


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (9): 2910-2918.DOI: 10.11772/j.issn.1001-9081.2022081149
• Multimedia computing and computer simulation • Previous Articles Next Articles
Received:2022-08-07
Revised:2022-11-14
Accepted:2022-11-25
Online:2023-01-18
Published:2023-09-10
Contact:
Yongwang WEN
About author:ZHANG Qiuyu, born in 1966, research fellow. His research interests include network and information security, intelligent information processing, pattern recognition.
Supported by:通讯作者:
温永旺
作者简介:张秋余(1966—),男,河北辛集人,研究员,博士生导师,CCF会员,主要研究方向:网络与信息安全、智能信息处理、模式识别;
基金资助:CLC Number:
Qiuyu ZHANG, Yongwang WEN. Triplet deep hashing method for speech retrieval[J]. Journal of Computer Applications, 2023, 43(9): 2910-2918.
张秋余, 温永旺. 用于语音检索的三联体深度哈希方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2910-2918.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022081149

Fig. 1 Model of triplet deep hashing system
| 组成 | 参数设置 |
|---|---|
| net1模块 | Conv2D(kernel_size=(3,3),activation='ReLU',stride=2, input-shape=(3,256,256)) |
| BatchNormalization(axis=-1) | |
| Conv2D(kernel_size=(3,3), activation='ReLU',stride=2) | |
| BatchNormalization(axis=-1) | |
| MaxPooling2D(kernel_ size=3, stride=1) | |
| SA模块 | Conv2D(kernel_ size=(3,3),stride=2,padding=1) |
| Sigmoid() | |
| net2模块 | Conv2D(kernel_ size=(3,3), activation='ReLU',stride=2) |
| BatchNormalization(axis=-1) | |
| Conv2D(kernel_ size=(3,3), activation='ReLU',stride=2) | |
| BatchNormalization(axis=-1) | |
| Average Pooling2D(kernel_size=(3,3), stride=1) | |
| FC层 | Flattens() |
| Dropout | Dropout(0.5) |
| 哈希层 | Dense(64,activation='ReLu') |
| 输出层 | Dense(10,activation='softmax') |
Tab. 1 Parameter setting of deep hash encoding model
| 组成 | 参数设置 |
|---|---|
| net1模块 | Conv2D(kernel_size=(3,3),activation='ReLU',stride=2, input-shape=(3,256,256)) |
| BatchNormalization(axis=-1) | |
| Conv2D(kernel_size=(3,3), activation='ReLU',stride=2) | |
| BatchNormalization(axis=-1) | |
| MaxPooling2D(kernel_ size=3, stride=1) | |
| SA模块 | Conv2D(kernel_ size=(3,3),stride=2,padding=1) |
| Sigmoid() | |
| net2模块 | Conv2D(kernel_ size=(3,3), activation='ReLU',stride=2) |
| BatchNormalization(axis=-1) | |
| Conv2D(kernel_ size=(3,3), activation='ReLU',stride=2) | |
| BatchNormalization(axis=-1) | |
| Average Pooling2D(kernel_size=(3,3), stride=1) | |
| FC层 | Flattens() |
| Dropout | Dropout(0.5) |
| 哈希层 | Dense(64,activation='ReLu') |
