


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (9): 2897-2903.DOI: 10.11772/j.issn.1001-9081.2022091342
• Multimedia computing and computer simulation • Previous Articles Next Articles
Received:2022-09-15
Revised:2022-11-23
Accepted:2022-11-30
Online:2023-02-22
Published:2023-09-10
Contact:
Zhangjin HUANG
About author:ZHOU Meng, born in 1993, M. S. candidate. His research interests include 3D vision, depth estimation.
Supported by:通讯作者:
黄章进
作者简介:周萌(1993—),男,湖北荆门人,硕士研究生,CCF会员,主要研究方向:三维视觉、深度估计;
基金资助:CLC Number:
Meng ZHOU, Zhangjin HUANG. Focal stack depth estimation method based on defocus blur[J]. Journal of Computer Applications, 2023, 43(9): 2897-2903.
周萌, 黄章进. 基于失焦模糊的焦点堆栈深度估计方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2897-2903.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022091342
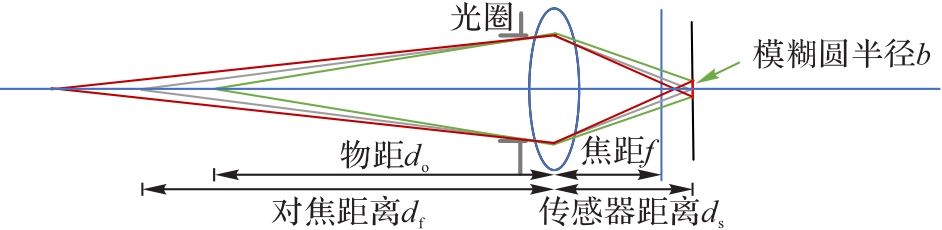
Fig. 1 Schematic diagram of defocus blur

Fig. 2 Overview framework of the proposed method

Fig. 3 Relationship between blur radius and object distance under different focus distance

