


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (2): 335-342.DOI: 10.11772/j.issn.1001-9081.2021122221
• Artificial intelligence • Previous Articles
Chengyu LIN1,2, Lei WANG1, Cong XUE1( )
)
Received:2022-01-06
Revised:2022-03-22
Accepted:2022-04-13
Online:2023-02-08
Published:2023-02-10
Contact:
Cong XUE
About author:LIN Chengyu, born in 1997, M. S. candidate. His research interests include natural language processing.Supported by:通讯作者:
薛聪
作者简介:林呈宇(1997—),男,浙江宁波人,硕士研究生,主要研究方向:自然语言处理基金资助:CLC Number:
Chengyu LIN, Lei WANG, Cong XUE. Weakly-supervised text classification with label semantic enhancement[J]. Journal of Computer Applications, 2023, 43(2): 335-342.
林呈宇, 王雷, 薛聪. 标签语义增强的弱监督文本分类模型[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 335-342.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021122221

Fig. 1 Learning framework of weakly-supervised text classification
| 示例 | 噪声类型 |
|---|---|
| 句子1:我国航天科技取得重大突破。 | 无标签噪声 |
| 句子2:晶科科技历史性抛盘套牢众多散户。 | 误识别噪声 |
| 句子3:神舟十号载人飞行任务新闻发布会。 | 未识别噪声 |
Tab.1 Noise instances in weakly-supervised text classification
| 示例 | 噪声类型 |
|---|---|
| 句子1:我国航天科技取得重大突破。 | 无标签噪声 |
| 句子2:晶科科技历史性抛盘套牢众多散户。 | 误识别噪声 |
| 句子3:神舟十号载人飞行任务新闻发布会。 | 未识别噪声 |

Fig. 2 Framework of weakly-supervised text classification model based on BERT

Fig. 3 Learning framework of LSETClass model
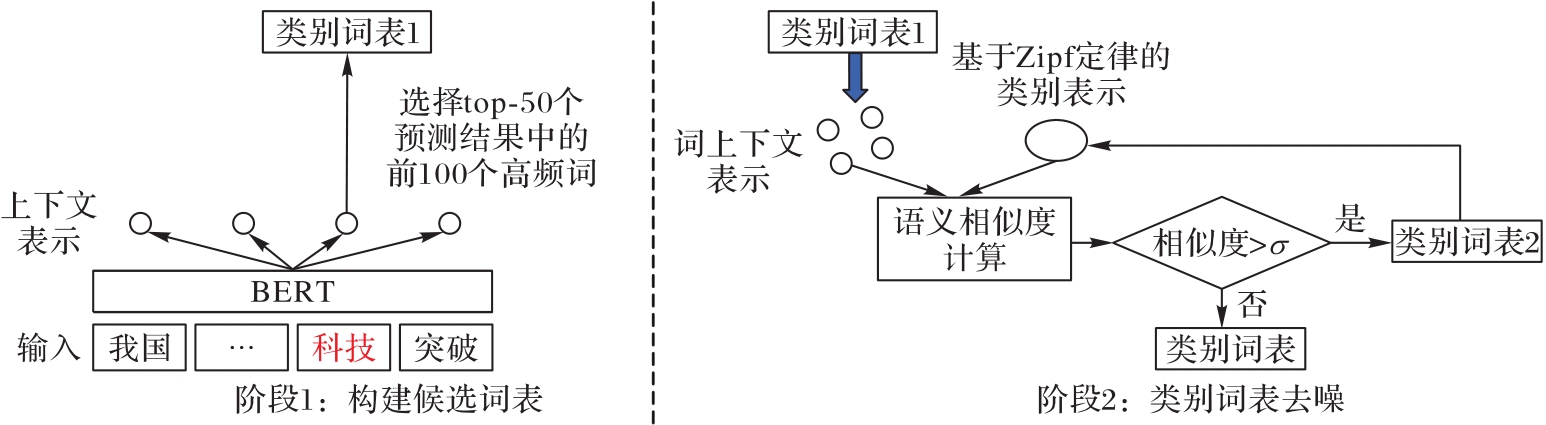
Fig. 4 Process of constructing category words based on contextual representation
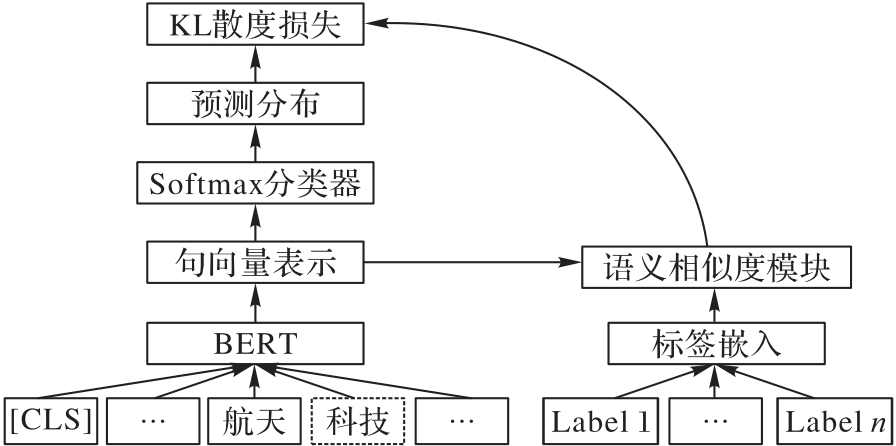
Fig. 5 Learning framework of self-training phase

Fig. 6 Distribution of hard-labels and labels in this paper
| 数据集 | 数据总量 | 样本数 | 类别数 | 平均每条数据词数 | |
|---|---|---|---|---|---|
| 训练集 | 测试集 | ||||
| THUCNews | 200 000 | 170 000 | 30 000 | 10 | 362 |
| AG News | 127 600 | 120 000 | 7 600 | 4 | 223 |
| IMDB | 50 000 | 25 000 | 25 000 | 2 | 292 |
Tab.2 Dataset introduction
| 数据集 | 数据总量 | 样本数 | 类别数 | 平均每条数据词数 | |
|---|---|---|---|---|---|
| 训练集 | 测试集 | ||||
| THUCNews | 200 000 | 170 000 | 30 000 | 10 | 362 |
| AG News | 127 600 | 120 000 | 7 600 | 4 | 223 |
| IMDB | 50 000 | 25 000 | 25 000 | 2 | 292 |
| 模型方法 | 数据集 | ||
|---|---|---|---|
| THUCNews | AG News | IMDB | |
| TextCNN | 91.22 | 87.26 | 86.73 |
| BiLSTM | 91.12 | 82.58 | 87.56 |
| BERT | 94.83 | 92.27 | 93.87 |
| UDA | 88.54 | 86.90 | 88.61 |
| LOTClass | 55.53 | 86.44 | 86.62 |
| BERT w.simple match | 48.46 | 75.21 | 68.74 |
| LSETClass | 60.82 | 87.85 | 88.48 |
| LSETClass-LE | 58.06 | 87.08 | 87.53 |
