


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (11): 3521-3529.DOI: 10.11772/j.issn.1001-9081.2023101524
• Advanced computing • Previous Articles Next Articles
Jinxing TU1, Zhixiong LI1, Jianqiang HUANG1,2( )
)
Received:2023-11-01
Revised:2024-02-03
Accepted:2024-02-05
Online:2023-11-04
Published:2024-11-10
Contact:
Jianqiang HUANG
About author:TU Jinxing, born in 2000, M. S. candidate. His research interests include high performance computing, program performance optimization.Supported by:
涂进兴1, 李志雄1, 黄建强1,2()
通讯作者:
黄建强
作者简介:涂进兴(2000—),男,江西丰城人,硕士研究生,CCF会员,主要研究方向:高性能计算、程序性能优化基金资助:CLC Number:
Jinxing TU, Zhixiong LI, Jianqiang HUANG. Dynamic partition algorithm for diagonal sparse matrix vector multiplication based on GPU[J]. Journal of Computer Applications, 2024, 44(11): 3521-3529.
涂进兴, 李志雄, 黄建强. 基于GPU对角稀疏矩阵向量乘法的动态划分算法[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3521-3529.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023101524

Fig. 1 Example of common format CSR for sparse matrix

Fig. 2 Common format DIA for diagonal sparse matrix
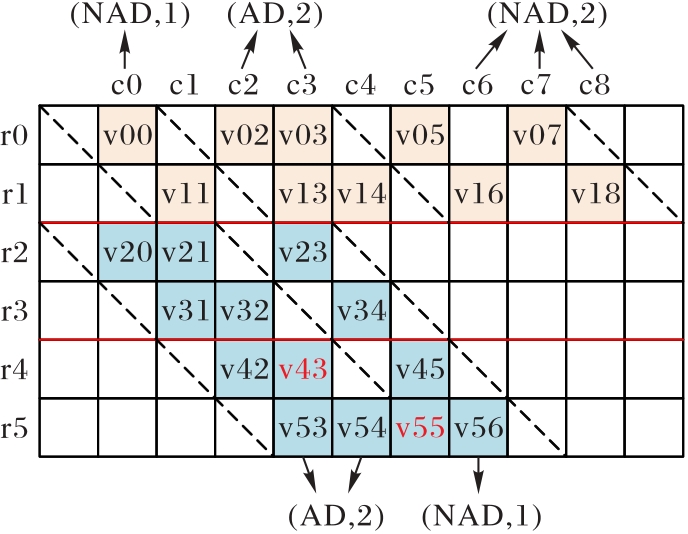
Fig. 3 Diagonal sparse matrix format CRSD

Fig. 4 Diagonal sparse matrix format BRCSD-Ⅱ

Fig. 5 DIA-Dynamic algorithm framework

Fig. 6 Flow of dynamic partition

Fig. 7 Diagonal sparse matrix format BDIA

Fig. 8 Flow of bottom acceleration optimization
| 矩阵 | 维度 | 对角线数 | 非零元数 |
|---|---|---|---|
| wang3 | 26 064 | 21 | 177 168 |
| wang4 | 26 068 | 23 | 177 196 |
| nemeth21 | 9 506 | 169 | 1 173 746 |
| nemeth22 | 9 506 | 197 | 1 358 832 |
| af_1_k101 | 503 625 | 897 | 17 550 675 |
| af_2_k101 | 503 625 | 897 | 17 550 675 |
| s3dkq4m2 | 90 449 | 661 | 4 820 891 |
| s3dkt3m2 | 90 449 | 655 | 3 753 461 |
| crystk02 | 13 965 | 99 | 968 583 |
| crystk03 | 24 696 | 99 | 1 751 178 |
| apache1 | 80 800 | 7 | 542 184 |
| apache2 | 715 176 | 11 | 4 817 870 |
| bbmat | 38 744 | 514 | 1 771 722 |
| majorbasis | 160 000 | 22 | 1 750 416 |
| mhd4800a | 4 800 | 58 | 102 252 |
| crashbasis | 160 000 | 22 | 1 750 416 |
| shyy161 | 76 480 | 7 | 329 762 |
| shyy41 | 4 720 | 7 | 20 042 |
| sherman3 | 5 005 | 7 | 20 033 |
| cryg10000 | 10 000 | 8 | 49 699 |
| dw8192 | 8 192 | 11 | 41 746 |
Tab. 1 Statistics of dataset
| 矩阵 | 维度 | 对角线数 | 非零元数 |
|---|---|---|---|
| wang3 | 26 064 | 21 | 177 168 |
| wang4 | 26 068 | 23 | 177 196 |
| nemeth21 | 9 506 | 169 | 1 173 746 |
| nemeth22 | 9 506 | 197 | 1 358 832 |
| af_1_k101 | 503 625 | 897 | 17 550 675 |
| af_2_k101 | 503 625 | 897 | 17 550 675 |
| s3dkq4m2 | 90 449 | 661 | 4 820 891 |
| s3dkt3m2 | 90 449 | 655 | 3 753 461 |
| crystk02 | 13 965 | 99 | 968 583 |
