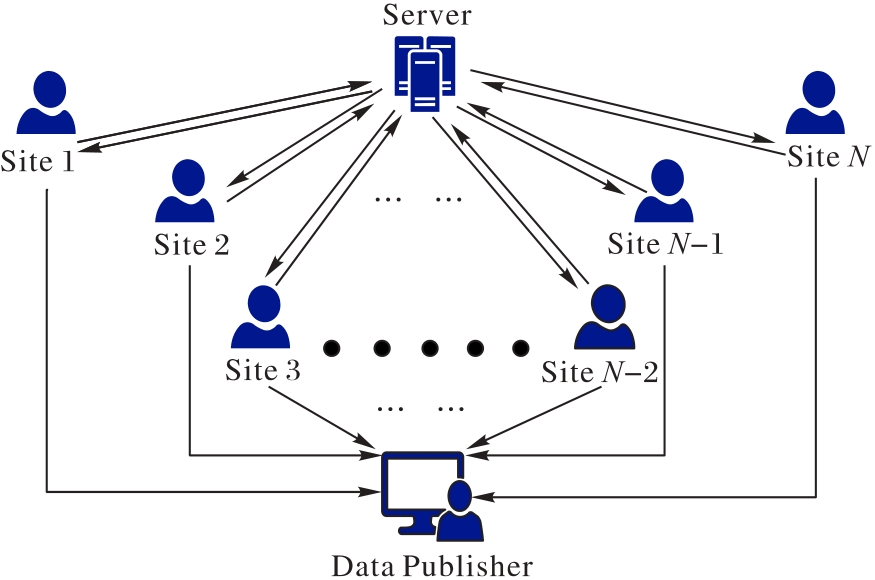
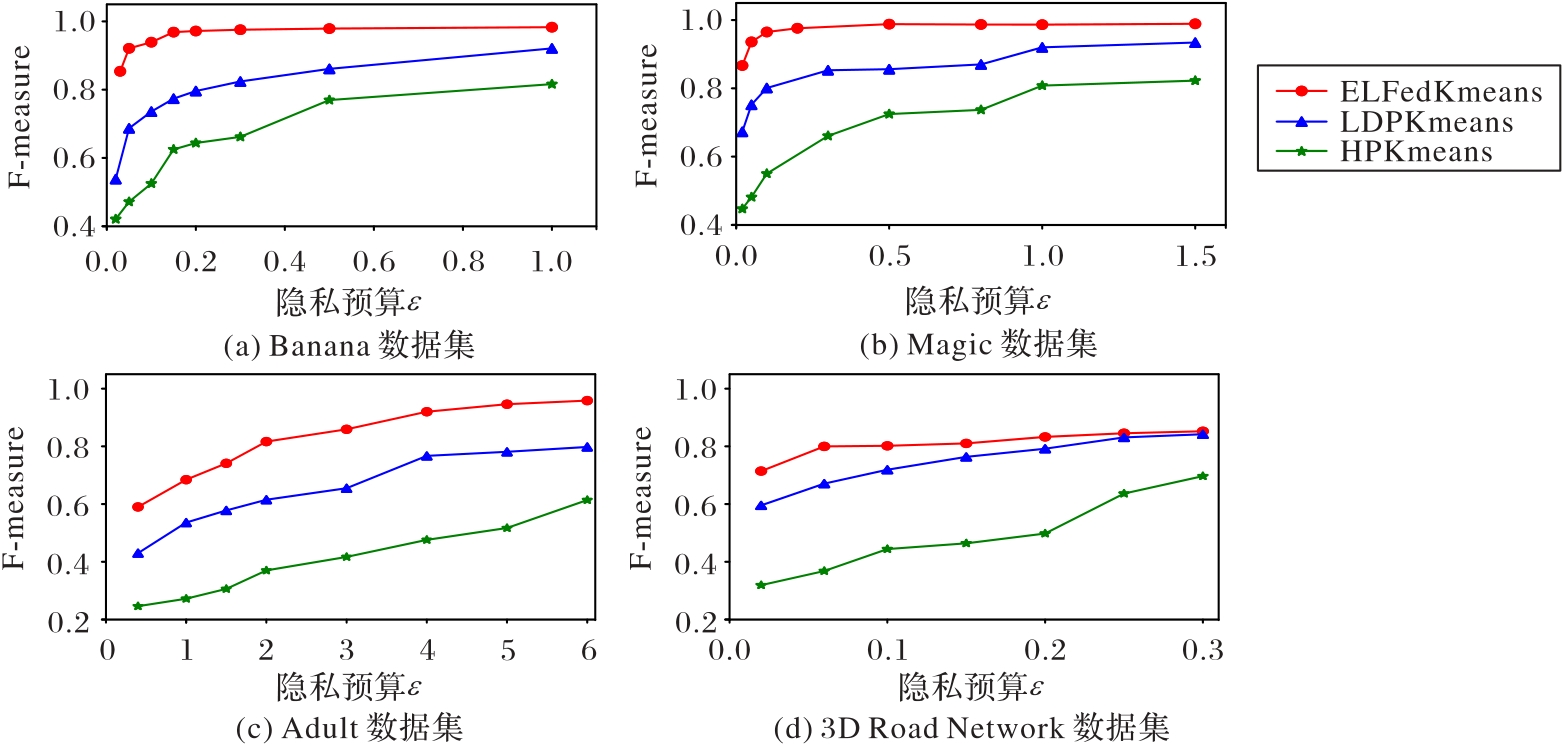
| 1 |
杨强. AI与数据隐私保护: “联邦学习”的破解之道[J].信息安全研究, 2019, 5(11): 961-965.