| LSETClass-WD | 58.27 | 87.22 | 87.36 |
Tab.3 Accuracy comparison of experimental results on different text datasets
| 模型方法 | 数据集 | ||
|---|---|---|---|
| THUCNews | AG News | IMDB | |
| TextCNN | 91.22 | 87.26 | 86.73 |
| BiLSTM | 91.12 | 82.58 | 87.56 |
| BERT | 94.83 | 92.27 | 93.87 |
| UDA | 88.54 | 86.90 | 88.61 |
| LOTClass | 55.53 | 86.44 | 86.62 |
| BERT w.simple match | 48.46 | 75.21 | 68.74 |
| LSETClass | 60.82 | 87.85 | 88.48 |
| LSETClass-LE | 58.06 | 87.08 | 87.53 |
| LSETClass-WD | 58.27 | 87.22 | 87.36 |
| 类别名 | LOTClass | LSETClass |
|---|---|---|
| 体育 | 体育, 体操,运动,体检,文体,体能,体质,体制,团体, 实体,群体,体力,体格,足球,体重,总体,整体,身体, 乒乓球,体裁,全体,个体,肉体,形体,体系,人体,立体, 篮球,sports,sport,本体,羽毛球,母体,体表,奥运,大体, 机体,肢体,载体,体外,体温,体型,运动会,运动员,体面,环球,物体,奥林匹克,体液,集体,一体,一体化,具体 | |
| 房产 | 房产,房地产,地产,房屋,住房,产业,购房,房子,新房,商品房,房价, 楼房,产权,产区,产地,书房,房间,产出,投产,买房,特产,产能,国产,矿产,药房,房门,客房,家产,高产,牢房,海产,厨房,产业园,房舍, 水产,原产,出产,产生,产物,评论,房县,房中,物产,house,论坛, 再生产,产值,破产,厂房,产量,生产,遗产,认可,停产,住宅,第三产业,知识产权,固定资产,信息网,子房,生产力,小区,乳房,产业资本,年产,病房,产妇,商品生产,盛产,产于,生产者,上房,第二产业,增产,住所,农产品,土特产,产业化,年产量,房基,物业,总产量,生产资料,生产量 | 房产,房地产,地产,住房,房屋, 房子,新房,商品房, 房价,买房,楼房,购房,住宅, 产权,书房,房间,产出, 投产,房中,房门,客房,家产, 房舍, 牢房,厨房,物业, 原产,出产,产物,房县,物产,house,再生产,产值,矿产, 破产,产量,药房,生产,遗产,停产,厂房,年产量, 知识产权,固定资产,信息网,小区,产业资本,年产, 商品生产,上房,增产,住所,产业化,房基,生产力 |
| 政治 | 政治,政治学,政治经济, 政治经济学, 宪政, 治国, 政治家,内政,军政,党政, 政治局, 国政,从政,政体, 为政,政局,政法,政府, 中国政府, 市政,行政,施政, 财政,政事,政权,政党, 政策, 美国政府,政务,执政, 民政,政制,政客,参政,邮政, 政协,治理,政工,政变, 朝政,党政军,专政,法治, 朝政, 政制,为政,政工, 专政,政局,整治,国政, 治安, 民政,市政,参政,政权, 政区,执政党,政绩,政事,廉政,中央政治局,政治委员, 政客,摄政,综合治理,主治,议政,政协,选举 |
Tab.4 Comparison results of category vocabularies on THUCNews dataset
| 类别名 | LOTClass | LSETClass |
|---|---|---|
| 体育 | 体育, 体操,运动,体检,文体,体能,体质,体制,团体, 实体,群体,体力,体格,足球,体重,总体,整体,身体, 乒乓球,体裁,全体,个体,肉体,形体,体系,人体,立体, 篮球,sports,sport,本体,羽毛球,母体,体表,奥运,大体, 机体,肢体,载体,体外,体温,体型,运动会,运动员,体面,环球,物体,奥林匹克,体液,集体,一体,一体化,具体 | |
| 房产 | 房产,房地产,地产,房屋,住房,产业,购房,房子,新房,商品房,房价, 楼房,产权,产区,产地,书房,房间,产出,投产,买房,特产,产能,国产,矿产,药房,房门,客房,家产,高产,牢房,海产,厨房,产业园,房舍, 水产,原产,出产,产生,产物,评论,房县,房中,物产,house,论坛, 再生产,产值,破产,厂房,产量,生产,遗产,认可,停产,住宅,第三产业,知识产权,固定资产,信息网,子房,生产力,小区,乳房,产业资本,年产,病房,产妇,商品生产,盛产,产于,生产者,上房,第二产业,增产,住所,农产品,土特产,产业化,年产量,房基,物业,总产量,生产资料,生产量 | 房产,房地产,地产,住房,房屋, 房子,新房,商品房, 房价,买房,楼房,购房,住宅, 产权,书房,房间,产出, 投产,房中,房门,客房,家产, 房舍, 牢房,厨房,物业, 原产,出产,产物,房县,物产,house,再生产,产值,矿产, 破产,产量,药房,生产,遗产,停产,厂房,年产量, 知识产权,固定资产,信息网,小区,产业资本,年产, 商品生产,上房,增产,住所,产业化,房基,生产力 |
