


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (2): 556-562.DOI: 10.11772/j.issn.1001-9081.2023020157
Special Issue: 多媒体计算与计算机仿真
• Multimedia computing and computer simulation • Previous Articles Next Articles
Weipeng JING, Qingxin XIAO, Hui LUO( )
)
Received:2023-02-21
Revised:2023-04-18
Accepted:2023-04-21
Online:2023-08-14
Published:2024-02-10
Contact:
Hui LUO
About author:JING Weipeng, born in 1979, Ph. D., professor. His research interests include artificial intelligence.Supported by:
景维鹏, 肖庆欣, 罗辉()
通讯作者:
罗辉
作者简介:景维鹏(1979—),男,黑龙江鹤岗人,教授,博士,CCF高级会员,主要研究方向:人工智能基金资助:CLC Number:
Weipeng JING, Qingxin XIAO, Hui LUO. Channel compensation algorithm for speaker recognition based on probabilistic spherical discriminant analysis[J]. Journal of Computer Applications, 2024, 44(2): 556-562.
景维鹏, 肖庆欣, 罗辉. 基于概率球面判别分析的说话人识别信道补偿算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 556-562.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023020157

Fig. 1 Flowchart of speaker recognition
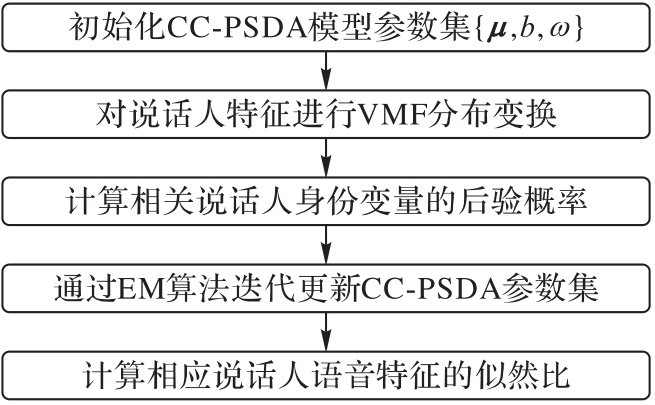
Fig. 2 Flowchart of CC-PSDA
| 模型 | 100维i-vector | 200维i-vector | 400维i-vector | |||
|---|---|---|---|---|---|---|
| EER | MinDCF | EER | MinDCF | EER | MinDCF | |
| cos | 4.87 | 0.352 | 4.28 | 0.324 | 4.15 | 0.321 |
| PLDA | 4.85 | 0.355 | 4.27 | 0.332 | 4.10 | 0.347 |
| HT-PLDA | 4.68 | 0.339 | 4.19 | 0.355 | 4.11 | 0.343 |
| PSDA | 4.62 | 0.336 | 4.17 | 0.346 | 4.09 | 0.352 |
| CC-PSDA | 4.23 | 0.314 | 3.88 | 0.286 | 3.63 | 0.249 |
Tab. 1 Comparison of recognition performance among various models on VoxCeleb1-O test set
| 模型 | 100维i-vector | 200维i-vector | 400维i-vector | |||
|---|---|---|---|---|---|---|
| EER | MinDCF | EER | MinDCF | EER | MinDCF | |
| cos | 4.87 | 0.352 | 4.28 | 0.324 | 4.15 | 0.321 |
| PLDA | 4.85 | 0.355 | 4.27 | 0.332 | 4.10 | 0.347 |
| HT-PLDA | 4.68 | 0.339 | 4.19 | 0.355 | 4.11 | 0.343 |
| PSDA | 4.62 | 0.336 | 4.17 | 0.346 | 4.09 | 0.352 |
| CC-PSDA | 4.23 | 0.314 | 3.88 | 0.286 | 3.63 | 0.249 |
| 模型 | 100维i-vector | 200维i-vector | 400维i-vector | |||
|---|---|---|---|---|---|---|
| EER | MinDCF | EER | MinDCF | EER | MinDCF | |
