


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (3): 894-902.DOI: 10.11772/j.issn.1001-9081.2022101589
• Multimedia computing and computer simulation • Previous Articles
Jiangfeng ZHANG1,2, Tao YAN1,2,3,4( ), Bin CHEN4,5, Yuhua QIAN2,3, Yantao SONG1,2,3
), Bin CHEN4,5, Yuhua QIAN2,3, Yantao SONG1,2,3
Received:2022-10-25
Revised:2023-01-12
Accepted:2023-01-16
Online:2023-03-15
Published:2023-03-10
Contact:
Tao YAN
About author:ZHANG Jiangfeng, born in 1998, M. S. candidate. His research interests include deep learning, 3D reconstruction.Supported by:
张江峰1,2, 闫涛1,2,3,4(), 陈斌4,5, 钱宇华2,3, 宋艳涛1,2,3
通讯作者:
闫涛
作者简介:张江峰(1998—),男,山西晋城人,硕士研究生,CCF会员,主要研究方向:深度学习、三维重建基金资助:CLC Number:
Jiangfeng ZHANG, Tao YAN, Bin CHEN, Yuhua QIAN, Yantao SONG. Multi-depth-of-field 3D shape reconstruction with global spatio-temporal feature coupling[J]. Journal of Computer Applications, 2023, 43(3): 894-902.
张江峰, 闫涛, 陈斌, 钱宇华, 宋艳涛. 全局时空特征耦合的多景深三维形貌重建[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 894-902.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022101589
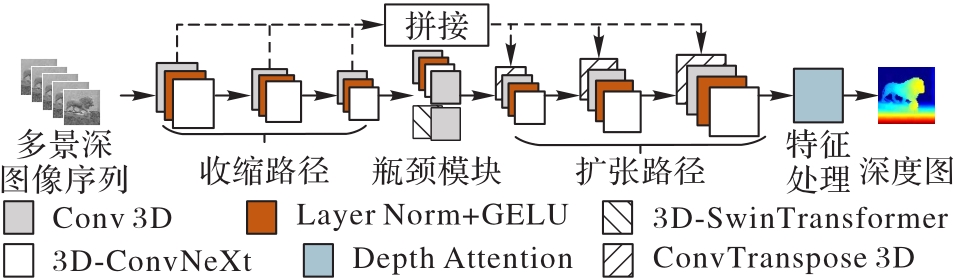
Fig. 1 Overall structure of GSTFC model
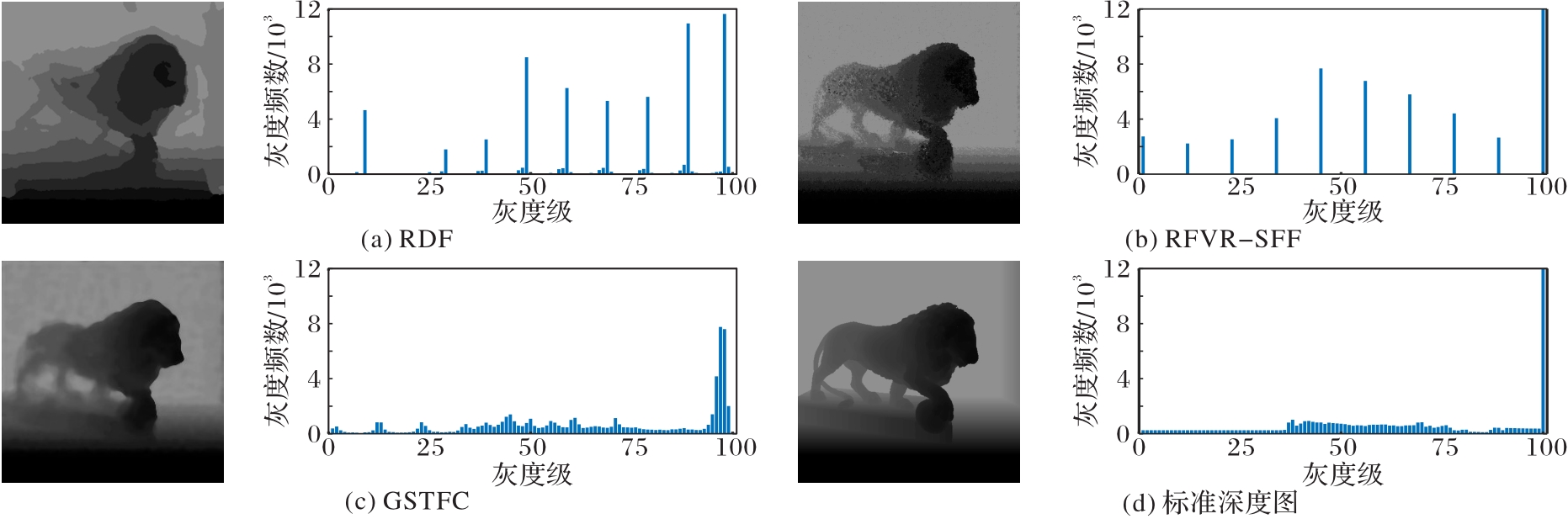
Fig.2 Depth maps predicted by different models and corresponding grayscale histograms
| 模型 | 主干 | 模块 | 特征处理 | MSE | 参数量/106 | 浮点运算量/GFLOPs |
|---|---|---|---|---|---|---|
| U | 3D-U型主干 | — | 卷积层 | 0.004 23 | 29.160 0 | 534.27 |
| U+T | 3D-U型主干 | 3D-SwinTransformer | 卷积层 | 0.003 73 | 35.657 0 | 549.18 |
| U+T+DFV | 3D-U型主干 | 3D-SwinTransformer | DFV | 35.660 0 | 549.18 | |
| X | 3D-ConvNeXt | — | 卷积层 | 0.005 10 | 9.760 0 | 233.17 |
| X+T | 3D-ConvNeXt | 3D-SwinTransformer | 卷积层 | 0.002 21 | 16.251 1 | 248.09 |
| X+T+DFV | 3D-ConvNeXt | 3D-SwinTransformer | DFV | 0.000 98 |
Tab. 1 Comparison analysis of ablation experiments
| 模型 | 主干 | 模块 | 特征处理 | MSE | 参数量/106 | 浮点运算量/GFLOPs |
|---|---|---|---|---|---|---|
| U | 3D-U型主干 | — | 卷积层 | 0.004 23 | 29.160 0 | 534.27 |
| U+T | 3D-U型主干 | 3D-SwinTransformer | 卷积层 | 0.003 73 | 35.657 0 | 549.18 |
| U+T+DFV | 3D-U型主干 | 3D-SwinTransformer | DFV | 35.660 0 | 549.18 | |
| X | 3D-ConvNeXt | — | 卷积层 | 0.005 10 | 9.760 0 | 233.17 |
| X+T | 3D-ConvNeXt | 3D-SwinTransformer | 卷积层 | 0.002 21 | 16.251 1 | 248.09 |
| X+T+DFV | 3D-ConvNeXt | 3D-SwinTransformer | DFV | 0.000 98 |
| 模型 | MSE | RMSE | Sqr.rel | Bumpiness | 参数量/103 |
