


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (6): 1785-1792.DOI: 10.11772/j.issn.1001-9081.2025050662
• Artificial intelligence • Previous Articles
Jintao WANG, Zhilin GAO, Qixiang MENG, Fanliang BU( )
)
Received:2025-06-23
Revised:2025-09-07
Accepted:2025-09-09
Online:2025-09-15
Published:2026-06-10
Contact:
Fanliang BU
About author:WANG Jintao, born in 2000, M. S. candidate. His research interests include natural language processing, information retrieval.Supported by:
王劲滔, 高志霖, 孟琪翔, 卜凡亮()
通讯作者:
卜凡亮
作者简介:王劲滔(2000—),男,江苏扬州人,硕士研究生,CCF会员,主要研究方向:自然语言处理、信息检索基金资助:CLC Number:
Jintao WANG, Zhilin GAO, Qixiang MENG, Fanliang BU. Legal case retrieval method via case information reformulation using large language model[J]. Journal of Computer Applications, 2026, 46(6): 1785-1792.
王劲滔, 高志霖, 孟琪翔, 卜凡亮. 基于大语言模型重构案件信息的类案检索方法[J]. 《计算机应用》唯一官方网站, 2026, 46(6): 1785-1792.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050662
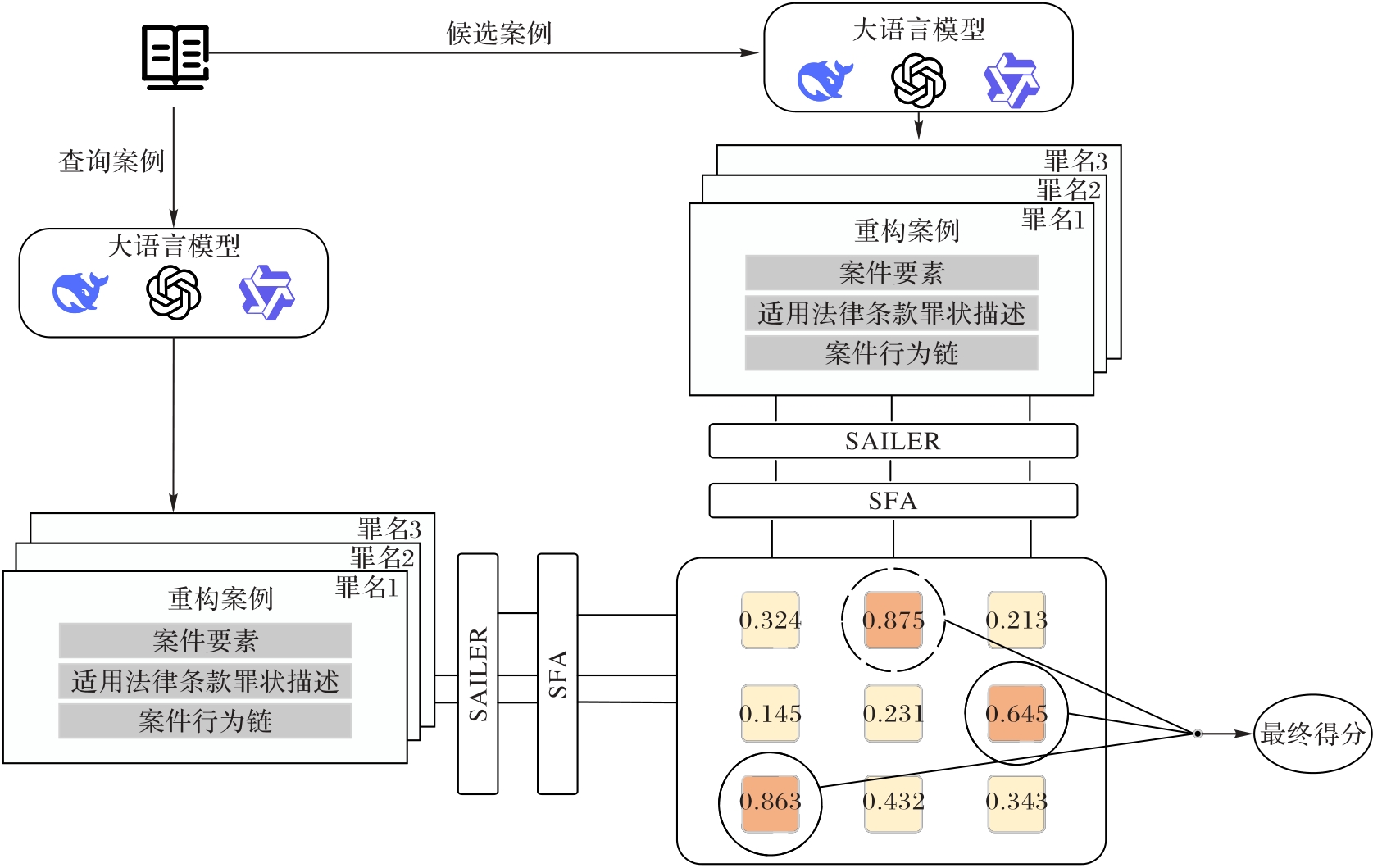
Fig. 1 Overall architecture of legal case retrieval model
| 案件要素 | 示例 |
|---|---|
| 犯罪人物类型 | 未成年人、精神病人等 |
| 罪名 | 抢劫罪、交通肇事罪等 |
| 犯罪行为 | 伤害、殴打、贩卖毒品等 |
| 涉案物品 | 甲基苯丙胺、机动车辆等 |
| 量刑情节 | 悔罪、立功、认罪等 |
| 和解情况 | 达成和解协议等 |
| 犯罪后果 | 死亡、轻伤、造成损失等 |
Tab.1 Examples of case elements
| 案件要素 | 示例 |
|---|---|
| 犯罪人物类型 | 未成年人、精神病人等 |
| 罪名 | 抢劫罪、交通肇事罪等 |
| 犯罪行为 | 伤害、殴打、贩卖毒品等 |
| 涉案物品 | 甲基苯丙胺、机动车辆等 |
| 量刑情节 | 悔罪、立功、认罪等 |
| 和解情况 | 达成和解协议等 |
| 犯罪后果 | 死亡、轻伤、造成损失等 |
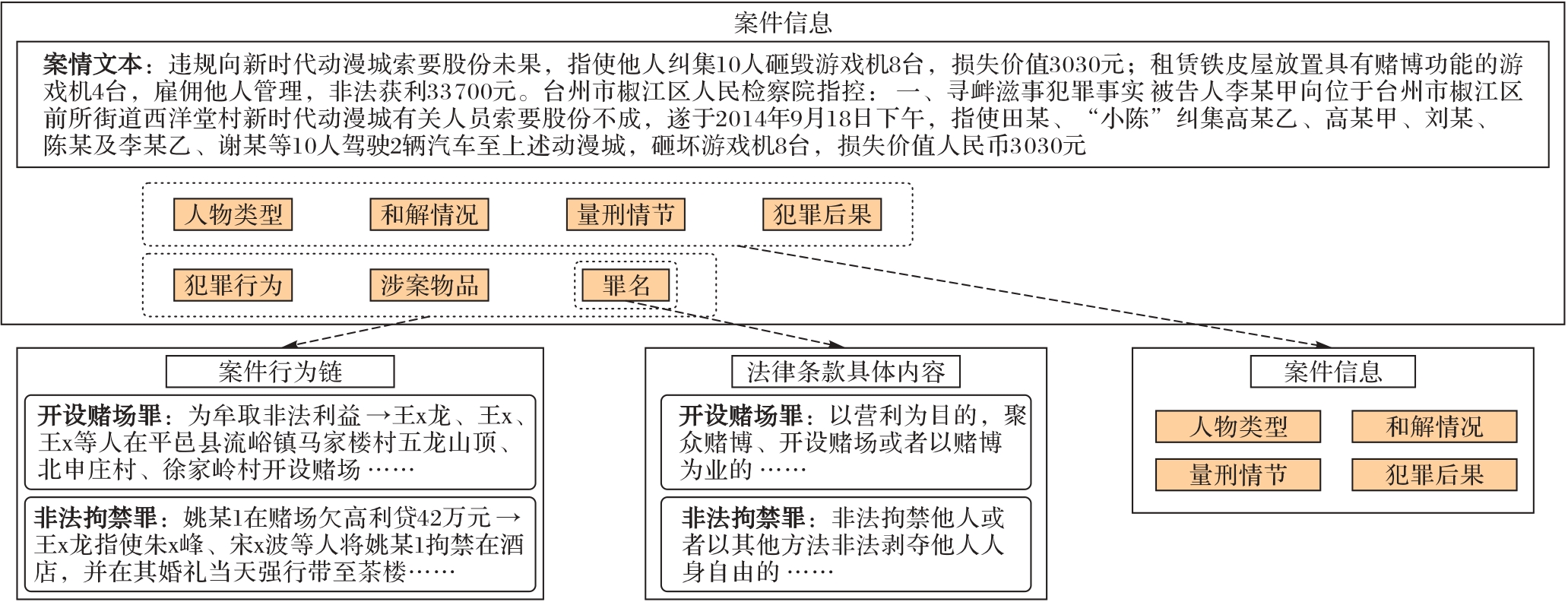
Fig.2 Components of reformulated case information
案件 子事实 | 案件要素 | 适用法律条款罪状描述 | 案件行为链 |
|---|---|---|---|
投注、参与赌网利润分成等行为 | |||
Tab.2 Example representations of sub-facts of cases
案件 子事实 | 案件要素 | 适用法律条款罪状描述 | 案件行为链 |
|---|---|---|---|
投注、参与赌网利润分成等行为 | |||
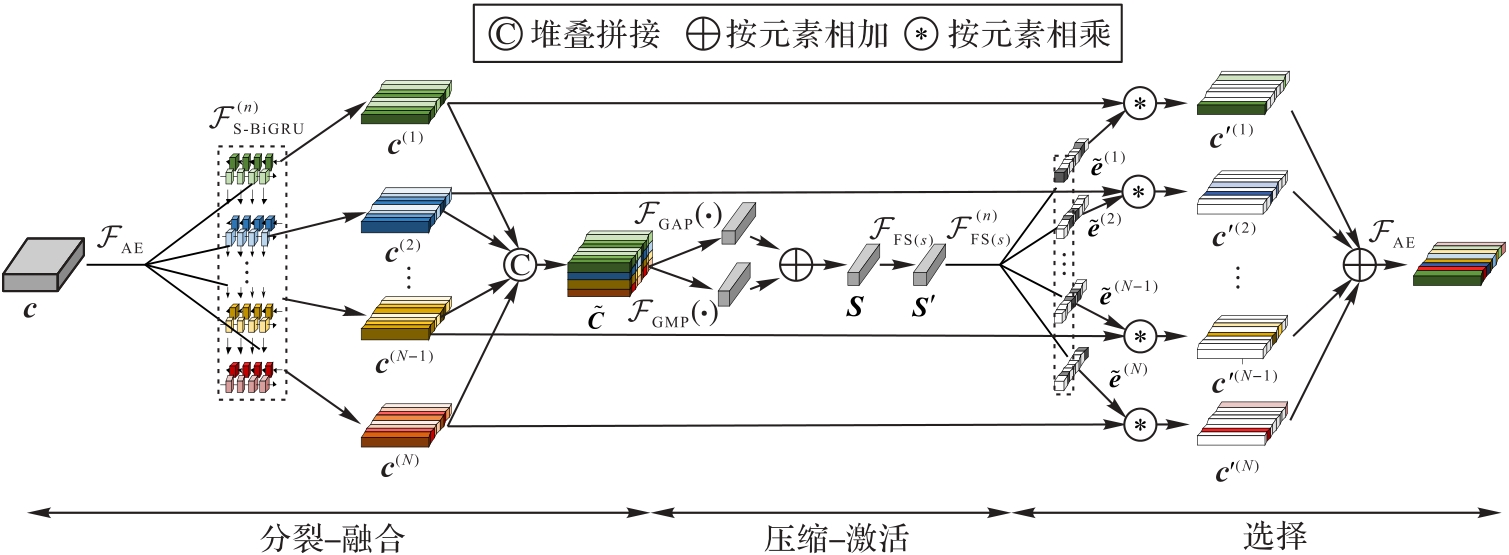
Fig.3 SFA mechanism
| 要件事实 | 案情事实 | 相似度 |
|---|---|---|
| 相似 | 相似 | 3 |
| 相似 | 不相似 | 2 |
| 不相似 | 相似 | 1 |
| 不相似 | 不相似 | 0 |
Tab.3 Annotation instructions for LeCaRD dataset
| 要件事实 | 案情事实 | 相似度 |
|---|---|---|
| 相似 | 相似 | 3 |
| 相似 | 不相似 | 2 |
| 不相似 | 相似 | 1 |
| 不相似 | 不相似 | 0 |
| 模型 | MAP | P@3 | NDCG@3 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|
| TF-IDF | 45.05 | 35.36 | 63.77 | 64.70 | 66.81 |
| BM-25 | 48.19 | 41.77 | 64.76 | 65.94 | 68.79 |