| cos | 6.90 | 0.468 | 6.74 | 0.455 | 5.96 | 0.470 |
| PLDA | 6.86 | 0.472 | 6.71 | 0.551 | 5.95 | 0.488 |
| HT-PLDA | 6.51 | 0.464 | 6.44 | 0.452 | 5.93 | 0.468 |
| PSDA | 6.40 | 0.466 | 6.35 | 0.443 | 5.84 | 0.429 |
| CC-PSDA | 5.84 | 0.420 | 5.67 | 0.411 | 5.41 | 0.397 |
Tab. 2 Comparison of recognition performance among various models on VoxCeleb1-E test set
| 模型 | 100维i-vector | 200维i-vector | 400维i-vector | |||
|---|---|---|---|---|---|---|
| EER | MinDCF | EER | MinDCF | EER | MinDCF | |
| cos | 6.90 | 0.468 | 6.74 | 0.455 | 5.96 | 0.470 |
| PLDA | 6.86 | 0.472 | 6.71 | 0.551 | 5.95 | 0.488 |
| HT-PLDA | 6.51 | 0.464 | 6.44 | 0.452 | 5.93 | 0.468 |
| PSDA | 6.40 | 0.466 | 6.35 | 0.443 | 5.84 | 0.429 |
| CC-PSDA | 5.84 | 0.420 | 5.67 | 0.411 | 5.41 | 0.397 |
| 模型 | 100维i-vector | 200维i-vector | 400维i-vector | |||
|---|---|---|---|---|---|---|
| EER | MinDCF | EER | MinDCF | EER | MinDCF | |
| cos | 11.24 | 0.625 | 10.43 | 0.615 | 9.86 | 0.536 |
| PLDA | 10.98 | 0.611 | 10.21 | 0.623 | 9.79 | 0.535 |
| HT-PLDA | 9.96 | 0.573 | 9.62 | 0.633 | 8.47 | 0.520 |
| PSDA | 9.87 | 0.598 | 9.40 | 0.572 | 8.23 | 0.493 |
| CC-PSDA | 8.65 | 0.511 | 7.69 | 0.506 | 7.14 | 0.447 |
Tab. 3 Comparison of recognition performance among various models on VoxCeleb1-H test set
| 模型 | 100维i-vector | 200维i-vector | 400维i-vector | |||
|---|---|---|---|---|---|---|
| EER | MinDCF | EER | MinDCF | EER | MinDCF | |
| cos | 11.24 | 0.625 | 10.43 | 0.615 | 9.86 | 0.536 |
| PLDA | 10.98 | 0.611 | 10.21 | 0.623 | 9.79 | 0.535 |
| HT-PLDA | 9.96 | 0.573 | 9.62 | 0.633 | 8.47 | 0.520 |
| PSDA | 9.87 | 0.598 | 9.40 | 0.572 | 8.23 | 0.493 |
| CC-PSDA | 8.65 | 0.511 | 7.69 | 0.506 | 7.14 | 0.447 |
| 模型 | EER | MinDCF |
|---|---|---|
| TDNN+PLDA | 8.31 | 0.513 |
| TDNN+cos | 7.13 | 0.303 |
| TDNN+PSDA | 7.05 | 0.317 |
| TDNN+CC-PSDA | 6.87 | 0.222 |
Tab. 4 Comparison of recognition performance of various models using x-vector speaker features
| 模型 | EER | MinDCF |
|---|---|---|
| TDNN+PLDA | 8.31 | 0.513 |
| TDNN+cos | 7.13 | 0.303 |
| TDNN+PSDA | 7.05 | 0.317 |
| TDNN+CC-PSDA | 6.87 | 0.222 |
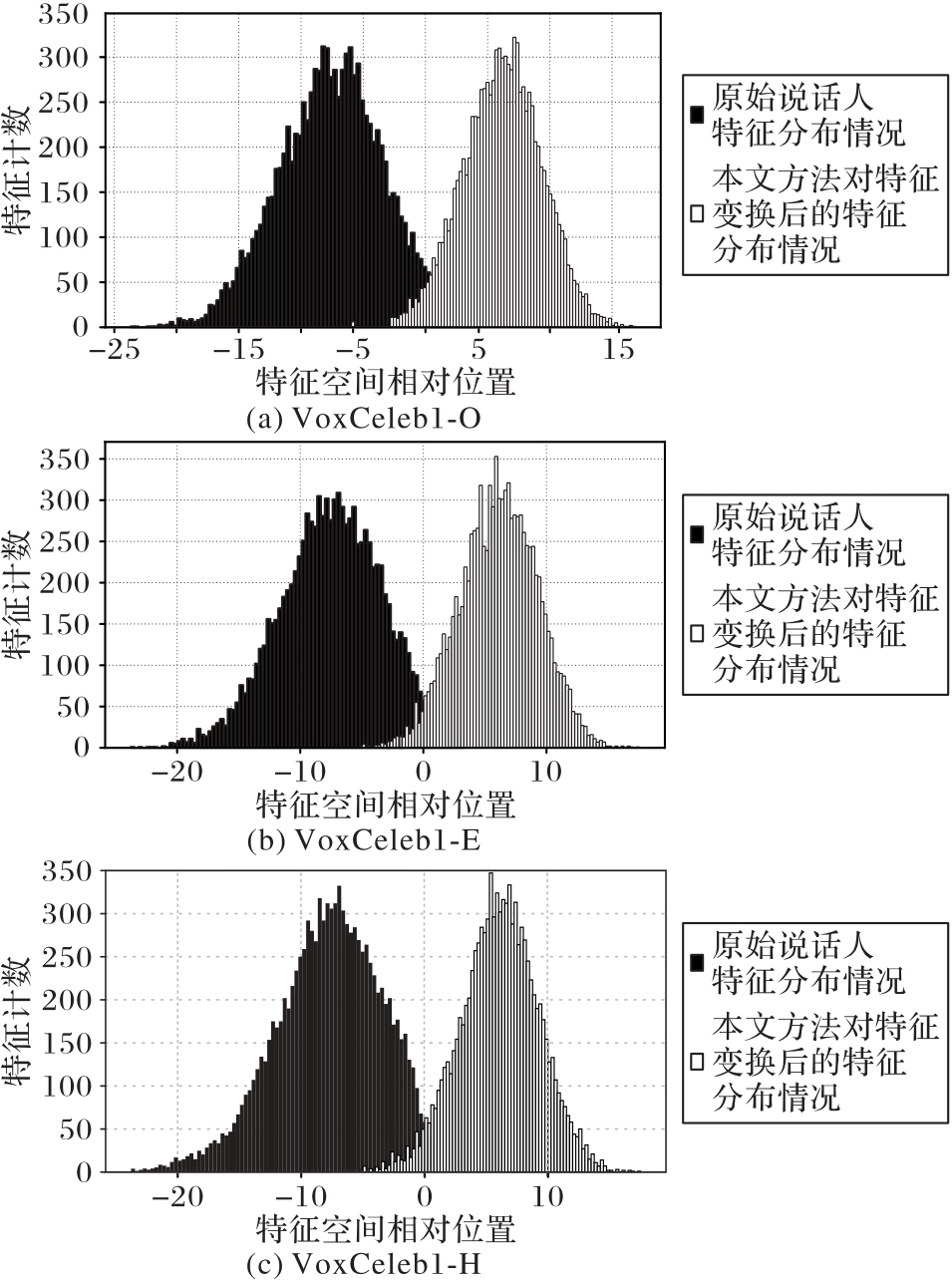