|---|---|---|---|---|---|
| RDF | 0.111 5 | 0.322 | 0.239 5 | 1.54 | — |
| DDFF | 0.033 4 | 0.167 | 1.74 | 39 806 222 | |
| DefocusNet | 0.021 8 | 0.134 | 0.035 9 | 2.52 | 1 508 047 |
| AiFDepthNet | — | — | 16 533 873 | ||
| FV-Net | 0.018 8 | 0.125 | 0.024 3 | 1.45 | |
| DFV-Net | 0.020 5 | 0.129 | 0.023 9 | — | |
| GSTFC | 0.009 8 | 0.091 | 0.057 5 | 0.51 | 16 269 231 |
Tab. 2 Comparison results of different models on FoD500 dataset
| 模型 | MSE | RMSE | Sqr.rel | Bumpiness | 参数量/103 |
|---|---|---|---|---|---|
| RDF | 0.111 5 | 0.322 | 0.239 5 | 1.54 | — |
| DDFF | 0.033 4 | 0.167 | 1.74 | 39 806 222 | |
| DefocusNet | 0.021 8 | 0.134 | 0.035 9 | 2.52 | 1 508 047 |
| AiFDepthNet | — | — | 16 533 873 | ||
| FV-Net | 0.018 8 | 0.125 | 0.024 3 | 1.45 | |
| DFV-Net | 0.020 5 | 0.129 | 0.023 9 | — | |
| GSTFC | 0.009 8 | 0.091 | 0.057 5 | 0.51 | 16 269 231 |
| 数据集 | 模型 | RMSE | PSNR/dB | SSIM | Correlation |
|---|---|---|---|---|---|
| Base-Line | SF | 0.032 6 | 30.100 6 | 0.947 5 | 0.946 5 |
| TENV | 0.020 8 | 33.889 6 | 0.935 4 | 0.994 4 | |
| DLAP | 0.025 3 | 32.900 6 | 0.910 2 | 0.996 0 | |
| FDC | 0.092 4 | 20.875 7 | 0.649 6 | 0.495 4 | |
| GC | 0.122 0 | 18.653 7 | 0.676 8 | 0.779 6 | |
| RDF | 0.024 7 | 32.847 8 | 0.904 8 | 0.962 4 | |
| RFVR-SFF | 0.008 0 | 42.813 1 | 0.952 3 | 0.996 9 | |
| GSTFC | 0.005 8 | 45.714 2 | 0.967 6 | 0.998 2 | |
4D Light Field | SF | 0.040 7 | 28.630 6 | 0.899 0 | 0.904 2 |
| TENV | 0.042 9 | 28.397 2 | 0.887 5 | 0.882 5 | |
| DLAP | 0.030 9 | 31.297 5 | 0.920 8 | 0.945 6 | |
| FDC | 0.088 8 | 21.203 1 | 0.563 8 | 0.523 9 | |
| GC | 0.112 9 | 19.162 5 | 0.796 0 | 0.697 4 | |
| RDF | 0.055 7 | 25.934 5 | 0.871 3 | 0.816 5 | |
| RFVR-SFF | 0.029 9 | 32.096 7 | 0.895 0 | 0.934 6 | |
| GSTFC | 0.026 2 | 33.686 5 | 0.921 7 | 0.947 6 | |
| POV-Ray | SF | 0.099 0 | 20.165 9 | 0.611 7 | 0.731 4 |
| TENV | 0.099 8 | 20.249 0 | 0.614 7 | 0.704 3 | |
| DLAP | 0.077 1 | 22.361 1 | 0.658 4 | 0.835 9 | |
| FDC | 0.123 4 | 18.228 6 | 0.465 4 | 0.508 7 | |
| GC | 0.140 3 | 17.086 7 | 0.532 1 | 0.546 2 | |
| RDF | 0.112 2 | 19.038 8 | 0.604 4 | 0.666 1 | |
| RFVR-SFF | 0.093 6 | 20.802 0 | 0.500 2 | 0.771 8 | |
| GSTFC | 0.076 6 | 22.402 4 | 0.655 0 | 0.845 1 | |
SLFD and DLFD | SF | 0.047 8 | 26.754 0 | 0.888 8 | 0.904 5 |
| TENV | 0.056 0 | 25.628 3 | 0.857 9 | 0.859 1 | |
| DLAP | 0.036 1 | 29.377 6 | 0.919 2 | 0.944 9 | |
