


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (3): 739-745.DOI: 10.11772/j.issn.1001-9081.2024050660
• Frontier research and typical applications of large models • Previous Articles Next Articles
Hao ZHOU1, Chao WANG1, Guoheng CUI1, Tingjin LUO2( )
)
Received:2024-05-22
Revised:2024-06-23
Accepted:2024-06-28
Online:2024-07-25
Published:2025-03-10
Contact:
Tingjin LUO
About author:ZHOU Hao, born in 1993, Ph. D., lecturer. His research interests include image understanding, scene graph generation, imbalance learning.Supported by:
周浩1, 王超1, 崔国恒1, 罗廷金2()
通讯作者:
罗廷金
作者简介:周浩(1993—),男,湖南长沙人,讲师,博士,CCF会员,主要研究方向:图像理解、场景图生成、不平衡学习基金资助:CLC Number:
Hao ZHOU, Chao WANG, Guoheng CUI, Tingjin LUO. Visual question answering model based on association and fusion of multiple semantic features[J]. Journal of Computer Applications, 2025, 45(3): 739-745.
周浩, 王超, 崔国恒, 罗廷金. 基于多语义关联与融合的视觉问答模型[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 739-745.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024050660
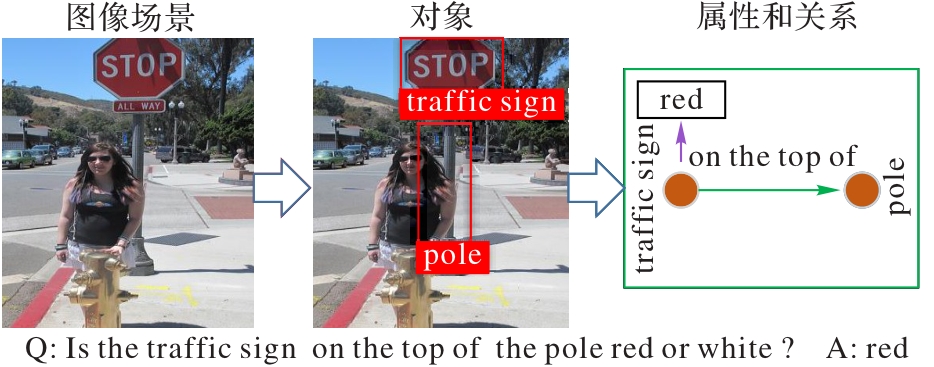
Fig. 1 Example of relationship- and attribute-related questions in VQA
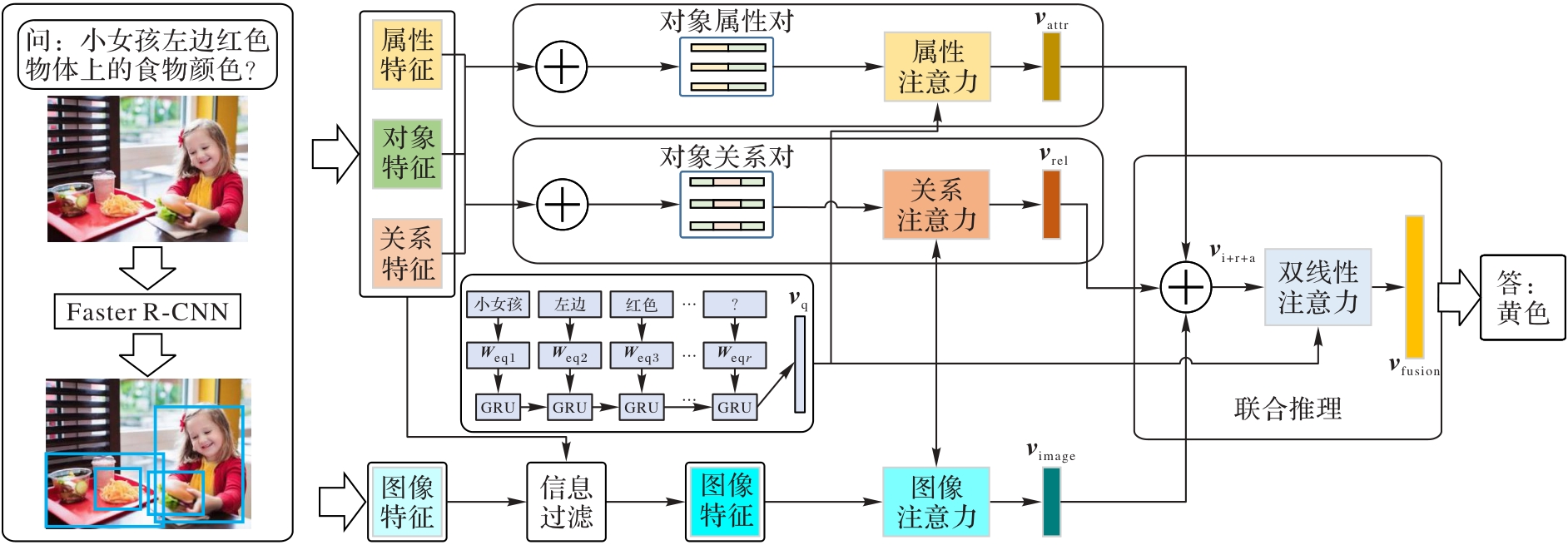
Fig. 2 Framework of visual question answering model based on multi-semantic association and fusion
| 模型 | 验证集 | 测试集 | 模型 | 验证集 | 测试集 |
|---|---|---|---|---|---|
| BAN | 66.0 | 70.0 | ViLT | — | 70.9 |
| DFAF | 66.2 | 70.2 | LXMERT | — | 72.4 |
| fPMC | 61.7 | 63.9 | CFR | 69.7 | 72.5 |
| CTI | 66.0 | 70.1 | 本文模型 | 70.6 | 72.9 |
| MCAN | 67.2 | 70.6 |
Tab. 1 Accuracies of different models on VQA2.0 validation and test sets
| 模型 | 验证集 | 测试集 | 模型 | 验证集 | 测试集 |
|---|---|---|---|---|---|
| BAN | 66.0 | 70.0 | ViLT | — | 70.9 |
| DFAF | 66.2 | 70.2 | LXMERT | — | 72.4 |
| fPMC | 61.7 | 63.9 | CFR | 69.7 | 72.5 |
| CTI | 66.0 | 70.1 | 本文模型 | 70.6 | 72.9 |
| MCAN | 67.2 | 70.6 |
| 模型 | 验证集 | 测试集 | 模型 | 验证集 | 测试集 |
|---|---|---|---|---|---|
| BAN | 61.5 | 55.2 | LXMERT | 59.8 | 60.0 |
| CTI | 61.7 | 54.9 | Oscar | — | 61.6 |
| MCAN | — | 57.4 | CFR | 73.6 | 72.1 |
| MMN | — | 60.4 | 本文模型 | 74.2 | 72.4 |
Tab. 2 Accuracies of different models on GQA validation and test sets
| 模型 | 验证集 | 测试集 | 模型 | 验证集 | 测试集 |
|---|---|---|---|---|---|
| BAN | 61.5 | 55.2 | LXMERT | 59.8 | 60.0 |
| CTI | 61.7 | 54.9 | Oscar | — | 61.6 |
| MCAN | — | 57.4 | CFR | 73.6 | 72.1 |
| MMN | — | 60.4 | 本文模型 | 74.2 | 72.4 |
| 特征嵌入模块 | 信息过滤模块 | 多注意力特征融合模块 | 准确率 |
|---|---|---|---|
| × | × | × | 59.2 |
| √ | × | × | 63.8 |
| √ | × | √ | 65.2 |
| √ | √ | × | 68.7 |
| √ | √ | √ | 69.9 |
Tab. 3 Accuracies of ablation experiments on VQA2.0 validation set
| 特征嵌入模块 | 信息过滤模块 | 多注意力特征融合模块 | 准确率 |
