


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (5): 1636-1643.DOI: 10.11772/j.issn.1001-9081.2023050663
Special Issue: 多媒体计算与计算机仿真
• Multimedia computing and computer simulation • Previous Articles Next Articles
Juxiang ZHOU1,2, Jinsheng LIU1( ), Jianhou GAN1,2, Di WU1, Zijie LI1
), Jianhou GAN1,2, Di WU1, Zijie LI1
Received:2023-05-29
Revised:2023-08-16
Accepted:2023-09-12
Online:2023-09-19
Published:2024-05-10
Contact:
Jinsheng LIU
About author:ZHOU Juxiang, born in 1986, Ph. D., associate professor. Her research interests include smart education, computer vision, speech recognition.Supported by:
周菊香1,2, 刘金生1(), 甘健侯1,2, 吴迪1, 李子杰1
通讯作者:
刘金生
作者简介:周菊香(1986—),女,陕西蓝田人,副教授,博士,CCF会员,主要研究方向:智慧教育、计算机视觉、语音识别基金资助:CLC Number:
Juxiang ZHOU, Jinsheng LIU, Jianhou GAN, Di WU, Zijie LI. Classroom speech emotion recognition method based on multi-scale temporal-aware network[J]. Journal of Computer Applications, 2024, 44(5): 1636-1643.
周菊香, 刘金生, 甘健侯, 吴迪, 李子杰. 基于多尺度时序感知网络的课堂语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1636-1643.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023050663
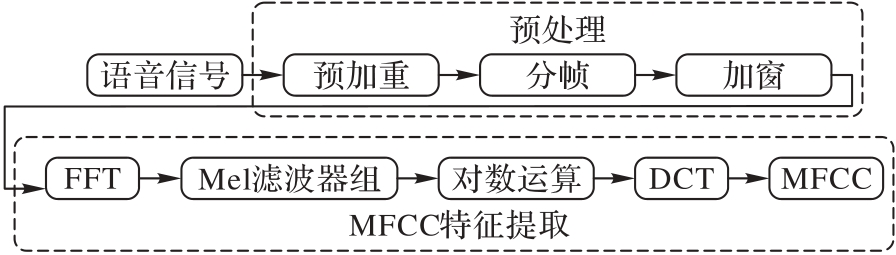
Fig. 1 MFCC feature extraction process

Fig. 2 Cross-gated mechanism
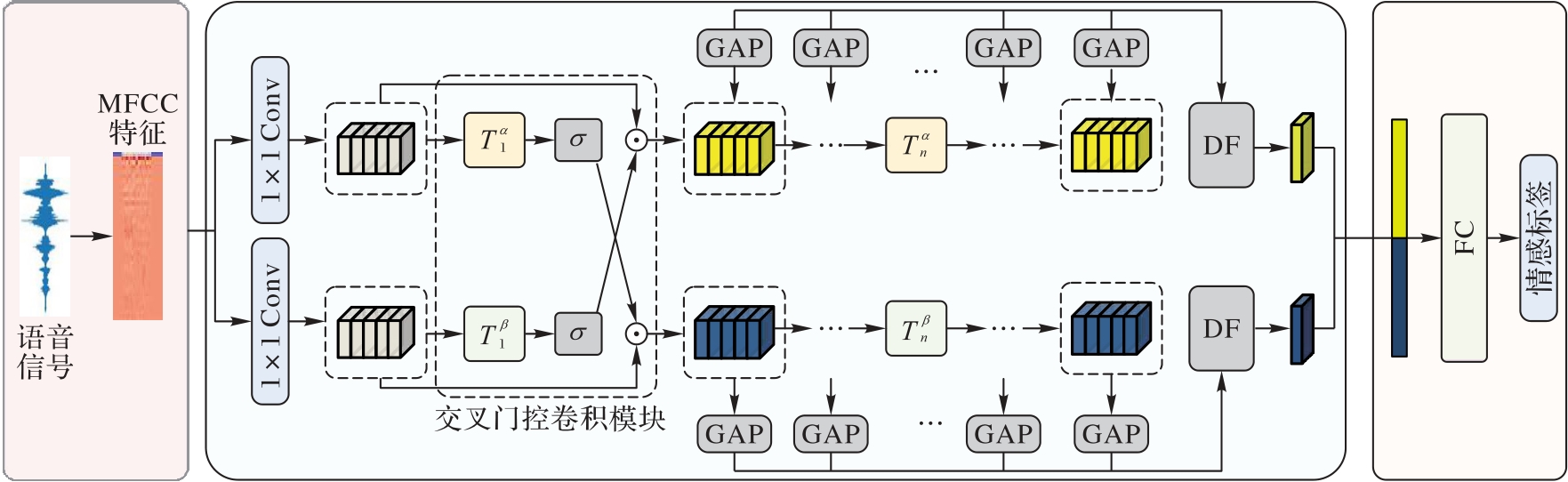
Fig. 3 Structure of multi-scale temporal-aware network

Fig. 4 Structure of TCN

Fig. 5 Structure of temporal-aware module
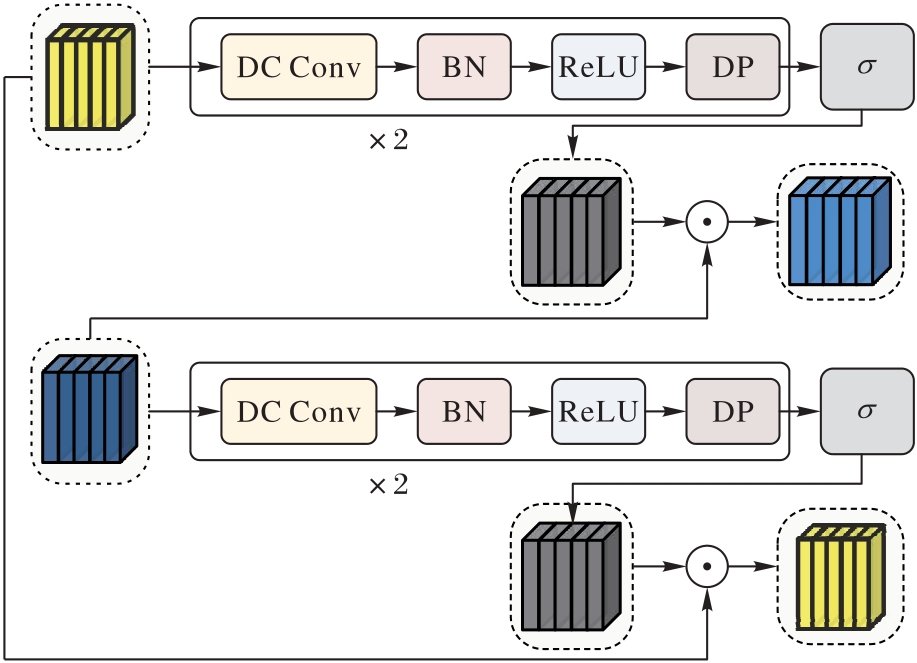
Fig. 6 Cross-gated convolution module
| 学段 | 年级 | 教师性别 |
|---|---|---|
| 小学 | 三年级 | 女 |
| 五年级 | 男 | |
| 初中 | 七年级 | 女 |
| 七年级 | 女 | |
| 高中 | 高二 | 女 |
| 高二 | 男 |
Tab. 1 Source information of corpus
| 学段 | 年级 | 教师性别 |
|---|---|---|
| 小学 | 三年级 | 女 |
| 五年级 | 男 | |
| 初中 | 七年级 | 女 |
| 七年级 | 女 | |
| 高中 | 高二 | 女 |
| 高二 | 男 |
| 情感类别 | 在课堂中的解释 |
|---|---|
| 高昂 | 教师和学生都包含;课堂氛围浓厚,声音较大,例如教师或学生富有感情地大声朗读、学生齐声大声朗读等。 |
| 紧张 | 多为学生情感;出现次数较少,例如当学生回答问题时因紧张导致回答声音小、磕磕绊绊等。 |
| 平静 | 教师和学生都包含;教师正常地讲课,学生正常地回答问题,没有明显的情感波动。 |
| 疑问 | 多为教师情感;老师对学生进行提问时的疑问语气,例如“哪位同学可以来读一下这段话呢?” |
| 满意 | 多为教师情感;当教师对学生的回答表示满意、赞同时,例如“嗯,回答得不错!”“回答得非常好!” |
| 沉默 | 课堂中无人讲话,学生在思考问题,但有其他的细微声音,例如教师板书发出的声音、学生移动身体发出的声音及其他不明显声音等。 |
Tab. 2 Meanings of emotional categories in classroom speech
| 情感类别 | 在课堂中的解释 |
|---|---|
| 高昂 | 教师和学生都包含;课堂氛围浓厚,声音较大,例如教师或学生富有感情地大声朗读、学生齐声大声朗读等。 |
| 紧张 | 多为学生情感;出现次数较少,例如当学生回答问题时因紧张导致回答声音小、磕磕绊绊等。 |
| 平静 | 教师和学生都包含;教师正常地讲课,学生正常地回答问题,没有明显的情感波动。 |
