


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (11): 3666-3673.DOI: 10.11772/j.issn.1001-9081.2024111654
• Advanced computing • Previous Articles
Shuai ZHOU1,2, Hao FU1,2( ), Wei LIU1,2
), Wei LIU1,2
Received:2024-11-27
Revised:2025-03-31
Accepted:2025-04-08
Online:2025-04-22
Published:2025-11-10
Contact:
Hao FU
About author:ZHOU Shuai, born in 2000, M. S. candidate. His research interests include offline reinforcement learning, intelligent robot.Supported by:
周帅1,2, 符浩1,2(), 刘伟1,2
通讯作者:
符浩
作者简介:周帅(2000—),男,湖北天门人,硕士研究生,主要研究方向:离线强化学习、智能机器人基金资助:CLC Number:
Shuai ZHOU, Hao FU, Wei LIU. Spatial-temporal Transformer-based hybrid return implicit Q-learning for crowd navigation[J]. Journal of Computer Applications, 2025, 45(11): 3666-3673.
周帅, 符浩, 刘伟. 基于时空Transformer的混合回报隐式Q学习人群导航[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3666-3673.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024111654

Fig. 1 Description of crowd navigation scenario

Fig. 2 Framework of STHRIQL algorithm
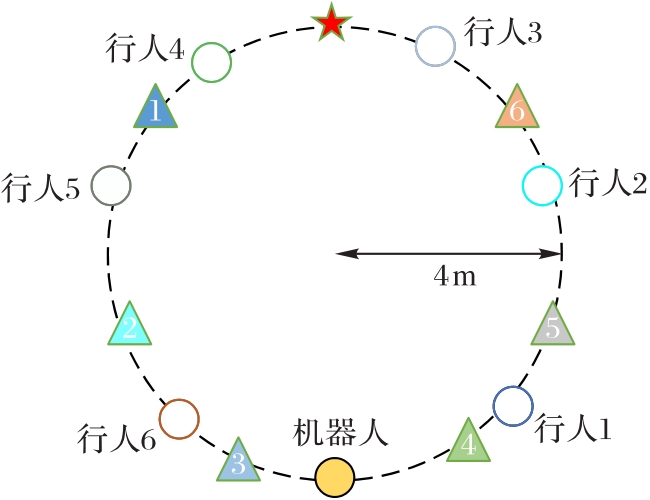
Fig. 3 Description of simulation environment
| 参数 | 取值 | 参数 | 取值 |
|---|---|---|---|
| 导航最长时限/s | 50 | 机器人首选速度/(m·s-1) | 1 |
| 时间步长/s | 0.25 | 行人首选速度/(m·s-1) | 1 |
| 碰撞半径r/m | 0.3 | 状态维度 | 48 |
| 机器人起点 | (0,-4) | 动作维度 | 2 |
| 导航目标点 | (0, 4) | 样本容量 | 5×105 |
Tab. 1 Dataset parameters
| 参数 | 取值 | 参数 | 取值 |
|---|---|---|---|
| 导航最长时限/s | 50 | 机器人首选速度/(m·s-1) | 1 |
| 时间步长/s | 0.25 | 行人首选速度/(m·s-1) | 1 |
| 碰撞半径r/m | 0.3 | 状态维度 | 48 |
| 机器人起点 | (0,-4) | 动作维度 | 2 |
| 导航目标点 | (0, 4) | 样本容量 | 5×105 |
| 参数 | 取值 | 参数 | 取值 |
|---|---|---|---|
| 批次大小 | 128 | 时间步数T | 8 |
| 学习率 | 3×10-4 | 期望回归因子 | 0.8 |
| 训练轮次 | 5×105 | 目标熵 | -2 |
| 折扣因子 | 0.9 | 1.0 | |
| 多头自注意头数 | 8 | 策略权重 | 50 |
Tab. 2 Training parameters
| 参数 | 取值 | 参数 | 取值 |
|---|---|---|---|
| 批次大小 | 128 | 时间步数T | 8 |
| 学习率 | 3×10-4 | 期望回归因子 | 0.8 |
| 训练轮次 | 5×105 | 目标熵 | -2 |
| 折扣因子 | 0.9 | 1.0 | |
| 多头自注意头数 | 8 | 策略权重 | 50 |
| 算法 | 训练 模式 | 成功 率/% | 碰撞 率/% | 平均导航时间/s | 平均 回报C | 样本 效率 |
|---|---|---|---|---|---|---|
| LSTM-RL | 在线 训练 | 97.8 | 2.2 | 12.71 | 0.932 | 0.129 |
| SARL | 98.6 | 1.4 | 11.47 | 1.016 | 0.146 | |
| ST2 | 99.0 | 1.0 | 11.32 | 1.022 | 0.154 | |
| HRIQL | 离线 训练 | 89.4 | 10.6 | 12.54 | 0.786 | 0.157 |
| STIQL | 98.4 | 1.6 | 12.30 | 0.949 | 0.190 | |
| STHRIQL | 99.2 | 0.8 | 12.08 | 1.003 | 0.201 |
Tab. 3 Quantitative evaluation results
| 算法 | 训练 模式 | 成功 率/% | 碰撞 率/% | 平均导航时间/s | 平均 回报C | 样本 效率 |
|---|---|---|---|---|---|---|
| LSTM-RL | 在线 训练 | 97.8 | 2.2 | 12.71 | 0.932 | 0.129 |