| 输出层 | Dense(10,activation='softmax') |
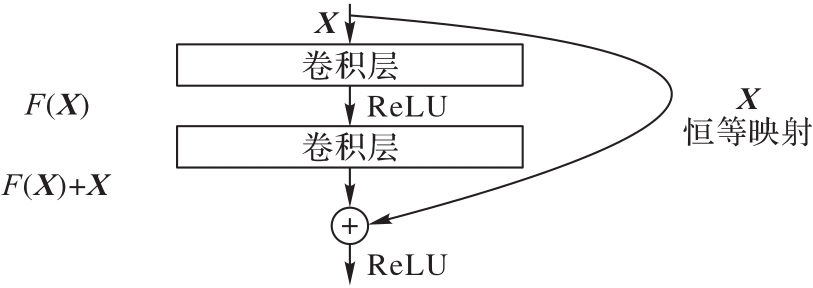
Fig. 2 Residual module structure
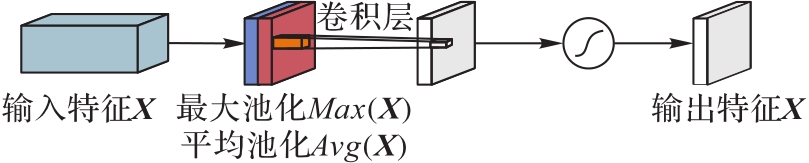
Fig. 3 Spatial attention module
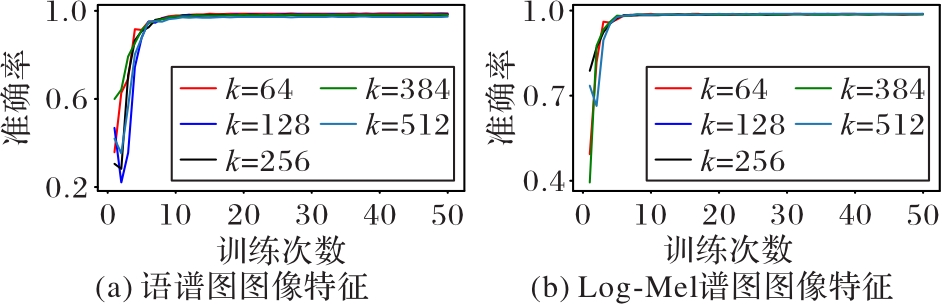
Fig. 4 Test accuracy curves of different hash code lengths k
| 图像特征 | 哈希码长度 | 不同方式的mAP/% | |
|---|---|---|---|
| 三联体标签 | 单标签 | ||
| 语谱图 | 64 | 98.86 | 89.70 |
| 128 | 98.53 | 92.04 | |
| 256 | 98.20 | 94.50 | |
| 384 | 98.20 | 96.96 | |
| 512 | 95.20 | 96.96 | |
| Log-Mel谱图 | 64 | 98.86 | 90.99 |
| 128 | 98.86 | 94.94 | |
| 256 | 98.69 | 96.81 | |
| 384 | 98.69 | 98.00 | |
| 512 | 98.66 | 98.03 | |
Tab. 2 mAP values of same encoding model under different hash code lengths
| 图像特征 | 哈希码长度 | 不同方式的mAP/% | |
|---|---|---|---|
| 三联体标签 | 单标签 | ||
| 语谱图 | 64 | 98.86 | 89.70 |
| 128 | 98.53 | 92.04 | |
| 256 | 98.20 | 94.50 | |
| 384 | 98.20 | 96.96 | |
| 512 | 95.20 | 96.96 | |
| Log-Mel谱图 | 64 | 98.86 | 90.99 |
| 128 | 98.86 | 94.94 | |
| 256 | 98.69 | 96.81 | |
| 384 | 98.69 | 98.00 | |
| 512 | 98.66 | 98.03 | |
| 方法 | 语音特征 | 网络 模型 | 不同哈希码长度下的mAP/% | ||||
|---|---|---|---|---|---|---|---|
| k=64 | k=128 | k=256 | k=384 | k=512 | |||
| 本文方法 | 语谱图 | ARN | 98.86 | 98.53 | 98.20 | 98.20 | 95.20 |
| Log-Mel谱图 | 98.86 | 98.86 | 98.69 | 98.69 | 98.66 | ||
| 文献[ | 语谱图 | CNN | 89.09 | 92.81 | 94.50 | 96.31 | 96.96 |
| 文献[ | 语谱图 | VGG16 | 85.00 | 84.40 | 82.20 | 82.20 | 80.40 |
| Log-Mel谱图 | 82.50 | 81.90 | 81.90 | 81.90 | 81.70 | ||
| 文献[ | 语谱图 | 3LCNN | 78.31 | 75.82 | 74.59 | 74.23 | 73.15 |
| Log-Mel谱图 | 80.05 | 79.83 | 79.27 | 78.56 | 77.96 | ||
| 文献[ | 语谱图 | VGG16 | 86.70 | 86.20 | 85.20 | 85.10 | 84.00 |
| Log-Mel谱图 | 86.00 | 85.30 | 85.00 | 85.00 | 84.90 | ||
| 文献[ | Log-Mel谱图 | CNN | 88.17 | 90.92 | 93.22 | 94.94 | 95.42 |
| CRNN | 88.33 | 91.03 | 94.36 | 95.56 | 95.94 | ||
Tab. 3 mAP values of different encoding models under different hash code lengths
| 方法 | 语音特征 | 网络 模型 | 不同哈希码长度下的mAP/% | ||||
|---|---|---|---|---|---|---|---|
| k=64 | k=128 | k=256 | k=384 | k=512 | |||
| 本文方法 | 语谱图 | ARN | 98.86 | 98.53 | 98.20 | 98.20 | 95.20 |
| Log-Mel谱图 | 98.86 | 98.86 | 98.69 | 98.69 | 98.66 | ||
| 文献[ | 语谱图 | CNN | 89.09 | 92.81 | 94.50 | 96.31 | 96.96 |
| 文献[ | 语谱图 | VGG16 | 85.00 | 84.40 | 82.20 | 82.20 | 80.40 |
| Log-Mel谱图 | 82.50 | 81.90 | 81.90 | 81.90 | 81.70 | ||
| 文献[ | 语谱图 | 3LCNN | 78.31 | 75.82 | 74.59 | 74.23 | 73.15 |
| Log-Mel谱图 | 80.05 | 79.83 | 79.27 | 78.56 | 77.96 | ||