Fig. 4 Relationship between blur variation and object distance

Fig. 5 Average gradient of each pixel with different directions of focal stack

Fig. 6 3D perception module

Fig. 7 Blur ambiguity near focal plane

Fig. 8 Channel difference module

Fig. 9 Encoder-decoder network
| 数据集 | 方法 | MAE | MSE | RMS | logRMS | absRel | sqrRel | 推理时间/ms |
|---|---|---|---|---|---|---|---|---|
| DefocusNet | AiFDepthNet | 7.880E-2 | 2.414E-2 | 0.145 E+0 | 0.258 | 0.161 | 4.030E-2 | 23.52 |
| DefocusNet | 20.47 | |||||||
| 文献[ | 7.289E-2 | 2.250E-2 | 0.139 E+0 | 0.262 | 0.146 | 3.743E-2 | ||
| 本文方法 | 5.326E-2 | 1.190E-2 | 0.099 E+0 | 0.182 | 0.115 | 1.613E-2 | 7.01 | |
| NYU Depth V2 | AiFDepthNet | 1.647E+0 | 2.768E+0 | 1.618E+0 | 1.834 | 5.572 | 9.498E+0 | 38.98 |
| DefocusNet | 9.934E-3 | 8.621E-2 | 2.590E-2 | 25.53 | ||||
| 文献[ | 8.829E-2 | 1.008E-1 | 0.329 | 0.253 | 3.260E-2 | |||
| 本文方法 | 6.804E-2 | 0.267 | 0.205 | 8.96 |
Tab. 1 Results of different methods on two datasets
| 数据集 | 方法 | MAE | MSE | RMS | logRMS | absRel | sqrRel | 推理时间/ms |
|---|---|---|---|---|---|---|---|---|
| DefocusNet | AiFDepthNet | 7.880E-2 | 2.414E-2 | 0.145 E+0 | 0.258 | 0.161 | 4.030E-2 | 23.52 |
| DefocusNet | 20.47 | |||||||
| 文献[ | 7.289E-2 | 2.250E-2 | 0.139 E+0 | 0.262 | 0.146 | 3.743E-2 | ||
| 本文方法 | 5.326E-2 | 1.190E-2 | 0.099 E+0 | 0.182 | 0.115 | 1.613E-2 | 7.01 | |
| NYU Depth V2 | AiFDepthNet | 1.647E+0 | 2.768E+0 | 1.618E+0 | 1.834 | 5.572 | 9.498E+0 | 38.98 |
| DefocusNet | 9.934E-3 | 8.621E-2 | 2.590E-2 | 25.53 | ||||
| 文献[ | 8.829E-2 | 1.008E-1 | 0.329 | 0.253 | 3.260E-2 | |||
| 本文方法 | 6.804E-2 | 0.267 | 0.205 | 8.96 |
| 方法 | MAE | RMS | absRel | sc-inv | ssitrim |
|---|---|---|---|---|---|
| AiFDepthNet | 0.239 | 0.312 | 0.276 | 0.319 | 0.509 |
| DefocusNet | 0.184 | 0.322 | 0.188 | 0.213 | 0.209 |
| 文献[ | 0.097 | 0.141 | 0.126 | 0.157 | 0.209 |
| 本文方法 | 0.096 | 0.114 | 0.162 | 0.088 | 0.250 |
Tab.2 Results of different methods training on DefocusNet dataset and testing on NYU Depth V2 dataset
| 方法 | MAE | RMS | absRel | sc-inv | ssitrim |
|---|---|---|---|---|---|
| AiFDepthNet | 0.239 | 0.312 | 0.276 | 0.319 | 0.509 |
| DefocusNet | 0.184 | 0.322 | 0.188 | 0.213 | 0.209 |
| 文献[ | 0.097 | 0.141 | 0.126 | 0.157 | 0.209 |
| 本文方法 | 0.096 | 0.114 | 0.162 | 0.088 | 0.250 |
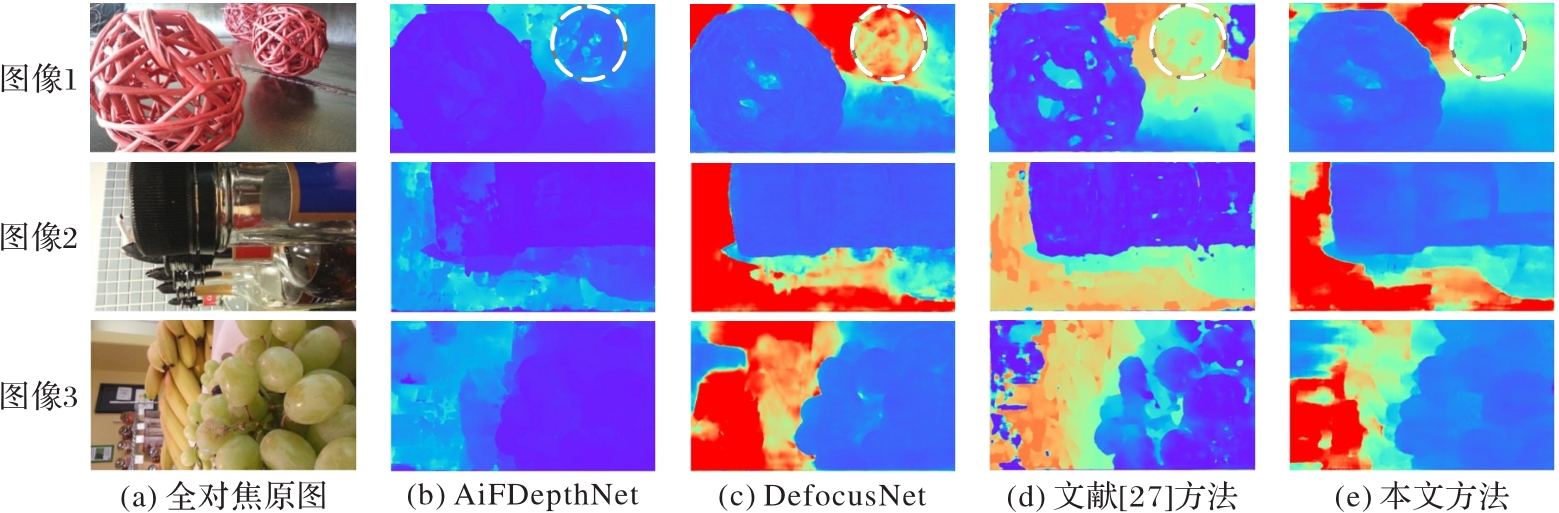
Fig. 10 Visual comparison of depth predictions on Mobile Depth dataset
| 实验 | 特征提取 | 焦点体 | 预测 | 评估指标 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D感知 | 孪生网络 | Naive | Diff-sxy | Diff-RGB | Layered | DO | MAE | MSE | sqrRel | |
| 1 | — | | | — | — | | — | 6.252E-2 | 0.118 | 2.606E-2 |
| 2 | | — | | — | — | | — | 6.081E-2 | 0.110 | 2.081E-2 |
| 3 | | — | | — | — | — | | 1.658E-1 | 0.264 | 9.776E-2 |
| 4 | | — | — | | — | | — | 5.846E-2 | 0.129 | 4.059E-2 |
| 5 | | — | — | — | | | — | 5.326E-2 | 0.099 | 1.613E-2 |
Tab. 3 Results of ablation experiments on DefocusNet dataset
| 实验 | 特征提取 | 焦点体 | 预测 | 评估指标 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D感知 | 孪生网络 | Naive | Diff-sxy | Diff-RGB | Layered | DO | MAE | MSE | sqrRel | |
| 1 | — | | | — | — | | — | 6.252E-2 | 0.118 | 2.606E-2 |
| 2 | | — | | — | — | | — | 6.081E-2 | 0.110 | 2.081E-2 |
| 3 | | — | | — | — | — | | 1.658E-1 | 0.264 | 9.776E-2 |
| 4 | | — | — | | — | | — | 5.846E-2 | 0.129 | 4.059E-2 |
| 5 | | — | — | — | | | — | 5.326E-2 | 0.099 | 1.613E-2 |