| FDC | 0.101 4 | 20.026 1 | 0.541 3 | 0.553 6 | |
| GC | 0.125 9 | 18.178 3 | 0.776 9 | 0.710 7 | |
| RDF | 0.066 1 | 24.223 2 | 0.869 7 | 0.807 4 | |
| RFVR-SFF | 0.085 5 | 21.720 0 | 0.388 8 | 0.726 4 | |
| GSTFC | 0.038 7 | 28.987 6 | 0.914 5 | 0.927 4 |
Tab. 3 Comparison results of different models on traditional datasets
| 数据集 | 模型 | RMSE | PSNR/dB | SSIM | Correlation |
|---|---|---|---|---|---|
| Base-Line | SF | 0.032 6 | 30.100 6 | 0.947 5 | 0.946 5 |
| TENV | 0.020 8 | 33.889 6 | 0.935 4 | 0.994 4 | |
| DLAP | 0.025 3 | 32.900 6 | 0.910 2 | 0.996 0 | |
| FDC | 0.092 4 | 20.875 7 | 0.649 6 | 0.495 4 | |
| GC | 0.122 0 | 18.653 7 | 0.676 8 | 0.779 6 | |
| RDF | 0.024 7 | 32.847 8 | 0.904 8 | 0.962 4 | |
| RFVR-SFF | 0.008 0 | 42.813 1 | 0.952 3 | 0.996 9 | |
| GSTFC | 0.005 8 | 45.714 2 | 0.967 6 | 0.998 2 | |
4D Light Field | SF | 0.040 7 | 28.630 6 | 0.899 0 | 0.904 2 |
| TENV | 0.042 9 | 28.397 2 | 0.887 5 | 0.882 5 | |
| DLAP | 0.030 9 | 31.297 5 | 0.920 8 | 0.945 6 | |
| FDC | 0.088 8 | 21.203 1 | 0.563 8 | 0.523 9 | |
| GC | 0.112 9 | 19.162 5 | 0.796 0 | 0.697 4 | |
| RDF | 0.055 7 | 25.934 5 | 0.871 3 | 0.816 5 | |
| RFVR-SFF | 0.029 9 | 32.096 7 | 0.895 0 | 0.934 6 | |
| GSTFC | 0.026 2 | 33.686 5 | 0.921 7 | 0.947 6 | |
| POV-Ray | SF | 0.099 0 | 20.165 9 | 0.611 7 | 0.731 4 |
| TENV | 0.099 8 | 20.249 0 | 0.614 7 | 0.704 3 | |
| DLAP | 0.077 1 | 22.361 1 | 0.658 4 | 0.835 9 | |
| FDC | 0.123 4 | 18.228 6 | 0.465 4 | 0.508 7 | |
| GC | 0.140 3 | 17.086 7 | 0.532 1 | 0.546 2 | |
| RDF | 0.112 2 | 19.038 8 | 0.604 4 | 0.666 1 | |
| RFVR-SFF | 0.093 6 | 20.802 0 | 0.500 2 | 0.771 8 | |
| GSTFC | 0.076 6 | 22.402 4 | 0.655 0 | 0.845 1 | |
SLFD and DLFD | SF | 0.047 8 | 26.754 0 | 0.888 8 | 0.904 5 |
| TENV | 0.056 0 | 25.628 3 | 0.857 9 | 0.859 1 | |
| DLAP | 0.036 1 | 29.377 6 | 0.919 2 | 0.944 9 | |
| FDC | 0.101 4 | 20.026 1 | 0.541 3 | 0.553 6 | |
| GC | 0.125 9 | 18.178 3 | 0.776 9 | 0.710 7 | |
| RDF | 0.066 1 | 24.223 2 | 0.869 7 | 0.807 4 | |
| RFVR-SFF | 0.085 5 | 21.720 0 | 0.388 8 | 0.726 4 | |
| GSTFC | 0.038 7 | 28.987 6 | 0.914 5 | 0.927 4 |

Fig. 3 Visualized comparison of reconstruction results of different models
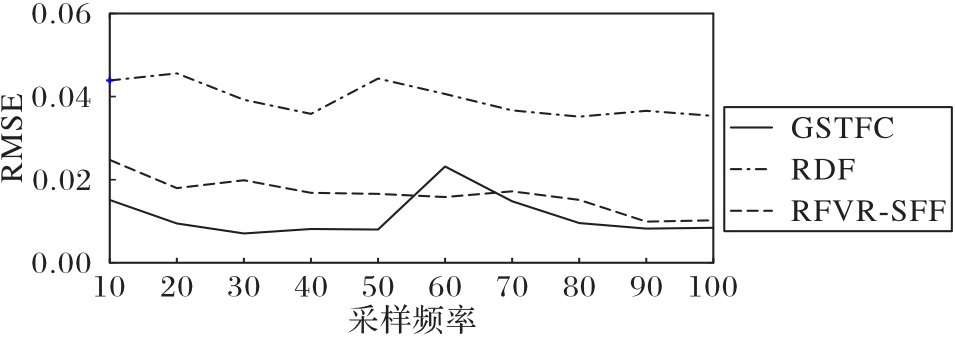
Fig. 4 Comparison of performance of different models at different sampling frequencies
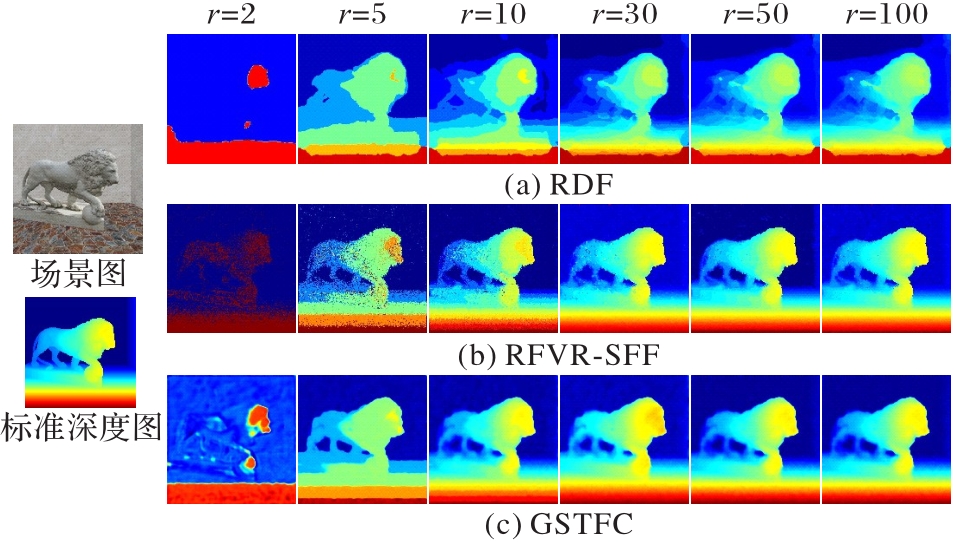
