


Journal of Computer Applications ›› 2021, Vol. 41 ›› Issue (12): 3645-3651.DOI: 10.11772/j.issn.1001-9081.2021010081
• Artificial intelligence • Previous Articles
Received:2021-01-18
Revised:2021-04-08
Accepted:2021-04-20
Online:2021-12-28
Published:2021-12-10
Contact:
Ran GAO
About author:CHEN Huazhu, born in 1982, Ph. D., lecturer. Her research interests include clustering, classification and image processing.
Supported by:通讯作者:
高冉
作者简介:陈花竹(1982—),女,河南濮阳人,讲师,博士,主要研究方向:聚类、分类及图像处理。
基金资助:CLC Number:
Ran GAO, Huazhu CHEN. Improved subspace clustering model based on spectral clustering[J]. Journal of Computer Applications, 2021, 41(12): 3645-3651.
高冉, 陈花竹. 改进的基于谱聚类的子空间聚类模型[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3645-3651.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021010081
| 变量符号 | 含义 | 变量符号 | 含义 |
|---|---|---|---|
| 数据的集合 | 矩阵 | ||
| 系数矩阵 | 表示所有 | ||
| 矩阵 | 单位矩阵 | ||
| 矩阵 | |||
| 迹范数( | |||
| 对角矩阵 | Trace Lasso范数 |
Tab. 1 Symbol description
| 变量符号 | 含义 | 变量符号 | 含义 |
|---|---|---|---|
| 数据的集合 | 矩阵 | ||
| 系数矩阵 | 表示所有 | ||
| 矩阵 | 单位矩阵 | ||
| 矩阵 | |||
| 迹范数( | |||
| 对角矩阵 | Trace Lasso范数 |

Fig. 1 Sample images of Extended Yale B face data base
| 方法 | 类的个数 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 5 | 8 | 10 | ||||||
| Ave. | Med. | Ave. | Med. | Ave. | Med. | Ave. | Med. | Ave. | Med. | |
| N-cut | 34.08 | 40.63 | 49.52 | 49.74 | 58.50 | 58.13 | 61.62 | 61.13 | 62.71 | 62.66 |
| K-means | 39.54 | 39.06 | 52.62 | 52.60 | 63.53 | 63.75 | 70.16 | 70.11 | 73.95 | 73.28 |
| LRR | 6.74±4.22 | 7.03 | 9.30±3.63 | 9.90 | 13.94±3.36 | 14.38 | 25.61±5.08 | 24.80 | 29.54±4.32 | 30.00 |
| LSR1 | 6.72±4.16 | 7.03 | 9.25±3.64 | 9.90 | 13.87±3.40 | 14.22 | 25.98±5.48 | 25.10 | 28.33±5.65 | 30.00 |
| LSR2 | 6.74±4.22 | 7.03 | 9.29±3.64 | 9.90 | 13.91±3.40 | 14.38 | 25.52±5.47 | 24.80 | 30.73±3.29 | 33.59 |
| CASS | 10.95±12.22 | 6.25 | 13.94±14.22 | 7.81 | 21.25±13.70 | 18.91 | 29.58±5.66 | 29.20 | 32.08±11.59 | 35.31 |
| LRSC | 3.15 | 2.34 | 4.71 | 4.17 | 13.06 | 8.44 | 26.83 | 28.71 | 35.89 | 34.84 |
| BDSSC | 3.90 | — | 17.70 | — | 25.70 | — | 33.20 | — | 39.53 | — |
| BDLRR | 3.91 | — | 10.02 | — | 12.97 | — | 27.70 | — | 30.84 | — |
| LatLRR | 2.54 | 0.78 | 4.21 | 2.60 | 6.90 | 5.63 | 14.34 | 10.06 | 22.92 | 23.59 |
| TSC | 8.06 | — | 9.00 | — | 10.14 | — | 12.58 | — | 17.86 | — |
| OMP | 4.45 | — | 6.35 | — | 8.93 | — | 12.90 | — | 9.82 | — |
| NSN | 1.71 | — | 3.63 | — | 5.81 | — | 8.46 | — | 9.82 | — |
| SSC | 1.87±6.39 | 0.00 | 3.35±7.02 | 0.78 | 4.32±4.60 | 2.81 | 5.99±4.13 4 | 4.49 | 7.29±4.28 | 5.47 |