| crystk03 | 24 696 | 99 | 1 751 178 |
| apache1 | 80 800 | 7 | 542 184 |
| apache2 | 715 176 | 11 | 4 817 870 |
| bbmat | 38 744 | 514 | 1 771 722 |
| majorbasis | 160 000 | 22 | 1 750 416 |
| mhd4800a | 4 800 | 58 | 102 252 |
| crashbasis | 160 000 | 22 | 1 750 416 |
| shyy161 | 76 480 | 7 | 329 762 |
| shyy41 | 4 720 | 7 | 20 042 |
| sherman3 | 5 005 | 7 | 20 033 |
| cryg10000 | 10 000 | 8 | 49 699 |
| dw8192 | 8 192 | 11 | 41 746 |

Fig. 9 Performance comparison of DIA and BRCSD-Ⅱ
| 矩阵 | BRCSD-Ⅱ(nrows) | DIA-Dynamic(maxdiff) | DIA | Light SpMV | Merge SpMV | Tile SpMV | BRCSD-Ⅱ |
|---|---|---|---|---|---|---|---|
| wang3 | 512 | 1 | 3.56 | 2.36 | 1.90 | 2.64 | 1.40 |
| wang4 | 512 | 1 | 4.13 | 2.16 | 1.86 | 2.91 | 1.39 |
| nemeth21 | 512 | 60 | 1.92 | 1.53 | 2.13 | 0.97 | 1.74 |
| nemeth22 | 512 | 60 | 1.58 | 1.32 | 1.75 | 0.92 | 1.34 |
| af_1_k101 | 512 | 0 | 26.37 | 1.16 | 1.86 | 1.09 | 1.95 |
| af_2_k101 | 512 | 0 | 26.13 | 1.16 | 1.88 | 1.07 | 1.95 |
| s3dkq4m2 | 512 | 5 | 12.41 | 1.23 | 1.80 | 0.91 | 1.82 |
| s3dkt3m2 | 512 | 10 | 13.49 | 1.15 | 1.66 | 0.85 | 1.84 |
| crystk02 | 512 | 5 | 2.62 | 1.87 | 2.37 | 1.51 | 1.84 |
| crystk03 | 512 | 0 | 2.41 | 2.09 | 2.43 | 1.56 | 1.74 |
| apache1 | 512 | 0 | 1.52 | 2.23 | 2.76 | 2.39 | 1.77 |
| apache2 | 512 | 0 | 2.62 | 2.21 | 2.04 | 2.42 | 2.01 |
| bbmat | 512 | 10 | 4.24 | 0.72 | 1.04 | 0.75 | 2.87 |
| majorbasis | 512 | 0 | 3.05 | 2.36 | 2.54 | 2.41 | 1.88 |
| mhd4800a | 512 | 0 | 1.36 | 1.10 | 1.21 | 1.37 | 1.35 |
| crashbasis | 512 | 0 | 3.14 | 2.35 | 2.59 | 2.41 | 1.87 |
| shyy161 | 512 | 0 | 2.24 | 2.05 | 2.69 | 2.10 | 1.86 |
| shyy41 | 512 | 0 | 1.21 | 2.04 | 2.59 | 2.99 | 1.23 |
| sherman3 | 256 | 0 | 1.08 | 2.42 | 3.10 | 3.33 | 1.28 |
| cryg10000 | 256 | 0 | 1.02 | 2.46 | 2.32 | 2.56 | 1.21 |
| dw8192 | 512 | 0 | 1.18 | 2.33 | 2.13 | 2.50 | 1.54 |
Tab. 2 Parameter information and acceleration ratios of DIA-Dynamic compared to other algorithms
| 矩阵 | BRCSD-Ⅱ(nrows) | DIA-Dynamic(maxdiff) | DIA | Light SpMV | Merge SpMV | Tile SpMV | BRCSD-Ⅱ |
|---|---|---|---|---|---|---|---|
| wang3 | 512 | 1 | 3.56 | 2.36 | 1.90 | 2.64 | 1.40 |
| wang4 | 512 | 1 | 4.13 | 2.16 | 1.86 | 2.91 | 1.39 |
| nemeth21 | 512 | 60 | 1.92 | 1.53 | 2.13 | 0.97 | 1.74 |
| nemeth22 | 512 | 60 | 1.58 | 1.32 | 1.75 | 0.92 | 1.34 |
| af_1_k101 | 512 | 0 | 26.37 | 1.16 | 1.86 | 1.09 | 1.95 |
| af_2_k101 | 512 | 0 | 26.13 | 1.16 | 1.88 | 1.07 | 1.95 |
| s3dkq4m2 | 512 | 5 | 12.41 | 1.23 | 1.80 | 0.91 | 1.82 |
| s3dkt3m2 | 512 | 10 | 13.49 | 1.15 | 1.66 | 0.85 | 1.84 |
| crystk02 | 512 | 5 | 2.62 | 1.87 | 2.37 | 1.51 | 1.84 |