| 文献[ | 语谱图 | VGG16 | 86.70 | 86.20 | 85.20 | 85.10 | 84.00 |
| Log-Mel谱图 | 86.00 | 85.30 | 85.00 | 85.00 | 84.90 | ||
| 文献[ | Log-Mel谱图 | CNN | 88.17 | 90.92 | 93.22 | 94.94 | 95.42 |
| CRNN | 88.33 | 91.03 | 94.36 | 95.56 | 95.94 | ||
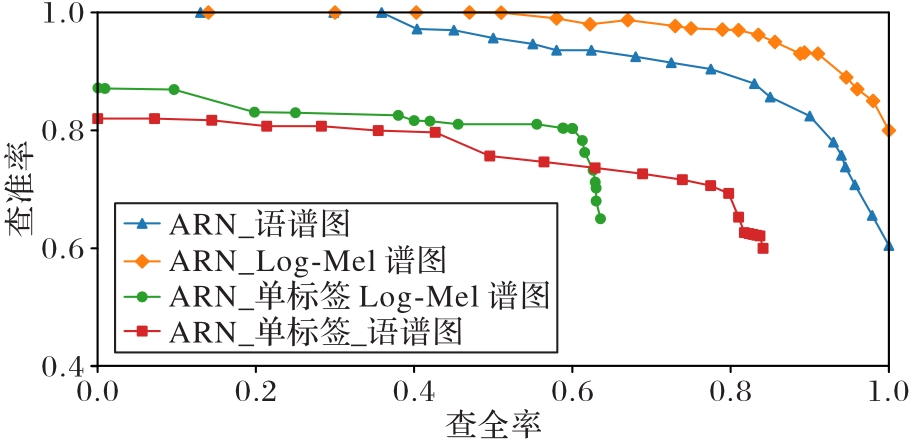
Fig. 5 P-R curves of different features under different labeling manners
| 方法 | 语音特征 | 网络模型 | R | P | F1 |
|---|---|---|---|---|---|
| 本文方法 | 语谱图 | ARN | 98.66 | 98.54 | 98.60 |
| Log-Mel谱图 | 100.00 | 99.57 | 99.78 | ||
| 文献[ | 语谱图 | CNN | — | 97.53 | — |
| SCfc2-CNN | — | 96.40 | — | ||
| MSCconv4-CNN | — | 99.49 | — | ||
| MSCconv5-CNN | — | 100.00 | — | ||
| 文献[ | Log-Mel谱图 | CNN | 99.80 | 100.00 | 99.90 |
| CRNN | 100.00 | 99.90 | 99.95 | ||
| 文献[ | MFCC | — | 95.00 | 93.00 | — |
| 文献[ | MFCC | LSTM | 94.00 | 93.00 | 93.50 |
| — | 83.00 | 84.00 | 83.50 |
Tab. 4 Retrieval performance comparison of different methods
| 方法 | 语音特征 | 网络模型 | R | P | F1 |
|---|---|---|---|---|---|
| 本文方法 | 语谱图 | ARN | 98.66 | 98.54 | 98.60 |
| Log-Mel谱图 | 100.00 | 99.57 | 99.78 | ||
| 文献[ | 语谱图 | CNN | — | 97.53 | — |
| SCfc2-CNN | — | 96.40 | — | ||
| MSCconv4-CNN | — | 99.49 | — | ||
| MSCconv5-CNN | — | 100.00 | — | ||
| 文献[ | Log-Mel谱图 | CNN | 99.80 | 100.00 | 99.90 |
| CRNN | 100.00 | 99.90 | 99.95 | ||
| 文献[ | MFCC | — | 95.00 | 93.00 | — |
| 文献[ | MFCC | LSTM | 94.00 | 93.00 | 93.50 |
| — | 83.00 | 84.00 | 83.50 |
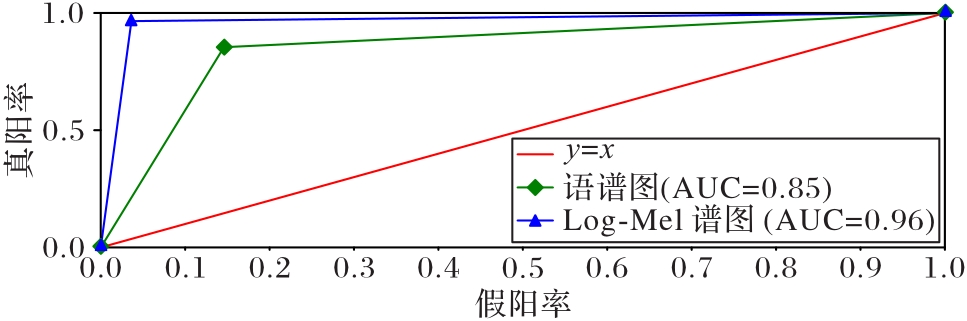
Fig. 6 ROC curves and AUC values for different features
| 方法 | 语音特征 | 查全率 | 查准率 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MP3 | R | R1 | R2 | MP3 | R | R1 | R2 | ||
| 本文方法 | 语谱图 | 100.00 | 95.82 | 88.70 | 100.00 | 100.00 | 95.82 | 88.70 | 100.00 |
| Log-Mel谱图 | 100.00 | 100.00 | 99.70 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| 文献[ | Log-Mel谱图 | 99.80 | 100.00 | — | — | 100.00 | 100.00 | — | — |
| 文献[ | Log-Mel谱图 | 100.00 | 100.00 | — | — | 99.50 | 100.00 | — | — |
| 文献[ | PNCC | 100.00 | 100.00 | 99.90 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
Tab. 5 Comparison results of recall and precision under different content preserving operations
| 方法 | 语音特征 | 查全率 | 查准率 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MP3 | R | R1 | R2 | MP3 | R | R1 | R2 | ||
| 本文方法 | 语谱图 | 100.00 | 95.82 | 88.70 | 100.00 | 100.00 | 95.82 | 88.70 | 100.00 |
| Log-Mel谱图 | 100.00 | 100.00 | 99.70 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| 文献[ | Log-Mel谱图 | 99.80 | 100.00 | — | — | 100.00 | 100.00 | — | — |