Fig. 3 Distribution of i-vector before and after feature transformation in different test sets
| 迭代次数 | VoxCeleb1-O | VoxCeleb1-E | VoxCeleb1-H | |||
|---|---|---|---|---|---|---|
| 变换前 | 变换后 | 变换前 | 变换后 | 变换前 | 变换后 | |
| 初值 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 1 | 60.87 | 80.23 | 85.91 | 80.10 | 80.43 | 88.42 |
| 2 | 40.91 | 73.10 | 70.66 | 79.21 | 89.16 | 79.90 |
| 3 | 39.66 | 45.87 | 60.78 | 66.89 | 77.94 | 63.27 |
| 4 | 38.36 | 30.17 | 48.13 | 54.21 | 67.09 | 55.81 |
| 5 | 37.11 | 29.68 | 50.32 | 45.90 | 52.43 | 49.33 |
| 6 | 37.28 | 29.80 | 45.12 | 41.01 | 51.88 | 48.84 |
| 7 | 37.28 | 29.80 | 44.65 | 39.82 | 50.29 | 48.63 |
| 8 | 37.28 | 29.80 | 44.65 | 39.77 | 50.01 | 48.63 |
| 9 | 37.28 | 29.80 | 44.65 | 39.77 | 50.01 | 48.63 |
| 10 | 37.28 | 29.80 | 44.65 | 39.77 | 50.01 | 48.63 |
Tab. 5 Update of between-class concentration parameter b in EM algorithm for CC-PSDA on different test sets
| 迭代次数 | VoxCeleb1-O | VoxCeleb1-E | VoxCeleb1-H | |||
|---|---|---|---|---|---|---|
| 变换前 | 变换后 | 变换前 | 变换后 | 变换前 | 变换后 | |
| 初值 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 1 | 60.87 | 80.23 | 85.91 | 80.10 | 80.43 | 88.42 |
| 2 | 40.91 | 73.10 | 70.66 | 79.21 | 89.16 | 79.90 |
| 3 | 39.66 | 45.87 | 60.78 | 66.89 | 77.94 | 63.27 |
| 4 | 38.36 | 30.17 | 48.13 | 54.21 | 67.09 | 55.81 |
| 5 | 37.11 | 29.68 | 50.32 | 45.90 | 52.43 | 49.33 |
| 6 | 37.28 | 29.80 | 45.12 | 41.01 | 51.88 | 48.84 |
| 7 | 37.28 | 29.80 | 44.65 | 39.82 | 50.29 | 48.63 |
| 8 | 37.28 | 29.80 | 44.65 | 39.77 | 50.01 | 48.63 |
| 9 | 37.28 | 29.80 | 44.65 | 39.77 | 50.01 | 48.63 |
| 10 | 37.28 | 29.80 | 44.65 | 39.77 | 50.01 | 48.63 |
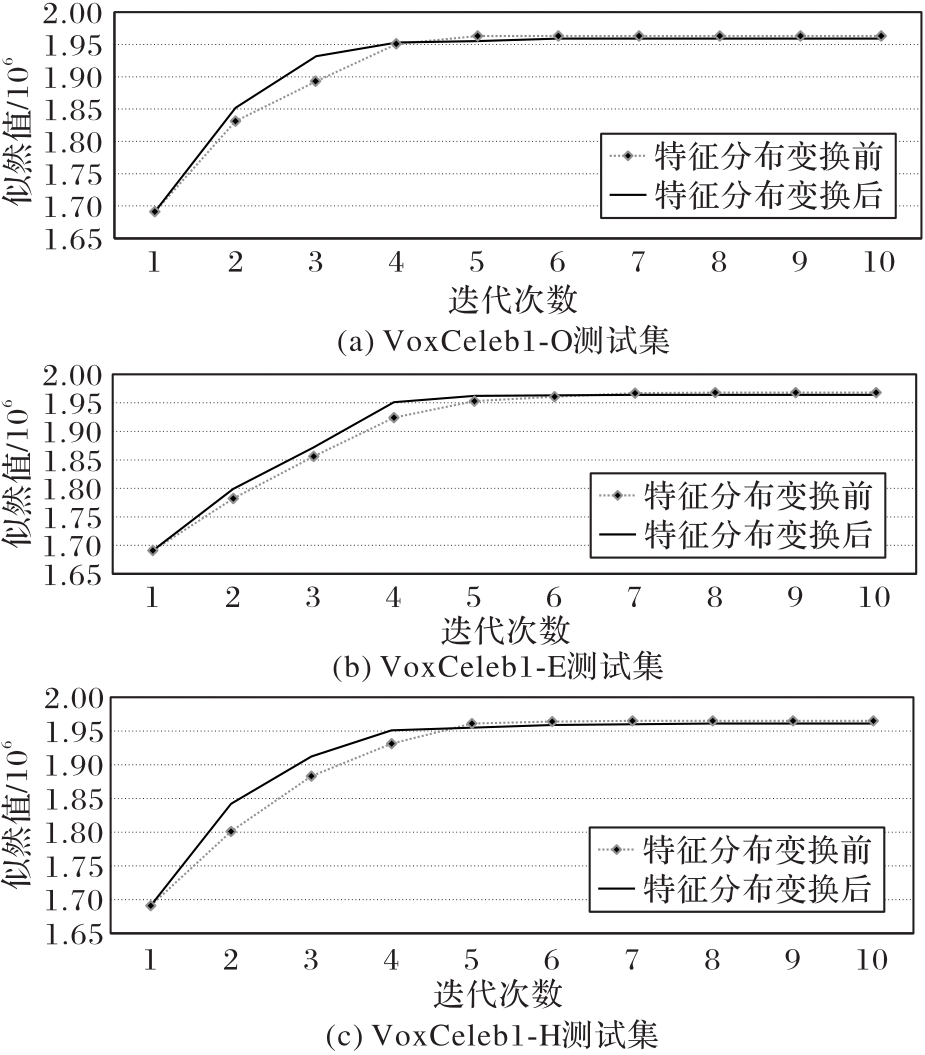
Fig. 4 EM algorithm training before and after CC-PSDA feature transformation in different test sets
| 1 | 陈晨,韩纪庆.说话人识别方法综述[J].智能计算机与应用,2015, 5(5):92-94,97. 10.3969/j.issn.2095-2163.2015.05.027 |
| CHEN C, HAN J Q. An overview of speaker recognition [J]. Intelligent Computer and Applications, 2015, 5(5):92-94,97. 10.3969/j.issn.2095-2163.2015.05.027 | |