| BDR | 2.97 | 0.00 | 1.15 | 1.04 | 3.00 | 2.66 | 4.46 | 4.20 | 2.95 | 3.52 |
| SSC+SSpeC | 1.92±6.71 | 0.00 | 3.33±6.97 | 1.04 | 4.49±5.29 | 2.50 | 3.67±2.90 | 3.13 | 2.71±2.04 | 2.19 |
| LSMR | 0.53 | 0.00 | 0.98 | 0.52 | 1.44 | 0.94 | 1.80 | 1.37 | 1.67 | 1.56 |
| SSSC | 0.76±3.90 | 0.00 | 0.82±1.14 | 0.52 | 1.32±0.99 | 1.25 | 2.14±1.05 | 1.95 | 2.40±1.10 | 2.50 |
| 本文模型 | 0.182±0.58 | 0.00 | 0.25±0.60 | 0.00 | 0.309±0.531 | 0.00 | 0.302±0.339 | 0.20 | 0.26±0.239 | 0.31 |
Tab. 2 Clustering error rate on Extended Yale B face data base
| 方法 | 类的个数 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 5 | 8 | 10 | ||||||
| Ave. | Med. | Ave. | Med. | Ave. | Med. | Ave. | Med. | Ave. | Med. | |
| N-cut | 34.08 | 40.63 | 49.52 | 49.74 | 58.50 | 58.13 | 61.62 | 61.13 | 62.71 | 62.66 |
| K-means | 39.54 | 39.06 | 52.62 | 52.60 | 63.53 | 63.75 | 70.16 | 70.11 | 73.95 | 73.28 |
| LRR | 6.74±4.22 | 7.03 | 9.30±3.63 | 9.90 | 13.94±3.36 | 14.38 | 25.61±5.08 | 24.80 | 29.54±4.32 | 30.00 |
| LSR1 | 6.72±4.16 | 7.03 | 9.25±3.64 | 9.90 | 13.87±3.40 | 14.22 | 25.98±5.48 | 25.10 | 28.33±5.65 | 30.00 |
| LSR2 | 6.74±4.22 | 7.03 | 9.29±3.64 | 9.90 | 13.91±3.40 | 14.38 | 25.52±5.47 | 24.80 | 30.73±3.29 | 33.59 |
| CASS | 10.95±12.22 | 6.25 | 13.94±14.22 | 7.81 | 21.25±13.70 | 18.91 | 29.58±5.66 | 29.20 | 32.08±11.59 | 35.31 |
| LRSC | 3.15 | 2.34 | 4.71 | 4.17 | 13.06 | 8.44 | 26.83 | 28.71 | 35.89 | 34.84 |
| BDSSC | 3.90 | — | 17.70 | — | 25.70 | — | 33.20 | — | 39.53 | — |
| BDLRR | 3.91 | — | 10.02 | — | 12.97 | — | 27.70 | — | 30.84 | — |
| LatLRR | 2.54 | 0.78 | 4.21 | 2.60 | 6.90 | 5.63 | 14.34 | 10.06 | 22.92 | 23.59 |
| TSC | 8.06 | — | 9.00 | — | 10.14 | — | 12.58 | — | 17.86 | — |
| OMP | 4.45 | — | 6.35 | — | 8.93 | — | 12.90 | — | 9.82 | — |
| NSN | 1.71 | — | 3.63 | — | 5.81 | — | 8.46 | — | 9.82 | — |
| SSC | 1.87±6.39 | 0.00 | 3.35±7.02 | 0.78 | 4.32±4.60 | 2.81 | 5.99±4.13 4 | 4.49 | 7.29±4.28 | 5.47 |
| BDR | 2.97 | 0.00 | 1.15 | 1.04 | 3.00 | 2.66 | 4.46 | 4.20 | 2.95 | 3.52 |
| SSC+SSpeC | 1.92±6.71 | 0.00 | 3.33±6.97 | 1.04 | 4.49±5.29 | 2.50 | 3.67±2.90 | 3.13 | 2.71±2.04 | 2.19 |
| LSMR | 0.53 | 0.00 | 0.98 | 0.52 | 1.44 | 0.94 | 1.80 | 1.37 | 1.67 | 1.56 |
| SSSC | 0.76±3.90 | 0.00 | 0.82±1.14 | 0.52 | 1.32±0.99 | 1.25 | 2.14±1.05 | 1.95 | 2.40±1.10 | 2.50 |
| 本文模型 | 0.182±0.58 | 0.00 | 0.25±0.60 | 0.00 | 0.309±0.531 | 0.00 | 0.302±0.339 | 0.20 | 0.26±0.239 | 0.31 |
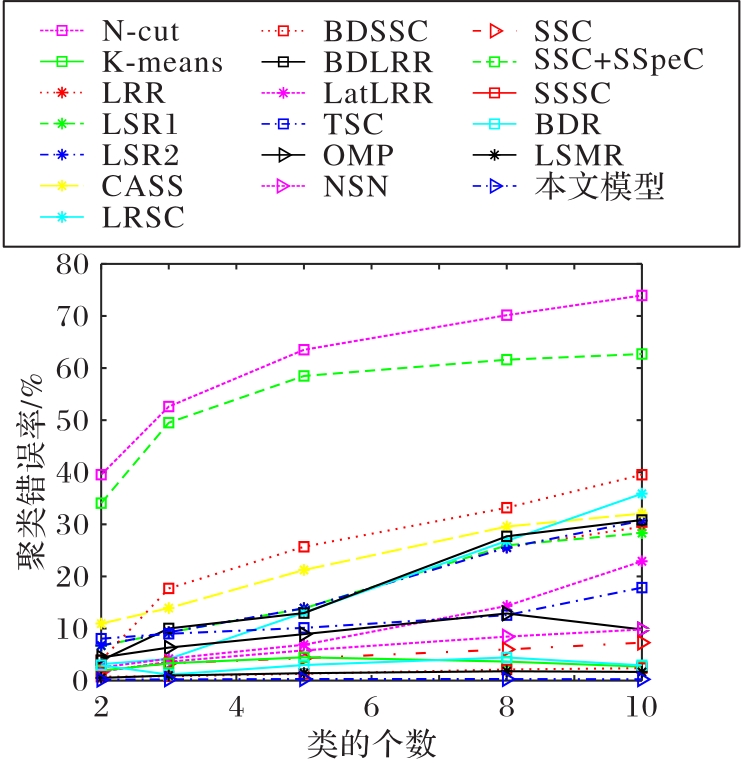
Fig. 2 Relationship between clustering error rate and the number of classes on Extended Yale B data dase

