


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (2): 393-402.DOI: 10.11772/j.issn.1001-9081.2023020143
• Artificial intelligence • Previous Articles
Andi GUO1, Zhen JIA1, Tianrui LI1,2( )
)
Received:2023-02-20
Revised:2023-03-21
Accepted:2023-04-03
Online:2023-08-14
Published:2024-02-10
Contact:
Tianrui LI
About author:GUO Andi, born in 1998, M. S. candidate. His research interests include natural language processing, knowledge graph.Supported by:通讯作者:
李天瑞
作者简介:郭安迪(1998—),男,山东菏泽人,硕士研究生,CCF学生会员,主要研究方向:自然语言处理、知识图谱基金资助:CLC Number:
Andi GUO, Zhen JIA, Tianrui LI. High-precision entity and relation extraction in medical domain based on pseudo-entity data augmentation[J]. Journal of Computer Applications, 2024, 44(2): 393-402.
郭安迪, 贾真, 李天瑞. 基于伪实体数据增强的高精准率医学领域实体关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 393-402.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023020143
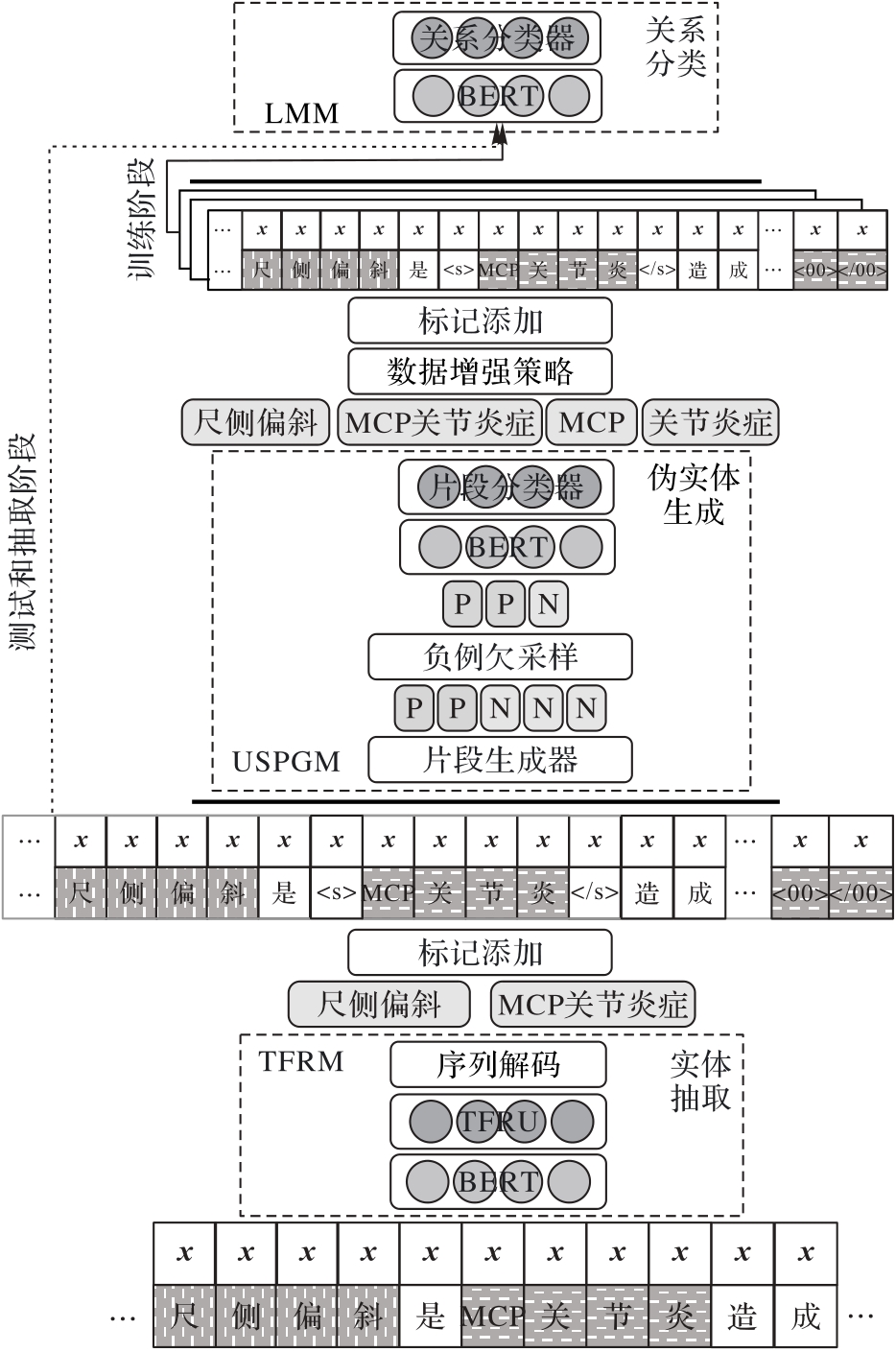
Fig. 1 Schematic diagram of overall model process

Fig. 2 Schematic diagram of TFRM

Fig. 3 Schematic diagram of USPGM
| 数据集类型 | 数据条目 | 关系数 | 主语数 | 宾语数 |
|---|---|---|---|---|
| 训练集 | 14 339 | 43 660 | 18 797 | 41 478 |
| 测试集 | 3 585 | 10 626 | 4 627 | 10 123 |
| 增强集 | 14 339 | 450 053 | 26 028 | 113 630 |
Tab. 1 Information of CMeIE dataset used in experiment
| 数据集类型 | 数据条目 | 关系数 | 主语数 | 宾语数 |
|---|---|---|---|---|
| 训练集 | 14 339 | 43 660 | 18 797 | 41 478 |
| 测试集 | 3 585 | 10 626 | 4 627 | 10 123 |
| 增强集 | 14 339 | 450 053 | 26 028 | 113 630 |

Fig. 4 Attention mask matrix in LMM

Fig. 5 Distribution of entity segment size
| 模型 | 预热率 | 批大小 | lr/10-5 | 实体抽取 | 关系分类 | |
|---|---|---|---|---|---|---|
| Epoch | 最大片段长度 | Epoch | ||||
| SpERT | 0.1 | 2 | 5 | — | 20 | 20 |
| PURE | 0.1 | 32 | 5 | 7 | — | 10 |
| PL-Marker | 0.1 | 32 | 5 | 7 | 20 | 8 |
| CBLUE | 0.1 | 32 | 5 | 7 | — | 8 |
| 本文模型 | 0.1 | 32 | 5 | 7 | — | 8 |
Tab. 2 Details of experimental parameters
| 模型 | 预热率 | 批大小 | lr/10-5 | 实体抽取 | 关系分类 | |
|---|---|---|---|---|---|---|
| Epoch | 最大片段长度 | Epoch | ||||
| SpERT | 0.1 | 2 | 5 | — | 20 | 20 |
| PURE | 0.1 | 32 | 5 | 7 | — | 10 |
| PL-Marker | 0.1 | 32 | 5 | 7 | 20 | 8 |
| CBLUE | 0.1 | 32 | 5 | 7 | — | 8 |
| 本文模型 | 0.1 | 32 | 5 | 7 | — | 8 |
| 模型 | 实体抽取 | 关系抽取 | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| SpERT | 59.66 | 78.23 | 67.70 | 46.79 | 46.86 | 46.82 |
| PURE | 72.94 | 70.48 | 71.69 | 53.87 | 48.70 | 51.16 |
| PL-Marker | 75.47 | 70.55 | 72.92 | 57.71 | 50.08 | 53.63 |
| CBLUE | 72.76 | 72.10 | 72.43 | 59.65 | 49.23 | 53.94 |
| 本文模型 | 76.01 | 73.20 | 74.57 | 68.97 | 48.39 | 56.88 |
Tab. 3 Comparison of experimental results among different models
