


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (12): 3727-3732.DOI: 10.11772/j.issn.1001-9081.2022121902
• Artificial intelligence • Previous Articles Next Articles
Yulian ZHANG, Shanshan YAO( ), Chao WANG, Jiang CHANG
), Chao WANG, Jiang CHANG
Received:2022-12-29
Revised:2023-03-07
Accepted:2023-03-08
Online:2023-03-17
Published:2023-12-10
Contact:
Shanshan YAO
About author:ZHANG Yulian, born in 1997, M. S. candidate. Her research interests include voiceprint recognition.Supported by:通讯作者:
姚姗姗
作者简介:张玉莲(1997—),女,山西晋城人,硕士研究生,主要研究方向:声纹识别基金资助:CLC Number:
Yulian ZHANG, Shanshan YAO, Chao WANG, Jiang CHANG. Text-independent speaker verification method based on uncertainty learning[J]. Journal of Computer Applications, 2023, 43(12): 3727-3732.
张玉莲, 姚姗姗, 王超, 畅江. 基于不确定性学习的文本无关的说话人确认方法[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3727-3732.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022121902
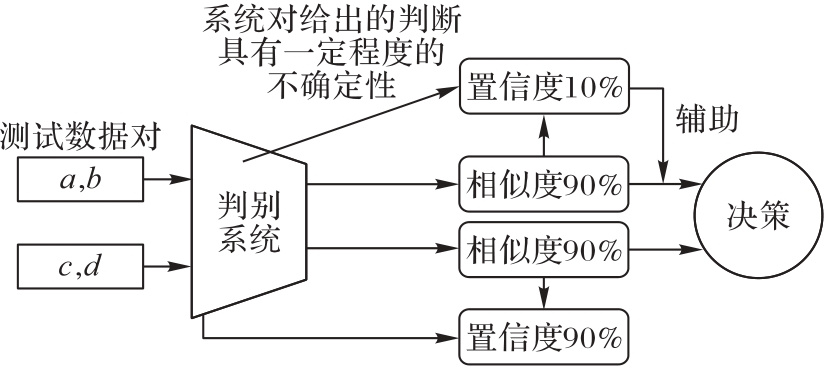
Fig.1 Schematic diagram of uncertainty

Fig.2 Certainty-based speaker verification model

Fig.3 Model architecture of TISV method based on UL
| 方法 | 层 | 卷积核大小 | 步长 | 输出尺寸 |
|---|---|---|---|---|
| 基线Thin ResNet34 | Conv1 | 3×3×32 | 1×1 | 32×64×L |
| Res1 | 3×3×32 | 1×1 | 32×64×L | |
| Res2 | 3×3×64 | 2×2 | 64×32× | |
| Res3 | 3×3×128 | 2×2 | 128×16×L/4 | |
| Res4 | 3×3×256 | 2×2 | 256×8×L/8 | |
| Flatten | — | — | 2 048×L/8 | |
| SAP | — | — | 4 096 | |
| Linear | 256 | — | 256 | |
| 本文方法 | Conv1 | 3×3×32 | 1×1 | 32×64×L |
| Res1 | 3×3×32 | 1×1 | 32×64×L | |
| Res2 | 3×3×64 | 2×2 | 64×32× | |
| Res3 | 3×3×128 | 2×2 | 128×16×L/4 | |
| Res4 | 3×3×256 | 2×2 | 256×8×L/8 | |
| Flatten | — | — | 2 048×L/8 | |
| SAP | — | — | 4 096 | |
| mu | 256 | — | 256 | |
| logvar | 256 | — | 256 |
Tab.1 Network architectures of baseline Thin ResNet34 and proposed method
| 方法 | 层 | 卷积核大小 | 步长 | 输出尺寸 |
|---|---|---|---|---|
| 基线Thin ResNet34 | Conv1 | 3×3×32 | 1×1 | 32×64×L |
| Res1 | 3×3×32 | 1×1 | 32×64×L | |
| Res2 | 3×3×64 | 2×2 | 64×32× | |
| Res3 | 3×3×128 | 2×2 | 128×16×L/4 | |
| Res4 | 3×3×256 | 2×2 | 256×8×L/8 | |
| Flatten | — | — | 2 048×L/8 | |
| SAP | — | — | 4 096 | |
| Linear | 256 | — | 256 | |
| 本文方法 | Conv1 | 3×3×32 | 1×1 | 32×64×L |
| Res1 | 3×3×32 | 1×1 | 32×64×L | |
| Res2 | 3×3×64 | 2×2 | 64×32× | |
| Res3 | 3×3×128 | 2×2 | 128×16×L/4 | |
| Res4 | 3×3×256 | 2×2 | 256×8×L/8 | |
| Flatten | — | — | 2 048×L/8 | |
| SAP | — | — | 4 096 | |
| mu | 256 | — | 256 | |
| logvar | 256 | — | 256 |
| 方法 | VoxCeleb1-O | |
|---|---|---|
| EER/% | minDCF | |
| 基线Thin ResNet34 | 2.413 | 0.304 |
| 本文方法 | 2.175 | 0.271 |
Tab.2 Evaluation results on VoxCeleb1-O test set after training on VoxCeleb1 development set
| 方法 | VoxCeleb1-O | |
|---|---|---|
| EER/% | minDCF | |
| 基线Thin ResNet34 | 2.413 | 0.304 |
| 本文方法 | 2.175 | 0.271 |
| 评估集 | 方法 | EER/% | minDCF |
|---|---|---|---|
| VoxCeleb1-O | 基线Thin ResNet34 | 1.186 | 0.132 |
| 本文方法 | 1.063 | 0.126 | |
| VoxCeleb1-E | 基线Thin ResNet34 | 1.332 | 0.152 |
| 本文方法 | 1.261 | 0.144 | |
| VoxCeleb1-H | 基线Thin ResNet34 | 2.433 | 0.244 |
| 本文方法 | 2.361 | 0.237 |
Tab.3 Evaluation results on VoxCeleb1-O、VoxCeleb1-E and VoxCeleb1-H test sets after training on VoxCeleb2 development set
