


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (2): 584-593.DOI: 10.11772/j.issn.1001-9081.2024010139
• Multimedia computing and computer simulation • Previous Articles
Linhao LI1,2,3, Yize WANG1, Yingshuang LI1,2,3( ), Yongfeng DONG1,2,3, Zhen WANG1,2,3
), Yongfeng DONG1,2,3, Zhen WANG1,2,3
Received:2024-02-06
Revised:2024-04-11
Accepted:2024-04-24
Online:2024-05-09
Published:2025-02-10
Contact:
Yingshuang LI
About author:LI Linhao, born in 1989, Ph. D., associate professor. His research interests include machine learning, computer vision, knowledge inference.Supported by:
李林昊1,2,3, 王逸泽1, 李英双1,2,3(), 董永峰1,2,3, 王振1,2,3
通讯作者:
李英双
作者简介:李林昊(1989—),男,山东威海人,副教授,博士,CCF会员,主要研究方向:机器学习、计算机视觉、知识推理基金资助:CLC Number:
Linhao LI, Yize WANG, Yingshuang LI, Yongfeng DONG, Zhen WANG. Panoptic scene graph generation method based on relation feature enhancement[J]. Journal of Computer Applications, 2025, 45(2): 584-593.
李林昊, 王逸泽, 李英双, 董永峰, 王振. 基于关系特征强化的全景场景图生成方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 584-593.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024010139

Fig. 1 Statistical graph of different types of subject-object pair

Fig. 2 PSGG method based on relation feature enhancement

Fig. 3 Different geometric positional relationships
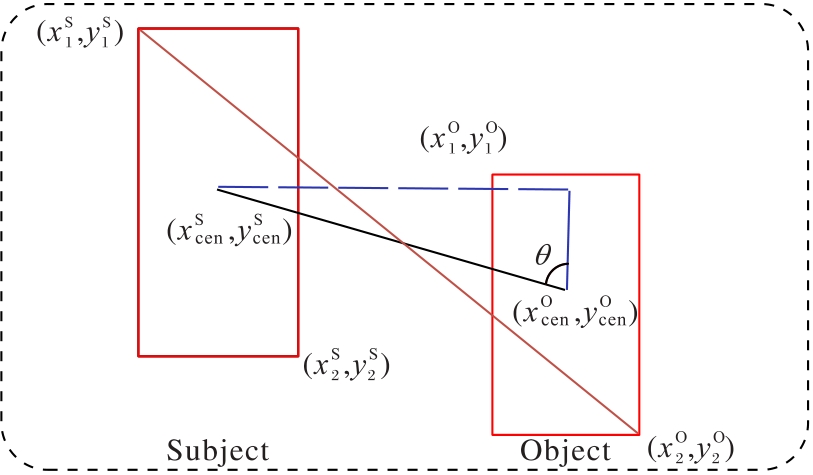
Fig. 4 Relative position feature extraction
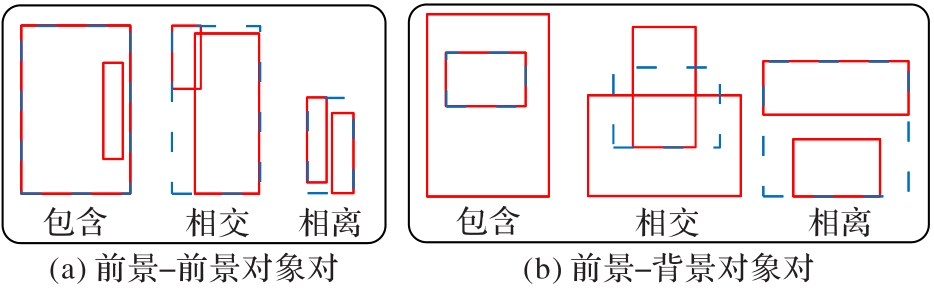
Fig. 5 Joint interaction area of subject-object pair

Fig. 6 Adaptive feature extraction method for visual features
| 对象对类型 | 占比/% |
|---|---|
| 前景-前景对象对 | 34 |
| 背景-背景对象对 | 21 |
| 前景-背景对象对 | 45 |
Tab. 1 Statistics of relationship types in each image
| 对象对类型 | 占比/% |
|---|---|
| 前景-前景对象对 | 34 |
| 背景-背景对象对 | 21 |
| 前景-背景对象对 | 45 |
| 骨干网络 | 方法 | PredCls | SGGen | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@20 | mR@20 | R@50 | mR@50 | R@100 | mR@100 | R@20 | mR@20 | R@50 | mR@50 | R@100 | mR@100 | ||
| ResNet-50 | VCTree[ | 45.23 | 20.47 | 50.76 | 22.56 | 52.67 | 23.27 | 20.60 | 9.56 | 22.10 | 10.03 | 22.50 | 10.18 |
| VCTree-RFE | 47.56 | 21.16 | 53.22 | 23.01 | 54.96 | 23.80 | 24.81 | 11.32 | 25.32 | 11.49 | 25.34 | 11.43 | |
| Motifs[ | 44.86 | 20.16 | 50.38 | 22.09 | 52.32 | 22.89 | 19.77 | 9.05 | 21.78 | 9.56 | 22.44 | 9.67 | |
| Motifs-RFE* | 46.64 | 21.04 | 52.24 | 22.89 | 54.42 | 23.24 | 23.45 | 10.33 | 25.12 | 11.62 | 25.87 | 11.96 | |
| IMP[ | 31.87 | 9.53 | 36.78 | 10.87 | 38.88 | 11.59 | 16.45 | 6.49 | 18.21 | 6.88 | 18.58 | 7.08 | |
| IMP-RFE* | 32.97 | 9.73 | 37.88 | 11.07 | 39.98 | 11.79 | 18.55 | 6.95 | 20.34 | 7.43 | 20.76 | 7.72 | |
| GPSNet[ | 31.46 | 13.19 | 39.87 | 16.38 | 44.67 | 18.28 | 16.76 | 5.75 | 18.43 | 6.31 | 19.15 | 6.50 | |