| 模型 | 实体抽取 | 关系抽取 | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| SpERT | 59.66 | 78.23 | 67.70 | 46.79 | 46.86 | 46.82 |
| PURE | 72.94 | 70.48 | 71.69 | 53.87 | 48.70 | 51.16 |
| PL-Marker | 75.47 | 70.55 | 72.92 | 57.71 | 50.08 | 53.63 |
| CBLUE | 72.76 | 72.10 | 72.43 | 59.65 | 49.23 | 53.94 |
| 本文模型 | 76.01 | 73.20 | 74.57 | 68.97 | 48.39 | 56.88 |
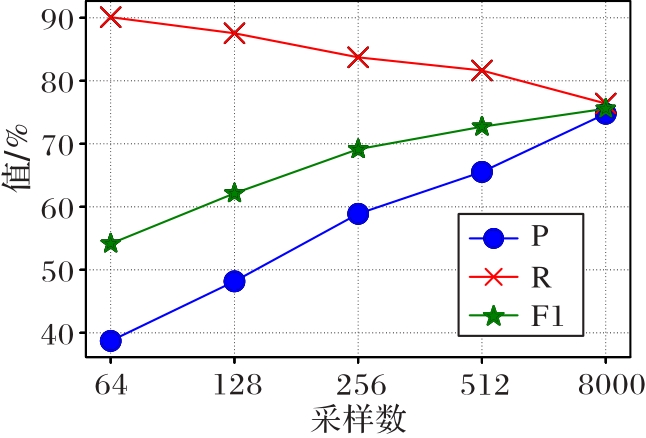
Fig. 6 Sampling number-model performance line chart
| 模型 | 关系抽取 | ||
|---|---|---|---|
| P | R | F1 | |
| Ground Truth | 85.69 | 60.08 | 70.64 |
| PURE | 67.84 | 44.48 | 53.73 |
| PL-Marker | 69.52 | 45.29 | 54.85 |
| CBLUE | 69.08 | 47.47 | 56.27 |
| TFRM | 69.97 | 48.39 | 56.88 |
Tab. 4 Comparison of experimental results of entity extraction models
| 模型 | 关系抽取 | ||
|---|---|---|---|
| P | R | F1 | |
| Ground Truth | 85.69 | 60.08 | 70.64 |
| PURE | 67.84 | 44.48 | 53.73 |
| PL-Marker | 69.52 | 45.29 | 54.85 |
| CBLUE | 69.08 | 47.47 | 56.27 |
| TFRM | 69.97 | 48.39 | 56.88 |
| 模型 | 实体抽取 | 实体关系抽取 | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| 未用TFRU | 71.52 | 72.04 | 71.52 | 69.08 | 47.47 | 56.27 |
| 1层 TFRU | 76.80 | 71.94 | 74.29 | 70.22 | 46.46 | 55.92 |
| 2层 TFRU | 76.01 | 73.20 | 74.57 | 69.97 | 48.39 | 56.88 |
| 3层 TFRU | 76.47 | 72.96 | 74.67 | 69.98 | 48.14 | 56.86 |
Tab. 5 Comparison experiment results of TFRU module parameters
| 模型 | 实体抽取 | 实体关系抽取 | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| 未用TFRU | 71.52 | 72.04 | 71.52 | 69.08 | 47.47 | 56.27 |
| 1层 TFRU | 76.80 | 71.94 | 74.29 | 70.22 | 46.46 | 55.92 |
| 2层 TFRU | 76.01 | 73.20 | 74.57 | 69.97 | 48.39 | 56.88 |
| 3层 TFRU | 76.47 | 72.96 | 74.67 | 69.98 | 48.14 | 56.86 |

Fig. 7 TFRU attention visualization
| 增强策略 | 实标记 | 悬浮标记 | ||||||
|---|---|---|---|---|---|---|---|---|
| P/% | R/% | F1/% | 每秒采样数 | P/% | R/% | F1/% | 每秒采样数 | |
| 59.65 | 49.23 | 53.94 | 173.7 | 57.71 | 50.08 | 53.63 | 729.8 | |
| 57.71 | 52.01 | 54.71 | 58.86 | 51.86 | 54.90 | |||
| 57.61 | 52.08 | 54.71 | 57.60 | 52.00 | 54.65 | |||
| 60.43 | 51.99 | 55.89 | 60.48 | 51.22 | 55.47 | |||
| 61.97 | 51.13 | 56.03 | 61.94 | 50.69 | 55.75 | |||
| 62.15 | 50.75 | 55.87 | 62.17 | 50.91 | 55.98 | |||
| 68.09 | 47.00 | 55.61 | 67.68 | 47.42 | 55.77 | |||
| 67.85 | 44.97 | 54.09 | 68.97 | 48.39 | 56.88 | |||
| 72.48 | 45.06 | 55.57 | 71.12 | 46.46 | 56.20 | |||
Tab. 6 Ablation experimental results of automatic generation module of relation negative examples
| 增强策略 | 实标记 | 悬浮标记 | ||||||
|---|---|---|---|---|---|---|---|---|
| P/% | R/% | F1/% | 每秒采样数 | P/% | R/% | F1/% | 每秒采样数 | |
| 59.65 | 49.23 | 53.94 | 173.7 | 57.71 | 50.08 | 53.63 | 729.8 | |
