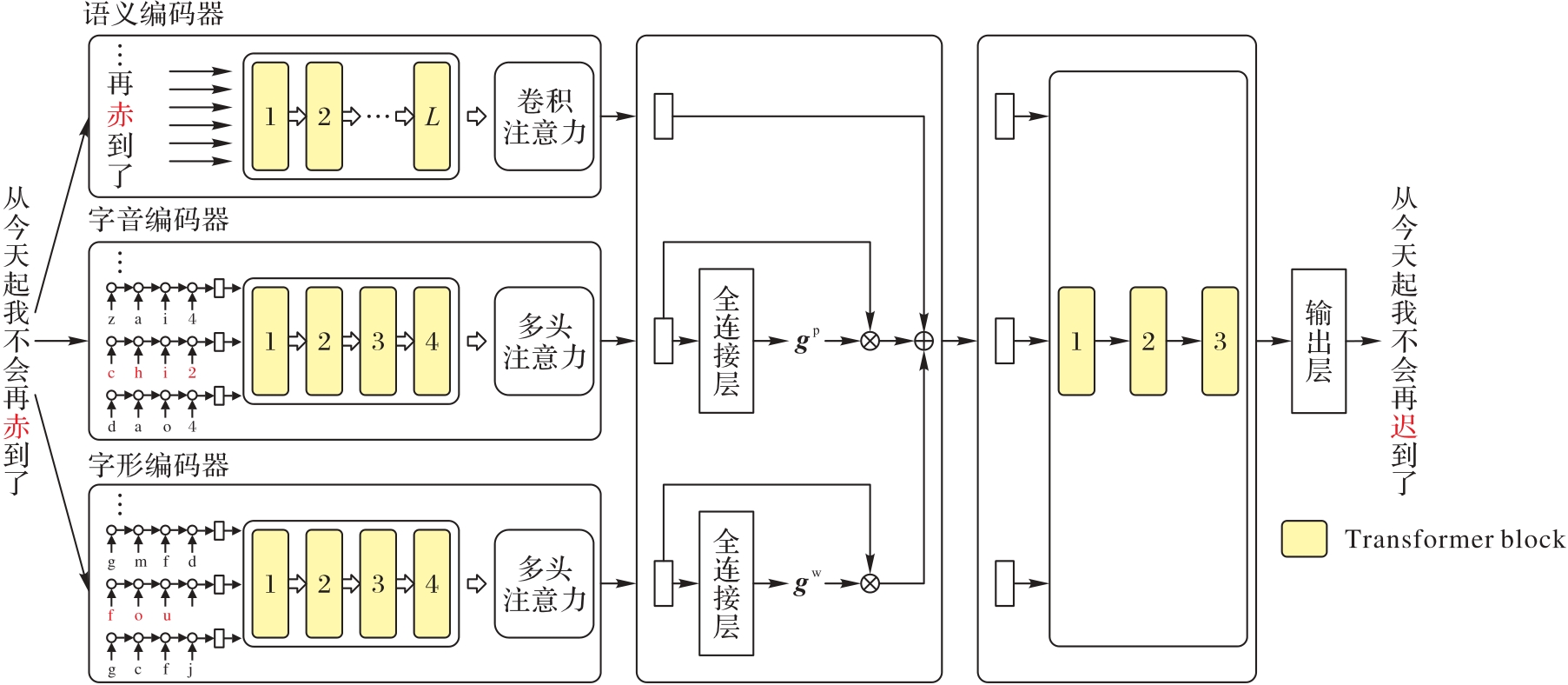
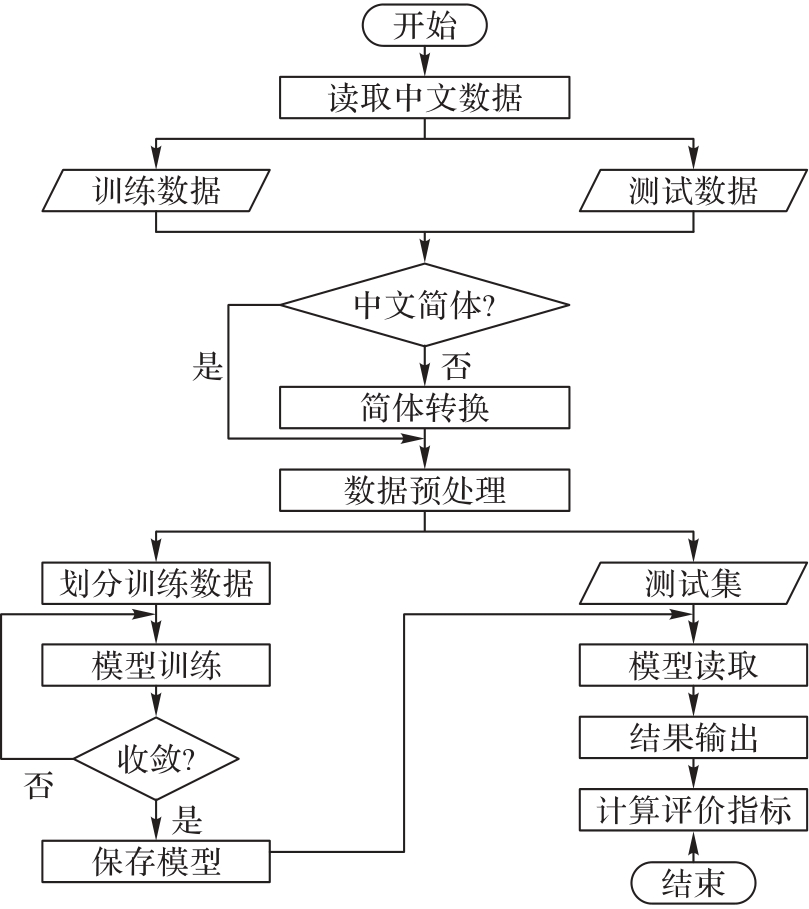
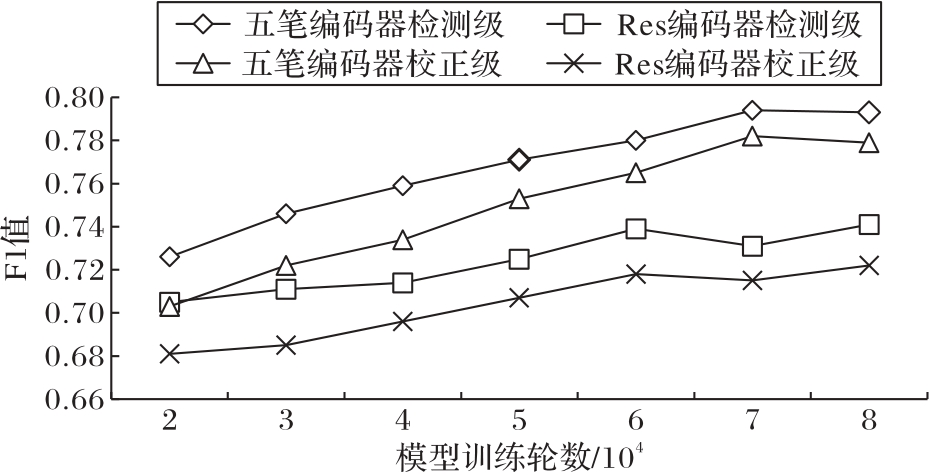
| 1 |
MARTINS B, SILVA M J. Spelling correction for search engine queries[C]// Proceedings of the 2004 International Conference on Natural Language Processing (in Spain), LNCS 3230. Berlin: Springer, 2004: 372-383.
|
| 2 |
AFLI H, QIU Z, WAY A, et al. Using SMT for OCR error correction of historical texts[C]// Proceedings of the 10th International Conference on Language Resources and Evaluation. Paris: ELRA, 2016: 962-966.
|
| 3 |
HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
|
| 4 |
LIU C L, LAI M H, CHUANG Y H, et al. Visually and phonologically similar characters in incorrect simplified Chinese words[C]// Proceedings of the 23rd International Conference on Computational Linguistics: Posters. [S.l.]: Coling 2010 Organizing Committee, 2010: 739-747.
|
| 5 |
HONG Y, YU X, HE N, et al. FASPell: a fast, adaptable, simple, powerful Chinese spell checker based on DAE-decoder paradigm[C]// Proceedings of the 5th Workshop on Noisy User-generated Text. Stroudsburg: ACL, 2019: 160-169.
|
| 6 |
CHENG X, XU W, CHEN K, et al. SpellGCN: incorporating phonological and visual similarities into language models for Chinese spelling check[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 871-881.
|
| 7 |
WANG B, CHE W, WU D, et al. Dynamic connected networks for Chinese spelling check[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: ACL, 2021: 2437-2446.
|
| 8 |
GUO Z, NI Y, WANG K, et al. Global attention decoder for Chinese spelling error correction[C]// Proceedings of the 2021 Findings of the Association for Computational Linguistics. Stroudsburg: ACL, 2021: 1419-1428.
|
| 9 |
LIU S, YANG T, YUE T, et al. PLOME: pre-training with misspelled knowledge for Chinese spelling correction[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 2991-3000.
|
| 10 |