| 疑问 | 多为教师情感;老师对学生进行提问时的疑问语气,例如“哪位同学可以来读一下这段话呢?” |
| 满意 | 多为教师情感;当教师对学生的回答表示满意、赞同时,例如“嗯,回答得不错!”“回答得非常好!” |
| 沉默 | 课堂中无人讲话,学生在思考问题,但有其他的细微声音,例如教师板书发出的声音、学生移动身体发出的声音及其他不明显声音等。 |
情感 类别 | 初始 标注数 | 增强 数据数 | 增强数据 采样数 | 重采样 后数量 |
|---|---|---|---|---|
| 总计 | 2 010 | 2 016 | 648 | 1 800 |
| 高昂 | 474 | 0 | 0 | 300 |
| 紧张 | 71 | 568 | 229 | 300 |
| 平静 | 626 | 0 | 0 | 300 |
| 疑问 | 98 | 784 | 202 | 300 |
| 满意 | 83 | 664 | 217 | 300 |
| 沉默 | 658 | 0 | 0 | 300 |
Tab. 3 Speech emotion corpus for teaching
情感 类别 | 初始 标注数 | 增强 数据数 | 增强数据 采样数 | 重采样 后数量 |
|---|---|---|---|---|
| 总计 | 2 010 | 2 016 | 648 | 1 800 |
| 高昂 | 474 | 0 | 0 | 300 |
| 紧张 | 71 | 568 | 229 | 300 |
| 平静 | 626 | 0 | 0 | 300 |
| 疑问 | 98 | 784 | 202 | 300 |
| 满意 | 83 | 664 | 217 | 300 |
| 沉默 | 658 | 0 | 0 | 300 |

Fig. 7 Comparison of data augmented spectrograms
| D | UAR/% | WAR/% | ||
|---|---|---|---|---|
| TIM-Net | 本文方法 | TIM-Net | 本文方法 | |
| 2 | 89.85 | 90.21 | 89.78 | 90.17 |
| 4 | 90.11 | 90.31 | 89.94 | 90.17 |
| 6 | 90.17 | 90.58 | 90.11 | 90.44 |
| 8 | 90.05 | 90.51 | 90.00 | 90.45 |
Tab. 4 Performance comparison of proposed method and TIM-Net at different D on self-built corpus
| D | UAR/% | WAR/% | ||
|---|---|---|---|---|
| TIM-Net | 本文方法 | TIM-Net | 本文方法 | |
| 2 | 89.85 | 90.21 | 89.78 | 90.17 |
| 4 | 90.11 | 90.31 | 89.94 | 90.17 |
| 6 | 90.17 | 90.58 | 90.11 | 90.44 |
| 8 | 90.05 | 90.51 | 90.00 | 90.45 |

Fig. 8 Comparison of confusion matrixes of proposed method and TIM-Net at different D on self-built corpus
| 数据集 | 语言 | 样本数 | 数据集 | 语言 | 样本数 |
|---|---|---|---|---|---|
| CASIA | 汉语 | 1 200 | IEMOCAP | 英语 | 5 531 |
| EMODB | 德语 | 535 | RAVDESS | 英语 | 1 440 |
| EMOVO | 意大利语 | 588 | SAVEE | 英语 | 480 |
Tab. 5 Basic information of six experimental datasets
| 数据集 | 语言 | 样本数 | 数据集 | 语言 | 样本数 |
|---|---|---|---|---|---|
| CASIA | 汉语 | 1 200 | IEMOCAP | 英语 | 5 531 |
| EMODB | 德语 | 535 | RAVDESS | 英语 | 1 440 |
| EMOVO | 意大利语 | 588 | SAVEE | 英语 | 480 |
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| TLFMRF[ | 85.83 | 85.83 | TIM-Net[ | 90.20 | 90.33 |
| CNN[ | 87.90 | 87.90 | 本文方法 | 90.60 | 90.75 |
| GM-TCNet[ | 89.50 | 89.50 |
Tab. 6 Comparison of UAR and WAR of each method on CASIA dataset
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| TLFMRF[ | 85.83 | 85.83 | TIM-Net[ | 90.20 | 90.33 |