| 57.71 | 52.01 | 54.71 | 58.86 | 51.86 | 54.90 | |||
| 57.61 | 52.08 | 54.71 | 57.60 | 52.00 | 54.65 | |||
| 60.43 | 51.99 | 55.89 | 60.48 | 51.22 | 55.47 | |||
| 61.97 | 51.13 | 56.03 | 61.94 | 50.69 | 55.75 | |||
| 62.15 | 50.75 | 55.87 | 62.17 | 50.91 | 55.98 | |||
| 68.09 | 47.00 | 55.61 | 67.68 | 47.42 | 55.77 | |||
| 67.85 | 44.97 | 54.09 | 68.97 | 48.39 | 56.88 | |||
| 72.48 | 45.06 | 55.57 | 71.12 | 46.46 | 56.20 | |||
| 案例 | 类别 | 实体关系样例 |
|---|---|---|
| 案例一 | 标准答案 | [Miller-Fisher综合征] |
未进行 数据增强 | [Miller-Fisher综合征] | |
| 数据增强 | [Miller-Fisher综合征] | |
| 案例二 | 标准答案 | [室上速] |
未进行 数据增强 | [室上速] | |
| 数据增强 | [室上速] |
Tab. 7 Case analysis
| 案例 | 类别 | 实体关系样例 |
|---|---|---|
| 案例一 | 标准答案 | [Miller-Fisher综合征] |
未进行 数据增强 | [Miller-Fisher综合征] | |
| 数据增强 | [Miller-Fisher综合征] | |
| 案例二 | 标准答案 | [室上速] |
未进行 数据增强 | [室上速] | |
| 数据增强 | [室上速] |
| 1 | 宁尚明,滕飞,李天瑞.基于多通道自注意力机制的电子病历实体关系抽取[J].计算机学报,2020,43(5): 916-929. 10.11897/SP.J.1016.2020.00916 |
| NING S M, TENG F, LI T R. Multi-channel self-attention mechanism for relation extraction in clinical records [J]. Chinese Journal of Computers, 2020, 43(5): 916-929. 10.11897/SP.J.1016.2020.00916 | |
| 2 | ZHONG Z, CHEN D. A frustratingly easy approach for entity and relation extraction [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsberg: ACL, 2021: 50-61. 10.18653/v1/2021.naacl-main.5 |
| 3 | YE D, LIN Y, LI P, et al. Packed levitated marker for entity and relation extraction [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsberg: ACL, 2022: 4904-4917. 10.18653/v1/2022.acl-long.337 |
| 4 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 5 | BLASCHKE C, VALENCIA A. The frame-based module of the SUISEKI information extraction system [J]. IEEE Intelligent Systems, 2002, 17(2): 14-20. 10.1109/mis.2002.999215 |
| 6 | CORNEY D P, JONES D T, BUXTON B F, et al. Extracting biological information from full-length papers:RN/ 03/17 [R/OL].[2022-02-01]. . 10.1093/bioinformatics/bth386 |
| 7 | FUNDEL K, KÜFFNER R, ZIMMER R. RelEx — Relation extraction using dependency parse trees [J]. Bioinformatics, 2007, 23(3): 365-371. 10.1093/bioinformatics/btl616 |
| 8 | ZHAO Z, YANG Z, SUN C, et al. A hybrid protein-protein interaction triple extraction method for biomedical literature [C]// Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine. Piscataway: IEEE, 2017: 1515-1521. 10.1109/bibm.2017.8217886 |
| 9 | KORDJAMSHIDI P, ROTH D, M-F MOENS. Structured learning for spatial information extraction from biomedical text: bacteria biotopes [J]. BMC Bbioinformatics, 2015, 16: Article No. 129. 10.1186/s12859-015-0542-z |
