


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (7): 2010-2016.DOI: 10.11772/j.issn.1001-9081.2022071133
• The 39th CCF National Database Conference (NDBC 2022) • Previous Articles
Menglin HUANG1, Lei DUAN1,2( ), Yuanhao ZHANG1, Peiyan WANG1, Renhao LI1
), Yuanhao ZHANG1, Peiyan WANG1, Renhao LI1
Received:2022-07-12
Revised:2022-08-11
Accepted:2022-08-22
Online:2022-09-23
Published:2023-07-10
Contact:
Lei DUAN
About author:HUANG Menglin, born in 1998, M. S. candidate. Her research interests include natural language processing.Supported by:
黄梦林1, 段磊1,2(), 张袁昊1, 王培妍1, 李仁昊1
通讯作者:
段磊
作者简介:黄梦林(1998—),女,重庆人,硕士研究生,CCF会员,主要研究方向:自然语言处理;基金资助:CLC Number:
Menglin HUANG, Lei DUAN, Yuanhao ZHANG, Peiyan WANG, Renhao LI. Prompt learning based unsupervised relation extraction model[J]. Journal of Computer Applications, 2023, 43(7): 2010-2016.
黄梦林, 段磊, 张袁昊, 王培妍, 李仁昊. 基于Prompt学习的无监督关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2010-2016.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022071133
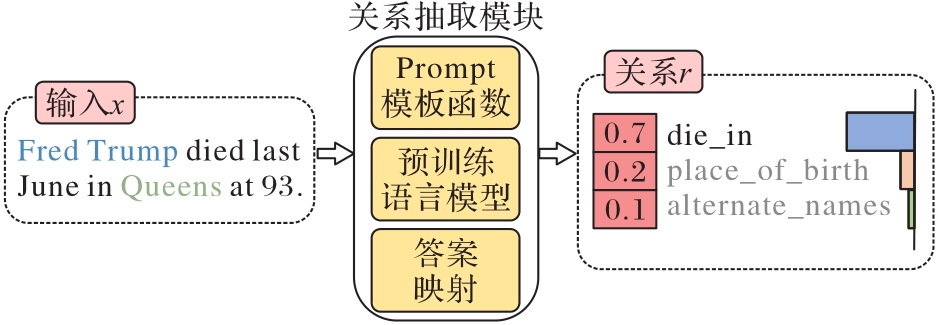
Fig. 1 Framework of relation extraction module
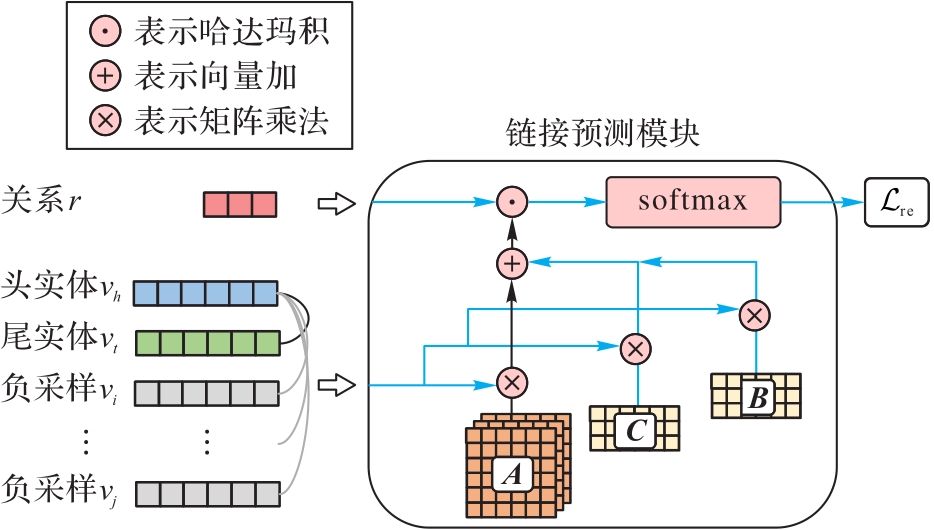
Fig. 2 Framework of link prediction module
| 模型 | B-cubed | V-measure | ARI | ||||
|---|---|---|---|---|---|---|---|
| F1 | Pre | Rec | F1 | Hom | Com | ||
| RelLDA | 29.1 | 24.8 | 35.2 | 30.0 | 26.1 | 35.1 | 13.3 |
| SelfORE | 41.4 | 38.5 | 44.7 | 40.4 | 37.8 | 43.3 | 35.0 |
| EIORE | 43.1 | 48.4 | 38.8 | 42.7 | 37.7 | 49.2 | 34.5 |
| HiURE | 45.3 | 40.2 | 51.8 | 45.9 | 40.0 | 53.8 | 38.6 |
| March | 37.5 | 31.1 | 47.4 | 38.7 | 32.6 | 47.8 | 27.6 |
| Simon* | 32.5 | 28.2 | 38.4 | 31.5 | 27.1 | 37.7 | 22.2 |
| Simon | 39.4 | 32.2 | 50.7 | 38.3 | 32.2 | 47.2 | 33.8 |
| EType* | 41.8 | 30.1 | 68.9 | 38.1 | 28.3 | 58.5 | 30.2 |
| EType | 41.9 | 31.3 | 59.0 | 41.3 | 33.6 | 53.9 | 30.5 |
| UREVA | 43.1 | — | — | 42.0 | — | — | 31.6 |
| PURE | 46.4 | 35.3 | 61.7 | 47.1 | 38.0 | 62.1 | 31.9 |
Tab. 1 Results of relation extraction on NYT dataset
| 模型 | B-cubed | V-measure | ARI | ||||
|---|---|---|---|---|---|---|---|
| F1 | Pre | Rec | F1 | Hom | Com | ||
| RelLDA | 29.1 | 24.8 | 35.2 | 30.0 | 26.1 | 35.1 | 13.3 |
| SelfORE | 41.4 | 38.5 | 44.7 | 40.4 | 37.8 | 43.3 | 35.0 |
| EIORE | 43.1 | 48.4 | 38.8 | 42.7 | 37.7 | 49.2 | 34.5 |
| HiURE | 45.3 | 40.2 | 51.8 | 45.9 | 40.0 | 53.8 | 38.6 |
| March | 37.5 | 31.1 | 47.4 | 38.7 | 32.6 | 47.8 | 27.6 |
| Simon* | 32.5 | 28.2 | 38.4 | 31.5 | 27.1 | 37.7 | 22.2 |
| Simon | 39.4 | 32.2 | 50.7 | 38.3 | 32.2 | 47.2 | 33.8 |
| EType* | 41.8 | 30.1 | 68.9 | 38.1 | 28.3 | 58.5 | 30.2 |
| EType | 41.9 | 31.3 | 59.0 | 41.3 | 33.6 | 53.9 | 30.5 |
| UREVA | 43.1 | — | — | 42.0 | — | — | 31.6 |
| PURE | 46.4 | 35.3 | 61.7 | 47.1 | 38.0 | 62.1 | 31.9 |