| CNN[ | 87.90 | 87.90 | 本文方法 | 90.60 | 90.75 |
| GM-TCNet[ | 89.50 | 89.50 |
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| LMT[ | 68.00 | 70.40 | TIM-Net[ | 89.90 | 90.09 |
| TLFMRF[ | — | 87.85 | 本文方法 | 89.30 | 89.53 |
| GM-TCNet[ | 89.47 | 89.35 |
Tab. 7 Comparison of UAR and WAR of each method on EMODB dataset
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| LMT[ | 68.00 | 70.40 | TIM-Net[ | 89.90 | 90.09 |
| TLFMRF[ | — | 87.85 | 本文方法 | 89.30 | 89.53 |
| GM-TCNet[ | 89.47 | 89.35 |
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| RM-CN[ | 68.93 | 68.93 | TIM-Net[ | 87.78 | 87.59 |
| TSP+INCA[ | 79.08 | 79.08 | 本文方法 | 87.57 | 87.08 |
| CTL-MTNet[ | 85.40 | 85.40 |
Tab. 8 Comparison of UAR and WAR of each method on EMOVO dataset
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| RM-CN[ | 68.93 | 68.93 | TIM-Net[ | 87.78 | 87.59 |
| TSP+INCA[ | 79.08 | 79.08 | 本文方法 | 87.57 | 87.08 |
| CTL-MTNet[ | 85.40 | 85.40 |
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| CNN-LSTM[ | 63.70 | 68.80 | TIM-Net[ | 70.04 | 69.08 |
| MPM[ | 64.50 | 65.50 | 本文方法 | 70.38 | 69.01 |
| GLAM[ | 68.20 | 69.70 |
Tab. 9 Comparison of UAR and WAR of each method on IEMOCAP dataset
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| CNN-LSTM[ | 63.70 | 68.80 | TIM-Net[ | 70.04 | 69.08 |
| MPM[ | 64.50 | 65.50 | 本文方法 | 70.38 | 69.01 |
| GLAM[ | 68.20 | 69.70 |
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| LMT[ | 71.00 | 71.60 | GM-TCNet[ | 86.91 | 87.08 |
| Bi-LSTM[ | 77.00 | 86.00 | 本文方法 | 87.32 | 87.29 |
| TIM-Net[ | 85.74 | 85.90 |
Tab. 10 Comparison of UAR and WAR of each method on RAVDESS dataset
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| LMT[ | 71.00 | 71.60 | GM-TCNet[ | 86.91 | 87.08 |
| Bi-LSTM[ | 77.00 | 86.00 | 本文方法 | 87.32 | 87.29 |
| TIM-Net[ | 85.74 | 85.90 |
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| SVM[ | — | 69.80 | TIM-Net[ | 80.96 | 82.92 |
| Zeta[ | 68.90 | — | 本文方法 | 81.84 | 83.13 |
| LMT[ | 68.00 | 70.40 |
Tab. 11 Comparison of UAR and WAR of each method on SAVEE dataset
| 方法 | UAR | WAR | 方法 | UAR | WAR |
|---|---|---|---|---|---|
| SVM[ | — | 69.80 | TIM-Net[ | 80.96 | 82.92 |
| Zeta[ | 68.90 | — | 本文方法 | 81.84 | 83.13 |
| LMT[ | 68.00 | 70.40 |
| D | UAR/% | WAR/% | ||||
|---|---|---|---|---|---|---|