Fig. 3 Visualization of affinity matrix, latent affinity matrix and clustering indicator matrix obtained by three models on Extended Yale B face data base (K=5)

Fig.4 Sample images of Hopkins 155 data base
| 方法 | 类的个数 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | Total | |||||||
| Ave. | Med. | Std. | Ave. | Med. | Std. | Ave. | Med. | Std. | |
| N-cut | 12.74 | 11.09 | 0.12 | 18.00 | 18.05 | 0.11 | 13.93 | 13.03 | 0.12 |
| K-means | 27.88 | 28.57 | 0.11 | 40.24 | 42.67 | 0.12 | 30.67 | 30.80 | 0.12 |
| LSA | 3.27 | 0.55 | 8.41 | 9.15 | 1.66 | 14.58 | 4.06 | 0.69 | 10.37 |
| LRR | 3.76 | 0.00 | 7.73 | 9.92 | 1.42 | 11.33 | 5.15 | 0.00 | 9.07 |
| BDLRR | 3.70 | 0.00 | 10.31 | 6.49 | 1.20 | 12.32 | 4.33 | 0.00 | 10.82 |
| LSR1 | 2.20 | 0.00 | 5.73 | 7.18 | 2.40 | 8.96 | 3.31 | 0.22 | 6.72 |
| LSR2 | 2.22 | 0.00 | 5.73 | 7.18 | 2.40 | 8.86 | 3.34 | 0.23 | 6.86 |
| BDSSC | 2.29 | 0.00 | 7.75 | 4.95 | 0.91 | 9.72 | 2.89 | 0.00 | 8.28 |
| SSC | 1.83 | 0.00 | 6.80 | 4.40 | 0.55 | 9.33 | 2.41 | 0.00 | 7.49 |
| LSMR | 2.09 | - | 5.08 | 7.87 | - | 8.46 | 3.39 | - | 6.45 |
| SSC+SSpeC | 1.81 | 0.00 | — | 4.35 | 0.56 | — | 2.39 | 0.00 | — |
| SSSC | 1.60 | 0.00 | 5.93 | 4.27 | 0.73 | 8.97 | 2.20 | 0.00 | 6.80 |
| DCSC | 1.43 | 0.00 | 4.08 | 4.17 | 1.11 | 6.68 | 2.04 | 0.00 | 4.90 |
| 本文模型 | 1.14 | 0.00 | 5.00 | 4.17 | 0.44 | 9.32 | 1.82 | 0.00 | 6.33 |
Tab.3 Clustering error rates on Hopkins 155 data base
| 方法 | 类的个数 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | Total | |||||||
| Ave. | Med. | Std. | Ave. | Med. | Std. | Ave. | Med. | Std. | |
| N-cut | 12.74 | 11.09 | 0.12 | 18.00 | 18.05 | 0.11 | 13.93 | 13.03 | 0.12 |
| K-means | 27.88 | 28.57 | 0.11 | 40.24 | 42.67 | 0.12 | 30.67 | 30.80 | 0.12 |
| LSA | 3.27 | 0.55 | 8.41 | 9.15 | 1.66 | 14.58 | 4.06 | 0.69 | 10.37 |
| LRR | 3.76 | 0.00 | 7.73 | 9.92 | 1.42 | 11.33 | 5.15 | 0.00 | 9.07 |
| BDLRR | 3.70 | 0.00 | 10.31 | 6.49 | 1.20 | 12.32 | 4.33 | 0.00 | 10.82 |
| LSR1 | 2.20 | 0.00 | 5.73 | 7.18 | 2.40 | 8.96 | 3.31 | 0.22 | 6.72 |
| LSR2 | 2.22 | 0.00 | 5.73 | 7.18 | 2.40 | 8.86 | 3.34 | 0.23 | 6.86 |
| BDSSC | 2.29 | 0.00 | 7.75 | 4.95 | 0.91 | 9.72 | 2.89 | 0.00 | 8.28 |
| SSC | 1.83 | 0.00 | 6.80 | 4.40 | 0.55 | 9.33 | 2.41 | 0.00 | 7.49 |
| LSMR | 2.09 | - | 5.08 | 7.87 | - | 8.46 | 3.39 | - | 6.45 |
| SSC+SSpeC | 1.81 | 0.00 | — | 4.35 | 0.56 | — | 2.39 | 0.00 | — |
| SSSC | 1.60 | 0.00 | 5.93 | 4.27 | 0.73 | 8.97 | 2.20 | 0.00 | 6.80 |
| DCSC | 1.43 | 0.00 | 4.08 | 4.17 | 1.11 | 6.68 | 2.04 | 0.00 | 4.90 |
| 本文模型 | 1.14 | 0.00 | 5.00 | 4.17 | 0.44 | 9.32 | 1.82 | 0.00 | 6.33 |