| 模型 | B-cubed F1 | V-measure F1 | ARI |
|---|---|---|---|
| SelfORE* | 14.5 | 5.1 | 3.2 |
| Simon* | 18.7 | 8.6 | 1.5 |
| Simon | 22.3 | 11.2 | 9.7 |
| UREVA | 24.5 | 13.8 | 11.7 |
| PURE | 26.6 | 29.0 | 13.2 |
Tab. 2 Results of relation extraction on SemEval dataset
| 模型 | B-cubed F1 | V-measure F1 | ARI |
|---|---|---|---|
| SelfORE* | 14.5 | 5.1 | 3.2 |
| Simon* | 18.7 | 8.6 | 1.5 |
| Simon | 22.3 | 11.2 | 9.7 |
| UREVA | 24.5 | 13.8 | 11.7 |
| PURE | 26.6 | 29.0 | 13.2 |
| 是否微调PLM | 模型 | B-cubed F1 | V-measure F1 | ARI |
|---|---|---|---|---|
| 否 | PUREmax | 19.5 | 10.9 | 6.3 |
| PUREcls | 33.3 | 34.9 | 20.2 | |
| 是 | PUREmax_finetune | 35.2 | 36.5 | 23.7 |
| PUREcls_finetune | 42.7 | 46.2 | 25.9 | |
| 否 | PURE | 46.4 | 47.1 | 31.9 |
Tab. 3 Results of ablation experiments on NYT dataset
| 是否微调PLM | 模型 | B-cubed F1 | V-measure F1 | ARI |
|---|---|---|---|---|
| 否 | PUREmax | 19.5 | 10.9 | 6.3 |
| PUREcls | 33.3 | 34.9 | 20.2 | |
| 是 | PUREmax_finetune | 35.2 | 36.5 | 23.7 |
| PUREcls_finetune | 42.7 | 46.2 | 25.9 | |
| 否 | PURE | 46.4 | 47.1 | 31.9 |
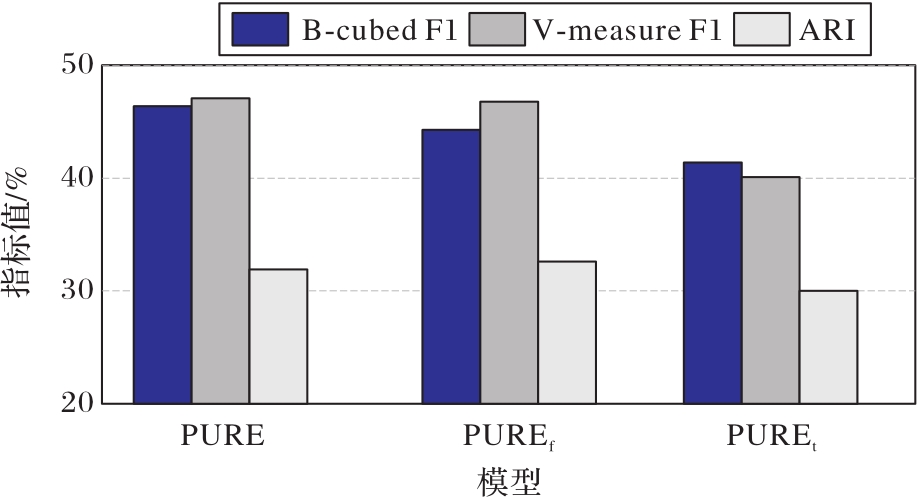
Fig. 3 Experimental results of different Prompt template functions
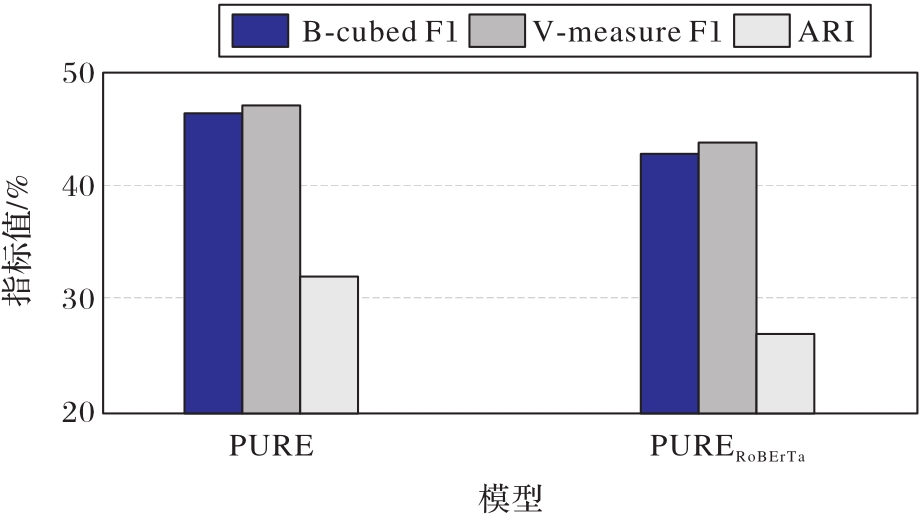
Fig. 4 Experimental results of different pre-trained language models
| 关系1 | 关系8 | 关系10 |
|---|---|---|
| /business/person/company | /people/person/place_lived | /location/location/containedby |
| /business/shareholder/major_shareholder_of | /people/person/place_of_death | /location/neighborhood/neighborhood_of |
| /business/advisor/companies_advised | /people/person/place_of_birt | /location/hud_county_place/county |
| /book/author/works_written | /location/location/containedby | /book/book_edition/place_of_publication |
| /organization/founder/organizations_founded | /book/edition/place_of_publication | /transportation/road/major_cities |
| /music/artist/label | /music/artist/origin | /geography/river/cities |
| /visual/artist/associated_periods_or_movements | /location/hud_county_place/county | /book/written_work/subjects |
Tab. 4 Examples of real meaning of high-frequency real relation in predicted relations
| 关系1 | 关系8 | 关系10 |
|---|---|---|
| /business/person/company | /people/person/place_lived | /location/location/containedby |
| /business/shareholder/major_shareholder_of | /people/person/place_of_death | /location/neighborhood/neighborhood_of |
| /business/advisor/companies_advised | /people/person/place_of_birt | /location/hud_county_place/county |
| /book/author/works_written | /location/location/containedby | /book/book_edition/place_of_publication |
| /organization/founder/organizations_founded | /book/edition/place_of_publication | /transportation/road/major_cities |