| crystk03 | 512 | 0 | 2.41 | 2.09 | 2.43 | 1.56 | 1.74 |
| apache1 | 512 | 0 | 1.52 | 2.23 | 2.76 | 2.39 | 1.77 |
| apache2 | 512 | 0 | 2.62 | 2.21 | 2.04 | 2.42 | 2.01 |
| bbmat | 512 | 10 | 4.24 | 0.72 | 1.04 | 0.75 | 2.87 |
| majorbasis | 512 | 0 | 3.05 | 2.36 | 2.54 | 2.41 | 1.88 |
| mhd4800a | 512 | 0 | 1.36 | 1.10 | 1.21 | 1.37 | 1.35 |
| crashbasis | 512 | 0 | 3.14 | 2.35 | 2.59 | 2.41 | 1.87 |
| shyy161 | 512 | 0 | 2.24 | 2.05 | 2.69 | 2.10 | 1.86 |
| shyy41 | 512 | 0 | 1.21 | 2.04 | 2.59 | 2.99 | 1.23 |
| sherman3 | 256 | 0 | 1.08 | 2.42 | 3.10 | 3.33 | 1.28 |
| cryg10000 | 256 | 0 | 1.02 | 2.46 | 2.32 | 2.56 | 1.21 |
| dw8192 | 512 | 0 | 1.18 | 2.33 | 2.13 | 2.50 | 1.54 |

Fig. 10 Performance comparison of DIA-dynamic, DIA, Light SpMV, Merge SpMV, Tile SpMV, and BRCSD-Ⅱ
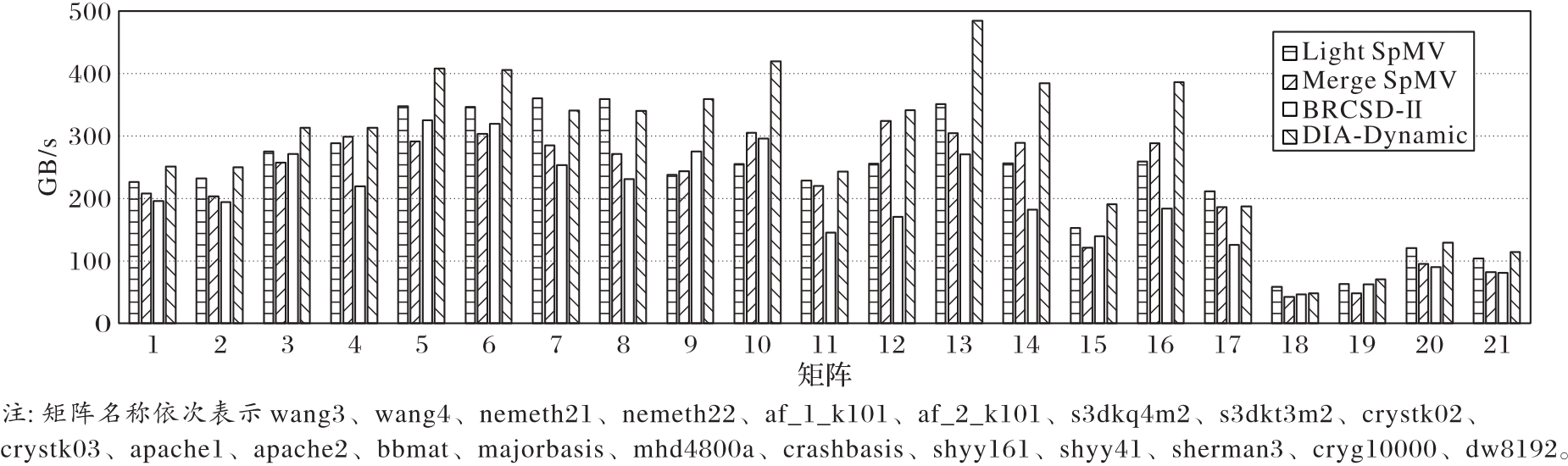
Fig. 11 Throughput comparison of DIA-Dynamic,Light SpMV,Merge SpMV,and BRCSD-Ⅱ
| 矩阵 | 非零元数 | 零元填充数 | ||
|---|---|---|---|---|
| DIA | BRCSD-Ⅱ | DIA-Dynamic | ||
| wang3 | 1.77×105 | 3.70×105 | 1.18×104 | 4.26×103 |
| wang4 | 1.77×105 | 4.22×105 | 1.38×104 | 4.06×103 |
| nemeth21 | 1.17×106 | 4.33×105 | 4.16×105 | 3.75×105 |
| nemeth22 | 1.36×106 | 5.14×105 | 4.66×105 | 4.17×105 |
| af_1_k101 | 1.76×107 | 4.34×108 | 1.16×107 | 1.13×107 |
| af_2_k101 | 1.76×107 | 4.34×108 | 1.16×107 | 1.13×107 |
| s3dkq4m2 | 4.82×106 | 5.50×107 | 2.02×106 | 1.80×106 |
| s3dkt3m2 | 3.75×106 | 5.55×107 | 2.01×106 | 1.82×106 |
| crystk02 | 9.69×105 | 4.14×105 | 4.00×105 | 3.23×105 |
| crystk03 | 1.75×106 | 6.94×105 | 6.79×105 | 5.12×105 |
| apache1 | 5.42×105 | 2.34×104 | 2.31×104 | 8.20×103 |
| apache2 | 4.82×106 | 3.05×106 | 1.87×105 | 2.47×104 |
| bbmat | 1.77×106 | 1.81×107 | 6.90×106 | 2.29×106 |
| majorbasis | 1.75×106 | 1.77×106 | 1.65×104 | 5.38×103 |
| mhd4800a | 1.02×105 | 1.76×105 | 1.95×105 | 1.76×105 |
| crashbasis | 1.75×106 | 1.77×106 | 1.65×104 | 5.38×103 |
| shyy161 | 3.30×105 | 2.06×105 | 4.06×103 | 8.30×102 |
| shyy41 | 2.00×104 | 1.30×104 | 3.51×103 | 3.49×102 |
| sherman3 | 2.00×104 | 1.50×104 | 1.53×104 | 1.31×104 |
| cryg10000 | 4.97×104 | 3.03×104 | 2.27×103 | 2.99×102 |
| dw8192 | 4.17×104 | 4.84×104 | 1.56×104 | 5.85×103 |
Tab. 3 Zero-element filling number of DIA-dynamic, DIA,BRCSD-Ⅱ
| 矩阵 | 非零元数 | 零元填充数 | ||
|---|---|---|---|---|
| DIA | BRCSD-Ⅱ | DIA-Dynamic | ||
| wang3 | 1.77×105 | 3.70×105 | 1.18×104 | 4.26×103 |
| wang4 | 1.77×105 | 4.22×105 | 1.38×104 | 4.06×103 |
| nemeth21 | 1.17×106 | 4.33×105 | 4.16×105 | 3.75×105 |
| nemeth22 | 1.36×106 | 5.14×105 | 4.66×105 | 4.17×105 |
| af_1_k101 | 1.76×107 | 4.34×108 | 1.16×107 | 1.13×107 |
| af_2_k101 | 1.76×107 | 4.34×108 | 1.16×107 | 1.13×107 |