| 政治 | 政治,政治学,政治经济, 政治经济学, 宪政, 治国, 政治家,内政,军政,党政, 政治局, 国政,从政,政体, 为政,政局,政法,政府, 中国政府, 市政,行政,施政, 财政,政事,政权,政党, 政策, 美国政府,政务,执政, 民政,政制,政客,参政,邮政, 政协,治理,政工,政变, 朝政,党政军,专政,法治, 朝政, 政制,为政,政工, 专政,政局,整治,国政, 治安, 民政,市政,参政,政权, 政区,执政党,政绩,政事,廉政,中央政治局,政治委员, 政客,摄政,综合治理,主治,议政,政协,选举 |
| 1 | YU Y, ZUO S M, JIANG H M, et al. Fine-tuning pre-trained language model with weak supervision: a contrastive-regularized self-training approach[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2021: 1063-1077. 10.18653/v1/2021.naacl-main.84 |
| 2 | MEKALA D, SHANG J B. Contextualized weak supervision for text classification[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 323-333. 10.18653/v1/2020.acl-main.30 |
| 3 | MENG Y, SHEN J M, ZHANG C, et al. Weakly-supervised neural text classification[C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 983-992. 10.1145/3269206.3271737 |
| 4 | WANG Z H, MEKALA D, SHANG J B. X-Class: text classification with extremely weak supervision[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2021: 3043-3053. 10.18653/v1/2021.naacl-main.242 |
| 5 | AWASTHI A, GHOSH S, GOYAL R, et al. Learning from rules generalizing labeled exemplars[EB/OL]. (2020-05-15) [2021-11-07].. |
| 6 | SHEN T, GENG X B, LONG G D, et al. Effective search of logical forms for weakly supervised knowledge-based question answering[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020: 2227-2233. 10.24963/ijcai.2020/308 |
| 7 | TAN B W, QIN L H, XING E P, et al. Summarizing text on any aspects: a knowledge-informed weakly-supervised approach[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 6301-6309. 10.18653/v1/2020.emnlp-main.510 |
| 8 | LI C L, XING J, SUN A X, et al. Effective document labeling with very few seed words: a topic model approach[C]// Proceedings of the 25th ACM International Conference on Information and Knowledge Management. New York: ACM, 2016: 85-94. 10.1145/2983323.2983721 |
| 9 | MENG Y, SHEN J M, ZHANG C, et al. Weakly-supervised hierarchical text classification[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019:6826-6833. 10.1609/aaai.v33i01.33016826 |
| 10 | KARAMANOLAKIS G, MUKHERJEE S, ZHENG G Q, et al. Self-training with weak supervision[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2021: 845-863. 10.18653/v1/2021.naacl-main.66 |
| 11 | REN W D, LI Y H, SU H T, et al. Denoising multi-source weak supervision for neural text classification[C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg, PA: ACL, 2020: 3739-3754. 10.18653/v1/2020.findings-emnlp.334 |