| GPSNet-RFE* | 31.86 | 13.79 | 40.27 | 16.98 | 45.17 | 18.88 | 18.48 | 5.98 | 20.14 | 6.54 | 20.86 | 6.78 | |
| ResNet-101 | VCTree[ | 45.86 | 21.32 | 51.16 | 23.08 | 53.07 | 23.76 | 21.59 | 9.56 | 23.32 | 10.09 | 24.01 | 10.28 |
| VCTree-RFE* | 47.96 | 22.14 | 53.75 | 23.61 | 55.32 | 24.56 | 25.96 | 11.37 | 26.70 | 11.54 | 26.80 | 11.58 | |
| Motifs[ | 45.08 | 19.87 | 50.48 | 21.48 | 52.48 | 22.16 | 19.29 | 9.44 | 21.09 | 9.98 | 21.74 | 10.11 | |
| Motifs-RFE* | 46.94 | 20.43 | 53.14 | 22.36 | 54.63 | 22.74 | 22.97 | 10.83 | 24.43 | 11.21 | 25.12 | 11.43 | |
| IMP[ | 30.47 | 8.97 | 35.87 | 10.47 | 38.28 | 11.39 | 17.88 | 7.09 | 19.46 | 7.53 | 20.06 | 7.71 | |
| IMP-RFE* | 31.68 | 9.23 | 36.98 | 11.07 | 39.68 | 11.49 | 19.96 | 7.21 | 21.50 | 7.73 | 22.32 | 8.01 | |
| GPSNet[ | 38.76 | 15.62 | 46.56 | 18.62 | 49.97 | 20.89 | 18.36 | 6.55 | 19.95 | 7.08 | 20.56 | 7.25 | |
| GPSNet-RFE* | 38.36 | 16.98 | 47.15 | 20.18 | 50.53 | 22.26 | 20.16 | 6.77 | 21.76 | 7.36 | 22.39 | 7.53 | |
Tab. 2 Comparison results of RFE and baseline methods on PSG dataset
| 骨干网络 | 方法 | PredCls | SGGen | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@20 | mR@20 | R@50 | mR@50 | R@100 | mR@100 | R@20 | mR@20 | R@50 | mR@50 | R@100 | mR@100 | ||
| ResNet-50 | VCTree[ | 45.23 | 20.47 | 50.76 | 22.56 | 52.67 | 23.27 | 20.60 | 9.56 | 22.10 | 10.03 | 22.50 | 10.18 |
| VCTree-RFE | 47.56 | 21.16 | 53.22 | 23.01 | 54.96 | 23.80 | 24.81 | 11.32 | 25.32 | 11.49 | 25.34 | 11.43 | |
| Motifs[ | 44.86 | 20.16 | 50.38 | 22.09 | 52.32 | 22.89 | 19.77 | 9.05 | 21.78 | 9.56 | 22.44 | 9.67 | |
| Motifs-RFE* | 46.64 | 21.04 | 52.24 | 22.89 | 54.42 | 23.24 | 23.45 | 10.33 | 25.12 | 11.62 | 25.87 | 11.96 | |
| IMP[ | 31.87 | 9.53 | 36.78 | 10.87 | 38.88 | 11.59 | 16.45 | 6.49 | 18.21 | 6.88 | 18.58 | 7.08 | |
| IMP-RFE* | 32.97 | 9.73 | 37.88 | 11.07 | 39.98 | 11.79 | 18.55 | 6.95 | 20.34 | 7.43 | 20.76 | 7.72 | |
| GPSNet[ | 31.46 | 13.19 | 39.87 | 16.38 | 44.67 | 18.28 | 16.76 | 5.75 | 18.43 | 6.31 | 19.15 | 6.50 | |
| GPSNet-RFE* | 31.86 | 13.79 | 40.27 | 16.98 | 45.17 | 18.88 | 18.48 | 5.98 | 20.14 | 6.54 | 20.86 | 6.78 | |
| ResNet-101 | VCTree[ | 45.86 | 21.32 | 51.16 | 23.08 | 53.07 | 23.76 | 21.59 | 9.56 | 23.32 | 10.09 | 24.01 | 10.28 |
| VCTree-RFE* | 47.96 | 22.14 | 53.75 | 23.61 | 55.32 | 24.56 | 25.96 | 11.37 | 26.70 | 11.54 | 26.80 | 11.58 | |
| Motifs[ | 45.08 | 19.87 | 50.48 | 21.48 | 52.48 | 22.16 | 19.29 | 9.44 | 21.09 | 9.98 | 21.74 | 10.11 | |
| Motifs-RFE* | 46.94 | 20.43 | 53.14 | 22.36 | 54.63 | 22.74 | 22.97 | 10.83 | 24.43 | 11.21 | 25.12 | 11.43 | |
| IMP[ | 30.47 | 8.97 | 35.87 | 10.47 | 38.28 | 11.39 | 17.88 | 7.09 | 19.46 | 7.53 | 20.06 | 7.71 | |
| IMP-RFE* | 31.68 | 9.23 | 36.98 | 11.07 | 39.68 | 11.49 | 19.96 | 7.21 | 21.50 | 7.73 | 22.32 | 8.01 | |