| s3dkq4m2 | 4.82×106 | 5.50×107 | 2.02×106 | 1.80×106 |
| s3dkt3m2 | 3.75×106 | 5.55×107 | 2.01×106 | 1.82×106 |
| crystk02 | 9.69×105 | 4.14×105 | 4.00×105 | 3.23×105 |
| crystk03 | 1.75×106 | 6.94×105 | 6.79×105 | 5.12×105 |
| apache1 | 5.42×105 | 2.34×104 | 2.31×104 | 8.20×103 |
| apache2 | 4.82×106 | 3.05×106 | 1.87×105 | 2.47×104 |
| bbmat | 1.77×106 | 1.81×107 | 6.90×106 | 2.29×106 |
| majorbasis | 1.75×106 | 1.77×106 | 1.65×104 | 5.38×103 |
| mhd4800a | 1.02×105 | 1.76×105 | 1.95×105 | 1.76×105 |
| crashbasis | 1.75×106 | 1.77×106 | 1.65×104 | 5.38×103 |
| shyy161 | 3.30×105 | 2.06×105 | 4.06×103 | 8.30×102 |
| shyy41 | 2.00×104 | 1.30×104 | 3.51×103 | 3.49×102 |
| sherman3 | 2.00×104 | 1.50×104 | 1.53×104 | 1.31×104 |
| cryg10000 | 4.97×104 | 3.03×104 | 2.27×103 | 2.99×102 |
| dw8192 | 4.17×104 | 4.84×104 | 1.56×104 | 5.85×103 |
| 矩阵 | DIA | BRCSD-Ⅱ | DIA-Dynamic |
|---|---|---|---|
| wang3 | 472.78 | 309.63 | 233.59 |
| wang4 | 515.06 | 310.56 | 233.73 |
| nemeth21 | 3 241.30 | 2 726.20 | 1 891.70 |
| nemeth22 | 3 769.20 | 3 103.80 | 2 149.50 |
| af_1_k101 | 18 216.00 | 1 143.50 | 807.08 |
| af_2_k101 | 18 216.00 | 1 143.50 | 807.08 |
| s3dkq4m2 | 13 344.00 | 1 441.00 | 979.27 |
| s3dkt3m2 | 13 227.00 | 1 243.00 | 849.67 |
| crystk02 | 20 142.00 | 1 779.40 | 1 239.20 |
| crystk03 | 1 993.10 | 1 778.20 | 1 213.70 |
| apache1 | 202.65 | 308.40 | 234.63 |
| apache2 | 281.43 | 392.31 | 210.79 |
| bbmat | 10 402.00 | 4 449.40 | 1 815.30 |
| majorbasis | 495.13 | 412.11 | 264.23 |
| mhd4800a | 1 164.90 | 1 072.10 | 777.35 |
| crashbasis | 495.13 | 412.11 | 264.23 |
| shyy161 | 202.15 | 264.09 | 176.00 |
| shyy41 | 188.29 | 240.45 | 164.26 |
| sherman3 | 198.52 | 301.47 | 220.54 |
| cryg10000 | 207.56 | 257.34 | 164.96 |
| dw8192 | 263.55 | 357.50 | 192.50 |
Tab. 4 Average number of commands executed by warp
| 矩阵 | DIA | BRCSD-Ⅱ | DIA-Dynamic |
|---|---|---|---|
| wang3 | 472.78 | 309.63 | 233.59 |
| wang4 | 515.06 | 310.56 | 233.73 |
| nemeth21 | 3 241.30 | 2 726.20 | 1 891.70 |
| nemeth22 | 3 769.20 | 3 103.80 | 2 149.50 |
| af_1_k101 | 18 216.00 | 1 143.50 | 807.08 |
| af_2_k101 | 18 216.00 | 1 143.50 | 807.08 |
| s3dkq4m2 | 13 344.00 | 1 441.00 | 979.27 |
| s3dkt3m2 | 13 227.00 | 1 243.00 | 849.67 |
| crystk02 | 20 142.00 | 1 779.40 | 1 239.20 |
| crystk03 | 1 993.10 | 1 778.20 | 1 213.70 |
| apache1 | 202.65 | 308.40 | 234.63 |
| apache2 | 281.43 | 392.31 | 210.79 |
| bbmat | 10 402.00 | 4 449.40 | 1 815.30 |
| majorbasis | 495.13 | 412.11 | 264.23 |
| mhd4800a | 1 164.90 | 1 072.10 | 777.35 |
| crashbasis | 495.13 | 412.11 | 264.23 |
| shyy161 | 202.15 | 264.09 | 176.00 |