| 12 | MENG Y, ZHANG Y Y, HUANG J X, et al. Text classification using label names only: a language model self-training approach[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 9006-9017. 10.18653/v1/2020.emnlp-main.724 |
| 13 | JINDAL I, PRESSEL D, LESTER B, et al. An effective label noise model for DNN text classification[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 3246-3256. 10.18653/v1/n19-1328 |
| 14 | POWERS D M W. Applications and explanations of Zipf’s law[C]// Proceedings of the 1998 Joint Conferences on New Methods in Language Processing and Computational Natural Language Learning. Somerset, NJ: ACL, 1998: 151-160. 10.3115/1603899.1603924 |
| 15 | GABRILOVICH E, MARKOVITCH S. Computing semantic relatedness using Wikipedia-based explicit semantic analysis[C]// Proceedings of the 20th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2007: 1606-1611. |
| 16 | CHEN X Y, XIA Y Q, JIN P, et al. Dataless text classification with descriptive LDA[C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2015: 2224-2231. 10.1609/aaai.v29i1.9506 |
| 17 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 18 | YANG Z L, DAI Z H, YANG Y M, et al. XLNet: generalized autoregressive pretraining for language understanding[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-11-07].. |
| 19 | ZHANG L, DING J D, XU Y, et al. Weakly-supervised text classification based on keyword graph[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2021: 2803-2813. 10.18653/v1/2021.emnlp-main.222 |
| 20 | JIN Y P, BHATIA A, WANVARIE D. Seed word selection for weakly-supervised text classification with unsupervised error estimation[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop. Stroudsburg, PA: ACL, 2021: 112-118. 10.18653/v1/2021.naacl-srw.14 |
| 21 | XIAO H R, LIU X, SONG Y Q. Efficient path prediction for semi-supervised and weakly supervised hierarchical text classification[C]// Proceedings of the 2019 World Wide Web Conference. New York: ACM, 2019: 3370-3376. 10.1145/3308558.3313658 |
| 22 | LEE D H. Pseudo-label: the simple and efficient semi-supervised learning method for deep neural networks[C/OL]// Proceedings of the ICML 2013 Workshop on Challenges in Representation Learning. [2021-11-07].. |
| 23 | XIE J Y, GIRSHICK R, FARHADI A. Unsupervised deep embedding for clustering analysis[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 478-487. |
