


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (9): 2696-2703.DOI: 10.11772/j.issn.1001-9081.2023091253
• Data science and technology • Previous Articles Next Articles
Shunyong LI1, Shiyi LI1,2, Rui XU1, Xingwang ZHAO2( )
)
Received:2023-09-12
Revised:2023-10-31
Accepted:2023-11-02
Online:2023-11-23
Published:2024-09-10
Contact:
Xingwang ZHAO
About author:LI Shunyong, born in 1975, Ph. D., professor. His research interests include statistical machine learning, data mining.Supported by:
李顺勇1, 李师毅1,2, 胥瑞1, 赵兴旺2()
通讯作者:
赵兴旺
作者简介:李顺勇(1975—),男,山西大同人,教授,博士,主要研究方向:统计机器学习、数据挖掘基金资助:CLC Number:
Shunyong LI, Shiyi LI, Rui XU, Xingwang ZHAO. Incomplete multi-view clustering algorithm based on self-attention fusion[J]. Journal of Computer Applications, 2024, 44(9): 2696-2703.
李顺勇, 李师毅, 胥瑞, 赵兴旺. 基于自注意力融合的不完整多视图聚类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2696-2703.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023091253

Fig. 1 Form of incomplete multi-view data

Fig. 2 Flow of IMVCSAF
| 数据集 | 类别数 | 样本数 | 视图 | 维度 |
|---|---|---|---|---|
| Caltech101-20 | 20 | 2 386 | HOG | 1 984 |
| GIST | 512 | |||
| LandUse-21 | 21 | 2 100 | PHOG | 59 |
| LBP | 40 | |||
| Scene-15 | 15 | 4 485 | PHOG | 59 |
| GIST | 20 | |||
| Noisy-MNIST | 10 | 20 000 | 视 | 784 |
| 视 | 784 |
Tab. 1 Experimental datasets
| 数据集 | 类别数 | 样本数 | 视图 | 维度 |
|---|---|---|---|---|
| Caltech101-20 | 20 | 2 386 | HOG | 1 984 |
| GIST | 512 | |||
| LandUse-21 | 21 | 2 100 | PHOG | 59 |
| LBP | 40 | |||
| Scene-15 | 15 | 4 485 | PHOG | 59 |
| GIST | 20 | |||
| Noisy-MNIST | 10 | 20 000 | 视 | 784 |
| 视 | 784 |
| 算法 | Caltech101-20 | LandUse-21 | Scene-15 | Noisy-MNIST | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | |
| AE2Nets | 33.61 | 49.20 | 24.99 | 19.22 | 23.03 | 5.75 | 27.88 | 31.35 | 13.93 | 38.67 | 33.79 | 19.99 |
| PVC | 41.42 | 56.53 | 31.00 | 21.33 | 23.14 | 8.10 | 25.61 | 25.31 | 11.25 | 35.97 | 27.74 | 16.99 |
| DAIMC | 44.63 | 59.53 | 32.70 | 19.30 | 19.45 | 5.80 | 23.60 | 21.88 | 9.44 | 34.44 | 27.15 | 16.42 |
| EERIMVC | 40.66 | 51.38 | 27.91 | 22.14 | 25.18 | 9.10 | 33.10 | 32.11 | 15.91 | 54.97 | 44.91 | 35.94 |
| DCCA | 38.59 | 52.51 | 29.81 | 14.08 | 20.02 | 3.38 | 31.83 | 33.19 | 14.93 | 61.82 | 60.55 | 37.71 |
| CPM-GAN | 41.42 | 55.89 | 33.74 | 19.02 | 21.58 | 6.11 | 27.30 | 27.18 | 11.93 | — | — | — |
| PIC | 57.53 | 64.32 | 45.22 | 23.60 | 26.52 | 9.45 | 38.70 | 37.98 | 21.16 | — | — | — |
| COMPLETER | 68.44 | 67.39 | 75.44 | 22.16 | 27.00 | 10.39 | 39.50 | 42.35 | 23.51 | 80.01 | 75.23 | 70.66 |
| IMVCSAF | 73.93 | 70.16 | 85.16 | 22.19 | 27.92 | 11.24 | 40.04 | 42.15 | 23.94 | 86.59 | 79.00 | 76.57 |
Tab. 2 Experimental comparison on data with 50% miss rate
| 算法 | Caltech101-20 | LandUse-21 | Scene-15 | Noisy-MNIST | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | |
| AE2Nets | 33.61 | 49.20 | 24.99 | 19.22 | 23.03 | 5.75 | 27.88 | 31.35 | 13.93 | 38.67 | 33.79 | 19.99 |
| PVC | 41.42 | 56.53 | 31.00 | 21.33 | 23.14 | 8.10 | 25.61 | 25.31 | 11.25 | 35.97 | 27.74 | 16.99 |
