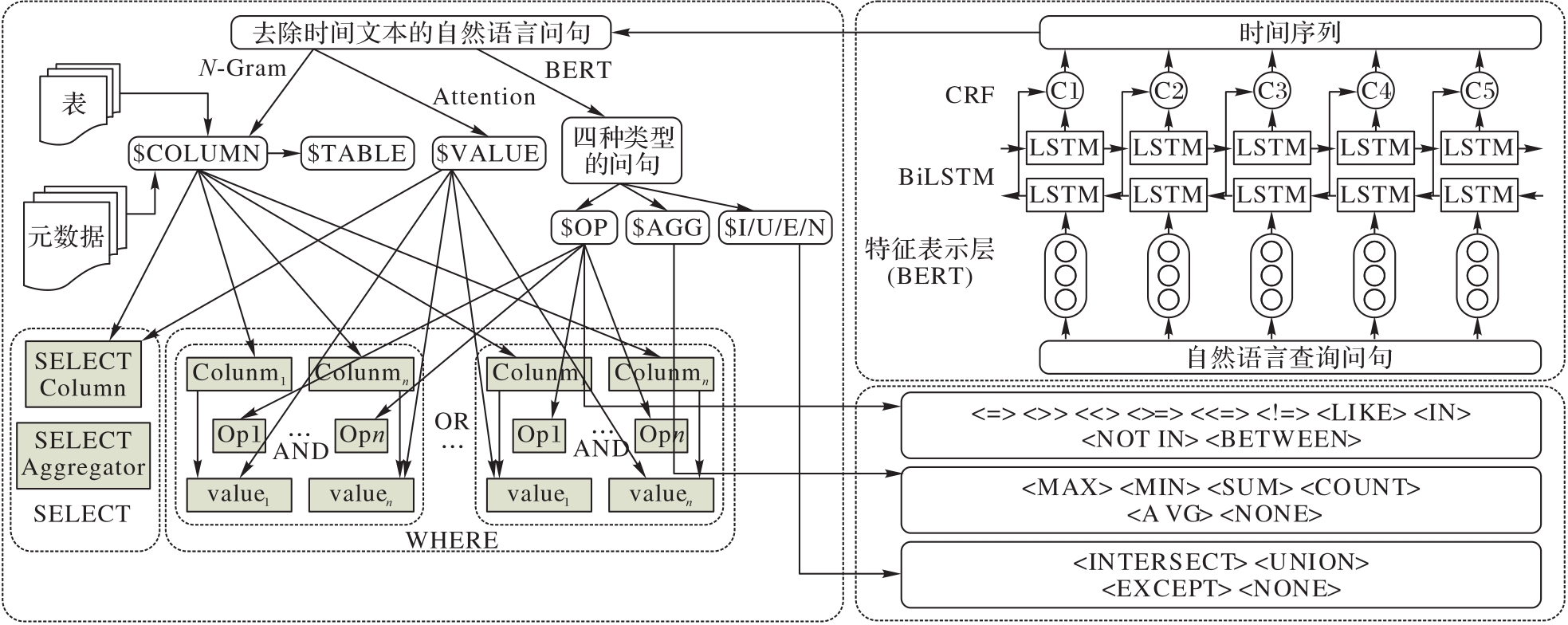
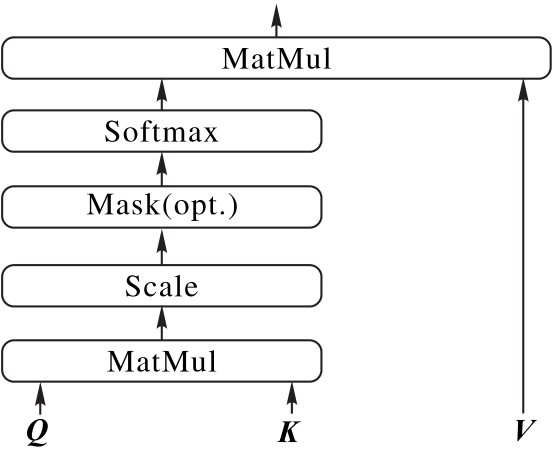
| 1 |
WARREN D H D, PEREIRA F C N. An efficient easily adaptable system for interpreting natural language queries[J]. American Journal of Computational Linguistics, 1982, 8(3/4): 110-122.
|
| 2 |
ANDROUTSOPOULOS I, RITCHIE G D, THANISCH P. Natural language interfaces to databases-an introduction[J]. Natural Language Engineering, 1995, 1(1): 29-81. 10.1017/s135132490000005x
|
| 3 |
POPESCU A M, ARMANASU A, ETZIONI O, et al. Modern natural language interfaces to databases: composing statistical parsing with semantic tractability[C]// Proceedings of the 20th International Conference on Computational Linguistics. [S.l.]: COLING, 2004: 141-147. 10.3115/1220355.1220376
|
| 4 |
HALLET C. Generic querying of relational databases using natural language generation techniques[C]// Proceedings of the 4th International Natural Language Generation Conference. Stroudsburg, PA: Association for Computational Linguistics, 2006: 95-102. 10.3115/1706269.1706289
|
| 5 |
GIORDANI A, MOSCHITTI A. Generating SQL queries using natural language syntactic dependencies and metadata[C]// Proceedings of the 2012 International Conference on Applications of Natural Language Processing to Information Systems, LNCS 7337. Berlin: Springer, 2012: 164-170.