| SARL | 98.6 | 1.4 | 11.47 | 1.016 | 0.146 | |
| ST2 | 99.0 | 1.0 | 11.32 | 1.022 | 0.154 | |
| HRIQL | 离线 训练 | 89.4 | 10.6 | 12.54 | 0.786 | 0.157 |
| STIQL | 98.4 | 1.6 | 12.30 | 0.949 | 0.190 | |
| STHRIQL | 99.2 | 0.8 | 12.08 | 1.003 | 0.201 |
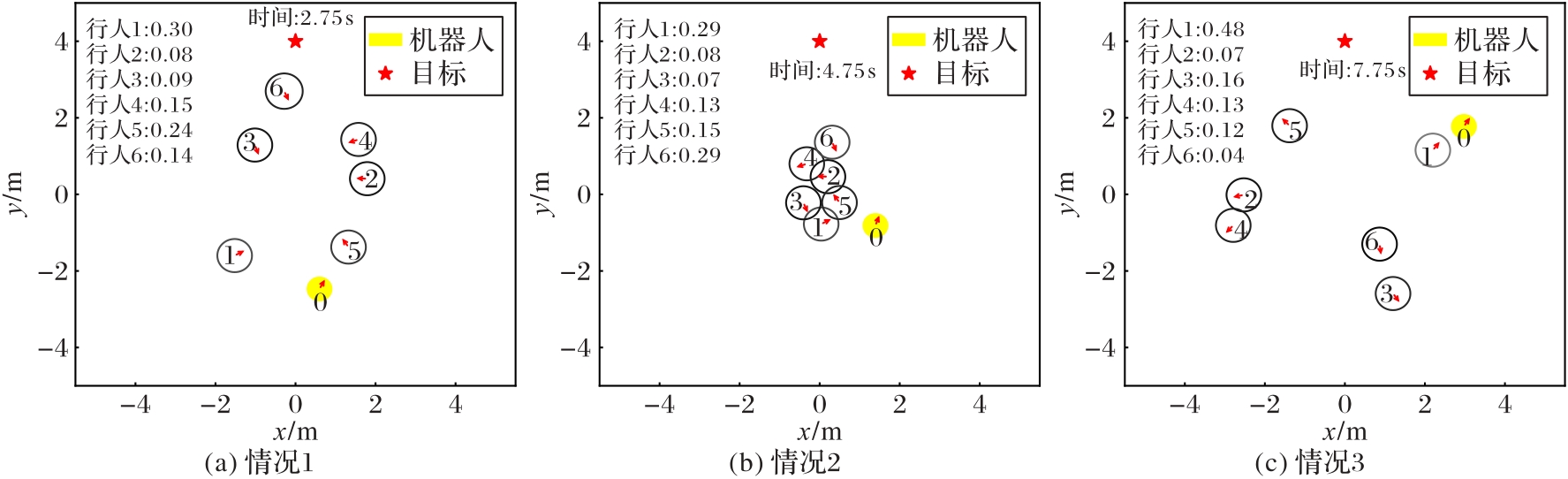
Fig. 4 Pedestrian attention weight distributions of spatial Transformer
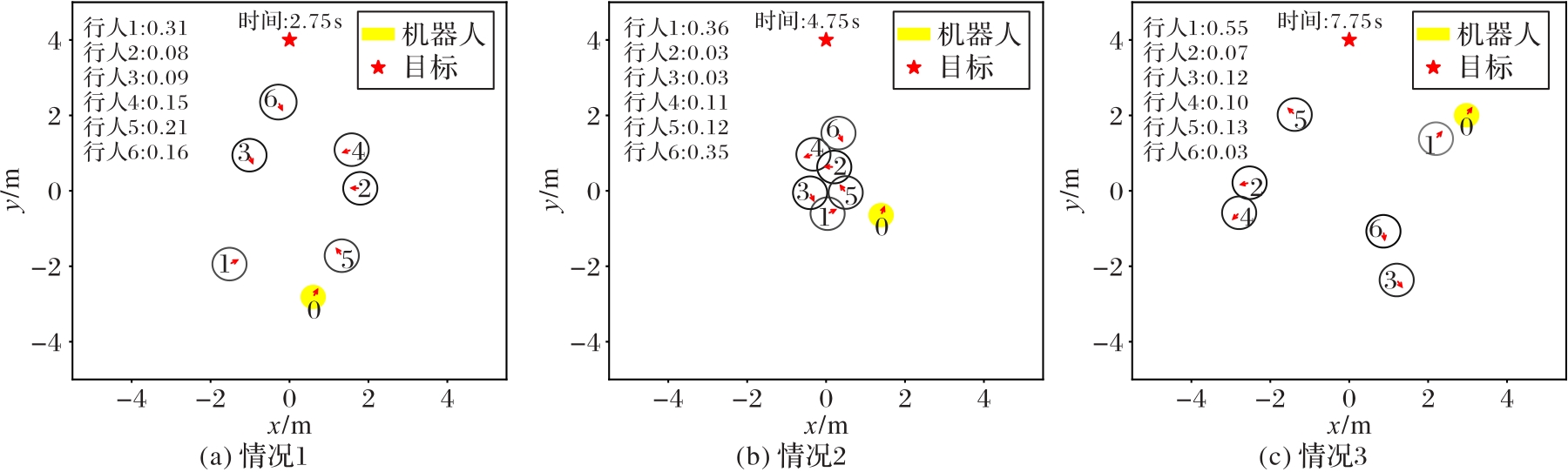
Fig. 5 Pedestrian attention weight distributions of spatial-temporal Transformer

Fig. 6 Navigation trajectories of all algorithms
| [1] | 杨姝慧.基于时空信息融合的深度强化学习机器人人群导航研究[D].济南:齐鲁工业大学,2024:2. |
| YANG S H. Research on robot crowd navigation with deep reinforcement learning based on spatio-temporal information fusion[D]. Jinan: Qilu University of Technology, 2024: 2. | |
| [2] | 何丽,张恒,袁亮,等.服务机器人社会意识导航方法综述[J]. 计算机工程与应用,2022,58(11):1-11. |
| HE L, ZHANG H, YUAN L, et al. Review of socially-aware navigation methods of service robots[J]. Computer Engineering and Applications, 2022, 58(11): 1-11. | |
| [3] | GARRELL A, SANFELIU A. Cooperative social robots to accompany groups of people[J]. The International Journal of Robotics Research, 2012, 31(13): 1675-1701. |
| [4] | FERRER G, GARRELL A, SANFELIU A. Robot companion: a social-force based approach with human awareness-navigation in crowded environments[C]// Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2013: 1688-1694. |
| [5] | HELBING D, MOLNÁR P. Social force model for pedestrian dynamics[J]. Physical Review. E, Statistical Physics, Plasmas, Fluids, and Related Interdisciplinary Topics, 1995, 51(5): 4282-4286. |
| [6] | VAN DEN BERG J, GUY S J, LIN M, et al. Reciprocal n-body collision avoidance[C]// Robotics Research: The 14th International Symposium ISRR, STAR 70. Berlin: Springer, 2011: 3-19. |
| [7] | KRETZSCHMAR H, SPIES M, SPRUNK C, et al. Socially compliant mobile robot navigation via inverse reinforcement learning[J]. The International Journal of Robotics Research, 2016, 35(11): 1289-1307. |
| [8] | TRAUTMAN P, MA J, MURRAY R M, et al. Robot navigation in dense human crowds: the case for cooperation[C]// Proceedings of the 2013 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2013: 2153-2160. |
| [9] | TRAUTMAN P, KRAUSE A. Unfreezing the robot: navigation in dense, interacting crowds[C]// Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2010: 797-803. |
| [10] | 王少桐,况立群,韩慧妍,等.基于优势后见经验回放的强化学习导航方法[J].计算机工程,2024,50(1):313-319. |