| 文献[ | Log-Mel谱图 | 100.00 | 100.00 | — | — | 99.50 | 100.00 | — | — |
| 文献[ | PNCC | 100.00 | 100.00 | 99.90 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
Fig. 7 Matching retrieval results for different speech features
| 方法 | 语音特征 | 主频/GHz | 语音 长度/s | 平均运行时间/ms |
|---|---|---|---|---|
| 文献[ | Log-Mel谱图 | 2.50 | 10 | 439.4 |
| 文献[ | Log-Mel谱图 | 2.50 | 10 | 527.4 |
| 文献[ | PNCC | 2.50 | 4 | 289.7 |
| 本文方法 | 语谱图 | 2.50 | 10 | 245.2 |
| Log-Mel谱图 | 2.50 | 10 | 234.7 |
Tab. 6 Comparison results of retrieval efficiency of proposed method and existing methods
| 方法 | 语音特征 | 主频/GHz | 语音 长度/s | 平均运行时间/ms |
|---|---|---|---|---|
| 文献[ | Log-Mel谱图 | 2.50 | 10 | 439.4 |
| 文献[ | Log-Mel谱图 | 2.50 | 10 | 527.4 |
| 文献[ | PNCC | 2.50 | 4 | 289.7 |
| 本文方法 | 语谱图 | 2.50 | 10 | 245.2 |
| Log-Mel谱图 | 2.50 | 10 | 234.7 |
| 1 | NG W W Y, LI J Y, TIAN X, et al. Bit-wise attention deep complementary supervised hashing for image retrieval[J]. Multimedia Tools and Applications, 2022, 81(1): 927-951. 10.1007/s11042-021-11494-8 |
| 2 | 万方,强浩鹏,雷光波. 自监督深度离散哈希图像检索[J]. 中国图象图形学报, 2021, 26(11):2659-2669. |
| WAN F, QIANG H P, LEI G B, et al. Self-supervised depth discrete hashing for image retrieval[J]. Journal of Image and Graphics, 2021, 26(11): 2659-2669. | |
| 3 | CAO R, ZHANG Q, ZHU J S, et al. Enhancing remote sensing image retrieval using a triplet deep metric learning network[J]. International Journal of Remote Sensing, 2020, 41(2): 740-751. 10.1080/2150704x.2019.1647368 |
| 4 | LI M Y, AN Z Y, WEI Q M, et al. Triplet deep hashing with joint supervised loss based on deep neural networks[J]. Computational Intelligence and Neuroscience, 2019, 2019: No.8490364. 10.1155/2019/8490364 |
| 5 | 黄羿博,王勇,张秋余,等. 基于混沌测量矩阵的生物哈希密文语音检索[J]. 华中科技大学学报(自然科学版), 2020, 48(12):32-37. |
| HUANG Y B, WANG Y, ZHANG Q Y, et al. Biohashing encrypted speech retrieval based on chaotic measurement matrix[J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2020, 48(12): 32-37. | |
| 6 | ZHANG Q Y, ZHAO X J, ZHANG Q W, et al. Content-based encrypted speech retrieval scheme with deep hashing[J]. Multimedia Tools and Applications, 2022, 81(7): 10221-10242. 10.1007/s11042-022-12123-8 |
| 7 | MASALSKI M, ADAMCZYK M, MORAWSKI K. Optimization of the speech test material in a group of hearing impaired subjects: a feasibility study for multilingual digit triplet test development[J]. Audiology Research, 2021, 11(3): 342-356. 10.3390/audiolres11030032 |