| DAIMC | 44.63 | 59.53 | 32.70 | 19.30 | 19.45 | 5.80 | 23.60 | 21.88 | 9.44 | 34.44 | 27.15 | 16.42 |
| EERIMVC | 40.66 | 51.38 | 27.91 | 22.14 | 25.18 | 9.10 | 33.10 | 32.11 | 15.91 | 54.97 | 44.91 | 35.94 |
| DCCA | 38.59 | 52.51 | 29.81 | 14.08 | 20.02 | 3.38 | 31.83 | 33.19 | 14.93 | 61.82 | 60.55 | 37.71 |
| CPM-GAN | 41.42 | 55.89 | 33.74 | 19.02 | 21.58 | 6.11 | 27.30 | 27.18 | 11.93 | — | — | — |
| PIC | 57.53 | 64.32 | 45.22 | 23.60 | 26.52 | 9.45 | 38.70 | 37.98 | 21.16 | — | — | — |
| COMPLETER | 68.44 | 67.39 | 75.44 | 22.16 | 27.00 | 10.39 | 39.50 | 42.35 | 23.51 | 80.01 | 75.23 | 70.66 |
| IMVCSAF | 73.93 | 70.16 | 85.16 | 22.19 | 27.92 | 11.24 | 40.04 | 42.15 | 23.94 | 86.59 | 79.00 | 76.57 |
| 算法 | Caltech101-20 | LandUse-21 | Scene-15 | Noisy-MNIST | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | |
| AE2Nets | 49.10 | 65.38 | 35.66 | 24.79 | 30.36 | 10.35 | 36.10 | 40.39 | 22.08 | 56.98 | 46.83 | 36.98 |
| PVC | 44.91 | 62.13 | 35.77 | 25.22 | 30.45 | 11.72 | 30.83 | 31.05 | 14.98 | 41.94 | 33.90 | 22.93 |
| DAIMC | 45.48 | 61.79 | 32.40 | 24.35 | 29.35 | 10.26 | 32.09 | 33.55 | 17.42 | 39.18 | 35.69 | 23.65 |
| EERIMVC | 43.28 | 55.04 | 30.42 | 24.92 | 29.57 | 12.24 | 39.60 | 38.99 | 22.06 | 65.47 | 57.69 | 49.54 |
| DCCA | 41.89 | 59.14 | 33.39 | 15.51 | 23.15 | 4.43 | 36.18 | 38.92 | 20.87 | 85.53 | 89.44 | 81.87 |
| CPM-GAN | 43.18 | 62.00 | 34.57 | 22.34 | 29.18 | 9.49 | 30.87 | 31.54 | 15.27 | — | — | — |
| PIC | 62.27 | 67.93 | 51.56 | 24.86 | 29.74 | 10.48 | 38.72 | 40.46 | 22.12 | — | — | — |
| COMPLETER | 70.18 | 68.06 | 77.88 | 25.63 | 31.73 | 13.05 | 41.07 | 44.68 | 24.78 | 89.08 | 88.86 | 85.47 |
| IMVCSAF | 77.07 | 72.80 | 89.55 | 26.82 | 33.64 | 14.05 | 41.26 | 45.36 | 25.86 | 92.42 | 87.40 | 84.06 |
Tab. 3 Experimental comparison on complete data
| 算法 | Caltech101-20 | LandUse-21 | Scene-15 | Noisy-MNIST | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | |
| AE2Nets | 49.10 | 65.38 | 35.66 | 24.79 | 30.36 | 10.35 | 36.10 | 40.39 | 22.08 | 56.98 | 46.83 | 36.98 |
| PVC | 44.91 | 62.13 | 35.77 | 25.22 | 30.45 | 11.72 | 30.83 | 31.05 | 14.98 | 41.94 | 33.90 | 22.93 |
| DAIMC | 45.48 | 61.79 | 32.40 | 24.35 | 29.35 | 10.26 | 32.09 | 33.55 | 17.42 | 39.18 | 35.69 | 23.65 |
| EERIMVC | 43.28 | 55.04 | 30.42 | 24.92 | 29.57 | 12.24 | 39.60 | 38.99 | 22.06 | 65.47 | 57.69 | 49.54 |
| DCCA | 41.89 | 59.14 | 33.39 | 15.51 | 23.15 | 4.43 | 36.18 | 38.92 | 20.87 | 85.53 | 89.44 | 81.87 |
| CPM-GAN | 43.18 | 62.00 | 34.57 | 22.34 | 29.18 | 9.49 | 30.87 | 31.54 | 15.27 | — | — | — |
| PIC | 62.27 | 67.93 | 51.56 | 24.86 | 29.74 | 10.48 | 38.72 | 40.46 | 22.12 | — | — | — |
| COMPLETER | 70.18 | 68.06 | 77.88 | 25.63 | 31.73 | 13.05 | 41.07 | 44.68 | 24.78 | 89.08 | 88.86 | 85.47 |
| IMVCSAF | 77.07 | 72.80 | 89.55 | 26.82 | 33.64 | 14.05 | 41.26 | 45.36 | 25.86 | 92.42 | 87.40 | 84.06 |

Fig. 3 Performance comparison under different miss rates on Caltech101-20 dataset

Fig. 4 Performance comparison under different miss rates on Noisy-MNIST dataset

Fig. 5 Model loss term parameter analysis on Caltech101-20 dataset