| WANG S T, KUANG L Q, HAN H Y, et al. Reinforcement learning navigation method based on advantage hindsight experience replay[J]. Computer Engineering, 2024, 50(1): 313-319. | |
| [11] | 李永迪,李彩虹,张耀玉,等.基于改进SAC算法的移动机器人路径规划[J].计算机应用,2023,43(2):654-660. |
| LI Y D, LI C H, ZHANG Y Y, et al. Mobile robot path planning based on improved SAC algorithm[J]. Journal of Computer Applications, 2023, 43(2): 654-660. | |
| [12] | SHI H, SHI L, XU M, et al. End-to-end navigation strategy with deep reinforcement learning for mobile robots[J]. IEEE Transactions on Industrial Informatics, 2020, 16(4): 2393-2402. |
| [13] | LONG P, FAN T, LIAO X, et al. Towards optimally decentralized multi-robot collision avoidance via deep reinforcement learning[C]// Proceedings of the 2018 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2018: 6252-6259. |
| [14] | XUE J, ZHANG S, LU Y, et al. Bidirectional obstacle avoidance enhancement‐deep deterministic policy gradient: a novel algorithm for mobile‐robot path planning in unknown dynamic environments[J]. Advanced Intelligent Systems, 2024, 6(4): No.2300444. |
| [15] | 马天,席润韬,吕佳豪,等.基于深度强化学习的移动机器人三维路径规划方法[J].计算机应用,2024,44(7):2055-2064. |
| MA T, XI R T, LYU J H, et al. Mobile robot 3D space path planning method based on deep reinforcement learning[J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. | |
| [16] | LU Y, CHEN Y, ZHAO D, et al. MGRL: graph neural network based inference in a Markov network with reinforcement learning for visual navigation[J]. Neurocomputing, 2021, 421: 140-150. |
| [17] | 李忠伟,刘伟鹏,罗偲.基于轨迹引导的移动机器人导航策略优化算法[J].计算机应用研究,2024,41(5):1456-1461. |
| LI Z W, LIU W P, LUO C. Autonomous navigation policy optimization algorithm for mobile robots based on trajectory guidance[J]. Application Research of Computers, 2024, 41(5): 1456-1461. | |
| [18] | CHEN Y F, LIU M, EVERETT M, et al. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning[C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 285-292. |
| [19] | CHEN Y F, EVERETT M, LIU M, et al. Socially aware motion planning with deep reinforcement learning[C]// Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2017: 1343-1350. |
| [20] | EVERETT M, CHEN Y F, HOW J P. Motion planning among dynamic, decision-making agents with deep reinforcement learning[C]// Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2018: 3052-3059. |
| [21] | LIU S, CHANG P, LIANG W, et al. Decentralized structural-RNN for robot crowd navigation with deep reinforcement learning[C]// Proceedings of the 2021 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2021: 3517-3524. |
