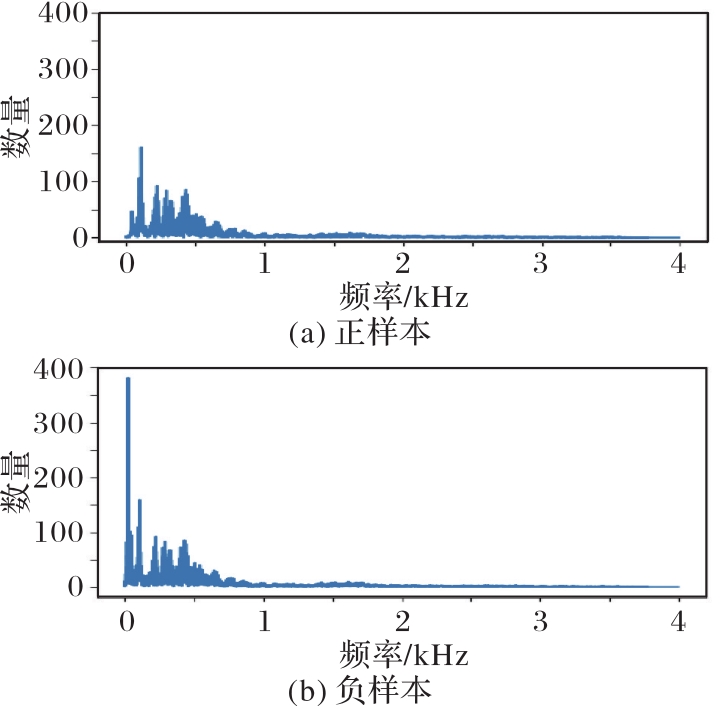
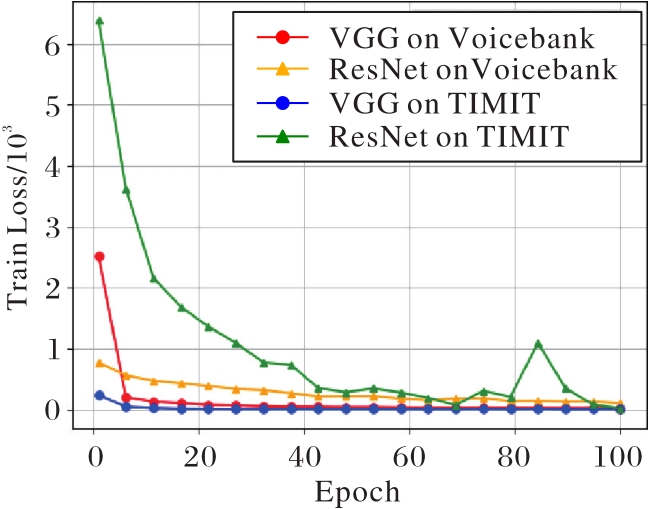
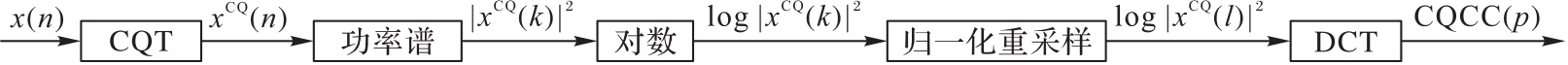Journal of Computer Applications ›› 2022, Vol. 42 ›› Issue (6): 1724-1728.DOI: 10.11772/j.issn.1001-9081.2021061432
• National Open Distributed and Parallel Computing Conference 2021 (DPCS 2021) • Previous Articles
Mingyu DONG1, Diqun YAN1,2( )
)