| shyy41 | 188.29 | 240.45 | 164.26 |
| sherman3 | 198.52 | 301.47 | 220.54 |
| cryg10000 | 207.56 | 257.34 | 164.96 |
| dw8192 | 263.55 | 357.50 | 192.50 |
| 1 | 王宇华,张宇琪,何俊飞,等.TEB:GPU上矩阵分解重构的高效SpMV存储格式[J]. 计算机科学与探索, 2024, 18(4):1094-1108. |
| WANG Y H, ZHANG Y Q, HE J F, et al. TEB: efficient SpMV storage format for matrix decomposition and reconstruction on GPU[J]. Journal of Frontiers of Computer Science and Technology, 2024, 18(4):1094-1108. | |
| 2 | FENG S, SUN J, PAL S, et al. CoSPARSE: a software and hardware reconfigurable SpMV framework for graph analytics[C]// Proceedings of the 58th ACM/IEEE Design Automation Conference. Piscataway: IEEE, 2021: 949-954. |
| 3 | AUGUSTINE T, SARMA J, POUCHET L N, et al. Generating piecewise-regular code from irregular structures[C]// Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation. New York: ACM, 2019: 625-639. |
| 4 | CHESHMI K, STROUT M M, DEHNAVI M M. Optimizing sparse computations jointly[C]// Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. New York: ACM, 2022: 459-460. |
| 5 | LI C, TANG M, TONG R, et al. P-Cloth: interactive complex cloth simulation on multi-GPU systems using dynamic matrix assembly and pipelined implicit integrators[J]. ACM Transactions on Graphics, 2020, 39(6): No.180. |
| 6 | AHRENS P, XU H, SCHIEFER N. A fill estimation algorithm for sparse matrices and tensors in blocked formats[C]// Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium. Piscataway: IEEE, 2018: 546-556. |
| 7 | SUN X, ZHANG Y, WANG T, et al. Optimizing SpMV for diagonal sparse matrices on GPU[C]// Proceedings of the 2011 International Conference on Parallel Processing. Piscataway: IEEE, 2011: 492-501. |
| 8 | BOYS B, DODWELL T J, HOBBS M, et al. PeriPy — a high performance OpenCL peridynamics package[J]. Computer Methods in Applied Mechanics and Engineering, 2021, 386: No.114085. |
| 9 | GAO J, XIA Y, YIN R, et al. Adaptive diagonal sparse matrix-vector multiplication on GPU[J]. Journal of Parallel and Distributed Computing, 2021, 157: 287-302. |
| 10 | NIU Y, LU Z, DONG M, et al. TileSpMV: a tiled algorithm for sparse matrix-vector multiplication on GPUs[C]// Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium. Piscataway: IEEE, 2021: 68-78. |
| 11 | MERRILL D, GARLAND M. Merge-based sparse matrix-vector multiplication (SpMV) using the CSR storage format[J]. ACM SIGPLAN Notices, 2016, 51(8): No.43. |
| 12 | LIU Y, SCHMIDT B. LightSpMV: faster CSR-based sparse matrix-vector multiplication on CUDA-enabled GPUs[C]// Proceedings of the IEEE 26th International Conference on Application-specific Systems, Architectures and Processors. Piscataway: IEEE, 2015: 82-89. |