XU H D, LI Z, ZHOU Q, et al. Read, listen, and see: leveraging multimodal information helps Chinese spell checking[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: ACL, 2021: 716-728.
|
| 11 |
LV Q, CAO Z, GENG L, et al. General and domain-adaptive Chinese spelling check with error-consistent pretraining[J]. ACM Transactions on Asian and Low-Resource Language Information Processing, 2023, 22(5): No.124.
|
| 12 |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186.
|
| 13 |
TSENG Y H, LEE L H, CHANG L P, et al. Introduction to SIGHAN 2015 bake-off for Chinese spelling check[C]// Proceedings of the 8th SIGHAN Workshop on Chinese Language Processing. Stroudsburg: ACL, 2015: 32-37.
|
| 14 |
JI T, YAN H, QIUX. SpellBERT: a lightweight pretrained model for Chinese spelling check[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 3544-3551.
|
| 15 |
WANG D, SONG Y, LI J, et al. A hybrid approach to automatic corpus generation for Chinese spelling check[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 2517-2527.
|
| 16 |
CUI Y, CHE W, LIU T, et al. Pre-training with whole word masking for Chinese BERT[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3504-3514.
|
| 17 |
潘广铭.基于多模态的中文拼写纠错方法研究[D].北京:北方工业大学,2024:24-28.
|
|
PAN G M. Research on multi-modal Chinese spelling correction[D]. Beijing: North China University of Technology, 2024: 24-28.
|
| 18 |
苏锦钿,余珊珊,洪晓斌.一种面向中文拼写纠错的自监督预训练方法[J].华南理工大学学报(自然科学版),2023,51(9):90-98.
|
|
SU J D, YU S S, HONG X B. A self-supervised pre-training method for Chinese spelling correction[J]. Journal of South China University of Technology (Natural Science Edition), 2023,51(9): 90-98.
|
| 19 |
WANG Y, WANG Y, LIU Y. Chinese spelling correction method based on multi-feature fusion and attention mechanism[C]// Proceedings of the 3rd International Conference on Computer, Artificial Intelligence and Control Engineering. New York: ACM, 2024: 481-487.
|


 ), Yuhan FANG1,2
), Yuhan FANG1,2