


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (12): 3856-3867.DOI: 10.11772/j.issn.1001-9081.2022111720
• Advanced computing • Previous Articles Next Articles
Li LIU1,2, Changbo CHEN1( )
)
Received:2022-11-21
Revised:2023-05-04
Accepted:2023-05-06
Online:2023-12-11
Published:2023-12-10
Contact:
Changbo CHEN
About author:LIU Li, born in 1998, M. S. candidate. Her research interests include high-performance computing, deep learning.
Supported by:通讯作者:
陈长波
作者简介:刘丽(1998—),女,河南信阳人,硕士研究生,CCF会员,主要研究方向:高性能计算、深度学习;
CLC Number:
Li LIU, Changbo CHEN. Band sparse matrix multiplication and efficient GPU implementation[J]. Journal of Computer Applications, 2023, 43(12): 3856-3867.
刘丽, 陈长波. 带状稀疏矩阵乘法及高效GPU实现[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3856-3867.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022111720
Fig.1 Sparse matrix
Fig.2 BCSR format
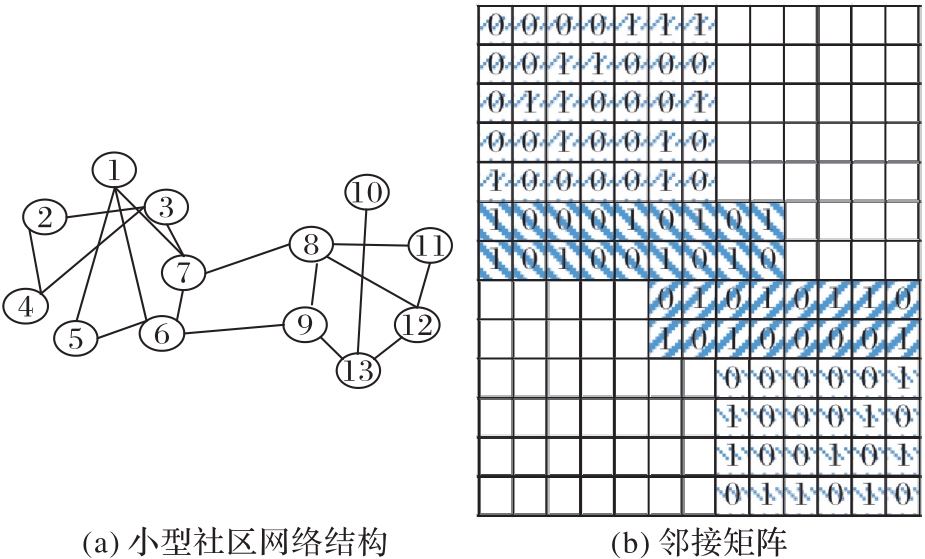
Fig.3 Community structure network

Fig.4 Band sparse matrix
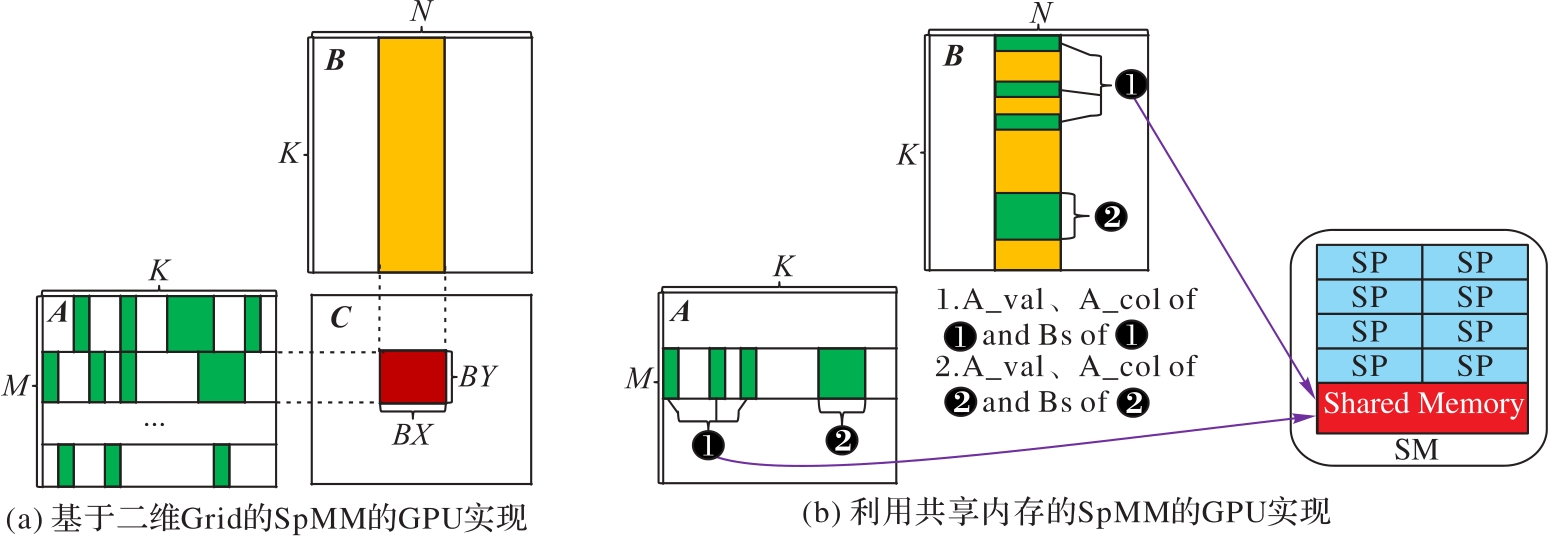
Fig. 5 GPU implementation of SpMM based on BRCV format
TuDataset 数据集中 不同领域 | 数据集名称 | 节点数 | 边数 | 子图数 | 平均 节点数 |
|---|---|---|---|---|---|
| 生物化学领域 | BZR_MD | 6 519 | 68 867 | 306 | 21.30 |
| COX2_MD | 7 962 | 206 084 | 303 | 26.28 | |
| DHFR_MD | 9 380 | 222 452 | 393 | 23.87 | |
| ER_MD | 9 512 | 209 482 | 446 | 21.33 | |
| 社交网络领域 | IMDB-BINARY | 19 773 | 386 124 | 1 000 | 19.77 |
| IMDB-MULTI | 19 502 | 395 146 | 1 500 | 13.00 |
Tab.1 Details of graph classification datasets
TuDataset 数据集中 不同领域 | 数据集名称 | 节点数 | 边数 | 子图数 | 平均 节点数 |
|---|---|---|---|---|---|
| 生物化学领域 | BZR_MD | 6 519 | 68 867 | 306 | 21.30 |
| COX2_MD | 7 962 | 206 084 | 303 | 26.28 | |
| DHFR_MD | 9 380 | 222 452 | 393 | 23.87 | |
| ER_MD | 9 512 | 209 482 | 446 | 21.33 | |
| 社交网络领域 | IMDB-BINARY | 19 773 | 386 124 | 1 000 | 19.77 |
| IMDB-MULTI | 19 502 | 395 146 | 1 500 | 13.00 |
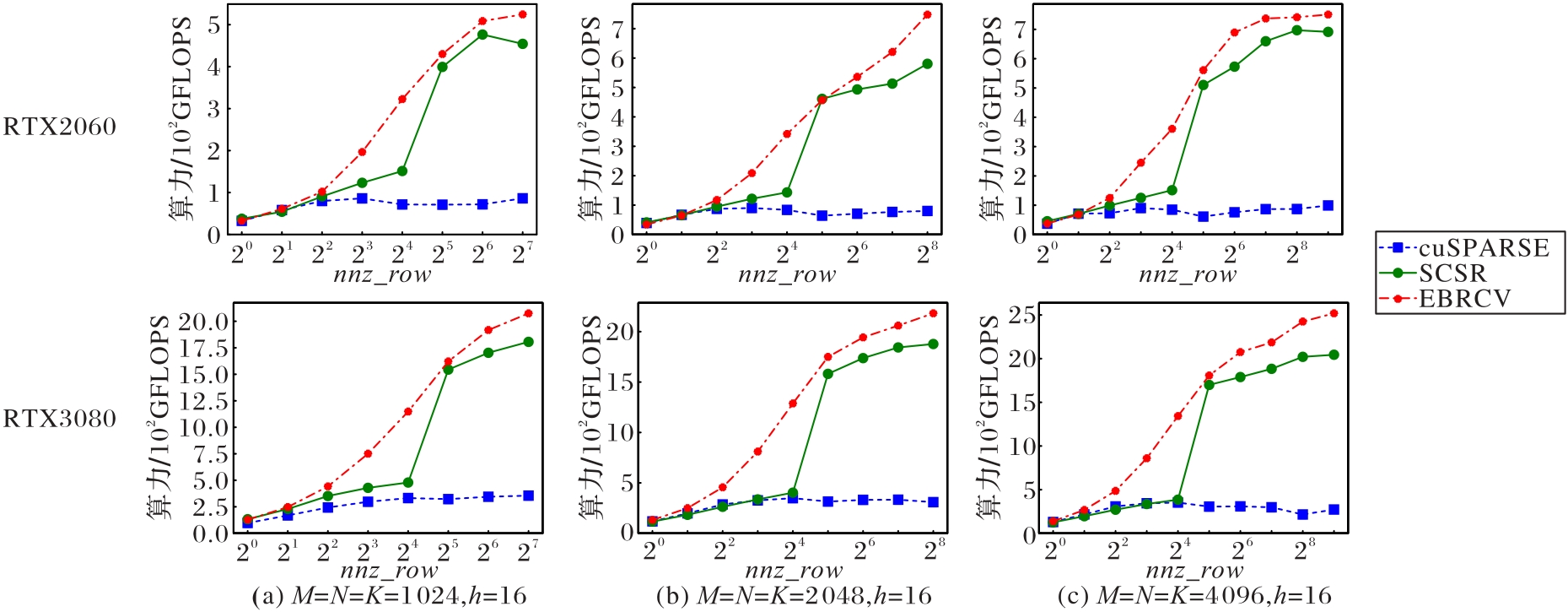
Fig. 6 Performance of different SpMM implementations for example 1 on different GPU when number of non-zero elements on each row of sparse matrix varies
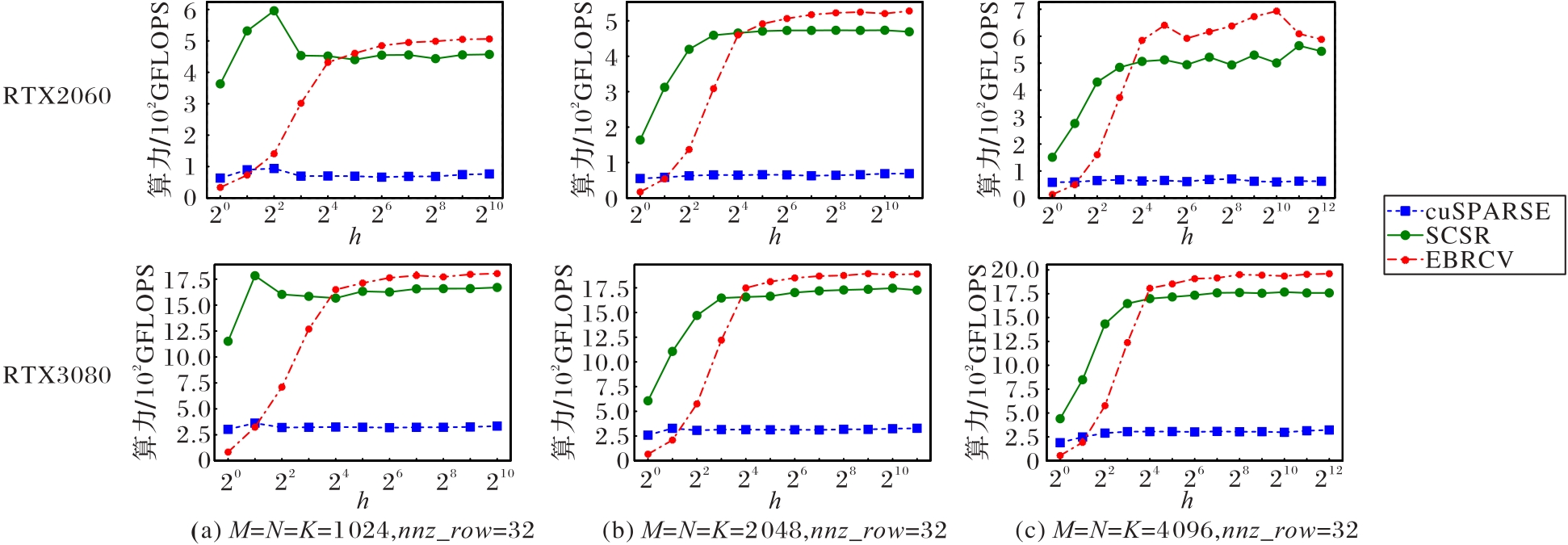
Fig. 7 Performance of different SpMM implementations for example 2 on different GPU when band height of sparse matrix varies
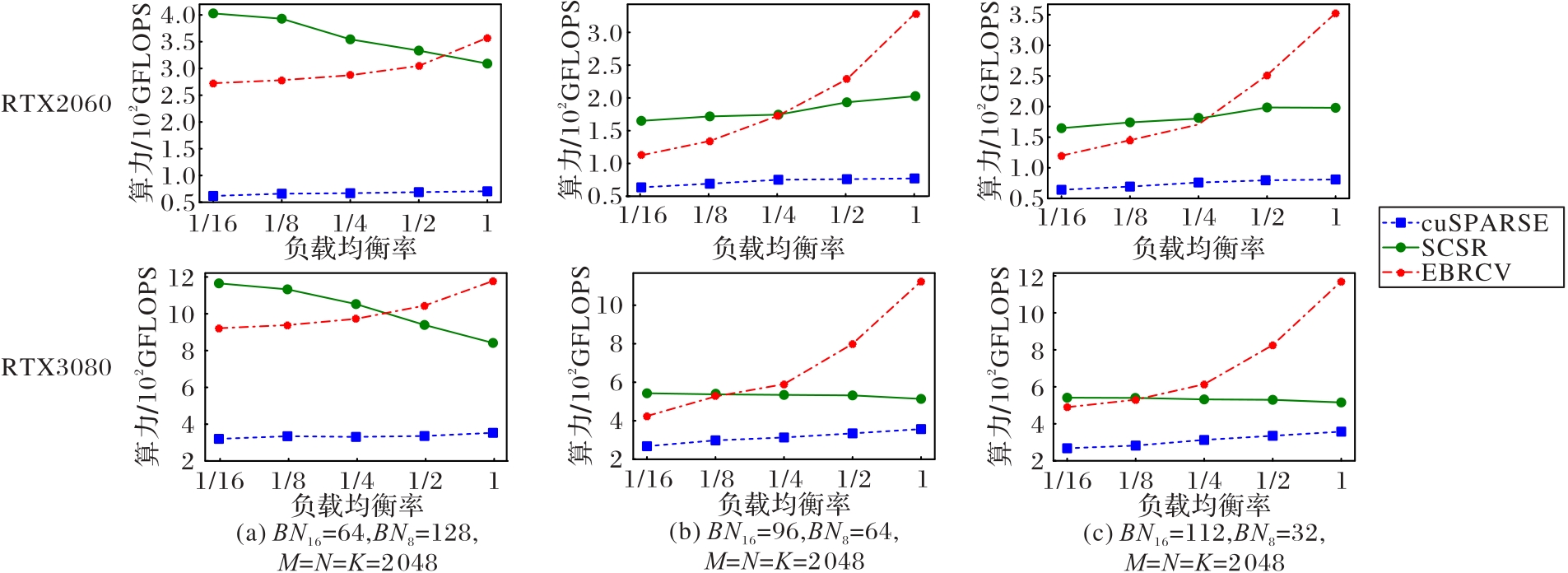