Fig. 5 Comparison experimental results of sparsity
| 1 | HUANG B, WANG W Q, BATES M, et al. Three-dimensional super-resolution imaging by stochastic optical reconstruction microscopy[J]. Science, 2008, 319(5864): 810-813. 10.1126/science.1153529 |
| 2 | 闫涛,钱宇华,李飞江,等. 三维时频变换视角的智能微观三维形貌重建方法[J]. 中国科学:信息科学 (2022-03-27) [2022-05-09].. 10.1360/ssi-2021-0386 |
| YAN T, QIAN Y H, LI F J, et al. Intelligent microscopic 3D shape reconstruction method based on 3D time-frequency transformation[J]. SCIENTIA SINICA Informationis (2022-03-27) [2022-05-09].. 10.1360/ssi-2021-0386 | |
| 3 | 闫涛,陈斌,刘凤娴,等. 基于多景深融合模型的显微三维重建方法[J]. 计算机辅助设计与图形学学报, 2017, 29(9): 1613-1623. 10.3969/j.issn.1003-9775.2017.09.004 |
| YAN T, CHEN B, LIU F X, et al. Multi-focus image fusion model for micro 3D reconstruction[J]. Journal of Computer-Aided Design and Computer Graphics, 2017, 29(9): 1613-1623. 10.3969/j.issn.1003-9775.2017.09.004 | |
| 4 | SCHÖNBERGER J L, FRAHM J M. Structure-from-motion revisited[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4104-4113. 10.1109/cvpr.2016.445 |
| 5 | 武越,苑咏哲,岳铭煜,等. 点云配准中多维度信息融合的特征挖掘方法[J]. 计算机研究与发展, 2022, 59(8): 1732-1741. 10.7544/issn1000-1239.20220042 |
| WU Y, YUAN Y Z, YUE M Y, et al. Feature mining method of multi-dimensional information fusion in point cloud registration[J]. Journal of Computer Research and Development, 2022, 59(8): 1732-1741. 10.7544/issn1000-1239.20220042 | |
| 6 | 吉新新,朴永日,张淼,等. 基于光场焦点堆栈的鲁棒深度估计[J]. 计算机学报, 2022, 45(6): 1226-1240. 10.11897/SP.J.1016.2022.01226 |
| JI X X, PIAO Y R, ZHANG M, et al. Robust depth estimation via light field focal stacks[J]. Chinese Journal of Computers, 2022, 45(6): 1226-1240. 10.11897/SP.J.1016.2022.01226 | |
| 7 | YAN T, WU P, QIAN Y H, et al. Multiscale fusion and aggregation PCNN for 3D shape recovery[J]. Information Sciences, 2020, 536: 277-297. 10.1016/j.ins.2020.05.100 |
| 8 | ALI U, MAHMOOD M T. Robust focus volume regularization in shape from focus[J]. IEEE Transactions on Image Processing, 2021, 30: 7215-7227. 10.1109/tip.2021.3100268 |
| 9 | JEON H G, SURH J, IM S, et al. Ring difference filter for fast and noise robust depth from focus[J]. IEEE Transactions on Image Processing, 2020, 29: 1045-1060. 10.1109/tip.2019.2937064 |
| 10 | HAZIRBAS C, SOYER S G, STAAB M C, et al. Deep depth from focus[C]// Proceedings of the 2018 Asian Conference on Computer Vision, LNCS 11363. Cham: Springer, 2019: 525-541. |