本文 方法 | 无交叉 门控机制 | 无多尺度特征融合 | 本文 方法 | 无交叉 门控机制 | 无多尺度特征融合 | |
| 2 | 90.21 | 89.64 | 90.19 | 90.17 | 89.54 | 90.06 |
| 4 | 90.31 | 90.05 | 89.95 | 90.17 | 90.00 | 90.00 |
| 6 | 90.58 | 90.01 | 90.18 | 90.44 | 90.04 | 90.12 |
| 8 | 90.51 | 90.19 | 90.15 | 90.45 | 90.05 | 90.13 |
Tab. 12 Results of ablation experiments
| D | UAR/% | WAR/% | ||||
|---|---|---|---|---|---|---|
本文 方法 | 无交叉 门控机制 | 无多尺度特征融合 | 本文 方法 | 无交叉 门控机制 | 无多尺度特征融合 | |
| 2 | 90.21 | 89.64 | 90.19 | 90.17 | 89.54 | 90.06 |
| 4 | 90.31 | 90.05 | 89.95 | 90.17 | 90.00 | 90.00 |
| 6 | 90.58 | 90.01 | 90.18 | 90.44 | 90.04 | 90.12 |
| 8 | 90.51 | 90.19 | 90.15 | 90.45 | 90.05 | 90.13 |
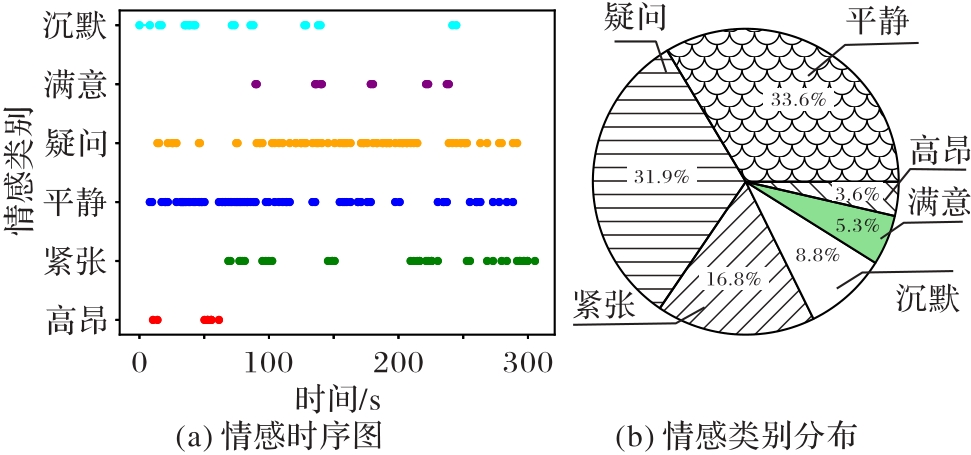
Fig. 9 Classroom speech emotion sequence diagram
| 1 | MARSLEN-WILSON W. The perception of speech: from sound to meaning[J]. Perception, 2008, 363(1493): 915-1122. 10.1098/rstb.2007.2195 |
| 2 | ZOU H, SI Y, CHEN C, et al. Speech emotion recognition with co-attention based multi-level acoustic information[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7367-7371. 10.1109/icassp43922.2022.9747095 |
| 3 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL]. (2017-12-06) [2023-09-12]. . |
| 4 | ZHONG Y, HU Y, HUANG H, et al. A lightweight model based on separable convolution for speech emotion recognition[C]// Proceedings of the Interspeech 2020. [S.l.]: International Speech Communication Association, 2020: 3331-3335. 10.21437/interspeech.2020-2408 |
| 5 | LIU L-Y, LIU W-Z, FENG L. SDTF-Net: static and dynamic time-frequency network for speech emotion recognition[J]. Speech Communication, 2023, 148: 1-8. 10.1016/j.specom.2023.01.008 |
| 6 | YUAN Q. A classroom emotion recognition model based on a convolutional neural network speech emotion algorithm[J]. Occupational Therapy International, 2022, 2022: 9563877. 10.1155/2022/9563877 |
| 7 | LAI L. English flipped classroom teaching mode based on emotion recognition technology[J]. Frontiers in Psychology, 2022, 13: 945273. 10.3389/fpsyg.2022.945273 |
| 8 | 钱婷.基于传统课堂的教师话语情感识别研究[D].武汉:华中师范大学,2019:26-39. 10.35745/ecei2019v2.102 |
| QIAN T. Research on teacher’s discourse emotion recognition based on traditional classroom [D]. Wuhan: Central China Normal University, 2019: 26-39. 10.35745/ecei2019v2.102 | |
| 9 | 王旭阳.基于深度学习的教师语音情感识别研究[D].武汉:华中师范大学,2021:33-42. |
