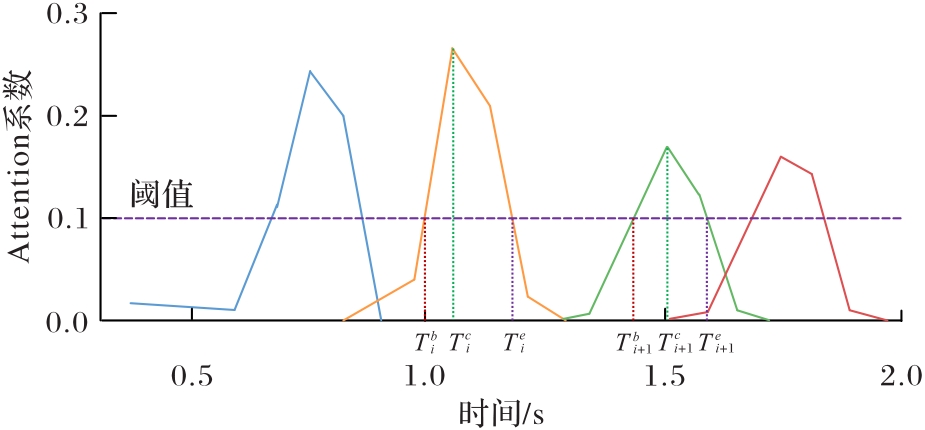
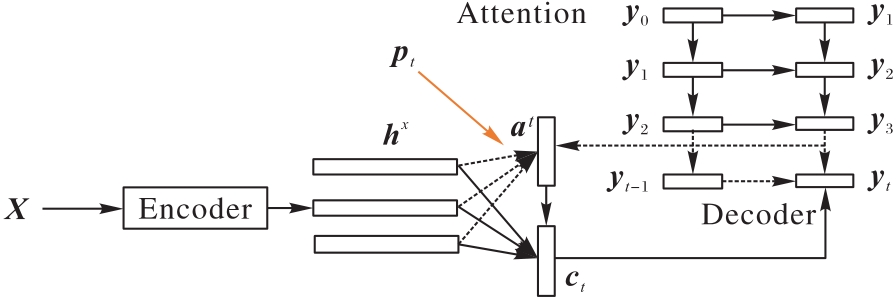
| 1 |
HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554. 10.1162/neco.2006.18.7.1527
|
| 2 |
PUNDAK G, SAINATH T N, PRABHAVALKAR R, et al. Deep context: end-to-end contextual speech recognition[C]// Proceedings of the 2018 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2018: 418-425. 10.1109/slt.2018.8639034
|
| 3 |
刘丙哲. 韵律信息在汉语语音识别中的应用[D]. 上海:复旦大学, 2002: 33-41.
|
|
LIU B Z. Application of prosodic information in Chinese speech recognition[D]. Shanghai: Fudan University, 2002: 33-41.
|
| 4 |
CHEN K, HASEGAWA-JOHNSON M, COHEN A, et al. Prosody dependent speech recognition on radio news corpus of American English[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(1):232-245. 10.1109/tsa.2005.853208
|
| 5 |
GADDE V R R. Modeling word durations[C]// Proceedings of the 6th International Conference on Spoken Language Processing. [S.l.]: International Speech Communication Association, 2000, 1: 601-604. 10.21437/icslp.2000-149
|
| 6 |
HANNUN A. Sequence modeling with CTC[J]. Distill, 2017, 2(11): No.8. 10.23915/distill.00008
|
| 7 |
ZHAO H B, HIGUCHI Y, OGAWA T, et al. An investigation of enhancing CTC model for triggered attention-based streaming ASR[EB/OL]. (2021-10-20) [2021-12-15]..
|
| 8 |
LEE J, WATANABE S. Intermediate loss regularization for CTC-based speech recognition[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2021: 6224-6228. 10.1109/icassp39728.2021.9414594
|
| 9 |
ZHOU W, ZHENG Z Y, SCHLÜTER R, et al. On language model integration for RNN transducer based speech recognition[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2022: 8407-8411. 10.1109/icassp43922.2022.9746948
|
| 10 |
KIM J, LEE J. Generalizing RNN-transducer to out-domain audio via sparse self-attention layers[C]// Proceedings of the Interspeech 2022. [S.l.]: International Speech Communication Association, 2022: 4123-4127. 10.21437/interspeech.2022-581
|
| 11 |
MORITZ N, HORI T, WATANABE S, et al. Sequence transduction with graph-based supervision[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2022: 7212-7216. 10.1109/icassp43922.2022.9747788
|
| 12 |
CHAN W, JAITLY N, LE Q V, et al. Listen, attend and spell[EB/OL]. (2015-08-20) [2021-12-15].. 10.1109/icassp.2016.7472621
|
| 13 |
JOSHI R, KANNAN V. Attention based end to end speech recognition for voice search in Hindi and English[C]// Proceedings of the 13th Annual Meeting of the Forum for Information Retrieval Evaluation. New York: ACM, 2021: 107-113. 10.1145/3503162.3503173
|
| 14 |
HE B, RADFAR M. The performance evaluation of attention-based neural ASR under mixed speech input[EB/OL]. (2021-08-03) [2021-12-15]..
|
| 15 |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780. 10.1162/neco.1997.9.8.1735
|
| 16 |
MEDSKER L R, JAIN L C. Recurrent neural networks[J]. Design and Applications, 2001, 5: 64-67.
|
| 17 |
ABDEL-HAMID O, DENG L, YU D. Exploring convolutional neural network structures and optimization techniques for speech recognition[C]// Proceedings of the Interspeech 2013. [S.l.]: International Speech Communication Association, 2013: 3366-3370. 10.21437/interspeech.2013-744
|
| 18 |
NEWATIA S, AGGARWAL R K. Convolutional neural network for ASR[C]// Proceedings of the 2nd International Conference on Electronics, Communication and Aerospace Technology. Piscataway: IEEE, 2018: 638-642. 10.1109/iceca.2018.8474688
|
| 19 |
GULATI A, QIN J, CHIU C C, et al. Conformer: convolution-augmented transformer for speech recognition[EB/OL]. (2020-05-16) [2021-12-15].. 10.21437/interspeech.2020-3015
|
| 20 |
ZEINELDEEN M, XU J J, LÜSCHER C, et al. Conformer-based hybrid ASR system for switchboard dataset[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2022: 7437-7441. 10.1109/icassp43922.2022.9746377
|
| 21 |
舒帆,屈丹,张文林,等. 采用长短时记忆网络的低资源语音识别方法[J]. 西安交通大学学报, 2017, 51(10):120-127. 10.7652/xjtuxb201710020
|
|
SHU F, QU D, ZHANG W L, et al. A speech recognition method using long short-term memory network in low resources[J]. Journal of Xi’an Jiaotong University, 2017, 51(10): 120-127. 10.7652/xjtuxb201710020
|


 ), Jianqing GAO1, Zhonghua FU2
), Jianqing GAO1, Zhonghua FU2