|---|---|---|---|
| × | × | × | 59.2 |
| √ | × | × | 63.8 |
| √ | × | √ | 65.2 |
| √ | √ | × | 68.7 |
| √ | √ | √ | 69.9 |
| 方法 | 验证集 | 测试集 |
|---|---|---|
| 引入空间特征 | 66.2 | 64.5 |
| 引入对象特征 | 71.4 | 68.9 |
| 引入对象和属性特征 | 72.9 | 70.8 |
| 引入对象和关系特征 | 73.4 | 71.6 |
| 引入多语义特征(本文模型) | 74.2 | 72.4 |
| 真实标记的对象和属性 | 87.0 | — |
Tab. 4 Influence of different input features on visual question answering model accuracy
| 方法 | 验证集 | 测试集 |
|---|---|---|
| 引入空间特征 | 66.2 | 64.5 |
| 引入对象特征 | 71.4 | 68.9 |
| 引入对象和属性特征 | 72.9 | 70.8 |
| 引入对象和关系特征 | 73.4 | 71.6 |
| 引入多语义特征(本文模型) | 74.2 | 72.4 |
| 真实标记的对象和属性 | 87.0 | — |

Fig. 3 Visualization results of attribute-related questions

Fig. 4 Visualization results with relationship-related questions
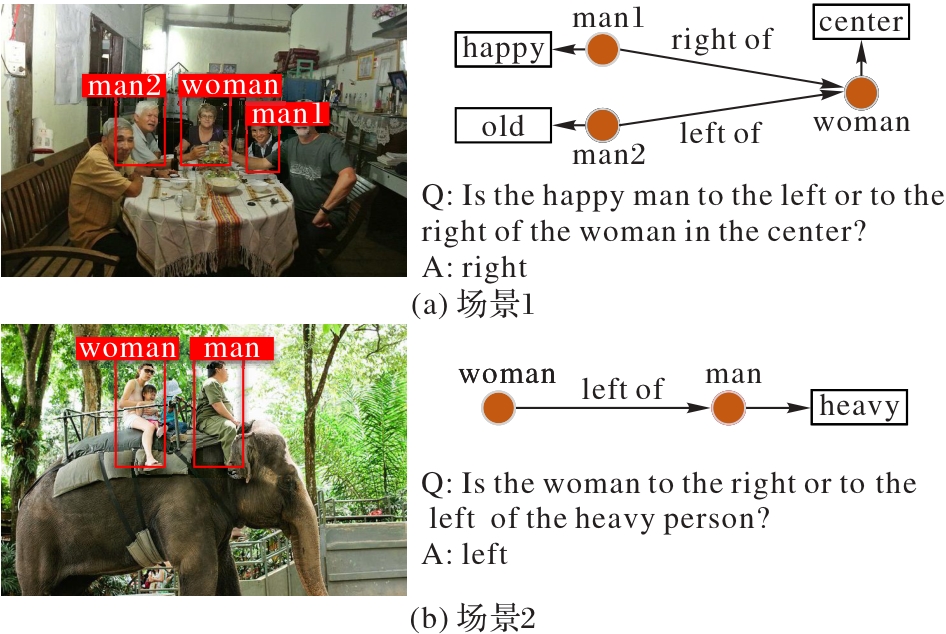
Fig. 5 Visualization results of compositional questions
| 1 | ANTOL S, AGRAWAL A, LU J, et al. VQA: visual question answering [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2425-2433. |
| 2 | YU J, ZHANG W, LU Y, et al. Reasoning on the relation: enhancing visual representation for visual question answering and cross-modal retrieval [J]. IEEE Transactions on Multimedia, 2020, 22(12): 3196-3209. |
| 3 | LU S, LIU M, YIN L, et al. The multi-modal fusion in visual question answering: a review of attention mechanisms [J]. PeerJ Computer Science, 2023, 9: No.e1400. |
| 4 | 李祥,范志广,李学相,等. 基于深度学习的视觉问答研究综述[J]. 计算机科学, 2023, 50(5):177-188. |
| LI X, FAN Z G, LI X X, et al. Survey of visual question answering based on deep learning[J]. Computer Science, 2023, 50(5):177-188. | |
| 5 | MALINOWSKI M, ROHRBACH M, FRITZ M. Ask your neurons: a neural-based approach to answering questions about images [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1-9. |
| 6 | KIM J H, LEE S W, KWAK D, et al. Multimodal residual learning for visual QA [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 361-369. |
| 7 | KIM J H, JUN J, ZHANG B T. Bilinear attention networks [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 1571-1581. |
| 8 | TENEY D, LIU L, VAN DEN HENGEL A. Graph-structured representations for visual question answering [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3233-3241. |
| 9 | YANG Z, HE X, GAO J, et al. Stacked attention networks for image question answering [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 21-29. |
| 10 | RAHMAN T, CHOU S H, SIGAL L, et al. An improved attention for visual question answering [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 1653-1662. |
| 11 | ZENG Y, ZHANG X, LI H. Multi-grained vision language pre-training: aligning texts with visual concepts [C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 25994-26009. |