Fig. 8 Performance of different SpMM implementations for example 3 on different GPU when load balancing ratio of thread blocks varies

Fig. 9 Performance of different SpMM implementations for example 4 on different GPU when band height of non-equal height band sparse matrix varies
| GPU | 稀疏矩阵 维度M | cuSPARSE | cuBLAS | Block-SpMM | SCSR | BRCV | 最小 加速比 | 最大 加速比 | |
|---|---|---|---|---|---|---|---|---|---|
| BS=16 | BS=32 | ||||||||
| RTX2060 | 1 822 | 72.27 | 138.29 | 216.12 | 384.28 | 394.62 | 1.03 | 5.47 | |
| 1 986 | 70.92 | 120.48 | 195.56 | 321.78 | 383.93 | 1.07 | 5.41 | ||
| 2 050 | 68.82 | 108.95 | 173.95 | 298.64 | 409.22 | 1.12 | 5.94 | ||
| 2 106 | 70.88 | 123.85 | 208.20 | 343.06 | 439.70 | 1.16 | 6.20 | ||
| 2 227 | 73.47 | 110.96 | 201.18 | 296.05 | 397.78 | 1.15 | 5.41 | ||
| RTX3080 | 1 822 | 327.83 | 558.28 | 930.60 | 1 649.26 | 1 239.26 | 0.90 | 4.55 | |
| 1 986 | 329.29 | 567.16 | 807.48 | 1 131.39 | 1 446.15 | 1.03 | 4.39 | ||
| 2 050 | 328.69 | 533.50 | 713.97 | 1 157.47 | 1 483.45 | 1.11 | 4.51 | ||
| 2 106 | 332.84 | 644.40 | 881.27 | 1 208.31 | 1 586.72 | 1.12 | 4.77 | ||
| 2 227 | 333.04 | 454.44 | 835.30 | 1 073.22 | 1 390.00 | 1.08 | 4.17 | ||
Tab.2 Performance comparison of different SpMM implementations on different GPU when both band height and the number of non-zero elements on each row of non-equal height band sparse matrix vary
| GPU | 稀疏矩阵 维度M | cuSPARSE | cuBLAS | Block-SpMM | SCSR | BRCV | 最小 加速比 | 最大 加速比 | |
|---|---|---|---|---|---|---|---|---|---|
| BS=16 | BS=32 | ||||||||
| RTX2060 | 1 822 | 72.27 | 138.29 | 216.12 | 384.28 | 394.62 | 1.03 | 5.47 | |
| 1 986 | 70.92 | 120.48 | 195.56 | 321.78 | 383.93 | 1.07 | 5.41 | ||
| 2 050 | 68.82 | 108.95 | 173.95 | 298.64 | 409.22 | 1.12 | 5.94 | ||
| 2 106 | 70.88 | 123.85 | 208.20 | 343.06 | 439.70 | 1.16 | 6.20 | ||
| 2 227 | 73.47 | 110.96 | 201.18 | 296.05 | 397.78 | 1.15 | 5.41 | ||
| RTX3080 | 1 822 | 327.83 | 558.28 | 930.60 | 1 649.26 | 1 239.26 | 0.90 | 4.55 | |
| 1 986 | 329.29 | 567.16 | 807.48 | 1 131.39 | 1 446.15 | 1.03 | 4.39 | ||
| 2 050 | 328.69 | 533.50 | 713.97 | 1 157.47 | 1 483.45 | 1.11 | 4.51 | ||
| 2 106 | 332.84 | 644.40 | 881.27 | 1 208.31 | 1 586.72 | 1.12 | 4.77 | ||
| 2 227 | 333.04 | 454.44 | 835.30 | 1 073.22 | 1 390.00 | 1.08 | 4.17 | ||