| 10 | KORDJAMSHIDI P, VAN OTTERLO M, M-F MOENS. Spatial role labeling: towards extraction of spatial relations from natural language [J]. ACM Transactions on Speech and Language Processing, 2011, 8(3): Article No. 4. 10.1145/2050104.2050105 |
| 11 | 刘奔,姬东鸿.药物实体和药物相互关系的联合识别 [J].计算机工程与设计,2017,38(5):1377-1381. 10.16208/j.issn1000-7024.2017.05.048 |
| LIU B, JI D H. Joint extraction of drug entity and drug-drug interaction[J]. Computer Engineering and Design, 2017, 38(5): 1377-1381. 10.16208/j.issn1000-7024.2017.05.048 | |
| 12 | LI F, ZHANG M, FU G, et al. A neural joint model for entity and relation extraction from biomedical text [J]. BMC Bioinformatics, 2017, 18: Article No. 198. 10.1186/s12859-017-1609-9 |
| 13 | BEKOULIS G, DELEU J, DEMEESTER T, et al. Adversarial training for multi-context joint entity and relation extraction [EB/OL]. (2019-01-14) [2022-05-06]. . 10.18653/v1/d18-1307 |
| 14 | 张世豪,杜圣东,贾真,等.基于深度神经网络和自注意力机制的医学实体关系抽取[J].计算机科学,2021,48(10): 77-84. 10.11896/jsjkx.210300271 |
| ZHANG S H, DU S D, JIA Z, et al. Medical entity relation extraction based on deep neural network and self-attention mechanism [J]. Computer Science, 2021, 48(10): 77-84. 10.11896/jsjkx.210300271 | |
| 15 | DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2019-05-24) [2019-09-01]. . 10.18653/v1/n18-2 |
| 16 | PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsberg: ACL, 2018: 2227-2237. 10.18653/v1/n18-1202 |
| 17 | LUO L, YANG Z, CAO M, et al. A neural network-based joint learning approach for biomedical entity and relation extraction from biomedical literature [J]. Journal of Biomedical Informatics, 2020, 103: 103384. 10.1016/j.jbi.2020.103384 |
| 18 | ZHAO T, YAN Z, CAO Y, et al. Asking effective and diverse questions: a machine reading comprehension based framework for joint entity-relation extraction [C]// Proceedings of the 29th International Joint Conferences on Artificial Intelligence. California: ijcai.org, 2021: 3948-3954. 10.24963/ijcai.2020/546 |
| 19 | EBERTS M, ULGES A. Span-based joint entity and relation extraction with transformer pre-training[EB/OL]. [2023-02-01]. . 10.18653/v1/2021.eacl-main.319 |
| 20 | SHEN Y, MA X, TANG Y, et al. A trigger-sense memory flow framework for joint entity and relation extraction [C]// Proceedings of the Web Conference 2021. New York: ACM, 2021: 1704-1715. 10.1145/3442381.3449895 |
| 21 | FENG S Y, GANGAL V, WEI J, et al. A survey of data augmentation approaches for NLP [C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsberg: ACL, 2021: 968-988. 10.18653/v1/2021.findings-acl.84 |
| 22 | WEI J, ZOU K. EDA: Easy data augmentation techniques for boosting performance on text classification tasks [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsberg: ACL, 2019: 6382-6388. 10.18653/v1/d19-1670 |