| BERT | 48.83 | 41.11 | 68.35 | 68.97 | 72.42 |
| RoBERTa | 53.83 | 47.62 | 74.40 | 74.33 | 76.70 |
| coCondenser | 52.13 | 47.11 | 67.22 | 66.86 | 69.21 |
| COT-MAE | 56.35 | 49.42 | 69.45 | 67.13 | 70.72 |
| RetroMAE | 55.76 | 49.97 | 68.01 | 67.20 | 68.83 |
| SAILER | 55.92 | 51.67 | 78.97 | 79.33 | 80.16 |
| Lawformer | 54.58 | 50.79 | 73.19 | 73.43 | 75.54 |
| BERT-PLI(BERT) | 47.91 | 39.99 | 63.22 | 68.56 | 72.24 |
| PromptCase | 64.92 | 55.45 | 78.15 | 78.30 | 80.23 |
| KELLER | 64.77 | 55.87 | 79.79 | 81.62 | 84.34 |
| 本文模型 | 67.45 | 60.95 | 83.01 | 83.44 | 85.37 |
Tab.4 Evaluation results of different models
| 模型 | MAP | P@3 | NDCG@3 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|
| TF-IDF | 45.05 | 35.36 | 63.77 | 64.70 | 66.81 |
| BM-25 | 48.19 | 41.77 | 64.76 | 65.94 | 68.79 |
| BERT | 48.83 | 41.11 | 68.35 | 68.97 | 72.42 |
| RoBERTa | 53.83 | 47.62 | 74.40 | 74.33 | 76.70 |
| coCondenser | 52.13 | 47.11 | 67.22 | 66.86 | 69.21 |
| COT-MAE | 56.35 | 49.42 | 69.45 | 67.13 | 70.72 |
| RetroMAE | 55.76 | 49.97 | 68.01 | 67.20 | 68.83 |
| SAILER | 55.92 | 51.67 | 78.97 | 79.33 | 80.16 |
| Lawformer | 54.58 | 50.79 | 73.19 | 73.43 | 75.54 |
| BERT-PLI(BERT) | 47.91 | 39.99 | 63.22 | 68.56 | 72.24 |
| PromptCase | 64.92 | 55.45 | 78.15 | 78.30 | 80.23 |
| KELLER | 64.77 | 55.87 | 79.79 | 81.62 | 84.34 |
| 本文模型 | 67.45 | 60.95 | 83.01 | 83.44 | 85.37 |
| 消除模块 | MAP | P@3 | NDCG@3 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|
| 案件行为链 | 61.91 | 54.28 | 79.31 | 80.37 | 81.92 |
| 法律条款罪状描述 | 65.28 | 56.82 | 80.32 | 81.86 | 84.66 |
| 案件要素 | 66.44 | 59.68 | 81.95 | 82.21 | 84.04 |
| SFA机制 | 64.89 | 55.55 | 79.12 | 80.71 | 83.82 |
Tab.5 Ablation experimental results
| 消除模块 | MAP | P@3 | NDCG@3 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|
| 案件行为链 | 61.91 | 54.28 | 79.31 | 80.37 | 81.92 |
| 法律条款罪状描述 | 65.28 | 56.82 | 80.32 | 81.86 | 84.66 |
| 案件要素 | 66.44 | 59.68 | 81.95 | 82.21 | 84.04 |
| SFA机制 | 64.89 | 55.55 | 79.12 | 80.71 | 83.82 |
| [1] | 谢永峰,尹华,乔丹. 类案检索技术研究综述[J]. 软件导刊, 2024, 23(6): 198-204. |
| XIE Y F, YIN H, QIAO D. A survey on law case retrieval technology[J]. Software Guide, 2024, 23(6): 198-204. | |