| GPSNet[ | 38.76 | 15.62 | 46.56 | 18.62 | 49.97 | 20.89 | 18.36 | 6.55 | 19.95 | 7.08 | 20.56 | 7.25 | |
| GPSNet-RFE* | 38.36 | 16.98 | 47.15 | 20.18 | 50.53 | 22.26 | 20.16 | 6.77 | 21.76 | 7.36 | 22.39 | 7.53 | |
| 方法 | 融合 策略 | SGGen/% | ||
|---|---|---|---|---|
| R@20 | R@50 | R@100 | ||
| VCTree-RFE | sum | 25.96 | 26.70 | 26.80 |
| cat | 24.83 | 25.31 | 25.42 | |
| prod | 24.76 | 25.51 | 25.36 | |
| Motifs-RFE | sum | 22.97 | 24.43 | 25.12 |
| cat | 21.37 | 23.16 | 24.10 | |
| prod | 21.40 | 23.23 | 24.12 | |
Tab. 3 Comparison of different feature fusion strategies
| 方法 | 融合 策略 | SGGen/% | ||
|---|---|---|---|---|
| R@20 | R@50 | R@100 | ||
| VCTree-RFE | sum | 25.96 | 26.70 | 26.80 |
| cat | 24.83 | 25.31 | 25.42 | |
| prod | 24.76 | 25.51 | 25.36 | |
| Motifs-RFE | sum | 22.97 | 24.43 | 25.12 |
| cat | 21.37 | 23.16 | 24.10 | |
| prod | 21.40 | 23.23 | 24.12 | |
| predicate | VCTree | VCTree-RFE | predicate | VCTree | VCTree-RFE | predicate | VCTree | VCTree-RFE |
|---|---|---|---|---|---|---|---|---|
| over | 52.98 | 54.67 | in front of | 15.30 | 18.90 | beside | 25.19 | 31.45 |
| on | 14.54 | 17.34 | in | 5.11 | 6.40 | attached | 16.96 | 21.11 |
| hanging from | 15.57 | 15.61 | going down | 0.00 | 6.43 | walking on | 12.06 | 23.32 |
| running on | 6.35 | 17.42 | standing on | 41.49 | 42.56 | sitting on | 17.81 | 19.21 |
| flying over | 17.56 | 28.11 | wearing | 18.61 | 20.01 | holding | 30.99 | 31.56 |
| looking | 20.21 | 21.86 | eating | 0.00 | 6.21 | playing | 23.33 | 32.01 |
| driving | 0.00 | 2.85 | parked on | 38.27 | 42.17 | driving on | 39.80 | 50.13 |
| kicking | 22.11 | 23.65 | swinging | 18.29 | 21.03 | enclosing | 1.15 | 3.13 |
Tab. 4 R@100 comparison results of some predicate categories of VCTree-RFE and VCTree on SGGen
| predicate | VCTree | VCTree-RFE | predicate | VCTree | VCTree-RFE | predicate | VCTree | VCTree-RFE |
|---|---|---|---|---|---|---|---|---|
| over | 52.98 | 54.67 | in front of | 15.30 | 18.90 | beside | 25.19 | 31.45 |
| on | 14.54 | 17.34 | in | 5.11 | 6.40 | attached | 16.96 | 21.11 |
| hanging from | 15.57 | 15.61 | going down | 0.00 | 6.43 | walking on | 12.06 | 23.32 |
| running on | 6.35 | 17.42 | standing on | 41.49 | 42.56 | sitting on | 17.81 | 19.21 |
| flying over | 17.56 | 28.11 | wearing | 18.61 | 20.01 | holding | 30.99 | 31.56 |
| looking | 20.21 | 21.86 | eating | 0.00 | 6.21 | playing | 23.33 | 32.01 |
| driving | 0.00 | 2.85 | parked on | 38.27 | 42.17 | driving on | 39.80 | 50.13 |
| kicking | 22.11 | 23.65 | swinging | 18.29 | 21.03 | enclosing | 1.15 | 3.13 |
| 方法 | 浮点运算量/GFLOPs | 参数量/106 |
|---|---|---|
| VCTree[ | 29.078 | 120.898 |
| VCTree-RFE | 29.392 (↑1.1%) | 121.953 (↑0.9%) |