| 23 | ABDOLLAHI M, GAO X, MEI Y, et al. Substituting clinical features using synthetic medical phrases: medical text data augmentation techniques [J]. Artificial Intelligence in Medicine, 2021, 120(C): 102167. 10.1016/j.artmed.2021.102167 |
| 24 | KANG T, PEROTTE A, TANG Y, et al. UMLS-based data augmentation for natural language processing of clinical research literature [J]. Journal of the American Medical Informatics Association, 2021, 28(4): 812-823. 10.1093/jamia/ocaa309 |
| 25 | SENNRICH R, HADDOW B, BIRCH A. Improving neural machine translation models with monolingual data [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsberg: ACL, 2016: 86-96. 10.18653/v1/p16-1009 |
| 26 | WANG A, LI L, WU X, et al. Entity relation extraction in the medical domain: based on data augmentation [J]. Annals of Translational Medicine, 2022, 10(19): 1061-1073. 10.21037/atm-22-3991 |
| 27 | KOBAYASHI S. Contextual augmentation: data augmentation by words with paradigmatic relations [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). Stroudsberg: ACL, 2018: 452-457. 10.18653/v1/n18-2072 |
| 28 | YANG Y, MALAVIYA C, FERNANDEZ J, et al. Generative data augmentation for commonsense reasoning [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsberg: ACL, 2020: 1008-1025. 10.18653/v1/2020.findings-emnlp.90 |
| 29 | QUTEINEH H, SAMOTHRAKIS S, SUTCLIFFE R. Textual data augmentation for efficient active learning on tiny datasets [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsberg: ACL, 2020: 7400-7410. 10.18653/v1/2020.emnlp-main.600 |
| 30 | WOLF T, DEBUT L, SANH V, et al. HuggingFace’s Transformers: state-of-the-art natural language processing [EB/OL].(2020-07-14)[2022-06-03]. . 10.18653/v1/2020.emnlp-demos.6 |
| 31 | ZHANG N, CHEN M, BI Z, et al. CBLUE: a Chinese biomedical language understanding evaluation benchmark [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsberg: ACL, 2022: 7888-7915. 10.18653/v1/2022.acl-long.544 |
| [1] | Yimin CAO, Lei CAI, Jingyang GAO. Gene data generation method based on generative adversarial network [J]. Journal of Computer Applications, 2022, 42(3): 783-790. |
| [2] | Qiujie SUN, Jinggui LIANG, Si LI. Chinese grammatical error correction model based on bidirectional and auto-regressive transformers noiser [J]. Journal of Computer Applications, 2022, 42(3): 860-866. |
| [3] | Yu PENG, Yaolian SONG, Jun YANG. Motor imagery electroencephalography classification based on data augmentation [J]. Journal of Computer Applications, 2022, 42(11): 3625-3632. |