| 11 | MAXIMOV M, GALIM K, LEAL-TAIXÉ L. Focus on defocus: bridging the synthetic to real domain gap for depth estimation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1068-1077. 10.1109/cvpr42600.2020.00115 |
| 12 | WANG N H, WANG R, LIU Y L, et al. Bridging unsupervised and supervised depth from focus via all-in-focus supervision[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 12601-12611. 10.1109/iccv48922.2021.01239 |
| 13 | YANG F T, HUANG X L, ZHOU Z H. Deep depth from focus with differential focus volume[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12632-12641. 10.1109/cvpr52688.2022.01231 |
| 14 | LIU Z, NING J, CAO Y, et al. Video Swin Transformer[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 3192-3201. 10.1109/cvpr52688.2022.00320 |
| 15 | NAYAR S K, NAKAGAWA Y. Shape from focus[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994, 16(8): 824-831. 10.1109/34.308479 |
| 16 | PECH-PACHECO J L, CRISTÓBAL G, CHAMORRO-MARTÍNEZ J, et al. Diatom autofocusing in brightfield microscopy: a comparative study[C]// Proceedings of the 15th International Conference on Pattern Recognition. Piscataway: IEEE, 2000: 314-317. |
| 17 | AN Y, KANG G, KIM I J, et al. Shape from focus through Laplacian using 3D window[C]// Proceedings of the 2nd International Conference on Future Generation Communication and Networking. Piscataway: IEEE, 2008: 46-50. 10.1109/fgcn.2008.139 |
| 18 | GEUSEBROEK J M, CORNELISSEN F, SMEULDERS A W M, et al. Robust autofocusing in microscopy[J]. Cytometry, 2000, 39(1): 1-9. 10.1002/(sici)1097-0320(20000101)39:1<1::aid-cyto2>3.0.co;2-j |
| 19 | AHMAD M B, CHOI T S. Application of three dimensional shape from image focus in LCD/TFT displays manufacturing[J]. IEEE Transactions on Consumer Electronics, 2007, 53(1): 1-4. 10.1109/tce.2007.339492 |
| 20 | HUANG W, JING Z L. Evaluation of focus measures in multi-focus image fusion[J]. Pattern Recognition Letters, 2007, 28(4): 493-500. 10.1016/j.patrec.2006.09.005 |
| 21 | SUBBARAO M, CHOI T. Accurate recovery of three-dimensional shape from image focus[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1995, 17(3): 266-274. 10.1109/34.368191 |
| 22 | CHOI T S, YUN J. Three-dimensional shape recovery from the focused-image surface[J]. Optical Engineering, 2000, 39(5): 1321-1326. 10.1117/1.602498 |