数据集 应用领域 | 数据集 | cuSPARSE | SCSR | cuBLAS | Block-SpMM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BS=16 | BS=32 | ||||||||||
| N=128 | N=256 | N=128 | N=256 | N=128 | N=256 | N=128 | N=256 | N=128 | N=256 | ||
| 图分类 | BZR_MD | 3.24 | 3.56 | 2.49 | 2.75 | 22.14 | 20.95 | 1.27 | 1.23 | 0.66 | 0.65 |
| COX2_MD | 3.63 | 4.24 | 3.12 | 3.46 | 25.87 | 23.51 | 1.02 | 1.11 | 0.65 | 0.60 | |
| DHFR_MD | 2.66 | 4.05 | 2.16 | 3.10 | 23.41 | 25.93 | 1.16 | 1.16 | 0.52 | 0.59 | |
| ER_MD | 3.17 | 3.13 | 2.82 | 2.49 | 29.97 | 22.73 | 1.13 | 1.04 | 0.55 | 0.54 | |
| IMDB-BINARY | 1.72 | 1.46 | 1.62 | 1.29 | 54.86 | 57.43 | 1.46 | 1.03 | 0.60 | 0.52 | |
| IMDB-MULTI | 1.81 | 2.15 | 1.90 | 1.57 | 62.68 | 76.73 | 1.26 | 1.21 | 0.73 | 0.72 | |
| 社区探测 | AIRPORT | 4.47 | 4.38 | 1.05 | 1.36 | 2.41 | 1.95 | 1.14 | 1.17 | 0.64 | 0.57 |
| email-Eu-core | 3.06 | 3.53 | 1.08 | 1.22 | 3.79 | 4.42 | 3.03 | 2.97 | 1.80 | 1.72 | |
Tab.3 Speedup ratios of BRCV compared to other four SpMM implementations on graph classification and community detection datasets
数据集 应用领域 | 数据集 | cuSPARSE | SCSR | cuBLAS | Block-SpMM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BS=16 | BS=32 | ||||||||||
| N=128 | N=256 | N=128 | N=256 | N=128 | N=256 | N=128 | N=256 | N=128 | N=256 | ||
| 图分类 | BZR_MD | 3.24 | 3.56 | 2.49 | 2.75 | 22.14 | 20.95 | 1.27 | 1.23 | 0.66 | 0.65 |
| COX2_MD | 3.63 | 4.24 | 3.12 | 3.46 | 25.87 | 23.51 | 1.02 | 1.11 | 0.65 | 0.60 | |
| DHFR_MD | 2.66 | 4.05 | 2.16 | 3.10 | 23.41 | 25.93 | 1.16 | 1.16 | 0.52 | 0.59 | |
| ER_MD | 3.17 | 3.13 | 2.82 | 2.49 | 29.97 | 22.73 | 1.13 | 1.04 | 0.55 | 0.54 | |
| IMDB-BINARY | 1.72 | 1.46 | 1.62 | 1.29 | 54.86 | 57.43 | 1.46 | 1.03 | 0.60 | 0.52 | |
| IMDB-MULTI | 1.81 | 2.15 | 1.90 | 1.57 | 62.68 | 76.73 | 1.26 | 1.21 | 0.73 | 0.72 | |
| 社区探测 | AIRPORT | 4.47 | 4.38 | 1.05 | 1.36 | 2.41 | 1.95 | 1.14 | 1.17 | 0.64 | 0.57 |
| email-Eu-core | 3.06 | 3.53 | 1.08 | 1.22 | 3.79 | 4.42 | 3.03 | 2.97 | 1.80 | 1.72 | |
| 1 | 刘伟峰. 高可扩展、高性能和高实用的稀疏矩阵计算研究进展与挑战[J]. 数值计算与计算机应用, 2020, 41(4): 259-281. 10.12288/szjs.2020.4.259 |
| LIU W F. Highly-scalable, highly-performant and highly-practical sparse matrix computations: progress and challenges[J]. Journal of Numerical Computation and Computer Applications, 2020, 41(4): 259-281. 10.12288/szjs.2020.4.259 | |