| [2] | LI H, AI Q, CHEN J, et al. SAILER: structure-aware pre-trained language model for legal case retrieval[C]// Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2023: 1035-1044. |
| [3] | DENG C, MAO K, DOU Z. Learning interpretable legal case retrieval via knowledge-guided case reformulation[C]// Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2024: 1253-1265. |
| [4] | TANG Y, QIU R, LI X. Prompt-based effective input reformulation for legal case retrieval[C]// Proceedings of the 2023 Australasian Database Conference, LNCS 14386. Cham: Springer, 2024: 87-100. |
| [5] | 李林睿,王东升,范红杰. 基于法条知识的事理型类案检索方法[J].浙江大学学报(工学版), 2024, 58(7): 1357-1365. |
| LI L R, WANG D S, FAN H J. Fact-based similar case retrieval methods based on statutory knowledge[J]. Journal of Zhejiang University (Engineering Science), 2024, 58(7): 1357-1365. | |
| [6] | XIAO C, HU X, LIU Z, et al. Lawformer: a pre-trained language model for Chinese legal long documents[J]. AI Open, 2021, 2: 79-84. |
| [7] | VAN OPIJNEN M, SANTOS C. On the concept of relevance in legal information retrieval[J]. Artificial Intelligence and Law, 2017, 25(1): 65-87. |
| [8] | KHATTAB O, ZAHARIA M. ColBERT: efficient and effective passage search via contextualized late interaction over BERT[C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 39-48. |
| [9] | MA Y, SHAO Y, WU Y, et al. LeCaRD: a legal case retrieval dataset for Chinese law system[C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 2342-2348. |
| [10] | SALTON G, BUCKLEY C. Term-weighting approaches in automatic text retrieval[J]. Information Processing and Management, 1988, 24(5): 513-523. |
| [11] | ROBERTSON S, ZARAGOZA H. The probabilistic relevance framework: BM25 and beyond[J]. Foundations and Trends® in Information Retrieval, 2009, 3(4): 333-389. |
| [12] | PONTE J M, CROFT W B. A language modeling approach to information retrieval[C]// Proceeding of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 1998: 275-281. |
| [13] | BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022. |
| [14] | 詹力林,秦永彬,黄瑞章,等. 融合时序行为链与事件类型的类案检索方法[J]. 计算机应用, 2025, 45(6): 1741-1747. |
| ZHAN L L, QIN Y B, HUANG R Z, et al. Legal case retrieval method integrating temporal behavior chain and event type[J]. Journal of Computer Applications, 2025, 45(6): 1741-1747. | |