| 12 | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. |
| 13 | JIANG H, MISRA I, ROHRBACH M, et al. In defense of grid features for visual question answering [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10264-10273. |
| 14 | NGUYEN B X, DO T, TRAN H, et al. Coarse-to-fine reasoning for visual question answering [C]// Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2022: 4558-4566. |
| 15 | ZHOU H, ZHANG J, LUO T, et al. Debiased scene graph generation for dual imbalance learning [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(4): 4274-4288. |
| 16 | ZHOU H, YANG Y, LUO T, et al. A unified deep sparse graph attention network for scene graph generation [J]. Pattern Recognition, 2022, 123: No.108367. |
| 17 | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1532-1543. |
| 18 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 19 | CHEN Y C, LI L, YU L, et al. Uniter: universal image-text representation learning [C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 104-120. |
| 20 | YANG Z, QIN Z, YU J, et al. Scene graph reasoning with prior visual relationship for visual question answering [C]// Proceedings of the 2020 IEEE International Conference on Image Processing. Piscataway: IEEE, 2020: 1411-1415. |
| 21 | YU Z, YU J, CUI Y, et al. Deep modular co-attention networks for visual question answering [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6274-6283. |
| 22 | XIONG P, SHEN Y, JIN H. MGA-VQA: multi-granularity alignment for visual question answering [EB/OL]. [2024-02-12].. |
| 23 | JING C, JIA Y, WU Y, et al. Maintaining reasoning consistency in compositional visual question answering [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5089-5098. |
| 24 | ANDREAS J, ROHRBACH M, DARRELL T, et al. Neural module networks [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 39-48. |
| 25 | CHEN W, GAN Z, LI L, et al. Meta module network for compositional visual reasoning [C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 655-664. |
| 26 | HU R, ROHRBACH A, DARRELL T, et al. Language-conditioned graph networks for relational reasoning [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 10293-10302. |
| 27 | JING C, JIA Y, WU Y, et al. Learning the dynamics of visual relational reasoning via reinforced path routing [C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 1122-1130. |
| 28 | 周浩. 图像语义场景图生成方法研究[D]. 长沙:国防科技大学, 2021: 133-136. |
| ZHOU H. Scene graph generation for image semantic understanding and representation [D]. Changsha: National University of Defense Technology, 2021: 133-136. | |