| 评估集 | 方法 | EER/% | minDCF |
|---|---|---|---|
| VoxCeleb1-O | 基线Thin ResNet34 | 1.186 | 0.132 |
| 本文方法 | 1.063 | 0.126 | |
| VoxCeleb1-E | 基线Thin ResNet34 | 1.332 | 0.152 |
| 本文方法 | 1.261 | 0.144 | |
| VoxCeleb1-H | 基线Thin ResNet34 | 2.433 | 0.244 |
| 本文方法 | 2.361 | 0.237 |
| λ | 训练集为VoxCeleb1开发集 | 训练集为Voxceleb2开发集 | ||||||
|---|---|---|---|---|---|---|---|---|
| VoxCeleb1-O测试集 | VoxCeleb1-O测试集 | VoxCeleb1-E测试集 | VoxCeleb1-H测试集 | |||||
| EER/% | minDCF | EER/% | minDCF | EER/% | minDCF | EER/% | minDCF | |
| 0 | 2.319 | 0.302 | 1.164 | 0.131 | 1.312 | 0.150 | 2.403 | 0.239 |
| 10-2 | 2.217 | 0.294 | 1.138 | 0.130 | 1.251 | 0.142 | 2.351 | 0.233 |
| 10-3 | 2.175 | 0.271 | 1.063 | 0.126 | 1.261 | 0.144 | 2.361 | 0.237 |
| 10-4 | 2.185 | 0.261 | 1.106 | 0.129 | 1.262 | 0.148 | 2.345 | 0.232 |
Tab.4 Evaluation results of proposed method on different test sets and development sets with different hyperparameter λ values
| λ | 训练集为VoxCeleb1开发集 | 训练集为Voxceleb2开发集 | ||||||
|---|---|---|---|---|---|---|---|---|
| VoxCeleb1-O测试集 | VoxCeleb1-O测试集 | VoxCeleb1-E测试集 | VoxCeleb1-H测试集 | |||||
| EER/% | minDCF | EER/% | minDCF | EER/% | minDCF | EER/% | minDCF | |
| 0 | 2.319 | 0.302 | 1.164 | 0.131 | 1.312 | 0.150 | 2.403 | 0.239 |
| 10-2 | 2.217 | 0.294 | 1.138 | 0.130 | 1.251 | 0.142 | 2.351 | 0.233 |
| 10-3 | 2.175 | 0.271 | 1.063 | 0.126 | 1.261 | 0.144 | 2.361 | 0.237 |
| 10-4 | 2.185 | 0.261 | 1.106 | 0.129 | 1.262 | 0.148 | 2.345 | 0.232 |
| 约束方式 | VoxCeleb1-O | |
|---|---|---|
| EER/% | minDCF | |
| 整个数据集噪声近似高斯分布 | 1.063 | 0.126 |
| 每个batch噪声近似高斯分布 | 1.130 | 0.129 |
Tab.5 Ablation experimental results
| 约束方式 | VoxCeleb1-O | |
|---|---|---|
| EER/% | minDCF | |
| 整个数据集噪声近似高斯分布 | 1.063 | 0.126 |
| 每个batch噪声近似高斯分布 | 1.130 | 0.129 |
| 1 | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255. 10.1109/cvpr.2009.5206848 |
| 2 | HUANG G B, MATTAR M, BERG T, et al. Labeled faces in the wild: a database for studying face recognition in unconstrained environments [EB/OL]. [2019-02-25]. . 10.1117/12.2080393 |
| 3 | NAGRANI A, CHUNG J S, ZISSERMAN A. VoxCeleb: a large-scale speaker identification dataset[EB/OL]. [2018-05-30]. . 10.21437/interspeech.2017-950 |
| 4 | JOYCE J M. Kullback-Leibler divergence[M]// International Encyclopedia of Statistical Science. Cham: Springer, 2011: 720-722. 10.1007/978-3-642-04898-2_327 |
| 5 | DEHAK N, KENNY P J, DEHAK R, et al. Front-end factor analysis for speaker verification [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2010, 19(4): 788-798. 10.1109/tasl.2010.2064307 |
| 6 | HANSEN J H L, HASAN T. Speaker recognition by machines and humans: a tutorial review[J]. IEEE Signal Processing Magazine, 2015, 32(6): 74-99. 10.1109/msp.2015.2462851 |
| 7 | SNYDER D, GARCIA-ROMERO D, POVEY D, et al. Deep neural network embeddings for text-independent speaker verification[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017:999-1003. 10.21437/interspeech.2017-620 |
| 8 | NOVOSELOV S, SHULIPA A, KREMNEV I, et al. On deep speaker embeddings for text-independent speaker recognition[EB/OL]. [2018-04-26]. . 10.21437/odyssey.2018-53 |