| 8 | FAN L, JIANG Q Y, YU Y Q, et al. Deep hashing for speaker identification and retrieval[C]// Proceeding of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 2908-2912. 10.21437/interspeech.2019-2457 |
| 9 | DENG M Q, MENG T T, CAO J W, et al. Heart sound classification based on improved MFCC features and convolutional recurrent neural networks[J]. Neural Networks, 2020, 130: 22-32. 10.1016/j.neunet.2020.06.015 |
| 10 | SAFI M E, ABBAS E I. Isolated word recognition based on PNCC with different classifiers in a noisy environment[J]. Applied Acoustics, 2022, 195: No.108848. 10.1016/j.apacoust.2022.108848 |
| 11 | 沈侃文,李文钧,岳克强. 融合LPCC和MFCC的支持向量机OSAHS鼾声识别[J]. 杭州电子科技大学学报(自然科学版), 2020, 40(6):1-5, 12. 10.13954/j.cnki.hdu.2020.06.001 |
| SHEN K W, LI W J, YUE K Q. Support vector machine OSAHS snoring recognition based on LPCC and MFCC[J]. Journal of Hangzhou Dianzi University (Natural Sciences), 2020, 40(6): 1-5, 12. 10.13954/j.cnki.hdu.2020.06.001 | |
| 12 | JIA Y J, CHEN X, YU J Q, et al. Speaker recognition based on characteristic spectrograms and an improved self-organizing feature map neural network[J]. Complex and Intelligent Systems, 2021, 7(4): 1749-1757. 10.1007/s40747-020-00172-1 |
| 13 | LI Q, SUN Z N, HE R, et al. A general framework for deep supervised discrete hashing[J]. International Journal of Computer Vision, 2020, 128(8/9): 2204-2222. 10.1007/s11263-020-01327-w |
| 14 | LONG J, WEI X X, QI Q Q, et al. A deep hashing method based on attention module for image retrieval[C]// Proceeding of the 13th International Conference on Intelligent Computation Technology and Automation. Piscataway: IEEE, 2020: 284-288. 10.1109/icicta51737.2020.00066 |
| 15 | LIAO W T, YANG M Y, ZHAN N, et al. Triplet-based deep similarity learning for person re-identification[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops. Piscataway: IEEE, 2017: 385-393. 10.1109/iccvw.2017.52 |
| 16 | ZHAO H, HE S F. A retrieval algorithm for encrypted speech based on perceptual hashing[C]// Proceeding of the 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery. Piscataway: IEEE, 2016: 1840-1845. 10.1109/fskd.2016.7603458 |
| 17 | HE S F, ZHAO H. A retrieval algorithm of encrypted speech based on syllable-level perceptual hashing[J]. Computer Science and Information Systems, 2017, 14(3): 703-718. 10.2298/csis170112024h |
