


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (4): 1036-1042.DOI: 10.11772/j.issn.1001-9081.2022030480
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Wenhao HU1, Jing LUO1, Xinhui TU2( )
)
Received:2022-04-13
Revised:2022-07-02
Accepted:2022-07-11
Online:2023-01-11
Published:2023-04-10
Contact:
Xinhui TU
About author:HU Wenhao, born in 1998, M. S. candidate. His research interests include information retrieval, natural language processing.Supported by:
胡文浩1, 罗景1, 涂新辉2()
通讯作者:
涂新辉
作者简介:胡文浩(1998—),男,湖北黄冈人,硕士研究生,主要研究方向:信息检索、自然语言处理;基金资助:CLC Number:
Wenhao HU, Jing LUO, Xinhui TU. Pseudo relevance feedback method for dense retrieval[J]. Journal of Computer Applications, 2023, 43(4): 1036-1042.
胡文浩, 罗景, 涂新辉. 面向稠密检索的伪相关反馈方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1036-1042.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022030480

Fig. 1 Architectures of two types of retrieval models

Fig. 2 Architecture of Dense-PRF model
| 数据集 | 前3个段落 | RepBERT与BM25 | |||
|---|---|---|---|---|---|
| α | β | ||||
| Robust04 | 1.0 | 0.6 | 0.4 | 0.2 | 1 |
| WT2G | 1.0 | 0.7 | 0.3 | 0.5 | 1 |
Tab. 1 Optimal parameters for score aggregation of top-3 paragraphs, RepBERT and BM25
| 数据集 | 前3个段落 | RepBERT与BM25 | |||
|---|---|---|---|---|---|
| α | β | ||||
| Robust04 | 1.0 | 0.6 | 0.4 | 0.2 | 1 |
| WT2G | 1.0 | 0.7 | 0.3 | 0.5 | 1 |
| 数据集 | 模型 | P@20 | NDCG@20 |
|---|---|---|---|
| Robust04 | BM25 | 0.363 1 | 0.424 0 |
| BM25+RM3 | 0.397 4 | 0.451 4 | |
| RepBERT | 0.310 4 | 0.376 3 | |
| RepBERT+PRF | 0.322 1 | 0.383 4 | |
| RepBERT+BM25 | 0.415 9 | 0.485 1 | |
Dense-PRF (RepBERT+BM25+PRF) | 0.432 5 | 0.498 3 | |
| WT2G | BM25 | 0.386 0 | 0.467 7 |
| BM25+RM3 | 0.434 0 | 0.508 4 | |
| RepBERT | 0.367 0 | 0.449 6 | |
| RepBERT+PRF | 0.385 0 | 0.463 1 | |
| RepBERT+BM25 | 0.449 0 | 0.546 5 | |
Dense-PRF (RepBERT+BM25+PRF) | 0.472 0 | 0.565 6 |
Tab. 2 Experimental results of different models on Robust04 and WT2G datasets
| 数据集 | 模型 | P@20 | NDCG@20 |
|---|---|---|---|
| Robust04 | BM25 | 0.363 1 | 0.424 0 |
| BM25+RM3 | 0.397 4 | 0.451 4 | |
| RepBERT | 0.310 4 | 0.376 3 | |
| RepBERT+PRF | 0.322 1 | 0.383 4 | |
| RepBERT+BM25 | 0.415 9 | 0.485 1 | |
Dense-PRF (RepBERT+BM25+PRF) | 0.432 5 | 0.498 3 | |
| WT2G | BM25 | 0.386 0 | 0.467 7 |
| BM25+RM3 | 0.434 0 | 0.508 4 | |
| RepBERT | 0.367 0 | 0.449 6 | |
| RepBERT+PRF | 0.385 0 | 0.463 1 | |
| RepBERT+BM25 | 0.449 0 | 0.546 5 | |
Dense-PRF (RepBERT+BM25+PRF) | 0.472 0 | 0.565 6 |
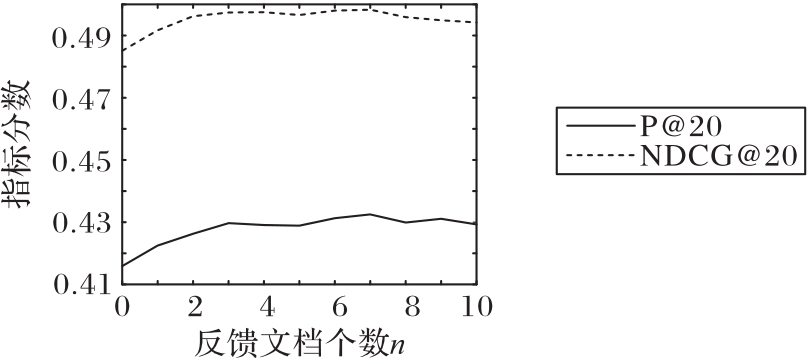
Fig. 3 Optimal results of different numbers of feedback documents on Robust04 dataset

Fig. 4 P@20 and NDCG@20 corresponding to different γ on Robust04 dataset
| 1 | 闫蓉,高光来. 基于检索结果排序的伪相关反馈[J]. 计算机应用, 2016, 36(8): 2099-2102, 2143. 10.11772/j.issn.1001-9081.2016.08.2099 |
| YAN R, GAO G L. Pseudo relevance feedback based on sorted retrieval result[J]. Journal of Computer Applications, 2016, 36(8): 2099-2102, 2143. 10.11772/j.issn.1001-9081.2016.08.2099 | |