Fig.5 Relationship between clustering error rate and the number of classes on Hopkins 155 data base

Fig.6 Sample images of USPS data base
| 方法 | 10类的ERR | 方法 | 10类的ERR |
|---|---|---|---|
| N-cut | 17.71 | SMR | 11.10 |
| K-means | 77.20 | SSC | 10.10 |
| LRR | 26.90 | LSMR | 38.70 |
| LSR1 | 42.90 | SSC+SSpeC | 8.90 |
| LSR2 | 25.30 | SSSC | 8.20 |
| CASS | 18.00 | 本文方法 | 7.70 |
Tab.4 Clustering error rates on USPS database
| 方法 | 10类的ERR | 方法 | 10类的ERR |
|---|---|---|---|
| N-cut | 17.71 | SMR | 11.10 |
| K-means | 77.20 | SSC | 10.10 |
| LRR | 26.90 | LSMR | 38.70 |
| LSR1 | 42.90 | SSC+SSpeC | 8.90 |
| LSR2 | 25.30 | SSSC | 8.20 |
| CASS | 18.00 | 本文方法 | 7.70 |
| 1 | BRADLEY P S, MANGASARIAN O L. k-plane clustering[J]. Journal of Global Optimization, 2000, 16(1): 23-32. 10.1023/a:1008324625522 |
| 2 | RODRIGUES É O, TOROK L, LIATSIS P, et al. k-MS: a novel clustering algorithm based on morphological reconstruction[J]. Pattern Recognition, 2017, 66: 392-403. 10.1016/j.patcog.2016.12.027 |
| 3 | MA Y, YANG A Y, DERKSEN H, et al. Estimation of subspace arrangements with applications in modeling and segmenting mixed data[J]. SIAM Review, 2008, 50(3): 413-458. 10.1137/060655523 |
| 4 | TSAKIRIS M C, VIDAL R. Algebraic clustering of affine subspaces[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(2): 482-489. 10.1109/tpami.2017.2678477 |
| 5 | ARCHAMBEAU C, DELANNAY N, VERLEYSEN M. Mixtures of robust probabilistic principal component analyzers[J]. Neurocomputing, 2008, 71(7/8/9): 1274-1282. 10.1016/j.neucom.2007.11.029 |
| 6 | MA Y, DERKSEN H, HONG W, et al. Segmentation of multivariate mixed data via lossy coding and compression[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(9): 1546-1562. 10.1109/tpami.2007.1085 |
| 7 | VIDAL R. Subspace clustering[J]. IEEE Signal Processing Magazine, 2011, 28(2): 52-68. 10.1109/msp.2010.939739 |
| 8 | ELHAMIFAR E, VIDAL R. Sparse subspace clustering[C]// Proceedings of the 2009 IEEE Conference on Computer Vision Pattern Recognition. Piscataway: IEEE, 2009: 2790-2797. 10.1109/cvpr.2009.5206547 |
| 9 | ELHAMIFAR E, VIDAL R. Sparse subspace clustering: algorithm, theory, and applications[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2765-2781. 10.1109/tpami.2013.57 |
| 10 | LIU G C, LIN Z C, YU Y. Robust subspace segmentation by low-rank representation[C]// Proceedings of the 27th International Conference on Machine Learning. Madison, WI: Omnipress, 2010: 663-670. 10.1109/iccv.2011.6126422 |