| WANG X Y. Research on teacher’s speech emotion recognition based on deep learning [D]. Wuhan: Central China Normal University, 2021: 33-42. | |
| 10 | LIKITHA M S, GUPTA S R R, HASITHA K, et al. Speech based human emotion recognition using MFCC[C]// Proceedings of the 2017 International Conference on Wireless Communications, Signal Processing and Networking. Piscataway: IEEE, 2017: 2257-2260. 10.1109/wispnet.2017.8300161 |
| 11 | YE J, WEN X-C, WEI Y, et al. Temporal modeling matters: a novel temporal emotional modeling approach for speech emotion recognition[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. 10.1109/icassp49357.2023.10096370 |
| 12 | PATNAIK S. Speech emotion recognition by using complex MFCC and deep sequential model[J]. Multimedia Tools and Applications, 2023, 82: 11897-11922. 10.1007/s11042-022-13725-y |
| 13 | ZHANG J, YAN W, ZHANG Y. A new speech feature fusion method with cross gate parallel CNN for speaker recognition [EB/OL]. [2023-09-12]. . 10.1109/access.2023.3294274 |
| 14 | WANG J, XUE M, CULHANE R, et al. Speech emotion recognition with dual-sequence LSTM architecture[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6474-6478. 10.1109/icassp40776.2020.9054629 |
| 15 | ANDAYANI F, THENG L B, TSUN M T, et al. Hybrid LSTM-transformer model for emotion recognition from speech audio files[J]. IEEE Access, 2022, 10: 36018-36027. 10.1109/access.2022.3163856 |
| 16 | CHEN W, XING X, XU X, et al. DST: deformable speech Transformer for emotion recognition[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. 10.1109/icassp49357.2023.10096966 |
| 17 | CHEN S, XING X, ZHANG W, et al. DWFormer: dynamic window transformer for speech emotion recognition[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. 10.1109/icassp49357.2023.10094651 |
| 18 | BAI S, KOLTER J Z, KOLTUN V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling [EB/OL]. (2018-04-19) [2023-09-12]. . |
| 19 | TAO H, SHAN S, HU Z, et al. Strong generalized speech emotion recognition based on effective data augmentation[J]. Entropy, 2022, 25(1): 68. 10.3390/e25010068 |
| 20 | McFEE B, RAFFEL C, LIANG D, et al. librosa: audio and music signal analysis in Python[C]// Proceedings of the 14th Python in Science Conference. Austin: Scientific Computing with Python, 2015: 18-24. 10.25080/majora-7b98e3ed-003 |