| 2 | 闫蓉,高光来. 基于伪文档的伪相关反馈方法[J]. 中文信息学报, 2016, 30(6): 156-163, 172. 10.11772/j.issn.1001-9081.2016.08.2099 |
| YAN R, GAO G L. A new pseudo relevance feedback based on pseudo document[J]. Journal of Chinese Information Processing, 2016, 30(6): 156-163, 172. 10.11772/j.issn.1001-9081.2016.08.2099 | |
| 3 | ROCCHIO J. Relevance feedback in information retrieval[M]// SALTON G. The SMART Retrieval System: Experiments in Automatic Document Processing. Upper Saddle River, NJ: Prentice Hall, 1971: 313-323. |
| 4 | ABDUL-JALEEL N, ALLAN J, CROFT W B, et al. UMass at TREC 2004: novelty and HARD[C/OL]// Proceedings of the 13th Text REtrieval Conference [2022-02-11].. 10.21236/ada460118 |
| 5 | ZHAI C X, LAFFERTY J. Model-based feedback in the language modeling approach to information retrieval[C]// Proceedings of the 10th ACM International Conference on Information and Knowledge Management. New York: ACM, 2001: 403-410. 10.1145/502585.502654 |
| 6 | AMATI G, C J van RIJSBERGEN. Probabilistic models of information retrieval based on measuring the divergence from randomness[J]. ACM Transactions on Information Systems, 2002, 20(4): 357-389. 10.1145/582415.582416 |
| 7 | DIAZ F, MITRA B, CRASWELL N. Query expansion with locally-trained word embeddings[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2016: 367-377. 10.18653/v1/p16-1035 |
| 8 | ROY D, GANGULY D, BHATIA S, et al. Using word embeddings for information retrieval: how collection and term normalization choices affect performance[C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 1835-1838. 10.1145/3269206.3269277 |
| 9 | 黄名选. 关联模式挖掘与词向量学习融合的伪相关反馈查询扩展[J]. 电子学报, 2021, 49(7): 1305-1313. 10.12263/DZXB.20200654 |
| HUANG M X. Pseudo-relevance feedback query expansion based on the fusion of association pattern mining and word embedding learning[J]. Acta Electronica Sinica, 2021, 49(7): 1305-1313. 10.12263/DZXB.20200654 | |
| 10 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 11 | LIN J, NOGUEIRA R, YATES A. Pretrained transformers for text ranking: BERT and beyond[J]. Synthesis Lectures on Human Language Technologies, 2021, 14(4): 18-20. 10.2200/s01123ed1v01y202108hlt053 |
| 12 | YU H C, XIONG C Y, CALLAN J. Improving query representations for dense retrieval with pseudo relevance feedback[C]// Proceedings of the 30th ACM International Conference on Information and Knowledge Management. New York: ACM, 2021: 3592-3596. 10.1145/3459637.3482124 |
| 13 | XIONG L, XIONG C Y, LI Y, et al. Approximate nearest neighbor negative contrastive learning for dense text retrieval[EB/OL]. (2023-01-24) [2023-02-12].. |
| 14 | WANG X, MACDONALD C, TONELLOTTO N, et al. Pseudo-relevance feedback for multiple representation dense retrieval[C]// Proceedings of the 2021 ACM SIGIR International Conference on Theory of Information Retrieval. New York: ACM, 2021: 297-306. 10.1145/3471158.3472250 |
