


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (8): 2406-2411.DOI: 10.11772/j.issn.1001-9081.2022071124
• Artificial intelligence • Previous Articles
Received:2022-08-01
Revised:2022-11-04
Accepted:2022-11-11
Online:2023-01-15
Published:2023-08-10
Contact:
Xiaoyan ZHANG
About author:DUAN Zhengyu, born in 1998, M. S. candidate. His research interests include deep learning, natural language processing.
通讯作者:
张小艳
作者简介:段正宇(1998—),男,安徽安庆人,硕士研究生,主要研究方向:深度学习、自然语言处理。
CLC Number:
Xiaoyan ZHANG, Zhengyu DUAN. Cross-lingual zero-resource named entity recognition model based on sentence-level generative adversarial network[J]. Journal of Computer Applications, 2023, 43(8): 2406-2411.
张小艳, 段正宇. 基于句级别GAN的跨语言零资源命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2406-2411.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022071124
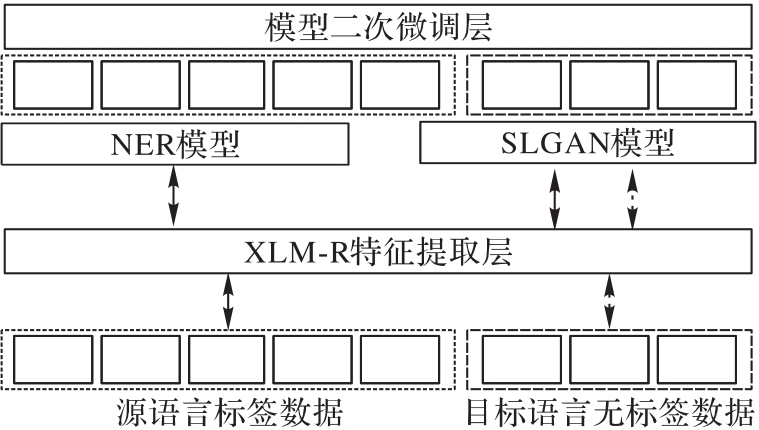
Fig. 1 Overall structure of SLGAN-XLM-R neural network model
| 语言 | 类型 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|
英语[en] (CoNLL2003) | 句子 | 14 987 | 3 466 | 3 684 |
| 实体 | 23 499 | 5 942 | 5 648 | |
德语[de] (CoNLL2003) | 句子 | 12 705 | 3 068 | 3 160 |
| 实体 | 11 851 | 4 833 | 3 673 | |
西班牙语[es] (CoNLL2002) | 句子 | 8 323 | 1 915 | 1 517 |
| 实体 | 18 798 | 4 351 | 3 558 | |
荷兰语[nl] (CoNLL2002) | 句子 | 15 806 | 2 895 | 5 195 |
| 实体 | 13 344 | 2 616 | 3 941 |
Tab. 1 Statistics of datasets
| 语言 | 类型 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|
英语[en] (CoNLL2003) | 句子 | 14 987 | 3 466 | 3 684 |
| 实体 | 23 499 | 5 942 | 5 648 | |
德语[de] (CoNLL2003) | 句子 | 12 705 | 3 068 | 3 160 |
| 实体 | 11 851 | 4 833 | 3 673 | |
西班牙语[es] (CoNLL2002) | 句子 | 8 323 | 1 915 | 1 517 |
| 实体 | 18 798 | 4 351 | 3 558 | |
荷兰语[nl] (CoNLL2002) | 句子 | 15 806 | 2 895 | 5 195 |
| 实体 | 13 344 | 2 616 | 3 941 |
| 实体类型 | 标注符号 | 实体描述 | 示例 |
|---|---|---|---|
| 人名 | B-PER | 人名开始单词 | 终(B-PER) 南(I-PER) 山(I-PER) |
| I-PER | 人名其他单词 | ||
组织或 公司 | B-ORG | 组织名的开始单词 | 华(B-ORG) 为(I-ORG) |
| I-ORG | 组织名的其他单词 | ||
| 地点 | B-LOC | 地名开始单词 | 西(B-LOC) 安(I-LOC) 市(I-LOC) |
| I-LOC | 地名结束单词 | ||
其他 实体 | B-MISC | 其他实体开始单词 | 疫(B-MISC) 苗(I-MISC) |
| I-MISC | 其他实体结束单词 | ||
| 非实体 | O | 其他非实体 | 你(O)好(O) |
Tab. 2 Named entity labeling scheme
| 实体类型 | 标注符号 | 实体描述 | 示例 |
|---|---|---|---|
| 人名 | B-PER | 人名开始单词 | 终(B-PER) 南(I-PER) 山(I-PER) |
| I-PER | 人名其他单词 | ||
组织或 公司 | B-ORG | 组织名的开始单词 | 华(B-ORG) 为(I-ORG) |
| I-ORG | 组织名的其他单词 | ||
| 地点 | B-LOC | 地名开始单词 | 西(B-LOC) 安(I-LOC) 市(I-LOC) |
| I-LOC | 地名结束单词 | ||
其他 实体 | B-MISC | 其他实体开始单词 | 疫(B-MISC) 苗(I-MISC) |
| I-MISC | 其他实体结束单词 | ||
| 非实体 | O | 其他非实体 | 你(O)好(O) |

Fig. 2 Statistics of the number of entities in each dataset
| 类别 | 样例 |
|---|---|
| 原始句子 | EU rejects German call to boycott British lamb |
| 原始标签 | B-ORG O B-MISC O O O B-MISC O O |
| 预处理后句子 | _EU_rejects_German_call_to_boycott_British_lamb |
预处理后 实体标签 | B-ORG O O O B-MISC O O O O O B-MISC O O O O |
预处理后 语言标签 | 0 |
Tab. 3 Example of data pre-processing
| 类别 | 样例 |
|---|---|
| 原始句子 | EU rejects German call to boycott British lamb |
| 原始标签 | B-ORG O B-MISC O O O B-MISC O O |
| 预处理后句子 | _EU_rejects_German_call_to_boycott_British_lamb |
预处理后 实体标签 | B-ORG O O O B-MISC O O O O O B-MISC O O O O |
预处理后 语言标签 | 0 |
| 模型 | 德语 | 西班牙语 | 荷兰语 | 平均值 |
|---|---|---|---|---|
| 文献[ | 48.12 | 60.55 | 61.56 | 56.74 |
| 文献[ | 58.50 | 65.10 | 65.40 | 63.00 |
| 文献[ | 57.23 | 64.10 | 63.37 | 61.57 |
| 文献[ | 61.50 | 73.50 | 69.90 | 68.30 |
| 文献[ | 65.24 | 75.93 | 74.61 | 71.93 |
| 文献[ | 69.56 | 74.96 | 77.57 | 73.57 |