| 21 | BURKHARDT F, PAESCHKE A, ROLFES M, et al. A database of German emotional speech[C]// Proceedings of the INTERSPEECH 2005. [S.l.]: International Speech Communication Association, 2005: 1517-1520. 10.21437/interspeech.2005-446 |
| 22 | COSTANTINI G, IADEROLA I, PAOLONI A, et al. EMOVO corpus: an Italian emotional speech database[C]// Proceedings of the 9th International Conference on Language Resources and Evaluation. Paris: European Language Resources Association, 2014: 3501-3504. |
| 23 | BUSSO C, BULUT M, LEE C-C, et al. IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42: 335-359. 10.1007/s10579-008-9076-6 |
| 24 | LIVINGSTONE S R, RUSSO F A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): a dynamic, multimodal set of facial and vocal expressions in North American English[J]. PLoS ONE, 2018, 13(5): e0196391. 10.1371/journal.pone.0196391 |
| 25 | JACKSON P, HAQ S . Surrey Audio-Visual Expressed Emotion (SAVEE) database [DB/OL]. (2015-01-05) [2023-09-12]. . |
| 26 | CHEN L, SU W, FENG Y, et al. Two-layer fuzzy multiple random forest for speech emotion recognition in human-robot interaction[J]. Information Sciences, 2020, 509: 150-163. 10.1016/j.ins.2019.09.005 |
| 27 | GAO M, DONG J, ZHOU D, et al. End-to-end speech emotion recognition based on one-dimensional convolutional neural network[C]// Proceedings of the 2019 3rd International Conference on Innovation in Artificial Intelligence. New York: ACM, 2019: 78-82. 10.1145/3319921.3319963 |
| 28 | YE J-X, WEN X-C, WANG X-Z, et al. GM-TCNet: gated multi-scale temporal convolutional network using emotion causality for speech emotion recognition[J]. Speech Communication, 2022, 145: 21-35. 10.1016/j.specom.2022.07.005 |
| 29 | ASSUNÇÃO G, MENEZES P, PERDIGÃO F. Speaker awareness for speech emotion recognition[J]. International Journal of Online and Biomedical Engineering, 2020, 16(4): 15-22. 10.3991/ijoe.v16i04.11870 |
| 30 | OZER I. Pseudo-colored rate map representation for speech emotion recognition[J]. Biomedical Signal Processing and Control, 2021, 66: 102502. 10.1016/j.bspc.2021.102502 |
| 31 | TUNCER T, DOGAN S, ACHARYA U R. Automated accurate speech emotion recognition system using twine shuffle pattern and iterative neighborhood component analysis techniques[J]. Knowledge-Based Systems, 2021, 211: 106547. 10.1016/j.knosys.2020.106547 |