| 29 | TANG K, ZHANG H, WU B, et al. Learning to compose dynamic tree structures for visual contexts [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6612-6621. |
| 30 | HUDSON D A, MANNING C D. GQA: a new dataset for real-world visual reasoning and compositional question answering [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6693-6702. |
| 31 | GAO P, JIANG Z, YOU H, et al. Dynamic fusion with intra-and inter-modality attention flow for visual question answering [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6632-6641. |
| 32 | SHA F, CHAO W L, HU H. Learning answer embeddings for visual question answering [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5428-5436. |
| 33 | DO T, TRAN H, DO T T, et al. Compact trilinear interaction for visual question answering [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 392-401. |
| 34 | TAN H, BANSAL M. LXMERT: learning cross-modality encoder representations from Transformers [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 5100-5111. |
| 35 | KIM W, SON B, KIM I. ViLT: vision-and-language Transformer without convolution or region supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 5583-5594. |
| 36 | LI X, YIN X, LI C, et al. OSCAR: object-semantics aligned pre-training for vision-language tasks [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12375. Cham: Springer, 2020: 121-137. |
| [1] | Linhao LI, Yize WANG, Yingshuang LI, Yongfeng DONG, Zhen WANG. Panoptic scene graph generation method based on relation feature enhancement [J]. Journal of Computer Applications, 2025, 45(2): 584-593. |
| [2] | Meiyu CAI, Runzhe ZHU, Fei WU, Kaiyu ZHANG, Jiale LI. Cross-view matching model based on attention mechanism and multi-granularity feature fusion [J]. Journal of Computer Applications, 2024, 44(3): 901-908. |
| [3] | Jia WANG-ZHU, Zhou YU, Jun YU, Jianping FAN. Video dynamic scene graph generation model based on multi-scale spatial-temporal Transformer [J]. Journal of Computer Applications, 2024, 44(1): 47-57. |
| [4] | Zhiping ZHU, Yan YANG, Jie WANG. Scene graph-aware cross-modal image captioning model [J]. Journal of Computer Applications, 2024, 44(1): 58-64. |
| [5] | ZHANG Chi, LI Zhuhong, LIU Zhou, SHEN Weiming. Unmanned aerial vehicle image positioning algorithm based on scene graph division [J]. Journal of Computer Applications, 2021, 41(10): 3004-3009. |
| [6] | ZHANG Wenying, HE Kunjin, ZHANG Rongli, LIU Yuxing. 3-D visualization and information management system design based on open scene graph [J]. Journal of Computer Applications, 2016, 36(7): 2056-2060. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||