| 文献[ | 71.90 | 74.30 | 77.60 | 74.60 |
| 本文模型(SLGAN+NER) | 69.51 | 78.32 | 78.71 | 75.51 |
| 本文模型(SLGAN-XLM-R) | 72.70 | 79.42 | 80.03 | 76.00 |
Tab. 4 F1 scores comparison of recognition results of different cross-lingual language models
| 模型 | 德语 | 西班牙语 | 荷兰语 | 平均值 |
|---|---|---|---|---|
| 文献[ | 48.12 | 60.55 | 61.56 | 56.74 |
| 文献[ | 58.50 | 65.10 | 65.40 | 63.00 |
| 文献[ | 57.23 | 64.10 | 63.37 | 61.57 |
| 文献[ | 61.50 | 73.50 | 69.90 | 68.30 |
| 文献[ | 65.24 | 75.93 | 74.61 | 71.93 |
| 文献[ | 69.56 | 74.96 | 77.57 | 73.57 |
| 文献[ | 71.90 | 74.30 | 77.60 | 74.60 |
| 本文模型(SLGAN+NER) | 69.51 | 78.32 | 78.71 | 75.51 |
| 本文模型(SLGAN-XLM-R) | 72.70 | 79.42 | 80.03 | 76.00 |
| 模型 | 训练方式 | 德语 | 西班牙语 | 荷兰语 |
|---|---|---|---|---|
| mBERT | 直接微调 | 62.34 | 69.70 | 68.52 |
| 对抗训练 | 63.97 | 72.43 | 71.49 | |
| 二次微调 | 66.30 | 74.46 | 72.96 | |
| XLM-R | 直接微调 | 67.32 | 74.04 | 76.98 |
| 对抗训练 | 69.51 | 78.32 | 78.71 | |
| 二次微调 | 72.70 | 79.42 | 80.03 |
Tab.5 F1 scores comparison of recognition results of different PLMs
| 模型 | 训练方式 | 德语 | 西班牙语 | 荷兰语 |
|---|---|---|---|---|
| mBERT | 直接微调 | 62.34 | 69.70 | 68.52 |
| 对抗训练 | 63.97 | 72.43 | 71.49 | |
| 二次微调 | 66.30 | 74.46 | 72.96 | |
| XLM-R | 直接微调 | 67.32 | 74.04 | 76.98 |
| 对抗训练 | 69.51 | 78.32 | 78.71 | |
| 二次微调 | 72.70 | 79.42 | 80.03 |
| 1 | BANERJEE P S, CHAKRABORTY B, TRIPATHI D, et al. A information retrieval based on question and answering and NER for unstructured information without using SQL[J]. Wireless Personal Communications, 2019, 108(3): 1909-1931. 10.1007/s11277-019-06501-z |
| 2 | FABBRI A, NG P, WANG Z G, et al. Template-based question generation from retrieved sentences for improved unsupervised question answering[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 4508-4513. 10.18653/v1/2020.acl-main.413 |
| 3 | NALLAPATI R, ZHOU B W, DOS SANTOS C, et al. Abstractive text summarization using sequence-to-sequence RNNs and beyond[C]// Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. Stroudsburg, PA: ACL, 2016: 280-290. 10.18653/v1/k16-1028 |
| 4 | KRUENGKRAI C, NGUYEN T H, ALJUNIED S M, et al. Improving low-resource named entity recognition using joint sentence and token labeling[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 5898-5905. 10.18653/v1/2020.acl-main.523 |
| 5 | SUN L F, YI L H, CHEN H X, et al. Back attention knowledge transfer for low-resource named entity recognition[EB/OL]. (2021-06-18) [2022-09-20].. 10.5121/csit.2022.120625 |
| 6 | LIU L L, DING B S, BING L D, et al. MulDA: a multilingual data augmentation framework for low-resource cross-lingual NER[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021: 5834-5846. 10.18653/v1/2021.acl-long.453 |
| 7 | JAIN A, PARANJAPE B, LIPTON Z C. Entity projection via machine translation for cross-lingual NER[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 1083-1092. 10.18653/v1/d19-1100 |
| 8 | DING B S, LIU L L, BING L D, et al. DAGA: data augmentation with a generation approach for low-resource tagging tasks[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 6045-6057. 10.18653/v1/2020.emnlp-main.488 |
| 9 | BARI M S, JOTY S R, JWALAPURAM P. Zero-resource cross-lingual named entity recognition[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 7415-7423. 10.1609/aaai.v34i05.6237 |
| 10 | KEUNG P, LU Y C, BHARDWAJ V. Adversarial learning with contextual embeddings for zero-resource cross-lingual classification and NER[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 1355-1360. 10.18653/v1/d19-1138 |
