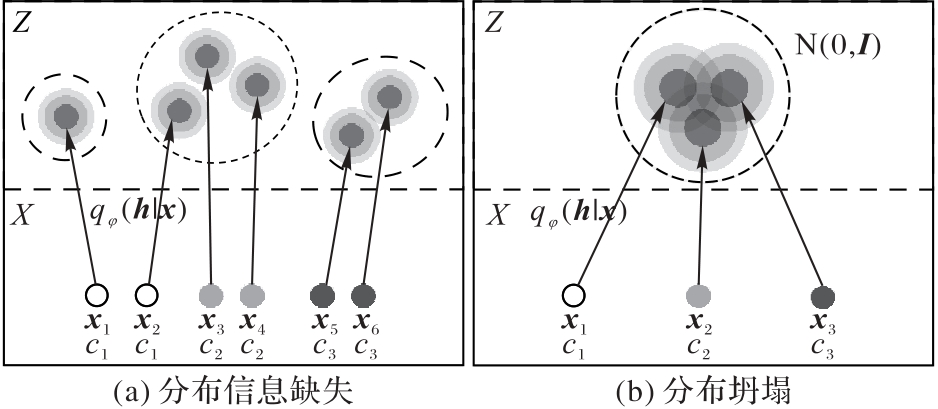
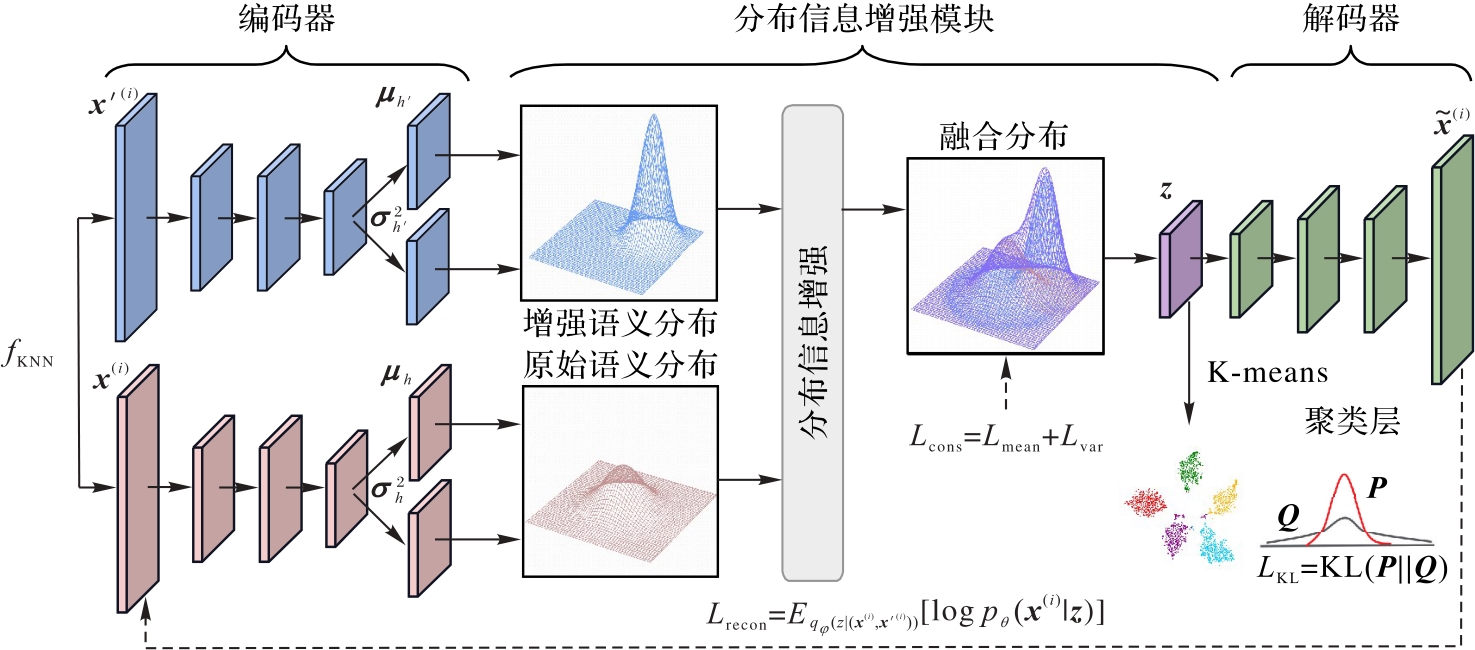
| [1] |
KINGMA D P, WELLING M. Auto-encoding variational Bayes[EB/OL]. [2024-06-10]..
|
| [2] |
MANDUCHI L, VANDENHIRTZ M, RYSER A, et al. Tree variational autoencoders[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 54952-54986.
|
| [3] |
BAI R, HUANG R, QIN Y, et al. HVAE: a deep generative model via hierarchical variational auto-encoder for multi-view document modeling[J]. Information Sciences, 2023, 623: 40-55.
|
| [4] |
TOLSTIKHIN I, BOUSQUET O, GELLY S, et al. Wasserstein auto-encoders[EB/OL]. [2024-06-10]..