| /music/artist/label | /music/artist/origin | /geography/river/cities |
| /visual/artist/associated_periods_or_movements | /location/hud_county_place/county | /book/written_work/subjects |
| 1 | 李冬梅,张扬,李东远,等.实体关系抽取方法研究综述[J].计算机研究与发展, 2020, 57(7): 1424-1448. 10.7544/issn1000-1239.2020.20190358 |
| LI D M, ZHANG Y, LI D Y, et al. Review of entity relation extraction methods[J]. Journal of Computer Research and Development, 2020, 57(7): 1424-1448. 10.7544/issn1000-1239.2020.20190358 | |
| 2 | CHEN T, SHI H C, LIU L Y, et al. Empower distantly supervised relation extraction with collaborative adversarial training [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 12675-12682. 10.1609/aaai.v35i14.17501 |
| 3 | YAO L M, HAGHIGHI A, RIEDEL S, et al. Structured relation discovery using generative models [C]// Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2011: 1456-1466. |
| 4 | MARCHEGGIANI D, TITOV I. Discrete-state variational autoencoders for joint discovery and factorization of relations[J]. Transactions of the Association for Computational Linguistics, 2016, 4: 231-244. 10.1162/tacl_a_00095 |
| 5 | SIMON É, GUIGUE V, PIWOWARSKI B. Unsupervised information extraction: regularizing discriminative approaches with relation distribution losses [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 1378-1387. 10.18653/v1/p19-1133 |
| 6 | TRAN T T, LE P, ANANIADOU S. Revisiting unsupervised relation extraction [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 7498-7505. 10.18653/v1/2020.acl-main.669 |
| 7 | YUAN C H, ELDARDIRY H. Unsupervised relation extraction: a variational autoencoder approach [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2021: 1929-1938. 10.18653/v1/2021.emnlp-main.147 |
| 8 | LIU P F, YUAN W Z, FU J L, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing[EB/OL]. (2021-07-28) [2022-05-22]. . 10.1145/3560815 |
| 9 | HU X, ZHANG C, XU Y, et al. SelfORE: self-supervised relational feature learning for open relation extraction [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 3673-3682. 10.18653/v1/2020.emnlp-main.299 |
| 10 | LIU F C, YAN L Y, LIN H Y, et al. Element intervention for open relation extraction [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021: 4683-4693. 10.18653/v1/2021.acl-long.361 |
| 11 | LIU S L, HU X M, ZHANG C W, et al. HiURE: hierarchical exemplar contrastive learning for unsupervised relation extraction [C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2022: 5970-5980. 10.18653/v1/2022.naacl-main.437 |
| 12 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 13 | LIU Y H, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. (2019-07-26) [2022-05-06]. . |
