


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (1): 58-64.DOI: 10.11772/j.issn.1001-9081.2022071109
• Cross-media representation learning and cognitive reasoning • Previous Articles Next Articles
Zhiping ZHU, Yan YANG( ), Jie WANG
), Jie WANG
Received:2022-07-29
Revised:2022-11-20
Accepted:2022-11-30
Online:2023-01-15
Published:2024-01-10
Contact:
Yan YANG
About author:ZHU Zhiping, born in 1998, M. S. candidate. His research interests include natural language processing, computer vision.Supported by:
朱志平, 杨燕(), 王杰
通讯作者:
杨燕
作者简介:朱志平(1998—),男,四川南充人,硕士研究生,主要研究方向:自然语言处理、计算机视觉;基金资助:CLC Number:
Zhiping ZHU, Yan YANG, Jie WANG. Scene graph-aware cross-modal image captioning model[J]. Journal of Computer Applications, 2024, 44(1): 58-64.
朱志平, 杨燕, 王杰. 基于场景图感知的跨模态图像描述模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 58-64.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022071109
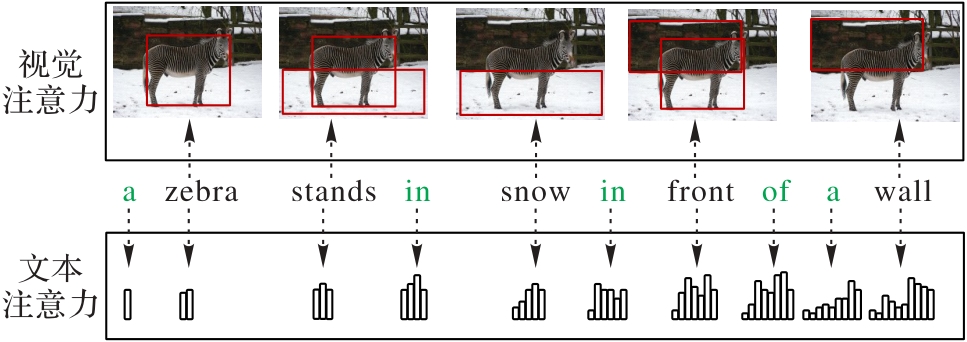
Fig. 1 Visual and textual attention used in description generation
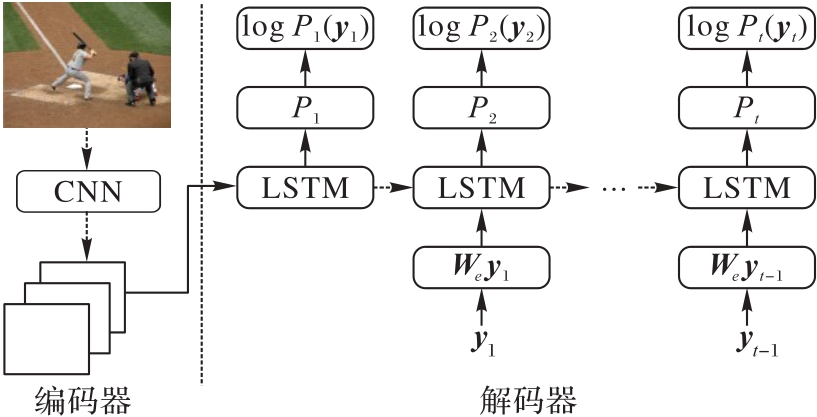
Fig. 2 Traditional encoder-decoder structure

Fig. 3 Structure of scene graph-aware cross-modal
| 模型 | BLEU1 | BLEU4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| GVD[ | 69.2 | 26.9 | 22.1 | — | 60.1 | 16.1 |
| Up-Down[ | 69.4 | 27.3 | 21.7 | — | 56.6 | 16.0 |
| Sub-GC[ | 69.1 | 28.2 | 22.3 | 49.0 | 60.3 | 16.7 |
| SGC-Net | 70.2 | 29.1 | 22.6 | 49.7 | 61.7 | 17.1 |
Tab. 1 Comparison of experimental results on Flickr30K dataset
| 模型 | BLEU1 | BLEU4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| GVD[ | 69.2 | 26.9 | 22.1 | — | 60.1 | 16.1 |
| Up-Down[ | 69.4 | 27.3 | 21.7 | — | 56.6 | 16.0 |
| Sub-GC[ | 69.1 | 28.2 | 22.3 | 49.0 | 60.3 | 16.7 |
| SGC-Net | 70.2 | 29.1 | 22.6 | 49.7 | 61.7 | 17.1 |
| 模型 | BLEU1 | BLEU4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| Up-Down[ | 77.2 | 36.2 | 27.0 | 56.4 | 113.5 | 20.3 |
| Sub-GC[ | 76.8 | 36.2 | 27.7 | 56.6 | 115.3 | 20.7 |
| SGC-Net | 77.1 | 36.3 | 28.0 | 57.1 | 114.8 | 21.3 |
Tab. 2 Comparison of experimental results on MS-COCO dataset
| 模型 | BLEU1 | BLEU4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| Up-Down[ | 77.2 | 36.2 | 27.0 | 56.4 | 113.5 | 20.3 |
| Sub-GC[ | 76.8 | 36.2 | 27.7 | 56.6 | 115.3 | 20.7 |
| SGC-Net | 77.1 | 36.3 | 28.0 | 57.1 | 114.8 | 21.3 |
| L | BLEU1 | BLEU4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| 1 | 76.4 | 36.0 | 27.7 | 56.5 | 113.7 | 20.9 |
| 2 | 76.6 | 36.0 | 27.8 | 56.6 | 113.6 | 21.0 |
| 3 | 76.8 | 36.2 | 27.8 | 56.8 | 114.2 | 21.2 |
| 4 | 76.9 | 36.3 | 27.9 | 56.9 | 114.5 | 21.1 |
| 5 | 77.1 | 36.3 | 28.0 | 57.1 | 114.8 | 21.3 |
| 6 | 76.8 | 35.9 | 27.8 | 56.7 | 114.5 | 21.0 |
| 7 | 76.7 | 35.8 | 27.8 | 56.6 | 114.5 | 20.9 |
| 8 | 76.5 | 35.7 | 27.7 | 56.6 | 114.2 | 21.0 |
| 9 | 76.5 | 35.7 | 27.7 | 56.4 | 114.2 | 20.9 |
| 10 | 76.4 | 35.8 | 27.7 | 56.7 | 113.9 | 20.8 |
| 11 | 76.3 | 35.7 | 27.7 | 56.4 | 113.8 | 20.8 |