| 9 | OKABE K, KOSHINAKA T, SHINODA K. Attentive statistics pooling for deep speaker embedding [EB/OL]. [2019-02-25]. . 10.21437/interspeech.2018-993 |
| 10 | ZHU Y, KO T, SNYDER D, et al. Self-attentive speaker embeddings for text-independent speaker verification[C]// Proceedings of the INTERSPEECH 2018. [S.l.]: International Speech Communication Association, 2018: 3573-3577. 10.21437/interspeech.2018-1158 |
| 11 | CAI W, CAI Z, ZHANG X, et al. A novel learnable dictionary encoding layer for end-to-end language identification[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5189-5193. 10.1109/icassp.2018.8462025 |
| 12 | LI C, MA X, JIANG B, et al. Deep Speaker: an end-to-end neural speaker embedding system[EB/OL]. [2017-05-05]. . |
| 13 | KWON Y, H-S HEO, LEE B-J, et al. The ins and outs of speaker recognition: lessons from VoxSRC 2020[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 5809-5813. 10.1109/icassp39728.2021.9413948 |
| 14 | DESPLANQUES B, THIENPONDT J, DEMUYNCK K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification[EB/OL]. [2020-08-10]. . 10.21437/interspeech.2020-2650 |
| 15 | WU Y, ZHAO J, GUO C, et al. Improving deep CNN architectures with variable-length training samples for text-independent speaker verification[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 81-85. 10.21437/interspeech.2021-559 |
| 16 | LIU T, DAS R K, LEE K A, et al. MFA: TDNN with multi-scale frequency-channel attention for text-independent speaker verification with short utterances[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7517-7521. 10.1109/icassp43922.2022.9747021 |
| 17 | KIM S-H, NAM H, Y-H PARK. Temporal dynamic convolutional neural network for text-independent speaker verification and phonemic analysis[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6742-6746. 10.1109/icassp43922.2022.9747421 |
| 18 | 陈晨, 肜娅峰, 季超群, 等. 基于深层信息散度最大化的说话人确认方法[J]. 通信学报, 2021, 42(7): 231-237. 10.11959/j.issn.1000-436x.2021133 |
| CHEN C, RONG Y F, JI C Q, et al. Speaker verification method based on deep information divergence maximization[J]. Journal on Communication, 2021, 42(7): 231-237. 10.11959/j.issn.1000-436x.2021133 | |
| 19 | 姜珊, 张二华, 张晗. 基于 Bi-GRU+BFE模型的短语音说话人识别[J]. 计算机与数字工程, 2022, 50(10): 2233-2239. |
| JIANG S, ZHANG E H, ZHANG H. Speaker recognition under short utterance based on Bi-GRU+BFE model[J]. Computer and Digital Engineering, 2022, 50(10): 2233-2239. | |
| 20 | ISOBE S, ARAI S. Deep convolutional encoder-decoder network with model uncertainty for semantic segmentation[C]// Proceedings of the 2017 IEEE International Conference on INnovations in Intelligent SysTems and Applications. Piscataway: IEEE, 2017: 365-370. 10.1109/inista.2017.8001187 |
| 21 | HU P, SCLAROFF S, SAENKO K. Uncertainty-aware learning for zero-shot semantic segmentation[J]. Advances in Neural Information Processing Systems, 2020, 33: 21713-21724. |
| 22 | CHOI J, CHUN D, KIM H, et al. Gaussian YOLOv3: an accurate and fast object detector using localization uncertainty for autonomous driving[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE,2019: 502-511. 10.1109/iccv.2019.00059 |
| 23 | YU T, LI D, YANG Y, et al. Robust person re-identification by modelling feature uncertainty [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 552-561. 10.1109/iccv.2019.00064 |