| 14 | PETRONI F, ROCKTÄSCHEL T, RIEDEL S, et al. Language models as knowledge bases? [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 2463-2473. 10.18653/v1/d19-1250 |
| 15 | GOSWAMI A, BHAT A, OHANA H, et al. Unsupervised relation extraction from language models using constrained cloze completion [C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg, PA: ACL, 2020: 1263-1276. 10.18653/v1/2020.findings-emnlp.113 |
| 16 | CHEN X, ZHANG N Y, XIE X, et al. KnowPrompt: knowledge-aware prompt-tuning with synergistic optimization for relation extraction [C]// Proceedings of the ACM Web Conference 2022. New York: ACM, 2022: 2778-2788. 10.1145/3485447.3511998 |
| 17 | NICKEL M, TRESP V, KRIEGEL H P. A three-way model for collective learning on multi-relational data [C]// Proceedings of the 28th International Conference on Machine Learning. Madison, WI: Omnipress, 2011: 809-816. 10.1145/2187836.2187874 |
| 18 | RIEDEL S, YAO L M, McCALLUM A, et al. Relation extraction with matrix factorization and universal schemas [C]// Proceedings of the 2013 Conference of the North American Chapter of the Association of Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2013: 74-84. |
| 19 | SANDHAUS E. The New York times annotated corpus[DS/OL]. [2022-05-11]. . 10.1007/978-3-319-64158-4_4 |
| 20 | HENDRICKX I, KIM S N, KOZAREVA Z, et al. SemEval-2010 Task 8: multi-way classification of semantic relations between pairs of nominal [C]// Proceedings of the 5th International Workshop on Semantic Evaluation. Stroudsburg, PA: ACL, 2010: 33-38. 10.3115/1621969.1621986 |
| 21 | BAGGA A, BALDWIN B. Entity-based cross-document coreferencing using the vector space model [C]// Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Volume 1. New Brunswick, NJ: ACL, 1998: 79-85. 10.3115/980845.980859 |
| 22 | ROSENBERG A, HIRSCHBERG J. V-measure: a conditional entropy-based external cluster evaluation measure [C]// Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg, PA: ACL, 2007: 410-420. |
| 23 | HUBERT L, ARABIE P. Comparing partitions[J]. Journal of Classification, 1985, 2(1): 193-218. 10.1007/bf01908075 |
| 24 | BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022. |
| 25 | ZENG D J, LIU K, CHEN Y B, et al. Distant supervision for relation extraction via piecewise convolutional neural networks [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 1753-1762. 10.18653/v1/d15-1203 |
| 26 | ROMANO S, VINH N X, BAILEY J, et al. Adjusting for chance clustering comparison measures[J]. Journal of Machine Learning Research, 2016, 17: 4635-4666. 10.5715/jnlp.4.3_1 |
| [1] | Zhe XU, Zhihong WANG, Cunyu SHAN, Yaru SUN, Ying YANG. Unsupervised face forgery video detection based on reconstruction error [J]. Journal of Computer Applications, 2023, 43(5): 1571-1577. |