| 24 | GUO B Y, HAN S Q, HAN X, et al. Label confusion learning to enhance text classification models[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 12929-12936. 10.1609/aaai.v35i14.17529 |
| 25 | KIM Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2014: 1746-1751. 10.3115/v1/d14-1181 |
| 26 | LIU P F, QIU X P, HUANG X J. Recurrent neural network for text classification with multi-task learning[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2016: 2873-2879. 10.24963/ijcai.2017/473 |
| 27 | XIE Q Z, DAI Z H, HOVY E, et al. Unsupervised data augmentation for consistency training[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 6256-6268. |
| 28 | EDUNOV S, OTT M, AULI M, et al. Understanding back-translation at scale[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2018: 489-500. 10.18653/v1/d18-1045 |
| 29 | SU J L. WoBERT: Word-based Chinese BERT model — ZhuiyiAI[EB/OL]. [2021-11-07].. 10.1145/3468920.3468936 |
| 30 | WEI J, ZOU K. EDA: easy data augmentation techniques for boosting performance on text classification tasks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 6382-6388. 10.18653/v1/d19-1670 |
| [1] | Rui XIAO, Mingyi LIU, Zhiying TU, Zhongjie WANG. Personal event detection method based on text mining in social media [J]. Journal of Computer Applications, 2022, 42(11): 3513-3519. |
| [2] | Zenghui ZHANG, Gaoxia JIANG, Wenjian WANG. Label noise filtering method based on dynamic probability sampling [J]. Journal of Computer Applications, 2021, 41(12): 3485-3491. |
| [3] | LUO Jun, CHEN Lifei. Sentiment classification of incomplete data based on bidirectional encoder representations from transformers [J]. Journal of Computer Applications, 2021, 41(1): 139-144. |
| [4] | ZHANG Zenghui, JIANG Gaoxia, WANG Wenjian. Label noise filtering method based on local probability sampling [J]. Journal of Computer Applications, 2021, 41(1): 67-73. |
| [5] | LI Tingting, LYU Jia, FAN Weiya. Semi-supervised self-training positive and unlabeled learning based on new spy technology [J]. Journal of Computer Applications, 2019, 39(10): 2822-2828. |
| [6] | LYU Jia, LI Junnan. Self-training method based on semi-supervised clustering and data editing [J]. Journal of Computer Applications, 2018, 38(1): 110-115. |
| [7] | Zhi-sheng LI Yue-heng SUN Pi-lian HE Yue-xian HOU. Chinese question answering pattern learning based on self-training mechanism and Web [J]. Journal of Computer Applications, 2008, 28(6): 1575-1577. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||