| 2 | MATEJU L, KYNYCH F, CERVA P, et al. Overlapped speech detection in broadcast streams using x-vectors[C]// Proceedings of the Interspeech 2022. Baixas, France:International Speech Communication Association, 2022: 4606-4610. 10.21437/interspeech.2022-81 |
| 3 | DEHAK N, KENNY P J, DEHAK R, et al. Front-end factor analysis for speaker verification[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2010, 19(4): 788-798. 10.1109/tasl.2010.2064307 |
| 4 | SNYDER D, GARCIA-ROMERO D, SELL G, et al. X-vectors: Robust DNN embeddings for speaker recognition[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5329-5333. 10.1109/icassp.2018.8461375 |
| 5 | PRINCE S J D, ELDER J H. Probabilistic linear discriminant analysis for inferences about identity[C]// Proceedings of the 2007 IEEE 11th International Conference on Computer Vision. Piscataway: IEEE, 2007: 1-8. 10.1109/iccv.2007.4409052 |
| 6 | GARCIA-ROMERO D, ZHOU X, ESPY-WILSON C Y. Multicondition training of Gaussian PLDA models in i-vector space for noise and reverberation robust speaker recognition[C]// Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2012: 4257-4260. 10.1109/icassp.2012.6288859 |
| 7 | CAI W, CHEN J, LI M. Analysis of length normalization in end-to-end speaker verification system[EB/OL]. (2018-06-11) [2022-07-23]. . 10.21437/interspeech.2018-92 |
| 8 | MATĚJKA P, GLEMBEK O, CASTALDO F, et al. Full-covariance UBM and heavy-tailed PLDA in i-vector speaker verification[C]// Proceedings of the 2011 IEEE Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2011: 4828-4831. 10.1109/icassp.2011.5947436 |
| 9 | BRÜMMER N, SWART A, MOŠNER L, et al. Probabilistic spherical discriminant analysis: an alternative to PLDA for length-normalized embeddings [EB/OL]. (2022-03-28) [2022-09-10]. . 10.21437/interspeech.2022-731 |
| 10 | 罗家诚.基于改进信道补偿的I-vector说话人识别[J].电子设计工程,2021,29(20):96-100. 10.14022/j.issn1674-6236.2021.20.020 |
| LUO J C. Improving channel compensation for I-vector based speaker recognition [J]. Electronic Design Engineering,2021,29(20):96-100. 10.14022/j.issn1674-6236.2021.20.020 | |
| 11 | QIN X, BU H, LI M. HI-MIA: a far-field text-dependent speaker verification database and the baselines[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 7609-7613. 10.1109/icassp40776.2020.9054423 |