| 11 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 12 | WU Q H, LIN Z J, WANG G X, et al. Enhanced meta-learning for cross-lingual named entity recognition with minimal resources[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 9274-9281. 10.1609/aaai.v34i05.6466 |
| 13 | PFEIFFER J, VULIĆ I, GUREVYCH I, et al. MAD-X: an adapter-based framework for multi-task cross-lingual transfer[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 7654-7673. 10.18653/v1/2020.emnlp-main.617 |
| 14 | WU Q H, LIN Z J, KARLSSON B F, et al. Single-/multi-source cross-lingual NER via teacher-student learning on unlabeled data in target language[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 6505-6514. 10.18653/v1/2020.acl-main.581 |
| 15 | WU Q H, LIN Z J, KARLSSON B F, et al. UniTrans: unifying model transfer and data transfer for cross-lingual named entity recognition with unlabeled data[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020:3926-3932. 10.24963/ijcai.2020/543 |
| 16 | YI H X, CHENG J. Zero-shot entity recognition via multi-source projection and unlabeled data[J]. IOP Conference Series: Earth and Environmental Science, 2021, 693: No.012084. 10.1088/1755-1315/693/1/012084 |
| 17 | FU Y W, LIN N K, YANG Z Y, et al. A dual-contrastive framework for low-resource cross-lingual named entity recognition[EB/OL]. (2022-04-02) [2022-09-20].. 10.18653/v1/2022.findings-emnlp.132 |
| 18 | CONNEAU A, KHANDELWAL K, GOYAL N, et al. Unsupervised cross-lingual representation learning at scale[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 8440-8451. 10.18653/v1/2020.acl-main.747 |
| 19 | TJONG KIM SANG E. Introduction to the CoNLL-2002 shared task: language-independent named entity recognition[C/OL]// Proceedings of the 6th Conference on Natural Language Learning 2002 [2022-09-20].. 10.3115/1118853.1118877 |
| 20 | TJONG KIM SANG E, DE MEULDER F. Introduction to the CoNLL-2003 shared task: language-independent named entity recognition[C/OL]// Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL 2003 [2022-09-20].. 10.3115/1119176.1119195 |
| 21 | CONNEAU A, LAMPLE G. Cross-lingual language model pretraining[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 7059-7069. 10.18653/v1/d18-1269 |
| 22 | LIU Y H, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. (2019-07-26) [2022-09-20].. |
| 23 | 王倩,李茂西,吴水秀,等. 基于跨语种预训练语言模型XLM-R的神经机器翻译方法[J]. 北京大学学报(自然科学版), 2022, 58(1):29-36. |
| WANG Q, LI M X, WU S X, et al. Neural machine translation based on XLM-R cross-lingual pre-training language model[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2022, 58(1):29-36. | |
| 24 | CHEN W L, JIANG H Q, WU Q H, et al. AdvPicker: effectively leveraging unlabeled data via adversarial discriminator for cross-lingual NER[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021: 743-753. 10.18653/v1/2021.acl-long.61 |
| 25 | WU Y H, SCHUSTER M, CHEN Z F, et al. Google’s neural machine translation system: bridging the gap between human and machine translation[EB/OL]. (2016-10-08) [2022-09-20].. |
| 26 | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization[EB/OL]. (2019-01-04) [2022-09-20].. |
| 27 | TSAI C T, MAYHEW S, ROTH D. Cross-lingual named entity recognition via wikification[C]// Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. Stroudsburg, PA: ACL, 2016: 219-228. 10.18653/v1/k16-1022 |