|
| 6 |
ZHONG V, XIONG C M, SOCHER R. Seq2SQL: generating structured queries from natural language using reinforcement learning[EB/OL]. (2017-11-09) [2021-06-20].. 10.48550/arXiv.1709.00103
|
| 7 |
YU T, ZHANG R, YANG K, et al. Spider: a large-scale human-labeled dataset for complex and cross-domain semantic parsing and Text-to-SQL task[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 3911-3921. 10.18653/v1/d18-1425
|
| 8 |
HE P C, MAO Y, CHAKRABARTI K, et al. X-SQL: reinforce schema representation with context[EB/OL]. (2019-08-21) [2021-06-20]..
|
| 9 |
ZHANG X Y, YIN F J, MA G J, et al. M-SQL: multi-task representation learning for single-table Text2SQL generation[J]. IEEE Access, 2020, 8:43156-43167. 10.1109/access.2020.2977613
|
| 10 |
YU T, YASUNAGA M, YANG K, et al. SyntaxSQLNet: syntax tree networks for complex and cross-domain text-to-SQL task[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 1653-1663. 10.18653/v1/d18-1193
|
| 11 |
GUO J Q, ZHAN Z C, GAO Y, et al. Towards complex Text-to-SQL in cross-domain database with intermediate representation[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 4524-4535. 10.18653/v1/p19-1444
|
| 12 |
YU T, LI Z F, ZHANG Z L, et al. TypeSQL: knowledge-based type-aware neural Text-to-SQL generation[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2018: 588-594. 10.18653/v1/n18-2093
|
| 13 |
WANG C L, TATWAWADI K, BROCKSCHMIDT M, et al. Robust text-to-SQL generation with execution-guided decoding[EB/OL]. (2018-09-13) [2021-06-20]..
|
| 14 |
FINEGAN-DOLLAK C, KUMMERFELD J K, ZHANG L, et al. Improving text-to-SQL evaluation methodology[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 351-360. 10.18653/v1/p18-1033
|
| 15 |
WANG B L, SHIN R, LIU X D, et al. RAT-SQL: relation-aware schema encoding and linking for text-to-SQL parsers[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 7567-7578. 10.18653/v1/2020.acl-main.677
|
| 16 |
MIN Q K, SHI Y F, ZHANG Y. A pilot study for Chinese SQL semantic parsing[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 3652-3658. 10.18653/v1/d19-1377
|
| 17 |
WANG L J, ZHANG A, WU K, et al. DuSQL: a large-scale and pragmatic Chinese text-to-SQL dataset[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2020: 6923-6935. 10.18653/v1/2020.emnlp-main.562
|
| 18 |
LIN X V, SOCHER R, XIONG C M. Bridging textual and tabular data for cross-domain text-to-SQL semantic parsing[C]// Proceedings of the 2020 Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg, PA: Association for Computational Linguistics, 2020: 4870-4888. 10.18653/v1/2020.findings-emnlp.438
|
| 19 |
VINYALS O, FORTUNATO M, JAITLY N. Pointer networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 2692-2700.
|
| 20 |
XU X J, LIU C, SONG D. SQLNet: generating structured queries from natural language without reinforcement learning[EB/OL]. (2017-11-13) [2021-06-20]..
|
| 21 |
PRICE P J. Evaluation of spoken language systems: the ATIS domain[C]// Proceedings of the 1990 Workshop on Speech and Natural Language. San Francisco: Morgan Kaufmann Publishers Inc., 1990: 91-95. 10.3115/116580.116612
|
| 22 |
ZELLE J M, MOONEY R J. Learning to parse database queries using inductive logic programming[C]// Proceedings of the 13th National Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 1996: 1050-1055. 10.1007/3-540-60925-3_59
|
| 23 |
张顺利,王应军,姬东鸿. 基于BLSTM网络的医学时间短语识别[J]. 计算机应用研究, 2020, 37(4):1059-1062. 10.19734/j.issn.1001-3695.2018.09.0742
|
|
ZHANG S L, WANG Y J, JI D H. Temporal phrases extraction in clinical text based on bidirectional long-short term memory model[J]. Application Research of Computers, 2020, 37(4): 1059-1062. 10.19734/j.issn.1001-3695.2018.09.0742
|
| 24 |
SHAW P, USZKOREIT J, VASWANI A. Self-attention with relative position representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 464-468. 10.18653/v1/n18-2074
|
| 25 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010.
|