| 12 | 王明合, 唐振民, 张二华.基于i-vector局部加权线性判别分析的说话人识别[J]. 仪器仪表学报, 2015, 36(12): 2842-2848. 10.3969/j.issn.0254-3087.2015.12.026 |
| WANG M H, TANG Z M, ZHANG E H. I-vector based speaker recognition using local weighted linear discriminant analysis[J]. Chinese Journal of Scientific Instrument, 2015, 36(12): 2842-2848. 10.3969/j.issn.0254-3087.2015.12.026 | |
| 13 | DING K. A note on Kaldi’s PLDA implementation [EB/OL]. (2018-04-02) [2023-04-15]. . 10.48550/arXiv.1804.00403 |
| 14 | HE M, RAJ D, HUANG Z, et al. Target-speaker voice activity detection with improved i-vector estimation for unknown number of speaker [EB/OL]. (2021-08-07) [2022-07-13]. . 10.21437/interspeech.2021-750 |
| 15 | JONES M C, PEWSEY A. Sinh-arcsinh distributions[J]. Biometrika, 2009, 96(4): 761-780. 10.1093/biomet/asp053 |
| 16 | 茅正冲, 王俊俊, 黄舒伟.基于PLDA信道补偿的说话人识别算法[J]. 计算机与数字工程, 2019, 47(11): 2757-2762. 10.3969/j.issn.1672-9722.2019.11.023 |
| MAO Z C, WANG J J, HUANG S W. Speaker compensation algorithm based on channel compensation[J]. Computer and Digital Engineering, 2019, 47(11): 2757-2762. 10.3969/j.issn.1672-9722.2019.11.023 | |
| 17 | SILNOVA A, BRUMMER N, GARCIA-ROMERO D, et al. Fast variational Bayes for heavy-tailed PLDA applied to i-vectors and x-vectors [EB/OL]. (2018-03-24) [2022-06-15]. . 10.21437/interspeech.2018-2128 |
| 18 | ZHAO M, MA Y, LIU M, et al. The speakIn system for VoxCeleb speaker recognition challange 2021 [EB/OL]. (2021-09-05) [2022-04-11]. . 10.48550/arXiv.2109.01989 |
| 19 | BANERJEE A, DHILLON I S, GHOSH J, et al. Clustering on the unit hypersphere using Von Mises-Fisher distributions[J]. The Journal of Machine Learning Research, 2005, 6: 1345-1382. 10.1007/s10846-005-9023-3 |
| 20 | LIU Y, LI Z, LI L, et al. Phoneme-aware and channel-wise attentive learning for text dependentspeaker verification [EB/OL]. (2021-06-25) [2023-04-15]. . 10.21437/interspeech.2021-2137 |
| 21 | ZHU G, JIANG F, DUAN Z. Y-vector: multiscale waveform encoder for speaker embedding [EB/OL]. (2021-06-09) [2022-04-25]. . 10.21437/interspeech.2021-1707 |