| 28 | NI J, DINU G, FLORIAN R. Weakly supervised cross-lingual named entity recognition via effective annotation and representation projection[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2017: 1470-1480. 10.18653/v1/p17-1135 |
| 29 | MAYHEW S, TSAI C T, ROTH D. Cheap translation for cross-lingual named entity recognition[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017: 2536-2545. 10.18653/v1/d17-1269 |
| 30 | WU S J, DREDZE M. Beto, Bentz, Becas: the surprising cross-lingual effectiveness of BERT[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 833-844. 10.18653/v1/d19-1077 |
| [1] | Jingsheng LEI, Kaijun LA, Shengying YANG, Yi WU. Joint entity and relation extraction based on contextual semantic enhancement [J]. Journal of Computer Applications, 2023, 43(5): 1438-1444. |
| [2] | Lifeng SHI, Zhengwei NI. Dialogue state tracking model based on slot correlation information extraction [J]. Journal of Computer Applications, 2023, 43(5): 1430-1437. |
| [3] | Ming XU, Linhao LI, Qiaoling QI, Liqin WANG. Abductive reasoning model based on attention balance list [J]. Journal of Computer Applications, 2023, 43(2): 349-355. |
| [4] | Guanyou XU, Weisen FENG. Python named entity recognition model based on transformer [J]. Journal of Computer Applications, 2022, 42(9): 2693-2700. |
| [5] | Jie HU, Yan HU, Mengchi LIU, Yan ZHANG. Chinese named entity recognition based on knowledge base entity enhanced BERT model [J]. Journal of Computer Applications, 2022, 42(9): 2680-2685. |
| [6] | Yayao ZUO, Haoyu CHEN, Zhiran CHEN, Jiawei HONG, Kun CHEN. Named entity recognition method combining multiple semantic features [J]. Journal of Computer Applications, 2022, 42(7): 2001-2008. |
| [7] | Yi ZHANG, Shuangsheng WANG, Bin HE, Peiming YE, Keqiang LI. Named entity recognition method of elementary mathematical text based on BERT [J]. Journal of Computer Applications, 2022, 42(2): 433-439. |
| [8] | Yaming LI, Kai XING, Hongwu DENG, Zhiyong WANG, Xuan HU. Derivative-free few-shot learning based performance optimization method of pre-trained models with convolution structure [J]. Journal of Computer Applications, 2022, 42(2): 365-374. |
| [9] | Chunming MA, Xiuhong LI, Zhe LI, Huiru WANG, Dan YANG. Survey of event extraction [J]. Journal of Computer Applications, 2022, 42(10): 2975-2989. |
| [10] | Lanlan ZENG, Yisong WANG, Panfeng CHEN. Named entity recognition based on BERT and joint learning for judgment documents [J]. Journal of Computer Applications, 2022, 42(10): 3011-3017. |
| [11] | LIU Ruiheng, YE Xia, YUE Zengying. Review of pre-trained models for natural language processing tasks [J]. Journal of Computer Applications, 2021, 41(5): 1236-1246. |
| [12] | LI Huihui, YAN Kun, ZHANG Lixuan, LIU Wei, LI Zhi. Circular pointer instrument recognition system based on MobileNetV2 [J]. Journal of Computer Applications, 2021, 41(4): 1214-1220. |
| [13] | YANG Weiya, YU Zhengtao, GAO Shengxiang, SONG Ran. Chinese-Vietnamese news topic discovery method based on cross-language neural topic model [J]. Journal of Computer Applications, 2021, 41(10): 2879-2884. |
| [14] | Yue WANG, Mengxuan WANG, Sheng ZHANG, Wen DU. Alarm text named entity recognition based on BERT [J]. Journal of Computer Applications, 2020, 40(2): 535-540. |
| [15] | WANG Kun, ZHENG Yi, FANG Shuya, LIU Shouyin. Long text aspect-level sentiment analysis based on text filtering and improved BERT [J]. Journal of Computer Applications, 2020, 40(10): 2838-2844. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||