| 23 | LEE I, MAHMOOD M T, CHOI T S. Adaptive window selection for 3D shape recovery from image focus[J]. Optics and Laser Technology, 2013, 45: 21-31. 10.1016/j.optlastec.2012.08.003 |
| 24 | THELEN A, FREY S, HIRSCH S, et al. Improvements in shape-from-focus for holographic reconstructions with regard to focus operators, neighborhood-size, and height value interpolation[J]. IEEE Transactions on Image Processing, 2009, 18(1): 151-157. 10.1109/tip.2008.2007049 |
| 25 | MINHAS R, MOHAMMED A A, WU Q M J. Shape from focus using fast discrete curvelet transform[J]. Pattern Recognition, 2011, 44(4): 839-853. 10.1016/j.patcog.2010.10.015 |
| 26 | YAN T, HU Z G, QIAN Y H, et al. 3D shape reconstruction from multifocus image fusion using a multidirectional modified Laplacian operator[J]. Pattern Recognition, 2020, 98: No.107065. 10.1016/j.patcog.2019.107065 |
| 27 | MAHMOOD M T. MRT letter: guided filtering of image focus volume for 3D shape recovery of microscopic objects[J]. Microscopy Research and Technique, 2014, 77(12): 959-963. 10.1002/jemt.22438 |
| 28 | RIBAL C, LERMÉ N, LE HÉGARAT-MASCLE S. Efficient graph cut optimization for shape from focus[J]. Journal of Visual Communication and Image Representation, 2018, 55: 529-539. 10.1016/j.jvcir.2018.06.029 |
| 29 | PERTUZ S, PUIG D, GARCIA M A. Analysis of focus measure operators for shape-from-focus[J]. Pattern Recognition, 2013, 46(5): 1415-1432. 10.1016/j.patcog.2012.11.011 |
| 30 | 山西大学. 一种全局时空聚焦特征耦合的多景深三维形貌重建方法: 202211130317.8[P]. 2022-12-09. |
| Shanxi University. A global spatio-temporal focusing feature coupled multi-depth-of-field 3D shape reconstruction method: 202211130317.8[P]. 2022-12-09. | |
| 31 | SCHECHNER Y Y, KIRYATI N. Depth from defocus vs. stereo: how different really are they?[J]. International Journal of Computer Vision, 2000, 39(2): 141-162. 10.1023/a:1008175127327 |
| 32 | MUHAMMAD M, CHOI T S. Sampling for shape from focus in optical microscopy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(3): 564-573. 10.1109/tpami.2011.144 |
| 33 | RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| 34 | 孙颖,丁卫平,黄嘉爽,等. RCAR-UNet:基于粗糙注意力机制的视网膜血管分割网络[J/OL]. 计算机研究与发展 (2022-07-13) [2022-09-11].. |
| SUN Y, DING W P, HUANG J S, et al. RCAR-UNet: retinal vessels segmentation network based on rough channel attention mechanism[J/OL]. Journal of Computer Research and Development (2022-07-13) [2022-10-19].. | |