| 2 | GALE T, ZAHARIA M, YOUNG C, et al. Sparse GPU kernels for deep learning[C]// Proceedings of the 2020 International Conference for High Performance Computing, Networking, Storage and Analysis. Piscataway: IEEE, 2020: 1-14. 10.1109/sc41405.2020.00021 |
| 3 | YANG C, BULUÇ A, OWENS J D. Design principles for sparse matrix multiplication on the GPU[C]// Proceedings of the 2018 European Conference on Parallel Processing, LNCS 11014. Cham: Springer, 2018: 672-687. |
| 4 | XU K, HU W, LESKOVEC J, et al. How powerful are graph neural networks?[EB/OL]. (2019-02-22) [2023-02-25].. |
| 5 | XIN J, YE X, ZHENG L, et al. Fast sparse deep neural network inference with flexible SpMM optimization space exploration[C]// Proceedings of the 2021 IEEE High Performance Extreme Computing Conference. Piscataway: IEEE, 2021: 1-7. 10.1109/hpec49654.2021.9622791 |
| 6 | DAVE S, BAGHDADI R, NOWATZKI T, et al. Hardware acceleration of sparse and irregular tensor computations of ML models: a survey and insights [J]. Proceedings of the IEEE, 2021, 109(10): 1706-1752. 10.1109/jproc.2021.3098483 |
| 7 | COLEY C W, JIN W, ROGERS L, et al. A graph-convolutional neural network model for the prediction of chemical reactivity[J]. Chemical Science, 2019, 10(2): 370-377. 10.1039/c8sc04228d |
| 8 | HUANG G, DAI G, WANG Y, et al. GE-SpMM: general-purpose sparse matrix-matrix multiplication on GPUs for graph neural networks [C]// Proceedings of the 2020 International Conference for High Performance Computing, Networking, Storage and Analysis. Piscataway: IEEE, 2020: 1-12. 10.1109/sc41405.2020.00076 |
| 9 | NAGASAKA Y, NUKADA A, KOJIMA R, et al. Batched sparse matrix multiplication for accelerating graph convolutional networks[C]// Proceedings of the 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing. Piscataway: IEEE, 2019: 231-240. 10.1109/ccgrid.2019.00037 |
| 10 | HOEFLER T, ALISTARH D, BEN-NUN T, et al. Sparsity in deep learning: pruning and growth for efficient inference and training in neural networks[J]. Journal of Machine Learning Research, 2021, 22: 1-124. |
| 11 | WANG Z. SparseRT: accelerating unstructured sparsity on GPUs for deep learning inference [C]// Proceedings of the 2020 ACM International Conference on Parallel Architectures and Compilation Techniques. New York: ACM, 2020: 31-42. 10.1145/3410463.3414654 |