| 24 | SHI Y, JAIN A K. Probabilistic face embeddings[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE,2019: 6901-6910. 10.1109/iccv.2019.00700 |
| 25 | CHANG J, LAN Z, CHENG C, et al. Data uncertainty learning in face recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 5709-5718. 10.1109/cvpr42600.2020.00575 |
| 26 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2016: 770-778. 10.1109/cvpr.2016.90 |
| 27 | CAI W, CHEN J, LI M. Exploring the encoding layer and loss function in end-to-end speaker and language recognition system[EB/OL]. [2018-04-14]. . 10.21437/odyssey.2018-11 |
| 28 | DENG J, GUO J, XUE N, et al. ArcFace: additive angular margin loss for deep face recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2019: 4690-4699. 10.1109/cvpr.2019.00482 |
| 29 | KINGMA D P, WELLING M. Auto-encoding variational Bayes[EB/OL]. [2018-04-14]. . 10.1561/2200000056 |
| 30 | ALEMI A A, FISCHER I, DILLON J V, et al. Deep variational information bottleneck[EB/OL]. [2019-10-23]. . |
| 31 | NAGRANI A, CHUNG J S, XIE W, et al. VoxCeleb: large-scale speaker verification in the wild[J]. Computer Speech & Language, 2020, 60: 101027. 10.1016/j.csl.2019.101027 |
| 32 | SNYDER D, CHEN G, POVEY D. MUSAN: a music, speech, and noise corpus[EB/OL]. [2019-10-23].. |
| 33 | KO T, PEDDINTI V, POVEY D, et al. A study on data augmentation of reverberant speech for robust speech recognition[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 5220-5224. 10.1109/icassp.2017.7953152 |
| 34 | DODDINGTON G R, PRZYBOCKI M A, MARTIN A F, et al. The NIST speaker recognition evaluation — overview, methodology, systems, results, perspective[J]. Speech Communication, 2000, 31(2/3): 225-254. 10.1016/s0167-6393(99)00080-1 |
| 35 | CHUNG J S, NAGRANI A, ZISSERMAN A. VoxCeleb2: deep speaker recognition[EB/OL]. [2018-04-14]. . 10.21437/interspeech.2018-1929 |
| 36 | CAI W, CHEN J, LI M. Exploring the encoding layer and loss function in end-to-end speaker and language recognition system[EB/OL]. [2018-04-14].. 10.21437/odyssey.2018-11 |
| 37 | PARK D S, CHAN W, ZHANG Y, et al. SpecAugment: a simple data augmentation method for automatic speech recognition [EB/OL]. [2019-12-03].. 10.21437/interspeech.2019-2680 |
| 38 | LOSHCHILOV I, HUTTER F. SGDR: stochastic gradient descent with warm restarts[EB/OL]. [2018-04-14]. . |
| [1] | Jing Zhao . Mandarin-Sichuan dialect bilingual text-independent speaker verification using GMM [J]. Journal of Computer Applications, 2008, 28(3): 792-794. |
| [2] | . Application of variable frame length and frame rate in speaker verification system [J]. Journal of Computer Applications, 2007, 27(8): 2051-2052. |
| [3] | . MFCC feature extraction of speech based on pitch period [J]. Journal of Computer Applications, 2007, 27(5): 1217-1219. |
| [4] | . Robust speaker verification in low bit rate channels [J]. Journal of Computer Applications, 2007, 27(4): 919-921. |
| [5] | Xin-Jian Gao Dan Qu . New score normalization method in speaker verification [J]. Journal of Computer Applications, 2007, 27(10): 2602-2604. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||