| 15 | KHATTAB O, ZAHARIA M. ColBERT: efficient and effective passage search via contextualized late interaction over BERT[C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 39-48. 10.1145/3397271.3401075 |
| 16 | QIU X P, SUN T X, XU Y G, et al. Pre-trained models for natural language processing: a survey[J]. Science China Technological Sciences, 2020, 63(10): 1872-1897. 10.1007/s11431-020-1647-3 |
| 17 | NOGUEIRA R, CHO K. Passage re-ranking with BERT[EB/OL]. (2020-04-14) [2022-03-12].. |
| 18 | ROBERTSON S E, WALKER S, BEAULIEU M M, et al. Okapi at TREC-4[C/OL]// Proceedings of the 4th Text REtrieval Conference [2022-03-11] . 10.1108/eum0000000007188 |
| 19 | AKKALYONCU YILMAZ Z, YANG W, ZHANG H T, et al. Cross-domain modeling of sentence-level evidence for document retrieval[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 3490-3496. 10.18653/v1/d19-1352 |
| 20 | MacAVANEY S, YATES A, COHAN A, et al. CEDR: contextualized embeddings for document ranking[C]// Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2019: 1101-1104. 10.1145/3331184.3331317 |
| 21 | LI C J, YATES A, MacAVANEY S, et al. PARADE: passage representation aggregation for document reranking[EB/OL]. (2021-07-10) [2022-03-12].. |
| 22 | KARPUKHIN V, OGUZ B, MIN S, et al. Dense passage retrieval for open-domain question answering[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 6769-6781. 10.18653/v1/2020.emnlp-main.550 |
| 23 | ZHAN J T, MAO J X, LIU Y Q, et al. RepBERT: contextualized text embeddings for first-stage retrieval[EB/OL]. (2020-07-20) [2022-03-12].. |
| 24 | DAI Z, CALLAN J. Context-aware document term weighting for ad-hoc search[C]// Proceedings of The Web Conference 2020. New York: ACM, 2020: 1897-1907. 10.1145/3366423.3380258 |
| 25 | NOGUEIRA R, YANG W, LIN J, et al. Document expansion by query prediction[EB/OL]. (2019-09-25) [2022-03-12].. |
| 26 | NOGUEIRA R, LIN J, EPISTEMIC A I. From doc2query to docTTTTTquery[EB/OL]. [2022-03-12].. |
| 27 | LI C J, SUN Y F, HE B, et al. NPRF: a neural pseudo relevance feedback framework for ad-hoc information retrieval[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2018: 4482-4491. 10.18653/v1/d18-1478 |
| 28 | ZHENG Z, HUI K, HE B, et al. BERT-QE: contextualized query expansion for document re-ranking[C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg, PA: ACL, 2020: 4718-4728. 10.18653/v1/2020.findings-emnlp.424 |
| 29 | VOORHEES E M. Overview of the TREC 2004 Robust Track. [C]// Proceedings of the 13th Text REetrieval Conference: TREC 2004. Gaithersburg, Maryland: National Institute of Standards and Technology, 2004: 52-69. 10.6028/nist.sp.500-261 |
| 30 | HAWKING D, VOORHEES E, CRASWELL N, et al. Overview of the TREC-8 Web track[C]// Proceedings of the 8th Text Retrieval Conference: TREC 1999. Gaithersburg, Maryland: National Institute of Standards and Technology, 1999: 131-150. 10.6028/nist.sp.500-242 |