| 35 | LIU Z, MAO H Z, WU C Y, et al. A ConvNet for the 2020s[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 11966-11976. 10.1109/cvpr52688.2022.01167 |
| 36 | 韩冰,张鑫云,任爽. 基于3D点云的卷积运算综述[J/OL]. 计算机研究与发展 (2022-07-11) [2022-11-04].. |
| HAN B, ZHANG X Y, REN S. Survey of convolution operations based on 3D point clouds[J/OL]. Journal of Computer Research and Development (2022-07-11) [2022-10-25].. | |
| 37 | NASEER M, RANASINGHE K, KHAN S H, et al. Intriguing properties of vision transformers[C]// Proceedings of the 35th Conference on Neural Information Processing Systems [2020-10-23].. |
| 38 | LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. 10.1109/iccv48922.2021.00986 |
| 39 | XIE S N, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5987-5995. 10.1109/cvpr.2017.634 |
| 40 | SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4510-4520. 10.1109/cvpr.2018.00474 |
| 41 | SHI J L, JIANG X R, GUILLEMOT C. A framework for learning depth from a flexible subset of dense and sparse light field views[J]. IEEE Transactions on Image Processing, 2019, 28(12): 5867-5880. 10.1109/tip.2019.2923323 |
| 42 | PERTUZ S, PUIG D, GARCIA M A. Reliability measure for shape-from-focus[J]. Image and Vision Computing, 2013, 31(10): 725-734. 10.1016/j.imavis.2013.07.005 |
| 43 | HONAUER K, JOHANNSEN O, KONDERMANN D, et al. A dataset and evaluation methodology for depth estimation on 4D light fields[C]// Proceedings of the 2016 Asian Conference on Computer Vision, LNCS 10113. Cham: Springer, 2017: 19-34. |
| 44 | HEBER S, POCK T. Convolutional networks for shape from light field[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3746-3754. 10.1109/cvpr.2016.407 |
| [1] | Rongjun CHEN, Xuanhui YAN, Chaocheng YANG. Fusion imaging-based recurrent capsule classification network for time series [J]. Journal of Computer Applications, 2023, 43(3): 692-699. |
| [2] | Boyi FU, Yuncong PENG, Xin LAN, Xiaolin QIN. Survey of label noise learning algorithms based on deep learning [J]. Journal of Computer Applications, 2023, 43(3): 674-684. |
| [3] | Qi WANG, Hang LEI, Xupeng WANG. Deep face verification under pose interference [J]. Journal of Computer Applications, 2023, 43(2): 595-600. |
| [4] | Ping WANG, Nan CHEN, Lei LU. Fall detection algorithm based on scene prior and attention guidance [J]. Journal of Computer Applications, 2023, 43(2): 529-535. |