| 22 | RAJAN R, KUMAR A V, BABU B P. Poetic meter classification using i-Vector-MTF fusion[C]// Proceedings of the 21st Annual Conference of the International Speech Communication Association. Baixas, France:International Speech Communication Association, 2020: 145-149. 10.21437/interspeech.2020-1794 |
| 23 | 肜娅峰, 陈晨, 陈德运,等.基于贝叶斯主成分分析的i-vector说话人确认方法[J].电子学报,2021,49(11):2186-2194. 10.12263/DZXB.20200476 |
| RONG Y F, CHEN C, CHEN D Y, et al. Bayesian principal component analysis for i-vector speaker verification[J]. Acta Electronica Sinica, 2021, 49(11): 2186-2194. 10.12263/DZXB.20200476 | |
| 24 | CHEN Z, LIN Y. Improving x-vector and PLDA for text-dependent speaker verification[C]// Proceedings of the 21st Annual Conference of the International Speech Communication Association. Baixas, France:International Speech Communication Association, 2020: 726-730. 10.21437/interspeech.2020-1188 |
| 25 | NGUYEN H V, BAI L. Cosine similarity metric learning for face verification[C]// Proceedings of the 10th Asian Conference on Computer Vision. Berlin: Springer, 2011: 709-720. 10.1007/978-3-642-19309-5_55 |
| 26 | OKABE K, KOSHINAKA T, SHINODA K. Attentive statistics pooling for deep speaker embedding [EB/OL]. (2019-02-25) [2023-01-15]. . 10.21437/interspeech.2018-993 |
| [1] | FANG Xin, HUANG Zexin, ZHANG Yuhan, GAO Tian, PAN Jia, FU Zhonghua, GAO Jianqing, LIU Junhua, ZOU Liang. Semi‑supervised end‑to‑end fake speech detection method based on time‑domain waveforms [J]. Journal of Computer Applications, 2023, 43(1): 227-231. |
| [2] | NIU Xiaoke, HUANG Yixin, XU Huaxing, JIANG Zhenyang. Speaker recognition in strong noise environment based on auditory cortical neuronal receptive field [J]. Journal of Computer Applications, 2020, 40(10): 3034-3040. |
| [3] | SUN Nian, ZHANG Yi, LIN Haibo, HUANG Chao. Short utterance speaker recognition algorithm based on multi-featured i-vector [J]. Journal of Computer Applications, 2018, 38(10): 2839-2843. |
| [4] | HUANG Wenna, PENG Yaxiong, HE Song. Vocal effort in speaker recognition based on MAP+CMLLR [J]. Journal of Computer Applications, 2017, 37(3): 906-910. |