Fig. 6 Sensitivity analysis of information entropy balance parameter α
| ACC | NMI | ARI | |||
|---|---|---|---|---|---|
| √ | 58.62 | 63.21 | 58.73 | ||
| √ | 32.07 | 36.69 | 19.30 | ||
| √ | 43.11 | 32.66 | 31.59 | ||
| √ | √ | 52.65 | 57.94 | 45.80 | |
| √ | √ | 60.48 | 63.15 | 62.42 | |
| √ | √ | 66.55 | 68.67 | 70.87 | |
| √ | √ | √ | 73.93 | 70.16 | 85.16 |
Tab. 4 Ablation experimental results
| ACC | NMI | ARI | |||
|---|---|---|---|---|---|
| √ | 58.62 | 63.21 | 58.73 | ||
| √ | 32.07 | 36.69 | 19.30 | ||
| √ | 43.11 | 32.66 | 31.59 | ||
| √ | √ | 52.65 | 57.94 | 45.80 | |
| √ | √ | 60.48 | 63.15 | 62.42 | |
| √ | √ | 66.55 | 68.67 | 70.87 | |
| √ | √ | √ | 73.93 | 70.16 | 85.16 |

Fig. 7 Data distribution of Noisy MNIST dataset
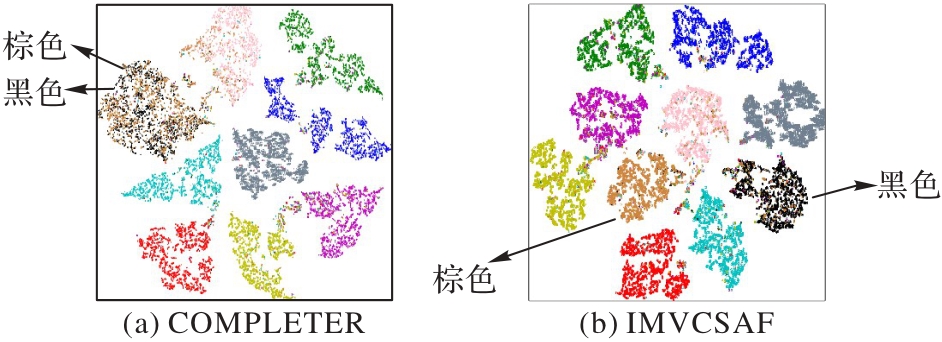
Fig. 8 Clustering visualization results
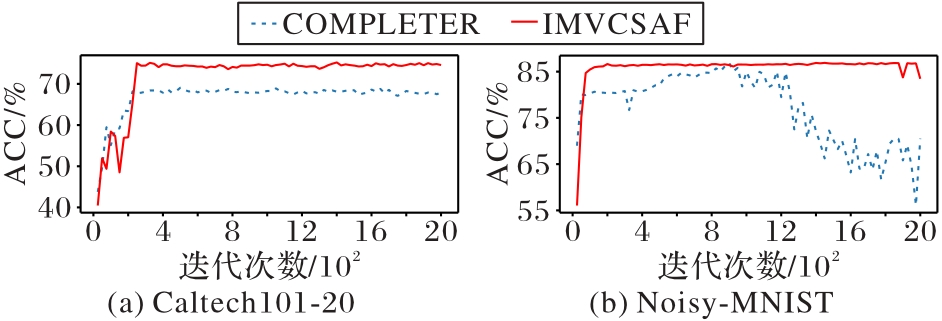
Fig. 9 Convergence curves on different datasets
| 1 | CHAO G, SUN S, BI J. A survey on multiview clustering [J]. IEEE Transactions on Artificial Intelligence, 2021, 2(2): 146-168. |
| 2 | YAN M, LI Y, HU P, et al. Robust multi-view clustering with incomplete information [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 1055-1069. |
| 3 | 劳景欢,黄栋,王昌栋,等. 基于视图互信息加权的多视图集成聚类算法[J]. 计算机应用, 2023, 43(6): 1713-1718. |
| LAO J H, HUANG D, WANG C D, et al. Multi-view ensemble clustering algorithm based on view-wise mutual information weighting [J]. Journal of Computer Applications, 2023, 43(6): 1713-1718. | |
| 4 | XU J, TANG H, REN Y, et al. Multi-level feature learning for contrastive multi-view clustering [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 16030-16039. |
| 5 | PAN E, ZHAO K. Multi-view contrastive graph clustering [C]// Proceedings of the 35th Conference on Neural Information Processing Systems.Red Hook: Curran Associates Inc., 2021: 2148-2159. |
| 6 | 何子仪,杨燕,张熠玲. 深度融合多视图聚类网络[J]. 计算机应用, 2023, 43(9): 2651-2656. |
| HE Z Y, YANG Y, ZHANG Y L. Multi-view clustering network with deep fusion [J]. Journal of Computer Applications, 2023, 43(9): 2651-2656. | |
| 7 | XU J, REN Y, LI G, et al. Deep embedded multi-view clustering with collaborative training [J]. Information Sciences, 2021, 573: 279-290. |
| 8 | ZHANG C, CUI Y, HAN Z, et al. Deep partial multi-view learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(5): 2402-2415. |
| 9 | LU R K, LIU J W, ZUO X. Attentive multi-view deep subspace clustering net [J]. Neurocomputing, 2021, 435: 186-196. |
| 10 | LI S Y, JIANG Y, ZHOU Z H. Partial multi-view clustering [C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2014: 1968-1974. |
| 11 | ZHAO H, LIU H, FU Y. Incomplete multi-modal visual data grouping [C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2016: 2392-2398. |
| 12 | WEN J, ZHANG Z, ZHANG Z, et al. Unified tensor framework for incomplete multi-view clustering and missing-view inferring[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 10273-10281. |
| 13 | XIA W, GAO Q, WANG Q, et al. Tensorized bipartite graph learning for multi-view clustering [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(4): 5187-5202. |