|
| [5] |
TU W, ZHOU S, LIU X, et al. Deep fusion clustering network[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 9978-9987.
|
| [6] |
GUO C, ZHOU J, CHEN H, et al. Variational autoencoder with optimizing Gaussian mixture model priors[J]. IEEE Access, 2020, 8: 43992-44005.
|
| [7] |
JIANG Z, ZHENG Y, TAN H, et al. Variational deep embedding: an unsupervised and generative approach to clustering[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2017: 1965-1972.
|
| [8] |
KIPF T N, WELLING M. Variational graph auto-encoders[EB/OL]. [2024-06-10]..
|
| [9] |
YANG B, FU X, SIDIROPOULOS N D, et al. Towards k-means-friendly spaces: simultaneous deep learning and clustering[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 3861-3870.
|
| [10] |
HARTIGAN J A, WONG M A. A K-means clustering algorithm[J]. Journal of the Royal Statistical Society Series C (Applied Statistics), 1979, 28(1): 100-108.
|
| [11] |
XIE J, GIRSHICK R, FARHADI A. Unsupervised deep embedding for clustering analysis[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 478-487.
|
| [12] |
YAN G, WEN K, HONG J, et al. An analysis method for time-based features of malicious domains based on time series clustering[C]// Proceedings of the 2023 International Conference on Web Information Systems and Applications, LNCS 14094. Singapore: Springer, 2023: 347-358.
|
| [13] |
BO D, WANG X, SHI C, et al. Structural deep clustering network[C]// Proceedings of the Web Conference 2020. New York: ACM, 2020: 1400-1410.
|
| [14] |
马胜位,黄瑞章,任丽娜,等. 基于多层语义融合的结构化深度文本聚类模型[J]. 计算机应用, 2023, 43(8):2364-2369.
|
|
MA S W, HUANG R Z, REN L N, et al. Structured deep text clustering model based on multi-layer semantic fusion[J]. Journal of Computer Applications, 2023, 43(8): 2364-2369.
|
| [15] |
DILOKTHANAKUL N, MEDIANO P A M, GARNELO M, et al. Deep unsupervised clustering with Gaussian mixture variational autoencoders[EB/OL]. [2024-07-10]..
|
| [16] |
CACIULARU A, GOLDBERGER J. An entangled mixture of variational autoencoders approach to deep clustering[J]. Neurocomputing, 2023, 529: 182-189.
|
| [17] |
李静楠,黄瑞章,任丽娜. 用户意图补充的半监督深度文本聚类[J]. 计算机科学与探索, 2023, 17(8): 1928-1937.
|
|
LI J N, HUANG R Z, REN L N. Semi-supervised deep document clustering model with supplemented user intention[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(8): 1928-1937.
|
| [18] |
黄瑞章,白瑞娜,陈艳平,等. CMDC:一种差异互补的迭代式多维度文本聚类算法[J]. 通信学报, 2020, 41(8): 155-164.
|
|
HUANG R Z, BAI R N, CHEN Y P, et al. CMDC: an iterative algorithm for complementary multi-view document clustering[J]. Journal on Communications, 2020, 41(8): 155-164.
|
| [19] |
GREENE D, CUNNINGHAM P. Practical solutions to the problem of diagonal dominance in kernel document clustering[C]// Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006: 377-384.
|
| [20] |
KADHIM A I, CHEAH Y N, AHAMED N H. Text document preprocessing and dimension reduction techniques for text document clustering[C]// Proceedings of the 4th International Conference on Artificial Intelligence with Applications in Engineering and Technology. Piscataway: IEEE, 2014: 69-73.
|
| [21] |
BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
|
| [22] |
HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786):504-507.
|
| [23] |
GUO X, GAO L, LIU X, et al. Improved deep embedded clustering with local structure preservation[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2017: 1753-1759.
|
| [24] |
GUO X, LIU X, ZHU E, et al. Deep clustering with convolutional autoencoders[C]// Proceedings of the 2017 International Conference on Neural Information Processing, LNCS 10635. Cham: Springer, 2017: 373-382.
|
| [25] |
薛菁菁,秦永彬,黄瑞章,等. SSVAE:一种补充语义信息的深度变分文本聚类模型[J]. 数据分析与知识发现, 2022, 6(6):71-83.
|
|
XUE J J, QIN Y B, HUANG R Z, et al. SSVAE: a deep variational text clustering model with semantic supplementation[J]. Data Analysis and Knowledge Discovery, 2022, 6(6): 71-83.
|
| [26] |
REN L, QIN Y, CHEN Y, et al. Deep structural enhanced network for document clustering[J]. Applied Intelligence, 2023, 53(10): 12163-12178.
|
| [27] |
BAI R, HUANG R, ZHENG L, et al. Structure enhanced deep clustering network via a weighted neighbourhood auto-encoder[J]. Neural Networks, 2022, 155: 144-154.
|
| [28] |
VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605.
|


 ), Jingjing XUE1,2,3, Yanping CHEN1,2,3, Yongbin QIN1,2,3
), Jingjing XUE1,2,3, Yanping CHEN1,2,3, Yongbin QIN1,2,3