 1780-1790. 10.1145/3292500.3330724 |
| 13 | WANG Z, QIN Z, TANG X, et al. Deep reinforcement learning with knowledge transfer for online rides order dispatching[C]// Proceedings of the 2018 IEEE International Conference on Data Mining. Piscataway: IEEE, 2018: 617-626. 10.1109/icdm.2018.00077 |
| 14 | VAN HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2016: 2094-2100. 10.1609/aaai.v30i1.10295 |
| 15 | CHILUKURI S, PESCH D. RECCE: deep reinforcement learning for joint routing and scheduling in time-constrained wireless networks[J]. IEEE Access, 2021, 9: 132053-132063. 10.1109/access.2021.3114967 |
| 16 | SON K, KIM D, KANG W J, et al. QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 5887-5896. 10.48550/arXiv.1905.05408 |
| 17 | CUI H, ZHANG Z. A cooperative multi-agent reinforcement learning method based on coordination degree[J]. IEEE Access, 2021, 9: 123805-123814. 10.1109/access.2021.3110255 |
| 18 | LIU B, LIU Q, STONE P, et al. Coach-player multi-agent reinforcement learning for dynamic team composition[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 6860-6870. 10.48550/arXiv.2105.08692 |
| 19 | LUO M, ZHANG W, SONG T, et al. Rebalancing expanding EV sharing systems with deep reinforcement learning[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020: 1338-1344. 10.24963/ijcai.2020/186 |
| 20 | ZHOU M, JIN J, ZHANG W, et al. Multi-agent reinforcement learning for order-dispatching via order-vehicle distribution matching[C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM, 2019: 2645-2653. 10.1145/3357384.3357799 |
| [1] | Yang LIU, Zhiyang LU, Jun WANG, Jun SHI. Gibbs artifact removal algorithm for magnetic resonance imaging based on self-attention connection UNet [J]. Journal of Computer Applications, 2023, 43(5): 1606-1611. |
| [2] | Tengfei CAO, Yanliang LIU, Xiaoying WANG. Edge computing and service offloading algorithm based on improved deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(5): 1543-1550. |
| [3] | Hui LIU, Linyu ZHANG, Fugang WANG, Rujin HE. Object detection algorithm based on attention mechanism and context information [J]. Journal of Computer Applications, 2023, 43(5): 1557-1564. |
| [4] | Kai ZHANG, Zhengchu QIN, Yue LIU, Xinyi QIN. Multi-learning behavior collaborated knowledge tracing model [J]. Journal of Computer Applications, 2023, 43(5): 1422-1429. |
| [5] | Lifeng SHI, Zhengwei NI. Dialogue state tracking model based on slot correlation information extraction [J]. Journal of Computer Applications, 2023, 43(5): 1430-1437. |
| [6] | Ruilin JIANG, Renchao QIN. Multi-neural network malicious code detection model based on depthwise separable convolution [J]. Journal of Computer Applications, 2023, 43(5): 1527-1533. |
| [7] | Hao SUN, Jian CAO, Haisheng LI, Dianhui MAO. Session-based recommendation model based on enhanced capsule network [J]. Journal of Computer Applications, 2023, 43(4): 1043-1049. |
| [8] | Zhouhua ZHU, Qi QI. Automatic detection and recognition of electric vehicle helmet based on improved YOLOv5s [J]. Journal of Computer Applications, 2023, 43(4): 1291-1296. |
| [9] | Lu CHEN, Daoxi CHEN, Yiming LU, Weizhong LU. Handwritten mathematical expression recognition model based on attention mechanism and encoder-decoder [J]. Journal of Computer Applications, 2023, 43(4): 1297-1302. |
| [10] | Shaochen HAO, Zizuan WEI, Yao MA, Dan YU, Yongle CHEN. Network intrusion detection model based on efficient federated learning algorithm [J]. Journal of Computer Applications, 2023, 43(4): 1169-1175. |
| [11] | Jiazhen ZU, Yongxia ZHOU, Le CHEN. Dual-branch residual low-light image enhancement combined with attention [J]. Journal of Computer Applications, 2023, 43(4): 1240-1247. |
| [12] | Guangyi DOU, Fanan WEI, Chuangyi QIU, Jianshu CHAO. Tracking appearance features based on attention self-correlation mechanism [J]. Journal of Computer Applications, 2023, 43(4): 1248-1254. |
| [13] | Juming HAO, Jingyu YANG, Shumei HAN, Yangping WANG. YOLOv4 highway pavement crack detection method using Ghost module and ECA [J]. Journal of Computer Applications, 2023, 43(4): 1284-1290. |
| [14] | Quan YUAN, Yunpeng XU, Chengliang TANG. Document-level relation extraction method based on path labels [J]. Journal of Computer Applications, 2023, 43(4): 1029-1035. |
| [15] | Xuedong HE, Shibin XUAN, Kuan WANG, Mengnan CHEN. DeepLabV3+ image segmentation algorithm fusing cumulative distribution function and channel attention mechanism [J]. Journal of Computer Applications, 2023, 43(3): 936-942. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||