| 32 | WEN X-C, YE J-X, LUO Y, et al. CTL-MTNet: a novel CapsNet and transfer learning-based mixed task net for single-corpus and cross-corpus speech emotion recognition[C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: IJCAI, 2022: 2305-2311. 10.24963/ijcai.2022/320 |
| 33 | SATT A, ROZENBERG S, HOORY R. Efficient emotion recognition from speech using deep learning on spectrograms[C]// Proceedings of the Interspeech 2017. [S.l.]: International Speech Communication Association, 2017: 1089-1093. 10.21437/interspeech.2017-200 |
| 34 | NEDIYANCHATH A, PARAMASIVAM P, YENIGALLA P. Multi-head attention for speech emotion recognition with auxiliary learning of gender recognition[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 7179-7183. 10.1109/icassp40776.2020.9054073 |
| 35 | ZHU W, LI X. Speech emotion recognition with global-aware fusion on multi-scale feature representation[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6437-6441. 10.1109/icassp43922.2022.9747517 |
| 36 | MUSTAQEEM, SAJJAD M, KWON S. Clustering-based speech emotion recognition by incorporating learned features and deep BiLSTM[J]. IEEE Access, 2020, 8: 79861-79875. 10.1109/access.2020.2990405 |
| 37 | KANWAL S, ASGHAR S. Speech emotion recognition using clustering based GA-optimized feature set[J]. IEEE Access, 2021, 9: 125830-125842. 10.1109/access.2021.3111659 |
| 38 | RAJAPAKSHE T, RANA R, KHALIFA S, et al. A novel policy for pre-trained deep reinforcement learning for speech emotion recognition[C]// Proceedings of the 2022 Australasian Computer Science Week. New York: ACM, 2022: 96-105. 10.1145/3511616.3513104 |
| [1] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [2] | Xingyao YANG, Hongtao SHEN, Zulian ZHANG, Jiong YU, Jiaying CHEN, Dongxiao WANG. Sequential recommendation based on hierarchical filter and temporal convolution enhanced self-attention network [J]. Journal of Computer Applications, 2024, 44(10): 3090-3096. |
| [3] | Yang WANG, Hongliang FU, Huawei TAO, Jing YANG, Yue XIE, Li ZHAO. Cross-corpus speech emotion recognition based on decision boundary optimized domain adaptation [J]. Journal of Computer Applications, 2023, 43(2): 374-379. |
| [4] | Xiaomeng SHAO, Meng ZHANG. Temporal convolutional knowledge tracing model with attention mechanism [J]. Journal of Computer Applications, 2023, 43(2): 343-348. |