| 31 | YANG P L, FANG H, LIN J. Anserini: enabling the use of Lucene for information retrieval research[C]// Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2017: 1253-1256. 10.1145/3077136.3080721 |
| [1] | Zhengyu ZHAO, Jing LUO, Xinhui TU. Information retrieval method based on multi-granularity semantic fusion [J]. Journal of Computer Applications, 2024, 44(6): 1775-1780. |
| [2] | Wangjing TANG, Bin XU, Meihan TONG, Meihuan HAN, Liming WANG, Qi ZHONG. Popular science text classification model enhanced by knowledge graph [J]. Journal of Computer Applications, 2022, 42(4): 1072-1078. |
| [3] | SHEN Li, LIU Hongxing, LI Yonghua. Automatic tracing method from Chinese document to source code based on version control [J]. Journal of Computer Applications, 2018, 38(10): 2996-3001. |
| [4] | ZHANG Ning, CHEN Qin. P2P loan default prediction model based on TF-IDF algorithm [J]. Journal of Computer Applications, 2018, 38(10): 3042-3047. |
| [5] | YUAN Dazeng, HE Mingxing, LI Xiao, ZENG Shengke. Private information retrieval protocol based on point function secret sharing [J]. Journal of Computer Applications, 2017, 37(2): 494-498. |
| [6] | LI Yan, ZHANG Bowen, HAO Hongwei. Query expansion with semantic vector representation [J]. Journal of Computer Applications, 2016, 36(9): 2526-2530. |
| [7] | SUN Xinyu, WU Jiang, PU Qiang. Relevance model estimation based on stable semantic clustering [J]. Journal of Computer Applications, 2016, 36(5): 1313-1318. |
| [8] | ZHANG YuanYuan ZHANG Qinyan JIANG Guanfu. Design and implementation of distributed retrieval system for electronic products information [J]. Journal of Computer Applications, 2013, 33(04): 1026-1030. |
| [9] | HU Xiao-sheng ZHONG Yong. Two-tier weighting aggregation ranking algorithm [J]. Journal of Computer Applications, 2012, 32(12): 3331-3334. |
| [10] | LU Qiang LI Xiao-lian WANG Zhi-guang. Survey on program algorithm recognition research [J]. Journal of Computer Applications, 2012, 32(10): 2863-2868. |
| [11] | LI Jin ZHANG Hua WU Hao-xiong XIANG Jun. BTopicMiner: domain-specific topic mining system for Chinese microblog [J]. Journal of Computer Applications, 2012, 32(08): 2346-2349. |
| [12] | LI Jin ZHANG Hua WU Hao-xiong XIANG Jun GU Xi-wu. Text classification model framework based on social annotation quality [J]. Journal of Computer Applications, 2012, 32(05): 1335-1339. |
| [13] | . Method for detecting changed geographical information based on information retrieval of Web pages [J]. Journal of Computer Applications, 2010, 30(4): 1132-1134. |
| [14] | . Annotating Web document in multi-granularity way by statistical topical model [J]. Journal of Computer Applications, 2010, 30(12): 3401-3406. |
| [15] | . Peer-to-peer based personalized Web information retrieval [J]. Journal of Computer Applications, 2010, 30(1): 114-117. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||