Tab. 3 Influence of text length on experimental results
| L | BLEU1 | BLEU4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| 1 | 76.4 | 36.0 | 27.7 | 56.5 | 113.7 | 20.9 |
| 2 | 76.6 | 36.0 | 27.8 | 56.6 | 113.6 | 21.0 |
| 3 | 76.8 | 36.2 | 27.8 | 56.8 | 114.2 | 21.2 |
| 4 | 76.9 | 36.3 | 27.9 | 56.9 | 114.5 | 21.1 |
| 5 | 77.1 | 36.3 | 28.0 | 57.1 | 114.8 | 21.3 |
| 6 | 76.8 | 35.9 | 27.8 | 56.7 | 114.5 | 21.0 |
| 7 | 76.7 | 35.8 | 27.8 | 56.6 | 114.5 | 20.9 |
| 8 | 76.5 | 35.7 | 27.7 | 56.6 | 114.2 | 21.0 |
| 9 | 76.5 | 35.7 | 27.7 | 56.4 | 114.2 | 20.9 |
| 10 | 76.4 | 35.8 | 27.7 | 56.7 | 113.9 | 20.8 |
| 11 | 76.3 | 35.7 | 27.7 | 56.4 | 113.8 | 20.8 |

Fig. 4 Comparison of generated description
| 1 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735 |
| 2 | CHEN L, ZHANG H W, XIAO J, et al. SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6298-6306. 10.1109/cvpr.2017.667 |
| 3 | PEDERSOLI M, LUCAS T, SCHMID C, et al. Areas of attention for image captioning [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1251-1259. 10.1109/iccv.2017.140 |
| 4 | 刘茂福,施琦,聂礼强.基于视觉关联与上下文双注意力的图像描述生成方法[J].软件学报, 2022, 33(9): 3210-3222. |
| LIU M F, SHI Q, NIE L Q. Image captioning based on visual relevance and context dual attention [J]. Journal of Software, 2022, 33(9): 3210-3222. | |
| 5 | 陈悦,郭宇,谢圆琰,等.基于图像描述算法的离线盲人视觉辅助系统[J].电信科学, 2022, 38(1): 61-72. 10.11959/j.issn.1000-0801.2022014 |
| CHEN Y, GUO Y, XIE Y Y, et al. Offline visual aid system for the blind based on image captioning [J]. Telecommunications Science, 2022, 38(1): 61-72. 10.11959/j.issn.1000-0801.2022014 | |
| 6 | 谢州益,冯亚枝,胡彦蓉,等.基于ResNet18特征编码器的水稻病虫害图像描述生成[J].农业工程学报, 2022, 38(12): 197-206. 10.11975/j.issn.1002-6819.2022.12.023 |
| XIE Z Y, FENG Y Z, HU Y R, et al. Generating image description of rice pests and diseases using a ResNet18 feature encoder [J]. Transactions of the Chinese Society of Agricultural Engineering, 2022, 38(12): 197-206. 10.11975/j.issn.1002-6819.2022.12.023 | |
| 7 | FARHADI A, HEJRATI M, SADEGHI M A, et al. Every picture tells a story: generating sentences from images [C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6314. Berlin: Springer, 2010: 15-29. |
| 8 | LI S M, KULKARNI G, BERG T L, et al. Composing simple image descriptions using web-scale n-grams [C]// Proceedings of the 15th Conference on Computational Natural Language Learning. Stroudsburg, PA: ACL, 2011: 220-228. |
| 9 | ORDONEZ V, KULKARNI G, BERG T L. Im2Text: describing images using 1 million captioned photographs [C]// Proceedings of the 24th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2011: 1143-1151. |
| 10 | HODOSH M, YOUNG P, HOCKENMAIER J. Framing image description as a ranking task: data, models and evaluation metrics [J]. Journal of Artificial Intelligence Research, 2013, 47: 853-899. 10.1613/jair.3994 |