| [4] | Ping LUO, Ling DING, Xue YANG, Yang XIANG. Chinese event detection based on data augmentation and weakly supervised adversarial training [J]. Journal of Computer Applications, 2022, 42(10): 2990-2995. |
| [5] | Shuang DENG, Xiaohai HE, Linbo QING, Honggang CHEN, Qizhi TENG. Weakly supervised fine-grained classification method of Alzheimer’s disease based on improved visual geometry group network [J]. Journal of Computer Applications, 2022, 42(1): 302-309. |
| [6] | LIU Yaxuan, ZHONG Yong. Joint extraction method of entities and relations based on subject attention [J]. Journal of Computer Applications, 2021, 41(9): 2517-2522. |
| [7] | JIA Chengxun, LAI Hua, YU Zhengtao, WEN Yonghua, YU Zhiqiang. Chinese-Vietnamese pseudo-parallel corpus generation based on monolingual language model [J]. Journal of Computer Applications, 2021, 41(6): 1652-1658. |
| [8] | LU Xinwei, YU Pengfei, LI Haiyan, LI Hongsong, DING Wenqian. Weakly supervised fine-grained image classification algorithm based on attention-attention bilinear pooling [J]. Journal of Computer Applications, 2021, 41(5): 1319-1325. |
| [9] | GAN Lan, SHEN Hongfei, WANG Yao, ZHANG Yuejin. Data augmentation method based on improved deep convolutional generative adversarial networks [J]. Journal of Computer Applications, 2021, 41(5): 1305-1313. |
| [10] | HUO Shoujun, HAO Yan, SHI Huiyu, DONG Yanqing, CAO Rui. Pattern recognition of motor imagery EEG based on deep convolutional network [J]. Journal of Computer Applications, 2021, 41(4): 1042-1048. |
| [11] | Yunpeng GONG, Zhiyong ZENG, Feng YE. Person re-identification method based on grayscale feature enhancement [J]. Journal of Computer Applications, 2021, 41(12): 3590-3595. |
| [12] | CHEN Li, WANG Hongyuan, ZHANG Yunpeng, CAO Liang, YIN Yuchang. Video-based person re-identification method by jointing evenly sampling-random erasing and global temporal feature pooling [J]. Journal of Computer Applications, 2021, 41(1): 164-169. |
| [13] | CHEN Foji, ZHU Feng, WU Qingxiao, HAO Yingming, WANG Ende. Infrared image data augmentation based on generative adversarial network [J]. Journal of Computer Applications, 2020, 40(7): 2084-2088. |
| [14] | CHENG Guangtao, GONG Jiachang, LI Jian. Smoke recognition method based on dense convolutional neural network [J]. Journal of Computer Applications, 2020, 40(5): 1465-1469. |
| [15] | FAN Wei, DUAN Bokun, HUANG Rui, LIU Ting, ZHANG Ning. Interactive augmentation method for aircraft engine borescope inspection images based on style transfer [J]. Journal of Computer Applications, 2020, 40(12): 3631-3636. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||