| 12 | CHILD R, GRAY S, RADFORD A, et al. Generating long sequences with sparse Transformers[EB/OL]. (2019-04-23) [2023-02-25].. |
| 13 | KITAEV N, KAISER Ł, LEVSKAYA A. Reformer: the efficient Transformer [EB/OL]. (2020-02-18) [2023-02-25].. |
| 14 | YANG C, BULUÇ A, OWENS J D. GraphBLAST: a high-performance linear algebra-based graph framework on the GPU[J]. ACM Transactions on Mathematical Software, 2022, 48(1): 1-51. 10.1145/3466795 |
| 15 | LANGR D, TVRDÍK P. Evaluation criteria for sparse matrix storage formats [J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(2): 428-440. 10.1109/tpds.2015.2401575 |
| 16 | CHOU S, KJOLSTAD F, AMARASINGHE S. Automatic generation of efficient sparse tensor format conversion routines[C]// Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation. New York: ACM, 2020: 823-838. 10.1145/3385412.3385963 |
| 17 | LIU W, VINTER B. CSR5: an efficient storage format for cross-platform sparse matrix-vector multiplication[C]// Proceedings of the 29th ACM International Conference on Supercomputing. New York: ACM, 2015: 339-350. 10.1145/2751205.2751209 |
| 18 | ECKER J P, BERRENDORF R, MANNUSS F. New efficient general sparse matrix formats for parallel SpMV operations [C]// Proceedings of the 2017 European Conference on Parallel Processing, LNCS 10417. Cham: Springer, 2017: 523-537. |
| 19 | XIE B, ZHAN J, LIU X, et al. CVR: efficient vectorization of SpMV on x86 processors[C]// Proceedings of the 2018 International Symposium on Code Generation and Optimization. New York: ACM, 2018: 149-162. 10.1145/3168818 |
| 20 | 程凯,田瑾,马瑞琳.基于GPU的高效稀疏矩阵存储格式研究[J].计算机工程, 2018, 44(8): 54-60. 10.19678/j.issn.1000-3428.0048047 |
| CHENG K, TIAN J, MA R L. Study on efficient storage format of sparse matrix based on GPU[J]. Computer Engineering, 2018, 44(8): 54-60. 10.19678/j.issn.1000-3428.0048047 | |
| 21 | ZHANG Y, YANG W, LI K, et al. Performance analysis and optimization for SpMV based on aligned storage formats on an ARM processor[J]. Journal of Parallel and Distributed Computing, 2021, 158: 126-137. 10.1016/j.jpdc.2021.08.002 |
| 22 | CORONADO-BARRIENTOS E, ANTONIOLETTI M, GARCIA-LOUREIRO A. A new AXT format for an efficient SpMV product using AVX-512 instructions and CUDA[J]. Advances in Engineering Software, 2021, 156: No.102997. 10.1016/j.advengsoft.2021.102997 |