| Motifs[ | 29.162 | 125.268 |
| Motifs-RFE | 29.405 (↑0.8%) | 126.323 (↑0.8%) |
| IMP[ | 29.058 | 94.777 |
| IMP-RFE | 29.073 (↑0.1%) | 96.175 (↑1.5%) |
| GPSNet[ | 29.056 | 99.409 |
| GPSNet-RFE | 29.069 (↑0.1%) | 100.765 (↑1.4%) |
Tab. 5 Comparison of computational complexity and parameter size of different methods
| 方法 | 浮点运算量/GFLOPs | 参数量/106 |
|---|---|---|
| VCTree[ | 29.078 | 120.898 |
| VCTree-RFE | 29.392 (↑1.1%) | 121.953 (↑0.9%) |
| Motifs[ | 29.162 | 125.268 |
| Motifs-RFE | 29.405 (↑0.8%) | 126.323 (↑0.8%) |
| IMP[ | 29.058 | 94.777 |
| IMP-RFE | 29.073 (↑0.1%) | 96.175 (↑1.5%) |
| GPSNet[ | 29.056 | 99.409 |
| GPSNet-RFE | 29.069 (↑0.1%) | 100.765 (↑1.4%) |
| 信息 | 语义 | 位置 | 自适应 | R@20 | R@50 | R@100 | mR@20 | mR@50 | mR@100 |
|---|---|---|---|---|---|---|---|---|---|
| √ | √ | √ | √ | 25.96 | 26.70 | 26.80 | 11.37 | 11.54 | 11.58 |
| √ | √ | √ | 25.47 | 26.29 | 26.39 | 11.11 | 11.29 | 11.43 | |
| √ | √ | √ | 24.98 | 25.59 | 25.69 | 10.81 | 11.09 | 11.13 | |
| √ | √ | √ | 23.64 | 24.14 | 24.72 | 10.26 | 10.58 | 10.69 | |
| √ | √ | √ | 22.73 | 24.35 | 24.40 | 9.77 | 10.29 | 10.31 | |
| 21.59 | 23.32 | 24.01 | 9.56 | 10.09 | 10.28 |
Tab. 6 Results of ablation experiments on SGGen subtask
| 信息 | 语义 | 位置 | 自适应 | R@20 | R@50 | R@100 | mR@20 | mR@50 | mR@100 |
|---|---|---|---|---|---|---|---|---|---|
| √ | √ | √ | √ | 25.96 | 26.70 | 26.80 | 11.37 | 11.54 | 11.58 |
| √ | √ | √ | 25.47 | 26.29 | 26.39 | 11.11 | 11.29 | 11.43 | |
| √ | √ | √ | 24.98 | 25.59 | 25.69 | 10.81 | 11.09 | 11.13 | |
| √ | √ | √ | 23.64 | 24.14 | 24.72 | 10.26 | 10.58 | 10.69 | |
| √ | √ | √ | 22.73 | 24.35 | 24.40 | 9.77 | 10.29 | 10.31 | |
| 21.59 | 23.32 | 24.01 | 9.56 | 10.09 | 10.28 |

Fig. 7 Visualization of VCTree-RFE relation triplet

Fig. 8 Visual comparison between VCTree and VCTree-RFE methods on PSG dataset
| 1 | YANG J, ANG Y Z, GUO Z, et al. Panoptic scene graph generation[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13687. Cham: Springer, 2022: 178-196. |
| 2 | JOHNSON J, GUPTA A, LI F F. Image generation from scene graphs[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1219-1228. |
| 3 | SCHUSTER S, KRISHNA R, CHANG A, et al. Generating semantically precise scene graphs from textual descriptions for improved image retrieval[C]// Proceedings of the 4th Workshop on Vision and Language. Stroudsburg: ACL, 2015: 70-80. |
| 4 | KONER R, LI H, HILDEBRANDT M, et al. Graphhopper: multi-hop scene graph reasoning for visual question answering[C]// Proceedings of the 2021 International Semantic Web Conference, LNCS 12922. Cham: Springer, 2021: 111-127. |