| 13 | VIRTANEN P, GOMMERS R, OLIPHANT T E, et al. SciPy 1.0: fundamental algorithms for scientific computing in Python[J]. Nature Methods, 2020, 17(3): 261-272. |
| 14 | LI C, XIA T, ZHAO W, et al. SpV8: pursuing optimal vectorization and regular computation pattern in SpMV[C]// Proceedings of the 58th ACM/IEEE Design Automation Conference. Piscataway: IEEE, 2021: 661-666. |
| 15 | GÓMEZ C, MANTOVANI F, FOCHT E, et al. Efficiently running SpMV on long vector architectures[C]// Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. New York: ACM, 2021: 292-303. |
| 16 | ZHANG Y, YANG W, LI K, et al. Performance analysis and optimization for SpMV based on aligned storage formats on an ARM processor[J]. Journal of Parallel and Distributed Computing, 2021, 158: 126-137. |
| 17 | CHU G, HE Y, DONG L, et al. Efficient algorithm design of optimizing SpMV on GPU[C]// Proceedings of the 32nd International Symposium on High-Performance Parallel and Distributed Computing. New York: ACM, 2023: 115-128. |
| 18 | ZHOU W, ZHAO Y, SHEN X, et al. Enabling runtime SpMV format selection through an overhead conscious method[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 31(1): 80-93. |
| 19 | 顾越,赵银亮.基于RISC-V向量指令的稀疏矩阵向量乘法实现与优化[J].计算机工程与科学,2022,44(1):1-8. |
| GU Y, ZHAO Y L. Implementation and optimization of sparse matrix vector multiplication based on RISC-V vector instruction[J]. Computer Engineering & Science, 2022, 44(1): 1-8. | |
| 20 | DU Z, LI J, WANG Y, et al. AlphaSparse: generating high performance SpMV codes directly from sparse matrices[C]// Proceedings of the 2022 International Conference for High Performance Computing, Networking, Storage and Analysis. Piscataway: IEEE, 2022: 1-15. |
| 21 | YESIL S, HEIDARSHENAS A, MORRISON A, et al. Speeding up SpMV for power-law graph analytics by enhancing locality & vectorization[C]// Proceedings of the 2020 International Conference for High Performance Computing, Networking, Storage and Analysis. Piscataway: IEEE, 2020: 1-15. |
| 22 | 邓军勇,马青青.一种用于图形渲染的高性能SpMV专用加速器结构[J].小型微型计算机系统,2021,42(3):584-588. |
| DENG J Y, MA Q Q. High-performance SpMV-specific accelerator structure for graphic rendering[J]. Journal of Chinese Computer Systems, 2021, 42(3): 584-588. | |
| 23 | PARRAVICINI A, CELLAMARE L G, SIRACUSA M, et al. Scaling up HBM efficiency of top-K SpMV for approximate embedding similarity on FPGAs[C]// Proceedings of the 58th ACM/IEEE Design Automation Conference. Piscataway: IEEE, 2021: 799-804. |
| 24 | 王鑫,彭健.基于HYB格式SpMV在新一代申威架构上的实现与优化[J]. 计算机工程与科学, 2023, 45(10):1754-1762. |