| 23 | BIAN H, HUANG J, DONG R, et al. A simple and efficient storage format for SIMD-accelerated SpMV[J]. Cluster Computing, 2021, 24(4): 3431-3448. 10.1007/s10586-021-03340-1 |
| 24 | KARIMI E, AGOSTINI N B, DONG S, et al. VCSR: an efficient GPU memory-aware sparse format[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(12):3977-3989. 10.1109/tpds.2022.3177291 |
| 25 | VUDUC R W, MOON H J. Fast sparse matrix-vector multiplication by exploiting variable block structure[C]// Proceedings of the 2005 International Conference on High Performance Computing and Communications, LNCS 3726. Berlin: Springer, 2005: 807-816. |
| 26 | ALMASRI M, ABU-SUFAH W. CCF: an efficient SpMV storage format for AVX512 platforms[J]. Parallel Computing, 2020, 100: No.102710. 10.1016/j.parco.2020.102710 |
| 27 | 杨世伟,蒋国平,宋玉蓉,等. 基于GPU的稀疏矩阵存储格式优化研究[J]. 计算机工程, 2019, 45(9): 23-31,39. |
| YANG S W, JIANG G P, SONG Y R, et al. Research on storage format optimization of sparse matrix based on GPU[J]. Computer Engineering, 2019, 45(9): 23-31, 39. | |
| 28 | LI Y, XIE P, CHEN X, et al. VBSF: a new storage format for SIMD sparse matrix-vector multiplication on modern processors[J]. The Journal of Supercomputing, 2020, 76(3): 2063-2081. 10.1007/s11227-019-02835-4 |
| 29 | AHRENS P, BOMAN E G. On optimal partitioning for sparse matrices in variable block row format[EB/OL]. (2021-05-25) [2023-02-25].. |
| 30 | ALIAGA J I, ANZT H, GRÜTZMACHER T, et al. Compression and load balancing for efficient sparse matrix-vector product on multicore processors and graphics processing units[J]. Concurrency and Computation: Practice and Experience, 2022, 34(14): No.e6515. 10.1002/cpe.6515 |
| 31 | NVIDIA. cuSPARSE library [EB/OL]. (2022-12) [2023-02-28].. |
| 32 | CHEN C, WU W. A geometric approach for analyzing parametric biological systems by exploiting block triangular structure[J]. SIAM Journal on Applied Dynamical Systems, 2022, 21(2): 1573-1596. 10.1137/21m1436373 |
| 33 | WU Z, PAN S, CHEN F, et al. A comprehensive survey on graph neural networks [J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 4-24. 10.1109/tnnls.2020.2978386 |