| [15] | TRAN V, NGUYEN M L, SATOH K. Building legal case retrieval systems with lexical matching and summarization using a pre-trained phrase scoring model[C]// Proceeding of the 17th International Conference on Artificial Intelligence and Law. New York: ACM, 2019: 275-282. |
| [16] | ASKARI A, VERBERNE S. Combining lexical and neural retrieval with Longformer-based summarization for effective case law retrieval[C]// Proceeding of the 2nd International Conference on Design of Experimental Search and Information Retrieval Systems. Aachen: CEUR-WS.org, 2021: 162-170. |
| [17] | YU W, SUN Z, XU J, et al. Explainable legal case matching via inverse optimal transport-based rationale extraction[C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 657-668. |
| [18] | SHAO Y, MAO J, LIU Y, et al. BERT-PLI: modeling paragraph-level interactions for legal case retrieval[C]// Proceeding of the 29th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020: 3501-3507. |
| [19] | ALTHAMMER S, HOFSTÄTTER S, HANBURY A. Cross-domain retrieval in the legal and patent domains: a reproducibility study[C]// Proceeding of the 2021 European Conference on Information Retrieval, LNCS 12657. Cham: Springer, 2021: 3-17. |
| [20] | HU W, ZHAO S, ZHAO Q, et al. BERT_LF: a similar case retrieval method based on legal facts[J]. Wireless Communications and Mobile Computing, 2022, 2022: No.2511147. |
| [21] | ZANG J, LIU H. Modeling selective feature attention for lightweight text matching[C]// Proceedings of the 33rd International Joint Conference on Artificial Intelligence. California: ijcai.org, 2024: 6624-6632. |
| [22] | 曹发鑫,孙媛媛,王治政,等. 面向借贷案件的相似案例匹配模型[J]. 计算工程, 2024, 50(1): 306-312. |
| CAO F X, SUN Y Y, WANG Z Z, et al. Similar case matching model for lending cases[J]. Computer Engineering, 2024, 50(1): 306-312. | |
| [23] | 刘权,余正涛,高盛祥,等. 融合案件要素的相似案例匹配[J]. 中文信息学报, 2022, 36(11): 140-147. |
| LIU Q, YU Z T, GAO S X, et al. Incorporating case elements for case matching[J]. Journal of Chinese Information Processing, 2022, 36(11): 140-147. | |
| [24] | 刘博阳,李尚,叶麟,等. 基于法律要素引导的相似案例推荐算法[J]. 智能计算机与应用, 2021, 11(6): 1-4, 13. |