| [5] | Shuying YANG, Haiming GUO, Xin LI. EEG classification based on channel selection and multi-dimensional feature fusion [J]. Journal of Computer Applications, 2023, 43(11): 3418-3427. |
| [6] | Qingqing NIE, Dingsheng WAN, Yuelong ZHU, Zhijia LI, Cheng YAO. Hydrological model based on temporal convolutional network [J]. Journal of Computer Applications, 2022, 42(6): 1756-1761. |
| [7] | Lei YANG, Hongdong ZHAO, Kuaikuai YU. End-to-end speech emotion recognition based on multi-head attention [J]. Journal of Computer Applications, 2022, 42(6): 1869-1875. |
| [8] | LIU Shize, ZHU Yida, CHEN Runze, LUO Haiyong, ZHAO Fang, SUN Yi, WANG Baohui. Traffic mode recognition algorithm based on residual temporal attention neural network [J]. Journal of Computer Applications, 2021, 41(6): 1557-1565. |
| [9] | YAO Jie, CHENG Chunling, HAN Jing, LIU Zheng. Anomaly detection method based on multi-task temporal convolutional network in cloud workflow [J]. Journal of Computer Applications, 2021, 41(6): 1701-1708. |
| [10] | ZHU Lin, NING Qian, LEI Yinjie, CHEN Bingcai. Remaining useful life prediction for turbofan engines by genetic algorithm-based selective ensembling and temporal convolutional network [J]. Journal of Computer Applications, 2020, 40(12): 3534-3540. |
| [11] | WANG Tianrui, BAO Qianyue, QIN Pinle. Environmental sound classification method based on Mel-frequency cepstral coefficient, deep convolution and Bagging [J]. Journal of Computer Applications, 2019, 39(12): 3515-3521. |
| [12] | XIANG Li, YAN Diqun, WANG Rangding, LI Xiaowen. Forensics algorithm of various operations for digital speech [J]. Journal of Computer Applications, 2019, 39(1): 126-130. |
| [13] | ZHANG Xiaoxia LI Ying. Bird sounds recognition based on energy detection in complex environments [J]. Journal of Computer Applications, 2013, 33(10): 2945-2949. |
| [14] | LI Shuling LIU Rong ZHANG Liuqin LIU Hong. Speech emotion recognition algorithm based on modified SVM [J]. Journal of Computer Applications, 2013, 33(07): 1938-1941. |
| [15] | Li-Qin Fu Xia Mao Li-Jiang Chen. Classifier fusion for speech emotion recognition based on improved queuing voting algorithm [J]. Journal of Computer Applications, 2009, 29(2): 381-385. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||