| 11 | LIU G C, LIN Z C, YAN S C, et al. Robust recovery of subspace structures by low-rank representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 171-184. 10.1109/tpami.2012.88 |
| 12 | LU C Y, MIN H, ZHAO Z Q, et al. Robust and efficient subspace segmentation via least squares regression[C]// Proceedings of the 2012 European Conference on Computer Vision, LNCS7578. Berlin: Springer, 2012: 347-360. |
| 13 | LU C Y, FENG J S, LIN Z C, et al. Correlation adaptive subspace segmentation by trace Lasso[C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 1345-1352. 10.1109/iccv.2013.170 |
| 14 | LIU G C, YAN S C. Latent low-rank representation for subspace segmentation and feature extraction[C]// Proceedings of the 2011 International Conference on Computer Vision. Piscataway: IEEE, 2011: 1615-1622. 10.1109/iccv.2011.6126422 |
| 15 | XIAO X B, WEI L. Robust subspace clustering via latent smooth representation clustering[J]. Neural Processing Letters, 2020, 52(2): 1317-1337. 10.1007/s11063-020-10306-8 |
| 16 | LU C Y, FENG J S, LIN Z C, et al. Subspace clustering by block diagonal representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(2): 487-501. 10.1109/tpami.2018.2794348 |
| 17 | SHI J B, MALIK J. Normalized cuts and image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(8): 888-905. 10.1109/34.868688 |
| 18 | LU C Y, YAN S C, LIN Z C. Convex sparse spectral clustering: single-view to multi-view[J]. IEEE Transactions on Image Processing, 2016, 25(6): 2833-2843. 10.1109/tip.2016.2553459 |
| 19 | LI C G, VIDAL R. Structured sparse subspace clustering: a unified optimization framework[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 277-286. 10.1109/cvpr.2015.7298624 |
| 20 | LI C G, YOU C, VIDAL R, et al. Structured sparse subspace clustering: a joint affinity learning and subspace clustering framework[J]. IEEE Transactions on Image Processing, 2017, 26(6): 2988-3001. 10.1109/tip.2017.2691557 |
| 21 | LIU M S, WANG Y, SUN J, et al. Structured block diagonal representation for subspace clustering[J]. Applied Intelligence, 2020, 50(8): 2523-2536. 10.1007/s10489-020-01629-z |
| 22 | CHEN H Z, WANG W W, FENG X C, et al. Discriminative and coherent subspace clustering[J]. Neurocomputing, 2018, 284: 177-186. 10.1016/j.neucom.2018.01.006 |
| 23 | BOYD S, PARIKH N, CHU E, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers[J]. Foundations and Trends in Machine Learning, 2011, 3(1): 1-122. |
| 24 | LIN Z C, CHEN M M, MA Y. The augmented Lagrange multiplier method for exact recovery of corrupted low-rank matrices[EB/OL]. (2013-10-18) [2020-11-19]. . |