| 11 | GONG Y C, WANG L W, HODOSH M, et al. Improving image-sentence embeddings using large weakly annotated photo collections [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8692. Cham: Springer, 2014: 529-545. |
| 12 | ANDERSON P, HE X D, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. 10.1109/cvpr.2018.00636 |
| 13 | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. 10.1109/tpami.2016.2577031 |
| 14 | YAO T, PAN Y W, LI Y H, et al. Exploring visual relationship for image captioning [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 711-727. |
| 15 | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [EB/OL]. (2017-02-22) [2022-05-17]. . 10.48550/arXiv.1609.02907 |
| 16 | RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1179-1195. 10.1109/cvpr.2017.131 |
| 17 | LIU W, CHEN S H, GUO L T, et al. CPTR: full Transformer network for image captioning [EB/OL]. (2021-01-28) [2022-05-17]. . |
| 18 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03) [2022-05-17]. . |
| 19 | BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. (2016-05-19) [2022-05-17]. . 10.1017/9781108608480.003 |
| 20 | XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 2048-2057. 10.1109/cvpr.2015.7298935 |
| 21 | HUANG L, WANG W M, CHEN J, et al. Attention on attention for image captioning [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 4633-4642. 10.1109/iccv.2019.00473 |
| 22 | LU J S, XIONG C M, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3242-3250. 10.1109/cvpr.2017.345 |
| 23 | PAN Y W, YAO T, LI Y H, et al. X-Linear attention networks for image captioning [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10968-10977. 10.1109/cvpr42600.2020.01098 |
| 24 | LUO Y P, JI J Y, SUN X S, et al. Dual-level collaborative transformer for image captioning [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 2286-2293. 10.1609/aaai.v35i3.16328 |
| 25 | ZELLERS R, YATSKAR M, THOMSON S, et al. Neural motifs: scene graph parsing with global context [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5831-5840. 10.1109/cvpr.2018.00611 |
| 26 | YOUNG P, LAI A, HODOSH M, et al. From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions [J]. Transactions of the Association for Computational Linguistics, 2014, 2: 67-78. 10.1162/tacl_a_00166 |
| 27 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755. |
| 28 | KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3128-3137. 10.1109/cvpr.2015.7298932 |
| 29 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2002: 311-318. 10.3115/1073083.1073135 |
| 30 | BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments [C]// Proceedings of the ACL-05 Workshop: Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Stroudsburg, PA: ACL, 2005: 65-72. |
| 31 | LIN C Y. ROUGE: a package for automatic evaluation of summaries [C]// Proceedings of the ACL-04 Workshop: Text Summarization Branches Out. Stroudsburg, PA: ACL, 2004: 74-81. 10.3115/1218955.1219032 |
| 32 | VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4566-4575. 10.1109/cvpr.2015.7299087 |
