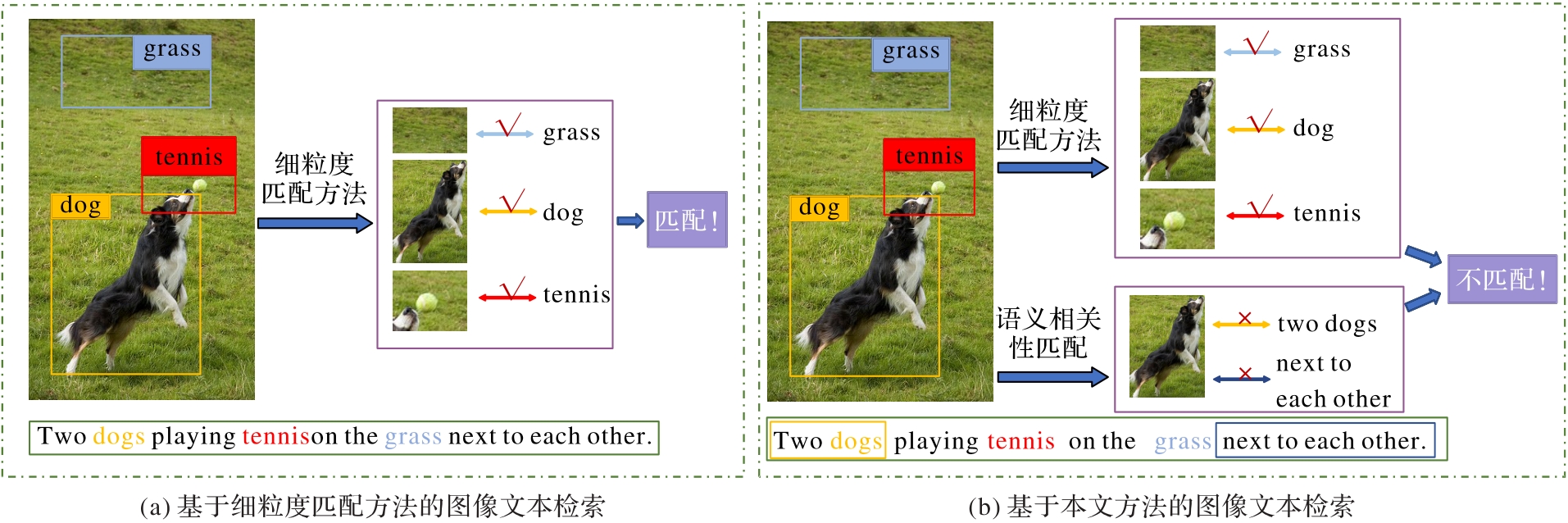
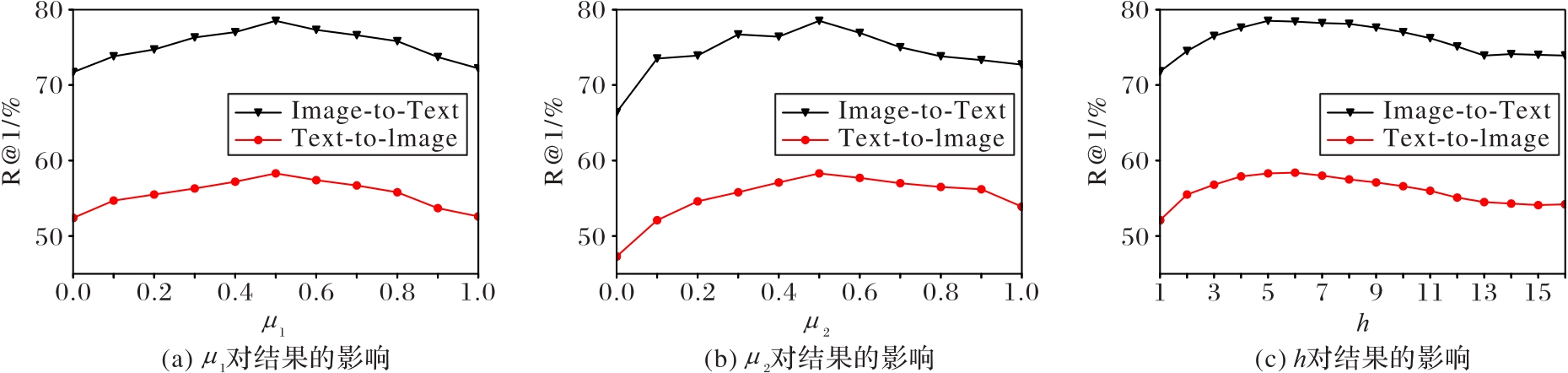
| 1 |
刘颖,郭莹莹,房杰,等.深度学习跨模态图文检索研究综述[J].计算机科学与探索, 2022, 16(3): 489-511. 10.3778/j.issn.1673-9418.2107076
|
|
LIU Y, GUO Y Y, FANG J, et al. Survey of research on deep learning image-text cross-modal retrieval [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 489-511. 10.3778/j.issn.1673-9418.2107076
|
| 2 |
LI X, WANG Y, SHA Z. Deep learning methods of cross-modal tasks for conceptual design of product shapes: a review [J]. Journal of Mechanical Design, 2023, 145(4): 041401. 10.1115/1.4056436
|
| 3 |
刘长红,曾胜,张斌,等.基于语义关系图的跨模态张量融合网络的图像文本检索[J].计算机应用, 2022, 42(10): 3018-3024. 10.11772/j.issn.1001-9081.2021091622
|
|
LIU C H, ZENG S, ZHANG B, et al. Cross-modal tensor fusion network based on semantic relation graph for image-text retrieval [J]. Journal of Computer Applications, 2022, 42(10): 3018-3024. 10.11772/j.issn.1001-9081.2021091622
|
| 4 |
李志欣,凌锋,张灿龙,等.融合两级相似度的跨媒体图像文本检索[J].电子学报, 2021, 49(2): 268-274. 10.12263/DZXB.20191037
|
|
LI Z X, LING F, ZHANG C L, et al. Cross-media image-text retrieval with two level similarity [J]. Acta Electronica Sinica, 2021, 49(2): 268-274. 10.12263/DZXB.20191037
|
| 5 |
FROME A, CORRADO G S, SHLENS J, et al. DeViSE: a deep visual-semantic embedding model [C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2013: 2121-2129.