| WANG X, PENG J. Implementation and optimization of HYB-based SpMV on the new-generation Sunway architecture[J]. Computer Engineering and Science, 2023, 45(10): 1754-1762. | |
| 25 | 杨思驰,赵荣彩,韩林,等.面向DCU的LDS访存向量化优化[J].计算机工程,2024,50(2):206-213. |
| YANG S C, ZHAO R C, HAN L, et al. Vectorization optimization of LDS memory access for DCU[J]. Computer Engineering, 2024, 50(2): 206-213. | |
| 26 | 李小玲,方建滨,马俊,等. 基于监督学习的稀疏矩阵自动任务分配[J]. 计算机工程与科学, 2023, 45(5):782-789. |
| LI X L, FANG J B, MA J, et al. Automated task allocation of sparse matrix computation based on supervised learning[J]. Computer Engineering and Science, 2023, 45(5): 782-789. | |
| 27 | CHEN Y, LI W, FAN R, et al. GPU optimization for high-quality kinetic fluid simulation[J]. IEEE Transactions on Visualization and Computer Graphics, 2022, 28(9): 3235-3251. |
| 28 | ANJANAPURA VENKATESH A K, SHILTON A, RANA S, et al. Kernel functional optimisation[C/OL]// Proceedings of the 35th Conference on Neural Information Processing Systems. [S.l.]: NIPS, 2021 [2023-09-21].. |
| 29 | SADI F, SWEENEY J, LOW T M, et al. Efficient SpMV operation for large and highly sparse matrices using scalable multi-way merge parallelization[C]// Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture. New York: ACM, 2019: 347-358. |
| 30 | HORGA A, REZINE A, CHATTOPADHYAY S, et al. Symbolic identification of shared memory based bank conflicts for GPUs[J]. Journal of Systems Architecture, 2022, 127: No.102518. |
| 31 | CHEN G, ZHANG C, ZOU Y. AFNet: temporal locality-aware network with dual structure for accurate and fast action detection[J]. IEEE Transactions on Multimedia, 2021, 23: 2672-2682. |
| 32 | SHA Z, CAI Z, TRAHAY F, et al. Unifying temporal and spatial locality for cache management inside SSDs[C]// Proceedings of the 2022 Design, Automation and Test in Europe Conference and Exhibition. Piscataway: IEEE, 2022: 891-896. |
| 33 | BRAUN L, FRÖNING H. CUDA Flux: a lightweight instruction profiler for CUDA applications[C]// Proceedings of the 2019 IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems. Piscataway: IEEE, 2019: 73-81. |
| 34 | KHAN M H, HASSAN O, KHAN S. Accelerating SpMV multiplication in probabilistic model checkers using GPUs[C]// Proceedings of the 2021 International Colloquium on Theoretical Aspects of Computing, LNCS 12819. Cham: Springer, 2021: 86-104. |
| [1] | Jinjin LI, Guoming SANG, Yijia ZHANG. Multi-domain fake news detection model enhanced by APK-CNN and Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2674-2682. |
| [2] | Li LIU, Changbo CHEN. Band sparse matrix multiplication and efficient GPU implementation [J]. Journal of Computer Applications, 2023, 43(12): 3856-3867. |