| [22] | CHEN C, LIU Y, KREISS S, et al. Crowd-robot interaction: crowd-aware robot navigation with attention-based deep reinforcement learning[C]// Proceedings of the 2019 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2019: 6015-6022. |
| [23] | YANG Y, JIANG J, ZHANG J, et al. ST2: spatial-temporal state transformer for crowd-aware autonomous navigation[J]. IEEE Robotics and Automation Letters, 2023, 8(2): 912-919. |
| [24] | 陈锶奇,耿婕,汪云飞,等.基于离线强化学习的研究综述[J].无线电通信技术,2024,50(5):831-842. |
| CHEN S Q, GENG J, WANG Y F, et al. Survey of research on offline reinforcement learning[J]. Radio Communication Technology, 2024, 50(5): 831-842. | |
| [25] | FIGUEIREDO PRUDENCIO R, MAXIMO M R O A, COLOMBINI E L. A survey on offline reinforcement learning: taxonomy, review, and open problems[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 10237-10257. |
| [26] | FUJIMOTO S, MEGER D, PRECUP D. Off-policy deep reinforcement learning without exploration[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2052-2062. |
| [27] | 王洋,张震,王迪,等.基于可变保守程度离线强化学习的机器人运动控制方法[J/OL].控制工程 [2024-12-22].. |
| WANG Y, ZHANG Z, WANG D, et al. Robot motion control method based on offline reinforcement learning with variable conservatism[J/OL]. Control Engineering [2024-10-22].. | |
| [28] | KOSTRIKOV I, NAIR A, LEVINE S. Offline reinforcement learning with implicit Q-learning[EB/OL]. [2024-03-19].. |
| [29] | SHAH D, BHORKAR A, LEEN H, et al. Offline reinforcement learning for visual navigation[C]// Proceedings of the 6th Conference on Robot Learning. New York: JMLR.org, 2023: 44-54. |
| [30] | NAIR A, GUPTA A, DALAL M, et al. AWAC: accelerating online reinforcement learning with offline datasets[EB/OL]. [2024-11-02].. |
| [31] | HAARNOJA T, ZHOU A, HARTIKAINEN K, et al. Soft actor-critic algorithms and applications[EB/OL]. [2024-09-03].. |
| [32] | FU J, KUMAR A, NACHUM O, et al. D4 RL: datasets for deep data-driven reinforcement learning[EB/OL].[2024-06-06].. |
| [1] | Chao SHI, Yuxin ZHOU, Qian FU, Wanyu TANG, Ling HE, Yuanyuan LI. Action recognition algorithm for ADHD patients using skeleton and 3D heatmap [J]. Journal of Computer Applications, 2025, 45(9): 3036-3044. |
| [2] | Yanqun LU, Yiyi ZHAO. Customer churn prediction model integrating hierarchical graph neural network and specific feature learning [J]. Journal of Computer Applications, 2025, 45(9): 3057-3066. |