Fig. 11 Performance evaluation of focal stack layers on Mobile Depth dataset
| 1 | EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2. Cambridge: MIT Press, 2014: 2366-2374. 10.48550/arXiv.1406.2283 |
| 2 | LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks[C]// Proceedings of the 4th International Conference on 3D Vision. Piscataway: IEEE, 2016: 239-248. 10.1109/3dv.2016.32 |
| 3 | YIN W, LIU Y F, SHEN C H, et al. Enforcing geometric constraints of virtual normal for depth prediction[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 5683-5692. 10.1109/iccv.2019.00578 |
| 4 | LI Z Y, WANG X Y, LIU X M, et al. BinsFormer: revisiting adaptive bins for monocular depth estimation[EB/OL]. (2022-04-03) [2022-04-17].. |
| 5 | SCHARSTEIN D, SZELISKI R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J]. International Journal of Computer Vision, 2002, 47(1/2/3): 7-42. 10.1023/a:1014573219977 |
| 6 | MAYER N, ILG E, HÄUSSER P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4040-4048. 10.1109/cvpr.2016.438 |
| 7 | KENDALL A, MARTIROSYAN H, DASGUPTA S, et al. End-to-end learning of geometry and context for deep stereo regression[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 66-75. 10.1109/iccv.2017.17 |
| 8 | GARG R, KUMAR B G V, CARNEIRO G, et al. Unsupervised CNN for single view depth estimation: geometry to the rescue[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9912. Cham: Springer, 2016: 740-756. |
| 9 | ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6612-6619. 10.1109/cvpr.2017.700 |
| 10 | GODARD C, AODHA O MAC, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3827-3837. 10.1109/iccv.2019.00393 |
| 11 | GODARD C, AODHA O MAC, BROSTOW G J. Unsupervised monocular depth estimation with left-right consistency[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6602-6611. 10.1109/cvpr.2017.699 |
| 12 | SUWAJANAKORN S, HERNÁNDEZ C, SEITZ S M. Depth from focus with your mobile phone[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3497-3506. 10.1109/cvpr.2015.7298972 |
| 13 | MAXIMOV M, GALIM K, LEAL-TAIXÉ L. Focus on defocus: bridging the synthetic to real domain gap for depth estimation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1071-1080. 10.1109/cvpr42600.2020.00115 |
| 14 | WANG N H, WANG R, LIU Y L, et al. Bridging unsupervised and supervised depth from focus via all-in-focus supervision[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 12601-12611. 10.1109/iccv48922.2021.01239 |
| 15 | FUJIMURA Y, IIYAMA M, FUNATOMI T, et al. Deep depth from focal stack with defocus model for camera-setting invariance[EB/OL]. (2022-02-26) [2022-03-12].. |
| 16 | YANG F T, HUANG X L, ZHOU Z H. Deep depth from focus with differential focus volume[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12632-12641. 10.1109/cvpr52688.2022.01231 |
| 17 | HAZIRBAS C, SOYER S G, STAAB M C, et al. Deep depth from focus[C]// Proceedings of the 2018 Asian Conference on Computer Vision, LNCS 11363. Cham: Springer, 2019: 525-541. |
| 18 | CERUSO S, BONAQUE-GONZÁLEZ S, OLIVA-GARCÍA R, et al. Relative multiscale deep depth from focus[J]. Signal Processing: Image Communication, 2021, 99: No.116417. 10.1016/j.image.2021.116417 |
| 19 | GUO Q, FENG W, ZHOU C, et al. Learning dynamic Siamese network for visual object tracking[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1781-1789. 10.1109/iccv.2017.196 |
| 20 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. |
| 21 | NAYAR S K, WATANABE M, NOGUCHI M. Real-time focus range sensor[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1996, 18(12): 1186-1198. 10.1109/34.546256 |
| 22 | SRINIVASAN P P, GARG R, WADHWA N, et al. Aperture supervision for monocular depth estimation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6393-6401. 10.1109/cvpr.2018.00669 |
| 23 | CARVALHO M, LE SAUX B, TROUVÉ-PELOUX P, et al. Deep depth from defocus: how can defocus blur improve 3D estimation using dense neural networks?[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11129. Cham: Springer, 2019: 307-323. |
| 24 | GALETTO F J, DENG G. Single image deep defocus estimation and its applications[EB/OL]. (2021-12-14) [2022-02-19].. 10.1007/s00371-022-02609-9 |
| 25 | SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2818-2826. 10.1109/cvpr.2016.308 |
| 26 | KASHIWAGI M, MISHIMA N, KOZAKAYA T, et al. Deep depth from aberration map[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 4069-4078. 10.1109/iccv.2019.00417 |
| 27 | WON C, JEON H G. Learning depth from focus in the wild[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13661. Cham: Springer, 2022: 1-18. |
| [1] | ZHAO Senxiang, LI Shaobo, CHEN Bin, ZHAO Xuezhuan. Local motion blur detection based on energy estimation [J]. Journal of Computer Applications, 2016, 36(10): 2859-2862. |
| [2] | LIANG Min ZHU Hong OUYANG Guang-zheng LIU Wei. Sub-pixel discrete method of point spread function from blurred images [J]. Journal of Computer Applications, 2012, 32(02): 496-498. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