| 18 | HUANG Y B, WANG Y, ZHANG Q Y, et al. Multi-format speech BioHashing based on spectrogram[J]. Multimedia Tools and Applications, 2020, 79(33/34): 24889-24909. 10.1007/s11042-020-09211-y |
| 19 | WANG C Y, TAI T C, WANG J C, et al. Sound events recognition and retrieval using multi-convolutional-channel sparse coding convolutional neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28:1875-1887. 10.1109/taslp.2020.2964959 |
| 20 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceeding of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 21 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceeding of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 22 | WANG D, ZHANG X W. THCHS-30: a free Chinese speech corpus[EB/OL]. (2015-12-10) [2022-05-11].. |
| 23 | ARIAS-VERGARA T, KLUMPP P, VASQUEZ-CORREA J C, et al. Multi-channel spectrograms for speech processing applications using deep learning methods[J]. Pattern Analysis and Applications, 2021, 24(2): 423-431. 10.1007/s10044-020-00921-5 |
| 24 | ZHENG X T, ZHANG Y C, LU X Q. Deep balanced discrete hashing for image retrieval[J]. Neurocomputing, 2020, 403: 224-236. 10.1016/j.neucom.2020.04.037 |
| 25 | ZHANG Z, ZOU Q, LIN Y W, et al. Improved deep hashing with soft pairwise similarity for multi-label image retrieval[J]. IEEE Transactions on Multimedia, 2020, 22(2): 540-553. 10.1109/tmm.2019.2929957 |
| 26 | ZHANG Q Y, ZHAO X J, HU Y J. A classification retrieval method for encrypted speech based on deep neural network and deep hashing[J]. IEEE Access, 2020, 8: 202469-202482. 10.1109/access.2020.3036048 |
| 27 | LI W, CHEN Y M, HU H S, et al. Using granule to search privacy preserving voice in home IoT systems[J]. IEEE Access, 2020, 8: 31957-31969. 10.1109/access.2020.2972975 |
| 28 | LI W, XIAO Y Z, TANG C, et al. Multi-user searchable encryption voice in home IoT system[J]. Internet of Things, 2020, 11: No.100180. 10.1016/j.iot.2020.100180 |
| 29 | ZHANG Q Y, BAI J, XU F J, et al. A retrieval method for encrypted speech based on improved power normalized cepstrum coefficients and perceptual hashing[J]. Multimedia Tools and Applications, 2022, 81(11): 15127-15151. 10.1007/s11042-022-12560-5 |
| [1] | Zhihua LIU, Wenjie CHEN, Aibin CHEN. Homologous spectrogram feature fusion with self-attention mechanism for bird sound classification [J]. Journal of Computer Applications, 2022, 42(4): 1260-1268. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