|
| 6 |
FAGHRI F, FLEET D J, KIROS J R, et al. VSE++: improving visual-semantic embeddings with hard negatives [C]// Proceedings of the 2018 British Machine Vision Conference. Durham: BMVA Press, 2018: No.344.
|
| 7 |
GU J, CAI J, JOTY S R, et al. Look, imagine and match: improving textual-visual cross-modal retrieval with generative models [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7181-7189. 10.1109/cvpr.2018.00750
|
| 8 |
ZHEN L, HU P, WANG X, et al. Deep supervised cross-modal retrieval [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10386-10395. 10.1109/cvpr.2019.01064
|
| 9 |
WEN K, GU X, CHENG Q. Learning dual semantic relations with graph attention for image-text matching [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(7): 2866-2879. 10.1109/tcsvt.2020.3030656
|
| 10 |
CHEN J, HU H, WU H, et al. Learning the best pooling strategy for visual semantic embedding [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15784-15793. 10.1109/cvpr46437.2021.01553
|
| 11 |
KARPATHY A, JOULIN A, LI F-F. Deep fragment embeddings for bidirectional image sentence mapping [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 1889-1897.
|
| 12 |
NIU Z, ZHOU M, WANG L, et al. Hierarchical multimodal LSTM for dense visual-semantic embedding [C]// Proceedings of the 2017 IEEE International Conference on computer Vision. Piscataway: IEEE, 2017: 1899-1907. 10.1109/iccv.2017.208
|
| 13 |
NAM H, J-W HA, KIM J. Dual attention networks for multimodal reasoning and matching [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2156-2164. 10.1109/cvpr.2017.232
|
| 14 |
LEE K-H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 212-228. 10.1007/978-3-030-01225-0_13
|
| 15 |
CHEN H, DING G, LIU X, et al. IMRAM: iterative matching with recurrent attention memory for cross-modal image-text retrieval [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 12652-12660. 10.1109/cvpr42600.2020.01267
|
| 16 |
QU L, LIU M, WU J, et al. Dynamic modality interaction modeling for image-text retrieval [C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 1104-1113. 10.1145/3404835.3462829
|
| 17 |
JI Z, CHEN K, WANG H. Step-wise hierarchical alignment network for image-text matching [EB/OL]. [2021-01-11]. . 10.24963/ijcai.2021/106
|
| 18 |
CHEN R, WANG H, WANG L, et al. Two-stream hierarchical similarity reasoning for image-text matching [EB/OL]. [2022-03-10]. .
|
| 19 |
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. 10.1109/cvpr.2018.00636
|
| 20 |
KRISHNA R, ZHU Y, GROTH O, et al. Visual Genome: connecting language and vision using crowdsourced dense image annotations [J]. International Journal of Computer Vision, 2017, 123(1): 32-73. 10.1007/s11263-016-0981-7
|
| 21 |
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. 10.1109/tpami.2016.2577031
|
| 22 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90
|
| 23 |
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255. 10.1109/cvpr.2009.5206848
|
| 24 |
SCHUSTER M, PALIWAL K K. Bidirectional recurrent neural networks [J]. IEEE Transactions on Signal Processing, 1997, 45(11): 2673-2681. 10.1109/78.650093
|
| 25 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010.
|
| 26 |
PLUMMER B A, WANG L, CERVANTES C M, et al. Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2641-2649. 10.1109/iccv.2015.303
|
| 27 |
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: lessons learned from the 2015 MSCOCO image captioning challenge [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 652-663. 10.1109/tpami.2016.2587640
|
| 28 |
JIANG Z, LIAN Z. Mutil-level local alignment and semantic matching network for image-text retrieval [C]// Proceedings of the 2022 International Conference on Artificial Neural Networks. Cham: Springer, 2022: 212-224. 10.1007/978-3-031-15934-3_18
|
| 29 |
KINGMA D P, BA J. Adam: a method for stochastic optimization [EB/OL]. (2017-01-30) [2021-08-03]. .
|


 ), Hong ZHANG1,2
), Hong ZHANG1,2