| LIU B Y, LI S, YE L, et al. Similar case recommendation algorithm based on legal elements[J]. Intelligent Computer and Applications, 2021, 11(6): 1-4, 13. | |
| [25] | LYU Y, WANG Z, REN Z, et al. Improving legal judgment prediction through reinforced criminal element extraction[J]. Information Processing and Management, 2022, 59(1): No.102780. |
| [26] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceeding of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [27] | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2024-03-25].. |
| [28] | GAO L, CALLAN J. Unsupervised corpus aware language model pre-training for dense passage retrieval[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 2843-2853. |
| [29] | XIAO S, LIU Z, SHAO Y, et al. RetroMAE: pre-training retrieval-oriented language models via masked auto-encoder[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 538-548. |
| [30] | WU X, MA G Y, LIN M, et al. ConTextual masked auto-encoder for dense passage retrieval[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 4738-4746. |
| [1] | Longyu XIONG, Shengdong DU, Haochen SHI, Jie HU, Yan YANG, Tianrui LI. Government affairs hotline question answering system based on knowledge-enhanced large language model architecture [J]. Journal of Computer Applications, 2026, 46(6): 1721-1727. |
| [2] | Taixin CAI, Fengfeng WEI. Large language model-enhanced ant colony optimization for multi-solution traveling salesman problems [J]. Journal of Computer Applications, 2026, 46(6): 1712-1720. |
| [3] | Qianfei WANG, Yang LI, Deyu LI, Suge WANG. Dual-channel feature fusion representation method for short-text clustering based on large language model [J]. Journal of Computer Applications, 2026, 46(5): 1441-1449. |
| [4] | Xing SHENG, Sunxian WENG, Kuosong CHEN, Zhongping WANG, Ruifeng REN, Yong LIU. Deep learning-based patent value evaluation for power grid enterprises [J]. Journal of Computer Applications, 2026, 46(5): 1468-1474. |
| [5] | Jiali ZHENG, Gang ZHOU, Jing CHEN, Shunhang LI. Adaptive multi-feature fusion detection method for AI-generated text [J]. Journal of Computer Applications, 2026, 46(5): 1433-1440. |