| 25 | GEORGHIADES A S, BELHUMEUR P N, KRIEGMAN D J. From few to many: illumination cone models for face recognition under variable lighting and pose[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(6): 643-660. 10.1109/34.927464 |
| 26 | TRON R, VIDAL R. A benchmark for the comparison of 3-D motion segmentation algorithms[C]// Proceedings of the 2007 IEEE Conference on Computer Vision Pattern Recognition. Piscataway: IEEE, 2007: 1-8. 10.1109/cvpr.2007.382974 |
| 27 | HULL J J. A database for handwritten text recognition research[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994, 16(5):550-554. 10.1109/34.291440 |
| 28 | FENG J S, LIN Z C, XU H, et al. Robust subspace segmentation with block-diagonal prior[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 3818-3825. 10.1109/cvpr.2014.482 |
| 29 | VIDAL R, FAVARO P. Low Rank Subspace Clustering (LRSC)[J]. Pattern Recognition Letters, 2014, 43: 47-61. 10.1016/j.patrec.2013.08.006 |
| 30 | FAVARO P, VIDAL R, RAVICHANDRAN A. A closed form solution to robust subspace estimation and clustering[C]// Proceedings of the 2011 IEEE Conference on Computer Vision Pattern Recognition. Piscataway: IEEE, 2011: 1801-1807. 10.1109/cvpr.2011.5995365 |
| 31 | HECKEL R, BÖLCSKEI H. Robust subspace clustering via thresholding[J]. IEEE Transactions on Information Theory, 2015, 61(11): 6320-6342. 10.1109/tit.2015.2472520 |
| 32 | DYER E L, SANKARANARAYANAN A C, BARANIUK R G. Greedy feature selection for subspace clustering[J]. Journal of Machine Learning Research, 2013, 14: 2487-2517. 10.1109/icassp.2013.6638260 |
| 33 | YAN J Y, POLLEFEYS M. A general framework for motion segmentation: independent, articulated, rigid, non-rigid, degenerate and non-degenerate[C]// Proceedings of the 2006 European Conference on Computer Vision, LNCS3954. Berlin: Springer, 2006: 94-106. 10.1007/978-3-540-70932-9_6 |
| 34 | HU H, LIN Z C, FENG J J, et al. Smooth representation clustering[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 3834-3841. 10.1109/cvpr.2014.484 |
| [1] | ZHU Cheng, ZHAO Xiaoqi, ZHAO Liping, JIAO Yuhong, ZHU Yafei, CHENG Jianying, ZHOU Wei, TAN Ying. Classification of functional magnetic resonance imaging data based on semi-supervised feature selection by spectral clustering [J]. Journal of Computer Applications, 2021, 41(8): 2288-2293. |
| [2] | ZHU Yuna, ZHANG Yutao, YAN Shaoge, FAN Yudan, CHEN Hantuo. Protocol identification approach based on semi-supervised subspace clustering [J]. Journal of Computer Applications, 2021, 41(10): 2900-2904. |