| 14 | LIU Z, CHEN Z, LI Y, et al. IMC-NLT: incomplete multi-view clustering by NMF and low-rank tensor [J]. Expert Systems with Applications, 2023, 221: No.119742. |
| 15 | XU C, GUAN Z, ZHAO W, et al. Adversarial incomplete multi-view clustering [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2019: 3933-3939. |
| 16 | WANG Q, DING Z, TAO Z, et al. Partial multi-view clustering via consistent GAN [C]// Proceedings of the 2018 IEEE International Conference on Data Mining. Piscataway: IEEE, 2018: 1290-1295. |
| 17 | WEN J, ZHANG Z, XU Y, et al. CDIMC-Net: cognitive deep incomplete multi-view clustering network [C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2020: 3230-3236. |
| 18 | LIN Y, GOU Y, LIU Z, et al. COMPLETER: incomplete multi-view clustering via contrastive prediction [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11169-11178. |
| 19 | CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607. |
| 20 | HE K, FAN H, WU Y, et al. Momentum contrast for unsupervised visual representation learning [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9726-9735. |
| 21 | VAN DEN OORD A, LI Y, VINYALS O. Representation learning with contrastive predictive coding [EB/OL]. (2019-01-22) [2023-04-13]. . |
| 22 | MacQEEN J. Some methods for classification and analysis of multivariate observations [C]// Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics. Oakland, CA: Regents of the University of California, 1967: 281-297. |
| 23 | MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 2204-2212. |
| 24 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 25 | LI F F, PERONA P. A Bayesian hierarchical model for learning natural scene categories [C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition — Volume 2. Piscataway: IEEE, 2005: 524-531. |
| 26 | YANG Y, NEWSAM S. Bag-of-visual-words and spatial extensions for land-use classification [C]// Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. New York: ACM, 2010: 270-279. |
| 27 | LI Y, NIE F, HUANG H, et al. Large-scale multi-view spectral clustering via bipartite graph [C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2015: 2750-2756. |
| 28 | WANG W, ARORA R, LIVESCU K, et al. On deep multi-view representation learning [C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 1083-1092. |
| 29 | ZHANG C, LIU Y, FU H. AE2-Nets: autoencoder in autoencoder networks [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 2572-2580. |
| 30 | ANDREW G, ARORA R, BILMES J, et al. Deep canonical correlation analysis [C]// Proceedings of the 30th International Conference on Machine Learning. New York: JMLR.org, 2013: 1247-1255. |
| 31 | HU M, CHEN S. Doubly aligned incomplete multi-view clustering[C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2018: 2262-2268. |
| 32 | WANG H, ZONG L, LIU B, et al. Spectral perturbation meets incomplete multi-view data [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2019: 3677-3683. |