| 33 | ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: semantic propositional image caption evaluation [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9909. Cham: Springer, 2016: 382-398. |
| 34 | ZHONG Y W, WANG L W, CHEN J S, et al. Comprehensive image captioning via scene graph decomposition [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12359. Cham: Springer, 2020: 211-229. |
| 35 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 36 | KRISHNA R, ZHU Y K, GROTH O, et al. Visual genome: connecting language and vision using crowdsourced dense image annotations [J]. International Journal of Computer Vision, 2017, 123(1): 32-73. 10.1007/s11263-016-0981-7 |
| 37 | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. PA: ACL, 2014: 1532-1543. 10.3115/v1/d14-1162 |
| 38 | KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. (2017-01-30) [2022-02-19]. . |
| 39 | ZHOU L W, KALANTIDIS Y, CHEN X L, et al. Grounded video description [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6571-6580. 10.1109/cvpr.2019.00674 |
| [1] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [2] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [3] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [4] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [5] | Kaipeng XUE, Tao XU, Chunjie LIAO. Multimodal sentiment analysis network with self-supervision and multi-layer cross attention [J]. Journal of Computer Applications, 2024, 44(8): 2387-2392. |
| [6] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [7] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [8] | Shangbin MO, Wenjun WANG, Ling DONG, Shengxiang GAO, Zhengtao YU. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding [J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. |
| [9] | Wu XIONG, Congjun CAO, Xuefang SONG, Yunlong SHAO, Xusheng WANG. Handwriting identification method based on multi-scale mixed domain attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2225-2232. |
| [10] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [11] | Dianhui MAO, Xuebo LI, Junling LIU, Denghui ZHANG, Wenjing YAN. Chinese entity and relation extraction model based on parallel heterogeneous graph and sequential attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2018-2025. |
| [12] | Li LIU, Haijin HOU, Anhong WANG, Tao ZHANG. Generative data hiding algorithm based on multi-scale attention [J]. Journal of Computer Applications, 2024, 44(7): 2102-2109. |
| [13] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [14] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| [15] | Wenliang WEI, Yangping WANG, Biao YUE, Anzheng WANG, Zhe ZHANG. Deep learning model for infrared and visible image fusion based on illumination weight allocation and attention [J]. Journal of Computer Applications, 2024, 44(7): 2183-2191. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||