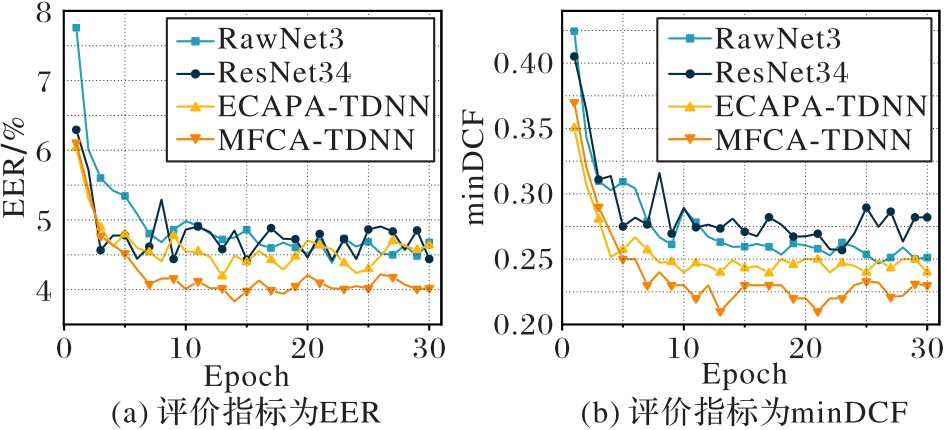
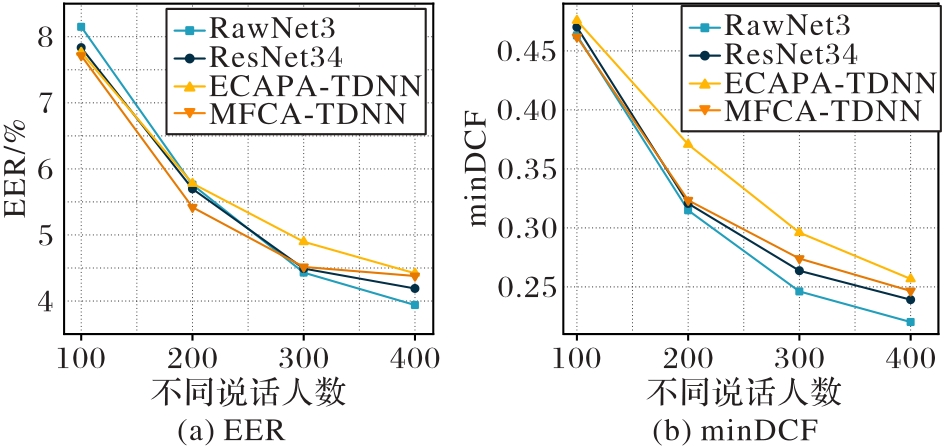
| 1 |
陈晨, 韩纪庆, 陈德运, 等.文本无关说话人识别中句级特征提取方法研究综述[J].自动化学报, 2022, 48(3): 664-688.
|
|
CHEN C, HAN J Q, CHEN D Y,et al. Utterance-level feature extraction in text-independent speaker recognition: a review[J]. Acta Automatica Sinica, 2022, 48(3): 664-688.
|
| 2 |
VARIANI E, LEI X, McDERMOTT E, et al. Deep neural networks for small footprint text-dependent speaker verification[C]// Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2014: 4052-4056.
|
| 3 |
SNYDER D, GARCIA-ROMERO D, SELL G, et al. X-vectors: robust DNN embeddings for speaker recognition[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5329-5333.
|
| 4 |
CHUNG J S, HUH J,MUN S, et al. In defence of metric learning for speaker recognition[EB/OL]. (2020-03-26) [2023-08-01]. .
|
| 5 |
DESPLANQUES B, THIENPONDT J, DEMUYNCK K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification[EB/OL]. (2020-05-14) [2023-08-01]. .
|
| 6 |
THIENPONDT J, DESPLANQUES B, DEMUYNCK K. Integrating frequency translational invariance in TDNNs and frequency positional information in 2D ResNets to enhance speaker verification[EB/OL]. (2021-04-06) [2023-08-01]..
|
| 7 |
ZHAO M, MA Y, LIU M, et al. The SpeakIn system for VoxCeleb Speaker Recognition Challange 2021[EB/OL]. (2021-09-05) [2023-08-01]. .
|
| 8 |
WAN Z-K, REN Q-H, QIN Y-C, et al. Statistical pyramid dense time delay neural network for speaker verification[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7532-7536.
|
| 9 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
|
| 10 |
GAO S-H, CHENG M-M, ZHAO K, et al. Res2Net: a new multi scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(2): 652- 662.
|
| 11 |
陈志高,李鹏,肖润秋,等.文本无关说话人识别的一种多尺度特征提取方法[J]. 电子与信息学报, 2021, 43(11): 3266-3271.
|
|
CEHN Z G, LI P, XIAO R Q,et al. A multi-scale feature extraction method for text-independent speaker recognition[J]. Journal of Electronics & Information Technology, 2021, 43(11): 3266-3271.
|
| 12 |
邓力洪,邓飞,张葛祥,等.改进 Res2Net的多尺度端到端说话人识别系统[J]. 计算机工程与应用, 2023, 59(24): 110-120.
|
|
DENG L H, DENG F, ZHANG G X, et al. Multi-scale end-to-end speaker recognition system based on improved Res2Net[J]. Computer Engineering and Applications, 2023, 59(24): 110-120.
|
| 13 |
WANG X, XUE F, WANG W, et al. A network model of speaker identification with new feature extraction methods and asymmetric BLSTM[J]. Neurocomputing, 2020, 403: 167-181.
|
| 14 |
ABRAHAM J V T, KHAN A N, SHAHINA A. A deep learning approach for robust speaker identification using chroma energy normalized statistics and Mel frequency cepstral coefficients[J]. International Journal of Speech Technology, 2023, 26: 579-587.
|
| 15 |
LIU T, DAS R K, LEE K A, et al. MFA: TDNN with multi-scale frequency-channel attention for text-independent speaker verification with short utterances[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7517-7521.
|
| 16 |
DAI Y, GIESEKE F, OEHMCKE S, et al. Attentional feature fusion[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 3559-3568.
|
| 17 |
PARK D S, CHAN W, ZHANG Y, et al. SpecAugment: a simple data augmentation method for automatic speech recognition[EB/OL]. (2019-08-18) [2023-08-01]. .
|
| 18 |
SNYDER D, CHEN G, POVEY D. MUSAN: a music, speech, and noise corpus[EB/OL]. (2015-10-28) [2023-08-01]. .
|
| 19 |
JUNG J-W, KIM Y J, H-S HEO, et al. Pushing the limits of raw waveform speaker recognition[J]. (2022-03-16) [2023-08-01]. .
|


 ), Yu XIONG, Hong YAN, Fuxing QIU
), Yu XIONG, Hong YAN, Fuxing QIU