| [3] | WANG Lijuan, CHEN Shaomin, YIN Ming, XU Yueying, HAO Zhifeng, CAI Ruichu, WEN Wen. Improved block diagonal subspace clustering algorithm based on neighbor graph [J]. Journal of Computer Applications, 2021, 41(1): 36-42. |
| [4] | LI Xingfeng, HUANG Yuqing, REN Zhenwen. Joint low-rank and sparse multiple kernel subspace clustering algorithm [J]. Journal of Computer Applications, 2020, 40(6): 1648-1653. |
| [5] | Meng ZENG, Bin NING, Zhihua CAI, Qiong GU. Hyperspectral band selection based on deep adversarial subspace clustering [J]. Journal of Computer Applications, 2020, 40(2): 381-385. |
| [6] | LIU Jingshu, WANG Li, LIU Jinglei. Fast spectral clustering algorithm without eigen-decomposition [J]. Journal of Computer Applications, 2020, 40(12): 3413-3422. |
| [7] | SONG Yan, YIN Jun. Multi-view spectral clustering algorithm based on shared nearest neighbor [J]. Journal of Computer Applications, 2020, 40(11): 3211-3216. |
| [8] | CUI Yixin, CHEN Xiaodong. Spark framework based optimized large-scale spectral clustering parallel algorithm [J]. Journal of Computer Applications, 2020, 40(1): 168-172. |
| [9] | MAO Yimin, LIU Yinping, LIANG Tian, MAO Dinghui. Functional module mining in uncertain protein-protein interaction network based on fuzzy spectral clustering [J]. Journal of Computer Applications, 2019, 39(4): 1032-1040. |
| [10] | GUO Xuancheng, LIN Hui, YE Xiucai, XU Chuanfeng. Controller deployment and switch dynamic migration strategy in software defined WAN [J]. Journal of Computer Applications, 2019, 39(2): 453-457. |
| [11] | SUN Shilei, WANG Chao, ZHAO Yuandi. Parameter independent clustering of air traffic trajectory based on silhouette coefficient [J]. Journal of Computer Applications, 2019, 39(11): 3293-3297. |
| [12] | ZHENG Xiaoyao, CHEN Dongmei, LIU Yuqing, YOU Hao, WANG Xiangshun, SUN Liping. Spectral clustering algorithm based on differential privacy protection [J]. Journal of Computer Applications, 2018, 38(10): 2918-2922. |
| [13] | CHENG Lingfang, YANG Tianpeng, CHEN Lifei. Soft subspace clustering algorithm for imbalanced data [J]. Journal of Computer Applications, 2017, 37(10): 2952-2957. |
| [14] | WU Jieqi, LI Xiaoyu, YUAN Xiaotong, LIU Qingshan. Parallel sparse subspace clustering via coordinate descent minimization [J]. Journal of Computer Applications, 2016, 36(2): 372-376. |
| [15] | WANG Weidong, LIU Bing, GUAN Hongjie, ZHOU Yong, XIA Shixiong. Spectral embedded clustering algorithm based on kernel function [J]. Journal of Computer Applications, 2015, 35(3): 761-765. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