| [6] | Xiaoyu WANG, Xin LI, Di XUE, Zhangtao JIANG, Wei WANG, Yanjun XIAO. Vulnerability classification framework for video surveillance network security based on large language models [J]. Journal of Computer Applications, 2026, 46(4): 1158-1170. |
| [7] | Kaizhou SHI, Xuan HE, Guoyi HOU, Gen LI, Shuanggao LI, Xiang HUANG. Airborne product metrological traceability knowledge graph construction method based on large language models [J]. Journal of Computer Applications, 2026, 46(4): 1086-1095. |
| [8] | Haoyang ZHANG, Liping ZHANG, Sheng YAN, Na LI, Xuefei ZHANG. Review of large language model methods for knowledge graph completion [J]. Journal of Computer Applications, 2026, 46(3): 683-695. |
| [9] | Bin SHEN, Xiaoning CHEN, Hua CHENG, Yiquan FANG, Huifeng WANG. Intelligent undergraduate teaching evaluation system based on large language models [J]. Journal of Computer Applications, 2026, 46(3): 993-1003. |
| [10] | Enkang XI, Jing FAN, Yadong JIN, Hua DONG, Hao YU, Yihang SUN. Review of threats faced by federated learning in privacy and security field [J]. Journal of Computer Applications, 2026, 46(3): 798-808. |
| [11] | Yiming HUANG, Xihua ZOU, Guo DENG, Di ZHENG. Pre-answering and retrieval filtering: dual-stage optimization method for RAG-based question-answering systems [J]. Journal of Computer Applications, 2026, 46(3): 696-707. |
| [12] | Rilong WANG, Zhenping LI, Xiaosong LI, Qiang GAO, Ya HE, Yong ZHONG, Yingxiao ZHAO. Multi-Agent collaborative knowledge reasoning framework [J]. Journal of Computer Applications, 2026, 46(3): 708-714. |
| [13] | Dingjia WU, Zhe CUI. MG-SQL: SQL generation framework with enhanced schema linking and multi-generator collaboration [J]. Journal of Computer Applications, 2026, 46(3): 723-731. |
| [14] | Fei GAO, Dong CHEN, Dixing BIAN, Wenqiang FAN, Qidong LIU, Pei LYU, Chaoyang ZHANG, Mingliang XU. Multistage coupled decision-making framework for researcher redeployment after discipline revocation [J]. Journal of Computer Applications, 2026, 46(2): 416-426. |
| [15] | Yixin LIU, Xianggen LIU, Wen LIU, Hongbo DENG, Ziye ZHANG, Hua MU. Benchmark dataset for retrieval-augmented generation on long documents [J]. Journal of Computer Applications, 2026, 46(2): 386-394. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||