| 34 | LIU F, XUE S, WU J, et al. Deep learning for community detection: progress, challenges and opportunities[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020: 4981-4987. 10.24963/ijcai.2020/693 |
| 35 | RANI S, MEHROTRA M. Community detection in social networks: literature review[J]. Journal of Information and Knowledge Management, 2019, 18(2): No.1950019. 10.1142/s0219649219500199 |
| 36 | GALLOPOULOS E, PHILIPPE B, SAMEH A H. Banded linear systems[M]// Parallelism in Matrix Computations, SCIENTCOMP. Dordrecht: Springer, 2016: 91-163. 10.1007/978-94-017-7188-7_5 |
| 37 | 中国科学院重庆绿色智能技术研究院. 一种带状稀疏矩阵的数据存储格式及其乘法加速方法: 202210931011.6[P]. 2022-11-08. |
| Chongqing Institute of Green and Intelligent Technology of Chinese Academy of Sciences. A data storage format for strip sparse matrix and its multiplication acceleration method: 202210931011.6 [P]. 2022-11-08. | |
| 38 | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [EB/OL]. (2017-02-22) [2023-03-01].. 10.48550/arXiv.1609.02907 |
| 39 | NVIIDA. Introduction of cuBLAS library[EB/OL]. [2023-04-01].. |
| 40 | YAMAGUCHI T, BUSATO F. Accelerating matrix multiplication with block sparse format and NVIDIA tensor cores[EB/OL]. (2021-03-19) [2023-04-09].. |
| 41 | MORRIS C, KRIEGE N M, BAUSE F, et al. TUDataset: a collection of benchmark datasets for learning with graphs[EB/OL]. (2020-07-16) [2023-02-28].. |
| 42 | ZHANG M, CHEN Y. Link prediction based on graph neural networks [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 5171-5181. |
| 43 | LESKOVEC J, KLEINBERG J, FALOUTSOS C. Graph evolution: densification and shrinking diameters[J]. ACM Transactions on Knowledge Discovery from Data, 2007, 1(1): No.2. 10.1145/1217299.1217301 |
| [1] | Jingwen CAI, Yongzhuang WEI, Zhenghong LIU. GPU-based method for evaluating algebraic properties of cryptographic S-boxes [J]. Journal of Computer Applications, 2022, 42(9): 2750-2756. |
| [2] | Fan PING, Xiaochun TANG, Yanyu PAN, Zhanhuai LI. Scheduling strategy of irregular tasks on graphics processing unit cluster [J]. Journal of Computer Applications, 2021, 41(11): 3295-3301. |
| [3] | HE Xi, WU Yantao, DI Zhenwei, CHEN Jia. GPU-based morphological reconstruction system [J]. Journal of Computer Applications, 2019, 39(7): 2008-2013. |