| [5] | Li’an ZHU, Hong ZHANG. Nonhomogeneous image dehazing based on dual-branch conditional generative adversarial network [J]. Journal of Computer Applications, 2023, 43(2): 567-574. |
| [6] | Keyou GUO, Xue LI, Min YANG. Real‑time detection method of traffic information based on lightweight YOLOv4 [J]. Journal of Computer Applications, 2023, 43(1): 74-80. |
| [7] | Zhijun SHEN, Lina MU, Jing GAO, Yuanhang SHI, Zhiqiang LIU. Review of fine-grained image categorization [J]. Journal of Computer Applications, 2023, 43(1): 51-60. |
| [8] | Yangping LIN, Jia LIU, Pei CHEN, Mingshu ZHANG, Xiaoyuan YANG. Semi-generative video steganography scheme based on deep convolutional generative adversarial net [J]. Journal of Computer Applications, 2023, 43(1): 169-175. |
| [9] | Jun ZHANG, Pengli WU, Lukui SHI, Jin SHI, Bin PAN. Deep learning model for multi-station temperature prediction combined with MOD11A1 and surface meteorological station data [J]. Journal of Computer Applications, 2023, 43(1): 321-328. |
| [10] | Xin FANG, Zexin HUANG, Yuhan ZHANG, Tian GAO, Jia PAN, Zhonghua FU, Jianqing GAO, Junhua LIU, Liang ZOU. Semi‑supervised end‑to‑end fake speech detection method based on time‑domain waveforms [J]. Journal of Computer Applications, 2023, 43(1): 227-231. |
| [11] | Youxin WANG, Bin CHEN. Print defect detection method based on deep comparison network [J]. Journal of Computer Applications, 2023, 43(1): 250-258. |
| [12] | Jinghu LI, Qianguo XING, Xiangyang ZHENG, Lin LI, Lili WANG. Noctiluca scintillans red tide extraction method from UAV images based on deep learning [J]. Journal of Computer Applications, 2022, 42(9): 2969-2974. |
| [13] | Jiaxuan WEI, Shikang DU, Zhixuan YU, Ruisheng ZHANG. Review of white-box adversarial attack technologies in image classification [J]. Journal of Computer Applications, 2022, 42(9): 2732-2741. |
| [14] | Jinghan YIN, Shaojun QU, Zekai YAO, Xuanye HU, Xiaoyu QIN, Pujing HUA. Traffic sign recognition model in haze weather based on YOLOv5 [J]. Journal of Computer Applications, 2022, 42(9): 2876-2884. |
| [15] | Yajiao LIU, Haitao YU, Jiang WANG, Lifeng YU, Chunhui ZHANG. Surface detection algorithm of multi-shape small defects for section steel based on deep learning [J]. Journal of Computer Applications, 2022, 42(8): 2601-2608. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||