| [5] | WANG Haibin, YU Zhengtao, MAO Cunli, GUO Jianyi. SMFCC: a novel feature extraction method for speech signal [J]. Journal of Computer Applications, 2016, 36(6): 1735-1740. |
| [6] | XIE Xiaojuan, ZENG Yicheng, XIONG Bingfeng. Feature combination method based on Fisher criterion in speaker recognition [J]. Journal of Computer Applications, 2016, 36(5): 1421-1425. |
| [7] | ZHANG Jun, GUAN Shengxiao. Integration algorithm of improved maximum a posteriori probability vector quantization and least squares support vector machine [J]. Journal of Computer Applications, 2015, 35(7): 2101-2104. |
| [8] | CHU Wen LI Yinguo XU Yang MENG Xiangtao. Speaker recognition method based on utterance level principal component analysis [J]. Journal of Computer Applications, 2013, 33(07): 1935-1937. |
| [9] | CHEN Zhimin MENG Zuqiang LIN Qifeng. Chinese story link detection based on extraction of elements correlative word [J]. Journal of Computer Applications, 2013, 33(01): 182-185. |
| [10] | HU Feng-song ZHANG Xuan. Speaker recognition method based on Mel frequency cepstrum coefficient and inverted Mel frequency cepstrum coefficient [J]. Journal of Computer Applications, 2012, 32(09): 2542-2544. |
| [11] | HE Wei XU Yang ZHANG Ling. Implementation and optimization of speaker recognition algorithm based on SOPC [J]. Journal of Computer Applications, 2012, 32(05): 1463-1466. |
| [12] | Liang HE Jia LIU. Speaker recognition based on linear log-likelihood kernel function [J]. Journal of Computer Applications, 2011, 31(08): 2083-2086. |
| [13] | . Recognition feature extraction based on little speech data for speaker under noisy conditions [J]. Journal of Computer Applications, 2010, 30(10): 2712-2714. |
| [14] | ZHANG Wei-Jie Wan-Chun FEI Liang-Jun XU Lu LIU. Study on a novel method of speaker recognition [J]. Journal of Computer Applications, 2009, 29(3): 764-767. |
| [15] | Ming Kang Cheng Liang Wang . Vector quantization based on the dynamic threshold of speaker recognition [J]. Journal of Computer Applications, 2009, 29(1): 146-148. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||