| [4] | WU Xuchen, PIAO Chunhui, JIANG Xuehong. Siting model of electric taxi charging station based on GPU parallel computing [J]. Journal of Computer Applications, 2019, 39(10): 3071-3078. |
| [5] | JI Lina, CHEN Qingkui, CHEN Yuanjing, ZHAO Deyu, FANG Yuling, ZHAO Yongtao. Real-time crowd counting method from video stream based on GPU [J]. Journal of Computer Applications, 2017, 37(1): 145-152. |
| [6] | GUAN Yaqin, ZHAO Xuesheng, WANG Pengfei, LI Dapeng. Parallel algorithm for massive point cloud simplification based on slicing principle [J]. Journal of Computer Applications, 2016, 36(7): 1793-1796. |
| [7] | ZHAO Mingchao, CHEN Zhibin, WEN Youwei. Parallel computation for image denoising via total variation dual model on GPU [J]. Journal of Computer Applications, 2016, 36(5): 1228-1231. |
| [8] | WANG Lei, WANG Pengfei, ZHAO Xuesheng, LU Lituo. Optimization of spherical Voronoi diagram generating algorithm based on graphic processing unit [J]. Journal of Computer Applications, 2015, 35(6): 1564-1566. |
| [9] | LIU Baoping, CHEN Qingkui, LI Jinjing, LIU Bocheng. Parallelization of deformable part model algorithm based on graphics processing unit [J]. Journal of Computer Applications, 2015, 35(11): 3075-3078. |
| [10] | CHEN Jingyuan LI Jianhua GUO Weibin. Improved parallel simulation of silicon anisotropic etching based on GPU [J]. Journal of Computer Applications, 2013, 33(12): 3317-3320. |
| [11] | LIU Jinming WANG Kuanquan. School of Computer Science and Technology, Harbin Institute of Technology, Harbin Heilongjiang 150001, China [J]. Journal of Computer Applications, 2013, 33(09): 2662-2666. |
| [12] | CUI Xiang JIANG Xiaofeng. Research and implementation of realistic dynamic tree scene [J]. Journal of Computer Applications, 2013, 33(06): 1711-1714. |
| [13] | HAN Yu YAN Bin YU Chao-qun LI Lei LI Jian-xin. GPU-based parallel implementation of FDK algorithm for cone-beam CT [J]. Journal of Computer Applications, 2012, 32(05): 1407-1410. |
| [14] | CHEN Ying LIN Jin-xian LV Tun. Implementation of LU decomposition and Laplace algorithms on GPU [J]. Journal of Computer Applications, 2011, 31(03): 851-855. |
| [15] | . Method of communication flow dependence analysis for shared-memory SPMD program [J]. Journal of Computer Applications, 2010, 30(3): 596-599. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||