| 5 | GAO L, WANG B, WANG W. Image captioning with scene-graph based semantic concepts[C]// Proceedings of the 10th International Conference on Machine Learning and Computing. New York: ACM, 2018: 225-229. |
| 6 | SHI J, ZHANG H, LI J. Explainable and explicit visual reasoning over scene graphs[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 8368-8376. |
| 7 | 张豪,张强,邵思羽,等. 深度学习在单图像三维模型重建的应用[J]. 计算机应用, 2020, 40(8): 2351-2357. |
| ZHANG H, ZHANG Q, SHAO S Y, et al. Application of deep learning to 3D model reconstruction of single image[J]. Journal of Computer Applications, 2020, 40(8): 2351-2357. | |
| 8 | TANG K, ZHANG H, WU B, et al. Learning to compose dynamic tree structures for visual contexts[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6612-6621. |
| 9 | JOHNSON J, KRISHNA R, STARK M, et al. Image retrieval using scene graphs[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3668-3678. |
| 10 | ZELLERS R, YATSKAR M, THOMSON S, et al. Neural Motifs: scene graph parsing with global context[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5831-5840. |
| 11 | SMAGULOVA K, JAMES A P. A survey on LSTM memristive neural network architectures and applications[J]. The European Physical Journal Special Topics, 2019, 228(10): 2313-2324. |
| 12 | XU D, ZHU Y, CHOY C B, et al. Scene graph generation by iterative message passing[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3097-3106. |
| 13 | LIN X, DING C, ZENG J, et al. GPS-Net: graph property sensing network for scene graph generation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3743-3752. |
| 14 | WOO S, KIM D, CHO D, et al. LinkNet: relational embedding for scene graph[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 558-568. |
| 15 | TANG K, NIU Y, HUANG J, et al. Unbiased scene graph generation from biased training[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3713-3122. |
| 16 | LI R, ZHANG S, WAN B, et al. Bipartite graph network with adaptive message passing for unbiased scene graph generation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11104-11114. |
| 17 | YU J, CHAI Y, WANG Y, et al. CogTree: cognition tree loss for unbiased scene graph generation[C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2021: 1274-1280. |
| 18 | GOEL A, FERNANDO B, KELLER F, et al. Not all relations are equal: mining informative labels for scene graph generation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15575-15585. |
| 19 | DONG X, GAN T, SONG X, et al. Stacked hybrid-attention and group collaborative learning for unbiased scene graph generation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19405-19414. |
| 20 | KUNDU S, AAKUR S N. IS-GGT: iterative scene graph generation with generative transformers[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 6292-6301. |