| 33 | LIU X, LI M, TANG C, et al. Efficient and effective regularized incomplete multi-view clustering [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(8): 2634-2646. |
| 34 | TIAN Y, SUN C, POOLE B, et al. What makes for good views for contrastive learning [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 6827-6839. |
| 35 | VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9:2579-2605. |
| [1] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [2] | Yu DU, Yan ZHU. Constructing pre-trained dynamic graph neural network to predict disappearance of academic cooperation behavior [J]. Journal of Computer Applications, 2024, 44(9): 2726-2731. |
| [3] | Yunchuan HUANG, Yongquan JIANG, Juntao HUANG, Yan YANG. Molecular toxicity prediction based on meta graph isomorphism network [J]. Journal of Computer Applications, 2024, 44(9): 2964-2969. |
| [4] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [5] | Xiyuan WANG, Zhancheng ZHANG, Shaokang XU, Baocheng ZHANG, Xiaoqing LUO, Fuyuan HU. Unsupervised cross-domain transfer network for 3D/2D registration in surgical navigation [J]. Journal of Computer Applications, 2024, 44(9): 2911-2918. |
| [6] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [7] | Tingjie TANG, Jiajin HUANG, Jin QIN, Hui LU. Session-based recommendation based on graph co-occurrence enhanced multi-layer perceptron [J]. Journal of Computer Applications, 2024, 44(8): 2357-2364. |
| [8] | Yuhan LIU, Genlin JI, Hongping ZHANG. Video pedestrian anomaly detection method based on skeleton graph and mixed attention [J]. Journal of Computer Applications, 2024, 44(8): 2551-2557. |
| [9] | Yanjie GU, Yingjun ZHANG, Xiaoqian LIU, Wei ZHOU, Wei SUN. Traffic flow forecasting via spatial-temporal multi-graph fusion [J]. Journal of Computer Applications, 2024, 44(8): 2618-2625. |
| [10] | Fan YANG, Yao ZOU, Mingzhi ZHU, Zhenwei MA, Dawei CHENG, Changjun JIANG. Credit card fraud detection model based on graph attention Transformation neural network [J]. Journal of Computer Applications, 2024, 44(8): 2634-2642. |
| [11] | Qianhong SHI, Yan YANG, Yongquan JIANG, Xiaocao OUYANG, Wubo FAN, Qiang CHEN, Tao JIANG, Yuan LI. Multi-granularity abrupt change fitting network for air quality prediction [J]. Journal of Computer Applications, 2024, 44(8): 2643-2650. |
| [12] | Zheng WU, Zhiyou CHENG, Zhentian WANG, Chuanjian WANG, Sheng WANG, Hui XU. Deep learning-based classification of head movement amplitude during patient anaesthesia resuscitation [J]. Journal of Computer Applications, 2024, 44(7): 2258-2263. |
| [13] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [14] | Zhi ZHANG, Xin LI, Naifu YE, Kaixi HU. DKP: defending against model stealing attacks based on dark knowledge protection [J]. Journal of Computer Applications, 2024, 44(7): 2080-2086. |
| [15] | Yiqun ZHAO, Zhiyu ZHANG, Xue DONG. Anisotropic travel time computation method based on dense residual connection physical information neural networks [J]. Journal of Computer Applications, 2024, 44(7): 2310-2318. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||