| [3] | Hongjun ZHANG, Gaojun PAN, Hao YE, Yubin LU, Yiheng MIAO. Multi-source heterogeneous data analysis method combining deep learning and tensor decomposition [J]. Journal of Computer Applications, 2025, 45(9): 2838-2847. |
| [4] | Chao LIU, Yanhua YU. Knowledge-aware recommendation model combining denoising strategy and multi-view contrastive learning [J]. Journal of Computer Applications, 2025, 45(9): 2827-2837. |
| [5] | Yonghao LIANG, Jinlong LI. Novel message passing network for neural Boolean satisfiability problem solver [J]. Journal of Computer Applications, 2025, 45(9): 2934-2940. |
| [6] | Jinggang LYU, Shaorui PENG, Shuo GAO, Jin ZHOU. Speech enhancement network driven by complex frequency attention and multi-scale frequency enhancement [J]. Journal of Computer Applications, 2025, 45(9): 2957-2965. |
| [7] | Yi WANG, Yinglong MA. Multi-task social item recommendation method based on dynamic adaptive generation of item graph [J]. Journal of Computer Applications, 2025, 45(8): 2592-2599. |
| [8] | Peng PENG, Ziting CAI, Wenling LIU, Caihua CHEN, Wei ZENG, Baolai HUANG. Speech emotion recognition method based on hybrid Siamese network with CNN and bidirectional GRU [J]. Journal of Computer Applications, 2025, 45(8): 2515-2521. |
| [9] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [10] | Quan JIANG, Wenqing HUANG, Zhiyong GOU. Lagrangian particle flow simulation by equivariant graph neural network [J]. Journal of Computer Applications, 2025, 45(8): 2666-2671. |
| [11] | Yinchuan TU, Yong GUO, Heng MAO, Yi REN, Jianfeng ZHANG, Bao LI. Evaluation of training efficiency and training performance of graph neural network models based on distributed environment [J]. Journal of Computer Applications, 2025, 45(8): 2409-2420. |
| [12] | Erkang XIANG, Rong HUANG, Aihua DONG. Open set recognition method with open generation and feature optimization [J]. Journal of Computer Applications, 2025, 45(7): 2195-2202. |
| [13] | Chen LIANG, Yisen WANG, Qiang WEI, Jiang DU. Source code vulnerability detection method based on Transformer-GCN [J]. Journal of Computer Applications, 2025, 45(7): 2296-2303. |
| [14] | Zimo ZHANG, Xuezhuan ZHAO. Multi-scale sparse graph guided vision graph neural networks [J]. Journal of Computer Applications, 2025, 45(7): 2188-2194. |
| [15] | Yongpeng TAO, Shiqi BAI, Zhengwen ZHOU. Neural architecture search for multi-tissue segmentation using convolutional and transformer-based networks in glioma segmentation [J]. Journal of Computer Applications, 2025, 45(7): 2378-2386. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||