| 21 | WANG L, YUAN Z, CHEN B. Learning to generate an unbiased scene graph by using attribute-guided predicate features[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 2581-2589. |
| 22 | YOON K, KIM K, MOON J, et al. Unbiased heterogeneous scene graph generation with relation-aware message passing neural network[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 3285-3294. |
| 23 | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 213-229. |
| 24 | 冯兴杰,张天泽. 基于分组卷积进行特征融合的全景分割算法[J]. 计算机应用, 2021, 41(7): 2054-2061. |
| FENG X J, ZHANG T Z. Panoptic segmentation algorithm based on grouped convolution for feature fusion[J]. Journal of Computer Applications, 2021, 41(7): 2054-2061. | |
| 25 | ZHOU Z, SHI M, CAESAR H. HiLo: exploiting high low frequency relations for unbiased panoptic scene graph generation[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 21580-21591. |
| 26 | WANG J, WEN Z, LI X, et al. Pair then relation: pair-net for panoptic scene graph generation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 10452-10465. |
| 27 | XU J, CHEN J, YANAI K. Contextual associated triplet queries for panoptic scene graph generation[C]// Proceedings of the 5th ACM International Conference on Multimedia in Asia. New York: ACM, 2023: No.100. |
| 28 | ZHAO C, SHEN Y, CHEN Z, et al. TextPSG: panoptic scene graph generation from textual descriptions[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 2827-2838. |
| 29 | ZHOU Z, SHI M, CAESAR H, et al. VLPrompt: vision-language prompting for panoptic scene graph generation[EB/OL]. [2024-07-27].. |
| 30 | LI L, JI W, WU Y, et al. Panoptic scene graph generation with semantics-prototype learning[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 3145-3153. |
| 31 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 91-99. |
| 32 | KIRILLOV A, GIRSHICK R, HE K, et al. Panoptic feature pyramid networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6392-6401. |
| 33 | ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 12993-13000. |
| 34 | ZHENG Z, WANG P, REN D, et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics, 2022, 52(8): 8574-8586. |
| [1] | SHENG Hongbo WANG Xili. Local clustering based adaptive linear neighborhood propagation algorithm for image classification [J]. Journal of Computer Applications, 2014, 34(1): 255-259. |
| [2] | . Parallel OLAP query optimization method based on semantic decomposition [J]. Journal of Computer Applications, 2010, 30(07): 1956-1958. |
| [3] | . Information query based on semantic association in grid environment [J]. Journal of Computer Applications, 2009, 29(06): 1517-1526. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||