| [3] | Jingwen CAI, Yongzhuang WEI, Zhenghong LIU. GPU-based method for evaluating algebraic properties of cryptographic S-boxes [J]. Journal of Computer Applications, 2022, 42(9): 2750-2756. |
| [4] | Fan PING, Xiaochun TANG, Yanyu PAN, Zhanhuai LI. Scheduling strategy of irregular tasks on graphics processing unit cluster [J]. Journal of Computer Applications, 2021, 41(11): 3295-3301. |
| [5] | HE Xi, WU Yantao, DI Zhenwei, CHEN Jia. GPU-based morphological reconstruction system [J]. Journal of Computer Applications, 2019, 39(7): 2008-2013. |
| [6] | WU Xuchen, PIAO Chunhui, JIANG Xuehong. Siting model of electric taxi charging station based on GPU parallel computing [J]. Journal of Computer Applications, 2019, 39(10): 3071-3078. |
| [7] | JI Lina, CHEN Qingkui, CHEN Yuanjing, ZHAO Deyu, FANG Yuling, ZHAO Yongtao. Real-time crowd counting method from video stream based on GPU [J]. Journal of Computer Applications, 2017, 37(1): 145-152. |
| [8] | GUAN Yaqin, ZHAO Xuesheng, WANG Pengfei, LI Dapeng. Parallel algorithm for massive point cloud simplification based on slicing principle [J]. Journal of Computer Applications, 2016, 36(7): 1793-1796. |
| [9] | ZHAO Mingchao, CHEN Zhibin, WEN Youwei. Parallel computation for image denoising via total variation dual model on GPU [J]. Journal of Computer Applications, 2016, 36(5): 1228-1231. |
| [10] | WANG Lei, WANG Pengfei, ZHAO Xuesheng, LU Lituo. Optimization of spherical Voronoi diagram generating algorithm based on graphic processing unit [J]. Journal of Computer Applications, 2015, 35(6): 1564-1566. |
| [11] | LIU Baoping, CHEN Qingkui, LI Jinjing, LIU Bocheng. Parallelization of deformable part model algorithm based on graphics processing unit [J]. Journal of Computer Applications, 2015, 35(11): 3075-3078. |
| [12] | CHEN Jingyuan LI Jianhua GUO Weibin. Improved parallel simulation of silicon anisotropic etching based on GPU [J]. Journal of Computer Applications, 2013, 33(12): 3317-3320. |
| [13] | FANG Juan GUO Mei DU Wenjuan LEI Ding. Low-power oriented cache design for multi-core processor [J]. Journal of Computer Applications, 2013, 33(09): 2404-2409. |
| [14] | LIU Jinming WANG Kuanquan. School of Computer Science and Technology, Harbin Institute of Technology, Harbin Heilongjiang 150001, China [J]. Journal of Computer Applications, 2013, 33(09): 2662-2666. |
| [15] | CUI Xiang JIANG Xiaofeng. Research and implementation of realistic dynamic tree scene [J]. Journal of Computer Applications, 2013, 33(06): 1711-1714. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||