| [2] | Mengting GE, Minghua WAN. Feature extraction model based on neighbor supervised locally invariant robust principal component analysis [J]. Journal of Computer Applications, 2023, 43(4): 1013-1020. |
| [3] | Yiyang GUO, Jiong YU, Xusheng DU, Shaozhi YANG, Ming CAO. Outlier detection algorithm based on autoencoder and ensemble learning [J]. Journal of Computer Applications, 2022, 42(7): 2078-2087. |
| [4] | LIU Ruiheng, YE Xia, YUE Zengying. Review of pre-trained models for natural language processing tasks [J]. Journal of Computer Applications, 2021, 41(5): 1236-1246. |
| [5] | SUN Heli, SUN Yuzhu, ZHANG Xiaoyun. Event description generation based on generative adversarial network [J]. Journal of Computer Applications, 2021, 41(5): 1256-1261. |
| [6] | GUO Yicun, CHEN Huahui. Survey on online hashing algorithm [J]. Journal of Computer Applications, 2021, 41(4): 1106-1112. |
| [7] | TU Hongyan, ZHANG Ting, XIA Pengfei, DU Yi. Reconstruction method for uncertain spatial information based on improved variational auto-encoder [J]. Journal of Computer Applications, 2021, 41(10): 2959-2963. |
| [8] | WANG Zhiyuan, JIANG Ailian, MUHAMMAD Osman. Unsupervised feature selection method based on regularized mutual representation [J]. Journal of Computer Applications, 2020, 40(7): 1896-1900. |
| [9] | YI Dongyi, DENG Genqiang, DONG Chaoxiong, ZHU Miaomiao, LYU Zhouping, ZHU Suisong. Medical insurance fraud detection algorithm based on graph convolutional neural network [J]. Journal of Computer Applications, 2020, 40(5): 1272-1277. |
| [10] | SONG Yan, YIN Jun. Multi-view spectral clustering algorithm based on shared nearest neighbor [J]. Journal of Computer Applications, 2020, 40(11): 3211-3216. |
| [11] | LIU Xiao, WANG Xiaoguo. Dense subgraph based telecommunication fraud detection approach in bank [J]. Journal of Computer Applications, 2019, 39(4): 1214-1219. |
| [12] | YANG Donghai, LIN Minmin, ZHANG Wenjie, YANG Jingmin. Image classification learning via unsupervised mixed-order stacked sparse autoencoder [J]. Journal of Computer Applications, 2019, 39(12): 3420-3425. |
| [13] | GONG Yonghong, ZHENG Wei, WU Lin, TAN Malong, YU Hao. Unsupervised feature selection algorithm based on self-paced learning [J]. Journal of Computer Applications, 2018, 38(10): 2856-2861. |
| [14] | FANG Ning, ZHOU Yu, YE Qingwei, LI Yugang. Modal parameter identification of vibration signal based on unsupervised learning convolutional neural network [J]. Journal of Computer Applications, 2017, 37(3): 786-790. |
| [15] | DENG Jiayuan, JI Donghong, FEI Chaoqun, REN Yafeng. Twitter text normalization based on unsupervised learning algorithm [J]. Journal of Computer Applications, 2016, 36(7): 1887-1892. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||