|
|
YANG Q. AI and data privacy protection: The way to federated learning [J]. Journal of Information Security Research, 2019, 5(11): 961-965.
|
| 2 |
LI T, SAHU A K, TALWALKAR A, et al. Federated learning: Challenges, methods, and future directions [J]. IEEE Signal Processing Magazine, 2020, 37(3): 50-60. 10.1109/msp.2020.2975749
|
| 3 |
DUCHI J C, JORDAN M I, WAINWRIGHT M J. Local privacy and statistical minimax rates [C]// Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science. Piscataway IEEE, 2013: 429-438. 10.1109/allerton.2013.6736718
|
| 4 |
XU R, WUNSCH D. Survey of clustering algorithms [J]. IEEE Transactions on Neural Networks, 2005, 16(3): 645-678. 10.1109/tnn.2005.845141
|
| 5 |
XU D, TIAN Y. A comprehensive survey of clustering algorithms [J]. Annals of Data Science, 2015, 2: 165-193. 10.1007/s40745-015-0040-1
|
| 6 |
DWORK C. Differential privacy: A survey of results [C]// Proceedings of the 5th International Conference on Theory and Applications of Models of Computation. Cham: Springer, 2008: 1-19. 10.1007/978-3-540-79228-4
|
| 7 |
BLUM A, DWORK C, McSHERRY F, et al. Practical privacy: the SuLQ framework [C]// Proceedings of the Twenty-Fourth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems. New York: ACM, 2005: 128-138. 10.1145/1065167.1065184
|
| 8 |
AAMER Y, BENKAOUZ Y, OUZZIF M, et al. Initial centroid selection method for an enhanced k-means clustering algorithm [C]// Proceedings of the 5th International Symposium on Ubiquitous Networking. Cham: Springer, 2020: 182-190. 10.1007/978-3-030-58008-7_15
|
| 9 |
RAHMAN Z, HOSSAIN M S, HASAN M, et al. An enhanced method of initial cluster center selection for K-means algorithm [C]// Proceedings of the 2021 Innovations in Intelligent Systems and Applications Conference. Piscataway: IEEE, 2021: 1-6. 10.1109/asyu52992.2021.9599017
|
| 10 |
WAN Y, XIONG Q, QIU Z, et al. K-means clustering algorithm based on memristive chaotic system and sparrow search algorithm [J]. Symmetry, 2022, 14(10): 2029. 10.3390/sym14102029
|
| 11 |
HAN L, XIE Y, FAN D, et al. Improved differential privacy K-means clustering algorithm for privacy budget allocation [C]// Proceedings of the 2022 International Conference on Computer Engineering and Artificial Intelligence. Piscataway: IEEE, 2022: 221-225. 10.1109/icceai55464.2022.00054
|
| 12 |
SU D, CAO J, LI N, et al. Differentially private k-means clustering [C]// Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy. New York: ACM, 2016: 26-37. 10.1145/2857705.2857708
|
| 13 |
FAN Z, XU X. APDPk-means: A new differential privacy clustering algorithm based on arithmetic progression privacy budget allocation [C]// HPCC/SmartCity/DSS: Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems. Piscataway: IEEE, 2019: 1737-1742. 10.1109/hpcc/smartcity/dss.2019.00238
|
| 14 |
JIANG Z L, GUO N, JIN Y, et al. Efficient two-party privacy-preserving collaborative k-means clustering protocol supporting both storage and computation outsourcing [J]. Information Sciences, 2020, 518: 168-180. 10.1016/j.ins.2019.12.051
|
| 15 |
XIA C, HUA J, TONG W, et al. Distributed K-Means clustering guaranteeing local differential privacy [J]. Computers & Security, 2020, 90: 101699. 10.1016/j.cose.2019.101699
|
| 16 |
ZHANG E, LI H, HUANG Y, et al. Practical multi-party private collaborative k-means clustering [J]. Neurocomputing, 2022, 467: 256-265. 10.1016/j.neucom.2021.09.050
|
| 17 |
DWORK C, ROTH A. The algorithmic foundations of differential privacy [J]. Foundations and Trends in Theoretical Computer Science, 2014, 9(3/4): 211-407. 10.1561/0400000042
|
| 18 |
WANG H, XU Z, XIONG L, et al. Conducting correlated Laplace mechanism for differential privacy [C]// Proceedings of the 2017 International Conference on Cloud Computing and Security. Cham: Springer, 2017: 72-85. 10.1007/978-3-319-68542-7_7
|
| 19 |
DWORK C, McSHERRY F, NISSIM K, et al. Calibrating noise to sensitivity in private data analysis [C]// Proceedings of the 2006 Theory of Cryptography Conference. Cham: Springer, 2006: 265-284. 10.1007/11681878_14
|
| 20 |
陈晓光.基于网格的密度峰值聚类算法研究及其应用[D].大连:大连理工大学, 2017: 19.
|
|
CHEN X G. Study on density peaks clustering algorithm based on grid and its application [D]. Dalian: Dalian University of Technology, 2017: 19.
|
| 21 |
DUA D, GRAFF C. UCI Machine learning repository [DB/OL]. [2022-09-20]. .
|


 ), Geng YANG1,2, Yuxian HUANG1
), Geng YANG1,2, Yuxian HUANG1